
- 1AI绘画SD图片高清化+面部修复+一键抠图,一些你不知道的事儿_sd抠图
- 2计算机网络七层体系结构(OSI七层结构)、TCP/IP四层模型、网络五层体系结构_七层架构
- 3玩自动阅读,100部手机去操作,一天可以赚1200?揭秘背后的故事_2023 自动阅读 项目
- 4大数据服务之linux中安装hadoop_linux安装hadoop
- 5在线客服系统源码H5网页版 带完整搭建教程_网页版客服聊天窗口源码
- 62023年《北上广深杭》有哪些值得加入的软件测试大厂公司呢?花了三天三夜整理出各大互联网公司_小鹅通上大厂吗
- 7开源模型应用落地-qwen模型小试-调用qwen1.5新模型-进阶篇(六)_qwen2
- 8Anaconda如何创建虚拟环境?如何切换虚拟环境?_anaconda切换虚拟环境
- 9浅谈数据逻辑结构分类
- 10Python猴子吃桃问题_猴子吃桃问题python
NLP中的Transformer,一文掌握
赞
踩
Transformer变压器模型的出现
2017 年,Vaswani 等人在关键论文“Attention is All You Need”中介绍了 Transformer 模型,它标志着与以前占主导地位的基于递归神经网络的模型(如 LSTM(长短期记忆)和 GRU(门控递归单元))的背离。这些模型是许多 NLP 应用程序的支柱,但具有固有的局限性,尤其是在处理长序列和并行处理数据方面。
Transformer的出现是解决这些限制的方法。它们的架构与以前根本不同,允许并行处理整个数据序列。这种转变不仅提高了处理效率,而且为处理大规模语言数据开辟了新的途径,这在涉及理解文本中的上下文和关系的任务中尤为关键。
了解 Transformer 架构
变压器的架构既复杂又巧妙。它由几个组件组成,这些组件协同工作以有效地处理语言数据: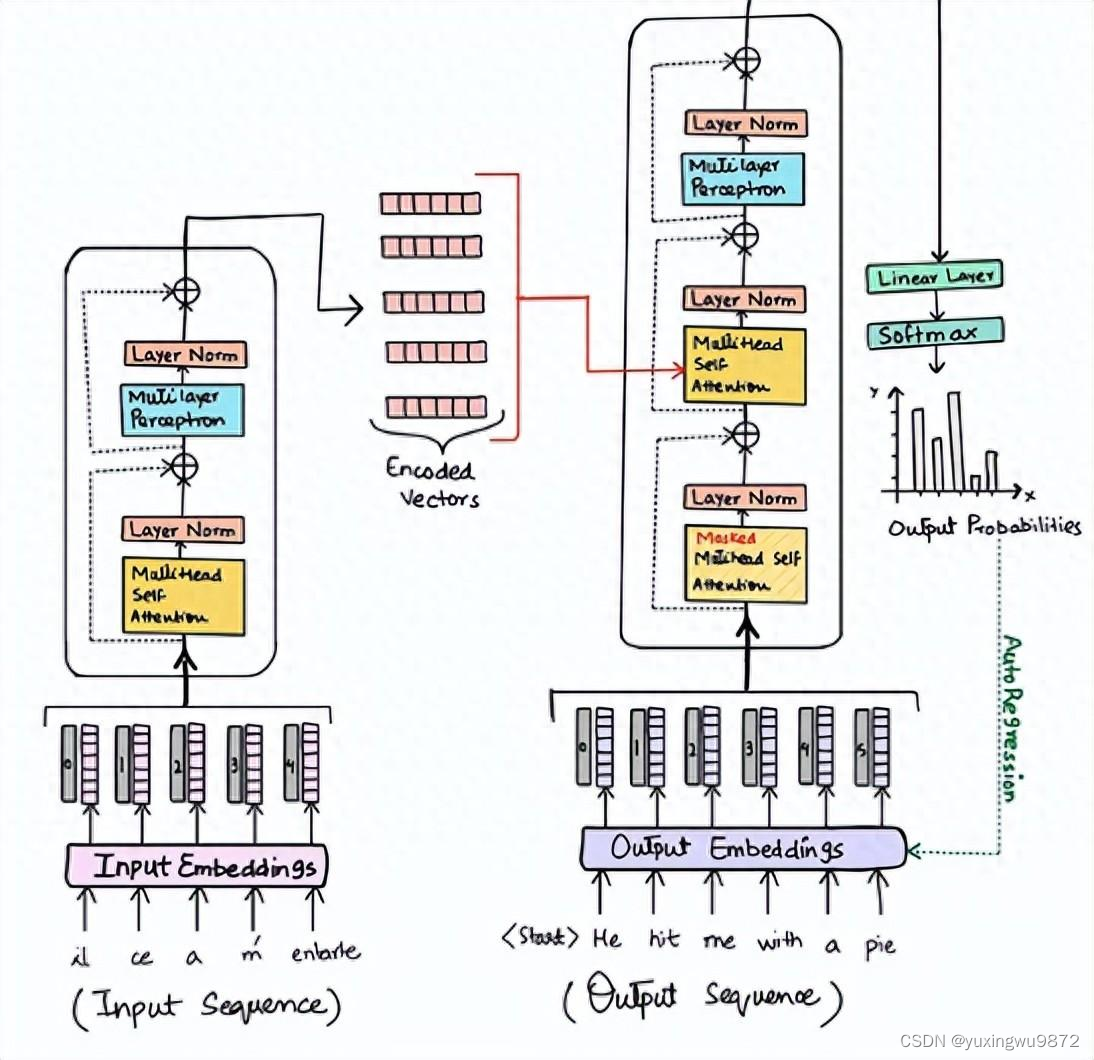
-Transformer 编码器和解码器模块
