
热门标签
热门文章
- 1浅谈【Stable-Diffusion WEBUI】(AI绘图)的基础和使用_stable diffusion --medvram --theme dark --xformers
- 2Hive(一) Hive概述、三种方式搭建和区别_hive 的安装过程与ha搭建有什么区别
- 3应用连MySQL 报错ERROR 1129 Host is blocked because of many connection errors
- 4PMP证书到期后,有没有必要续证了_pmp证书有必要续吗
- 5Centos7一键安装Docker脚本_centos安装docker 菜鸟 一键脚本
- 6linux搭建raid5命令,命令行操作RAID5
- 7C语言 哈希表的简单实现_用 hash table 实现一个存储学生成绩的程序,你的程序要能处理 collision,请使用
- 8【Redis】sentinel故障转移_sentinel 是如何实现故障转移的
- 9【Super数据结构】堆结构的建立与调整&&堆的应用(含堆排序/topK问题)
- 10【Web前端】JS高级知识总结_前端js高级部分
当前位置: article > 正文
transformer的学习记录【完整代码+详细注释】(系列五)_transformer与故障诊断代码
作者:IT小白 | 2024-04-13 02:58:58
赞
踩
transformer与故障诊断代码
第一节:transformer的架构介绍 + 输入部分的实现
链接:https://editor.csdn.net/md/?articleId=124648718
第二节 编码器部分实现(一)
链接:https://editor.csdn.net/md/?articleId=124648718
第三节 编码器部分实现(二)
链接:https://editor.csdn.net/md/?articleId=124724264
第四节 编码器部分实现(三)
链接:https://editor.csdn.net/md/?articleId=124746022
第五节 解码器部分实现
链接:https://editor.csdn.net/md/?articleId=124750632
第六节 输出部分实现
链接:https://editor.csdn.net/md/?articleId=124757450
1 解码器部分介绍
- 由N个解码层堆叠而成
- 每个解码器由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层、规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层、规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层、规范化层以及一个残差连接
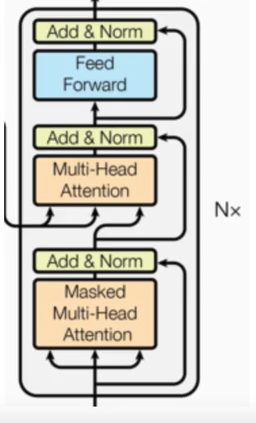
2 解码器层
2.1 解码作用
每个解码器层, 根据给定的输入,向目标方向进行特征提取操作,即解码操作。
2.2 解码器层的代码分析
- 多头自注意力机制,Q = K = V
self_attn - 多头注意力机制: Q ! = K = V
src_attn
2.3 解码器层类的代码
# 构建解码器层类
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
# size : 代表词嵌入的维度
# attn :多头自注意力机制对象
# src_attn : 常规的注意力机制对象
# feed_forweawrd : 前馈全连接层
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.dropout = dropout
# 使用clones函数, 克隆3个子层连接对象
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, source_mask, target_mask):
# x: 上一层输入的张量
# memory : 代表编码器的语义存储张量
# source_mask : 源数据的掩码张量
# target_mask : 目标数据的掩码张量
m = memory
# 第一步,让x 进入第一个子层,(多头自注意力子层
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
# 第二步,让x 进入第二个子层,(常规注意力子层
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
# 第三步,让x进入第三个子层,前馈全连接层
return self.sublayer[2](x, self.feed_forward)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3 解码器
- 就是把解码器层 × N
3.1 解码器代码
# 构建解码器类
class Decoder(nn.Module):
def __init__(self, layer, N):
# layer : 代表解码器层 的对象
# N : 代表将layer进行几层的拷贝
super(Decoder, self).__init__()
# 利用clones函数克隆N个layer
self.layers = clones(layer, N)
# 实例化一个规范化层
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, source_mask, target_mask):
# x: 代表目标数数的嵌入表示
# memory : 代表编码器的输出张量
# source_mask : 源数据的掩码张量
# target_mask: 目标数据的掩码张量
# x经过所有的编码器层,最后通过规范化层
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4 到目前为止完整的代码
- 可以直接运行!
import math
from torch.autograd import Variable
from torch import nn
import torch
import copy
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
# main作用:集成了整个Transformer代码
########################################################################################################################
########################################################################################################################
# 构建 Embedding 类来实现文本嵌入层
# vocab : 词表的长度, d_model : 词嵌入的维度
class Embedding(nn.Module):
def __init__(self, vocab, d_model):
super(Embedding, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
# 词表: 1000*512, 共是1000个词,每一行是一个词,每个词是一个512d的向量表示
vocab = 1000
d_model = 512
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embedding(vocab, d_model)
embr = emb(x)
########################################################################################################################
# 构建位置编码器的类
# d_model : 代表词嵌入的维度
# dropout : 代表Dropout层的置零比率
# max_len : 代表每个句子的最大长度
# 初始化一个位置编码矩阵pe,大小是 max_len * d_model
# 初始化一个绝对位置矩阵position, 大小是max_len * 1
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
# 定义一个变化矩阵,div_term, 跳跃式的初始化
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
# 将前面定义的变化矩阵 进行技术,偶数分别赋值
pe[:, 0::2] = torch.sin(position * div_term) # 用正弦波给偶数部分赋值
pe[:, 1::2] = torch.cos(position * div_term) # 用余弦波给奇数部分赋值
# 将二维张量,扩充为三维张量
pe = pe.unsqueeze(0) # 1 * max_len * d_model
# 将位置编码矩阵,注册成模型的buffer,这个buffer不是模型中的参数,不跟随优化器同步更新
# 注册成buffer后,就可以在模型保存后 重新加载的时候,将这个位置编码器和模型参数
self.register_buffer('pe', pe)
def forward(self, x):
# x : 代表文本序列的词嵌入表示
# 首先明确pe的编码太长了,将第二个维度,就是max_len对应的维度,缩小成x的句子的同等的长度
x = x + Variable(self.pe[:, : x.size(1)], requires_grad=False) # 表示位置编码是不参与更新的
return self.dropout(x)
d_model = 512
dropout = 0.1
max_len = 60
vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embedding(vocab, d_model)
embr = emb(x)
x = embr # shape: [2, 4, 512]
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)
# print(pe_result)
def attention(query, key, value, mask=None, dropout=None):
# query, key, value : 代表注意力的三个输入张量
# mask : 掩码张量
# dropout : 传入Dropout实例化对象
# 首先,将query的最后一个维度提取出来,代表的是词嵌入的维度
d_k = query.size(-1)
# 按照注意力计算公式,将query和key 的转置进行矩阵乘法,然后除以缩放系数
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# print("..", scores.shape)
# 判断是否使用掩码张量
if mask is not None:
# 利用masked_fill 方法,将掩码张量和0进行位置的意义比较,如果等于0,就替换成 -1e9
scores = scores.masked_fill(mask == 0, -1e9)
# scores的最后一个维度上进行 softmax
p_attn = F.softmax(scores, dim=-1)
# 判断是否使用dropout
if dropout is not None:
p_attn = dropout(p_attn)
# 最后一步完成p_attm 和 value 的乘法,并返回query的注意力表示
return torch.matmul(p_attn, value), p_attn
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print('attn', attn)
# print('attn.shape', attn.shape)
# print("p_attn", p_attn)
# print(p_attn.shape)
# 实现克隆函数,因为在多头注意力机制下,要用到多个结果相同的线性层
# 需要使用clone 函数u,将他们统一 初始化到一个网络层列表对象中
def clones(module, N):
# module : 代表要克隆的目标网络层
# N : 将module几个
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
# 实现多头注意力机制的类
class MultiHeadAttention(nn.Module):
def __init__(self, head, embedding_dim, dropout=0.1):
# head : 代表几个头的函数
# embedding_dim : 代表词嵌入的维度
# dropout
super(MultiHeadAttention, self).__init__()
# 强调:多头的数量head 需要整除 词嵌入的维度 embedding_dim
assert embedding_dim % head == 0
# 得到每个头,所获得 的词向量的维度
self.d_k = embedding_dim // head