Transformer由多个编码器和解码器块堆叠在一起组成。这种结构与传统的 seq2seq 模型有很大不同,后者通常具有单个编码器和单个解码器。
- 自我注意力机制
Transformer的核心创新是自我注意力机制。这s使编码器中的每个位置关注编码器前一层中的所有位置。同样,解码器中的每个位置都可以处理解码器中的所有位置,直到该位置以及编码器中的所有位置。这种机制允许模型权衡输入数据不同部分的重要性,从而能够细致入微地理解数据中的上下文和关系。
- 位置编码
由于 Transformer 不按顺序处理数据,因此它们缺少有关序列中单词顺序的信息。位置编码被添加到输入嵌入中以提供此位置信息,使模型能够理解单词序列。
- 前馈神经网络
每个编码器和解码器模块都包含一个完全连接的前馈网络。该网络处理来自注意力层的输出,每层都有自己的参数。
- 层归一化和残差连接
这些元素对于稳定和加速 Transformer 模型的训练至关重要。层归一化有助于在将每个子层的输出传递到下一层之前对其进行归一化,残差连接有助于避免训练期间梯度消失的问题。
与传统模型(LSTM、GRU、seq2seq)的比较
Transformers 与 LSTM、GRU 和 seq2seq 模型等传统模型之间的关键比较在于它们处理数据的方法。LSTM 和 GRU 模型擅长从序列中捕获信息,但这样做是按顺序进行的。这种顺序处理意味着这些模型可能会遇到文本中的长期依赖关系,因为信息必须经过序列中的每个步骤。
Seq2seq 模型通常用于机器翻译和其他类似任务,通常由编码器和解码器组成。虽然有效,但它们也按顺序处理信息,并且可能会在文本中的长序列和复杂关系中挣扎。
Transformer 通过并行处理整个数据序列来克服这些挑战。这种并行处理功能显著提高了模型的效率及其处理复杂语言任务的能力。Transformers 中的自我注意力机制允许对文本中的上下文和关系进行更细致入微的理解,这在语言翻译、摘要和问答系统等任务中特别有价值。