self.head = head
self.embedding_dim = embedding_dim
# 获得线性层,需要获得4个,分别是Q K V 以及最终输出的线性层
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
# 初始化注意力张量
self.attn = None
# 初始化dropout对象
self.drop = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
# query,key,value 是注意力机制的三个输入张量,mask代表掩码张量
# 首先判断是否使用掩码张量
if mask is not None:
# 使用squeeze将掩码张量进行围堵扩充,代表多头的第n个头
mask = mask.unsqueeze(1)
# 得到batch_size
batch_size = query.size(0)
# 首先使用 zip 将网络能和输入数据连接在一起,模型的输出 利用 view 和 transpose 进行维度和形状的
query, key, value = \
[model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)
for model, x in zip(self.linears, (query, key, value))]
# 将每个头的输出 传入到注意力层
x, self.attn = attention(query, key, value, mask=mask, dropout=self.drop)
# 得到每个头的计算结果,每个output都是4维的张量,需要进行维度转换
# 前面已经将transpose(1, 2)
# 注意,先transpose 然后 contiguous,否则无法使用view
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head*self.d_k)
# 最后将x输入到线性层的最后一个线性层中进行处理,得到最终的多头注意力结构输出
return self.linears[-1](x)
# 实例化若干个参数
head = 8
embedding_dim = 512
dropout = 0.2
# 若干输入参数的初始化
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
mha = MultiHeadAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)
# print(mha_result.shape)
import math
from torch.autograd import Variable
from torch import nn
import torch
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
# d_model : 代表词嵌入的维度,同时也是两个线性层的输入维度和输出维度
# d_ff : 代表第一个线性层的输出维度,和第二个线性层的输入维度
# dropout : 经过Dropout层处理时,随机置零
super(PositionwiseFeedForward, self).__init__()
# 定义两层全连接的线性层
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
# x: 来自上一层的输出
# 首先将x送入第一个线性网络,然后relu 然后dropout
# 然后送入第二个线性层
return self.w2(self.dropout(F.relu((self.w1(x)))))
d_model = 512
d_ff = 64
dropout = 0.2
# 这个是上一层的输出,作为前馈连接的输入
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)
# print(ff_result)
# print(ff_result.shape)
# 构架规范化层的类
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
# features : 代表词嵌入的维度
# eps :一个很小的数,防止在规范化公式 除以0
super(LayerNorm, self).__init__()
# 初始化两个参数张量 a2 b 2 用于对结果作规范化 操作计算
# 用nn.Parameter 封装,代表他们也是模型中的参数,也要随着模型计算而计算
self.a2 = nn.Parameter(torch.ones(features))
self.b2 = nn.Parameter(torch.zeros(features))
self.eps = eps # 传入到模型中去
def forward(self, x):
# x : 是上一层网络的输出 (两层的前馈全连接层)
# 首先对x进行 最后一个维度上的求均值操作,同时要求保持输出维度和输入维度一致
mean = x.mean(-1, keepdim=True)
# 接着对x最后一个维度上求标准差的操作,同时要求保持输出维度和输入维度一制
std = x.std(-1, keepdim=True)
# 按照规范化公式进行计算并返回
return self.a2 * (x-mean) / (std + self.eps) + self.b2
features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)
# print(ln_result)
# print(ln_result.shape)
# 构建子层连接结构的类
class SublayerConnection(nn.Module):
def __init__(self, size, dropout=0.1):
# size 是词嵌入的维度
super(SublayerConnection, self).__init__()
# 实例化一个规范化层的对象
self.norm = LayerNorm(size)\
# 实例化一个dropout对象
self.dropout = nn.Dropout(p=dropout)
self.size = size
def forward(self, x, sublayer):
# : x代表上一层传入的张量
# sublayer : 代表子层连接中 子层函数
# 首先将x进行规范化,送入子层函数,然后dropout, 最后残差连接
return x + self.dropout(sublayer(self.norm(x)))
size = d_model = 512
head = 8
dropout = 0.2
x = pe_result
mask = Variable(torch.zeros(2, 4, 4))
# 子层函数采用的是多头注意力机制
self_attn = MultiHeadAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)
# print(sc_result)
# print(sc_result.shape)
# 构建编码器层的类
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
# size : 代表词嵌入的维度
# self_attn : 代表传入的多头自注意力子层的实例化对象
# feed_forward : 代表前馈全连接层实例化对象
# dropout : 进行dropout置零比率
super(EncoderLayer, self).__init__()
# 将两个实例化对象和参数传入类中
self.self_attn = self_attn
self.feed_forward = feed_forward
self.size = size
# 编码器层中,有两个子层连接结构,需要clones函数进行操作
self.sublayer = clones(SublayerConnection(size, dropout), 2)
def forward(self, x, mask):
# x: 代表上一层传入的张量(位置编码
# mask : 代表掩码张量
# 首先让 x 经过第一个子层连接结构,内部包含多头自注意力机制子层
# 再让张量经过第二个子层连接结构,其中包含前馈全连接网络
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
size = d_model = 512
head = 8
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(2, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)
# print(el_result)
# print(el_result.shape)
# 构建编码器类 Encoder
class Encoder(nn.Module):
def __init__(self, layer, N):
# layer : 代表上一节编写的 编码器层
# N : 代表 编码器中需要 几个编码器层(layer)
super(Encoder, self).__init__()
# 首先使用 clones 函数 克隆 N 个编码器层 防止在self.layer中
self.layers = clones(layer, N)
# 初始化一个规范化层,作用在编码器后面
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
# 代表上一层输出的张量
# mask 是掩码张量
# 让x 依次经过N个编码器层的处理;最后再经过规范化层就可以输出了
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
size = d_model = 512
head = 8
d_ff = 64
c = copy.deepcopy
attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8
mask = Variable(torch.zeros(2, 4, 4))
en = Encoder(layer, N)
en_result = en(x, mask)
# print(en_result)
# print(en_result.shape)
# 构建解码器层类
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
# size : 代表词嵌入的维度
# attn :多头自注意力机制对象
# src_attn : 常规的注意力机制对象
# feed_forweawrd : 前馈全连接层
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.dropout = dropout
# 使用clones函数, 克隆3个子层连接对象
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, source_mask, target_mask):
# x: 上一层输入的张量
# memory : 代表编码器的语义存储张量
# source_mask : 源数据的掩码张量
# target_mask : 目标数据的掩码张量
m = memory
# 第一步,让x 进入第一个子层,(多头自注意力子层
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
# 第二步,让x 进入第二个子层,(常规注意力子层
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
# 第三步,让x进入第三个子层,前馈全连接层
return self.sublayer[2](x, self.feed_forward)
size = d_model = 512
head = 8
d_ff = 64
dropout = 0.2
# 这里就没有区分多头自注意力和常规注意力机制了
self_attn = src_attn = MultiHeadAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
x = pe_result
memory = en_result
mask = Variable(torch.zeros(2, 4, 4))
source_mask = target_mask = mask
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
dl_result = dl(x, memory, source_mask, target_mask)
# print(dl_result)
# print(dl_result.shape)
# 构建解码器类
class Decoder(nn.Module):
def __init__(self, layer, N):
# layer : 代表解码器层 的对象
# N : 代表将layer进行几层的拷贝
super(Decoder, self).__init__()
# 利用clones函数克隆N个layer
self.layers = clones(layer, N)
# 实例化一个规范化层
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, source_mask, target_mask):
# x: 代表目标数数的嵌入表示
# memory : 代表编码器的输出张量
# source_mask : 源数据的掩码张量
# target_mask: 目标数据的掩码张量
# x经过所有的编码器层,最后通过规范化层
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)
size = d_model = 512
head = 8
d_ff = 64
dropout = 0.2
c = copy.deepcopy
attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout)
N = 8
x = pe_result
memory = en_result
mask = Variable(torch.zeros(2, 4, 4))
source_mask = target_mask = mask
de = Decoder(layer, N)
de_result = de(x, memory, source_mask, target_mask)
print(de_result)
print(de_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
推荐阅读
相关标签

