
- 1uni-app集成使用SQLite_uni-app使用sqlite页面代码怎么写
- 2Google分布式系统三大论文(三)MapReduce: Simplified Data Processing on Large Clusters_在google那篇论文中说明,在mapreduce中,用户指定一个_______处理一个key/va
- 3Android Studio 最新汉化包下载及安装方法,持续更新 & IDEA_android studio汉化包
- 4机器学习套路 —— 样本集的拆分(正样本、负样本)_负样本英文
- 5大数据之Hudi数据湖_基本概念_文件布局_存储方式_.parquet文件和.log文件_以及文件查找过滤方式_布隆过滤---大数据之Hudi数据湖工作笔记0006
- 6GitHub 使用教程图文详解
- 7Xcode下载模拟器报错Could not download iOS 17.4 Simulator (21E213).
- 8云计算在IT领域的发展和应用_云计算it领域
- 9猴子吃桃问题(数学公式推算过程和源码)_猴子第一天摘下若干桃子,当即吃了一半,还不过瘾,又多吃了一个; 第二天又将剩下的
- 10移除chromeDriver脚本文件
推荐系统算法 协同过滤算法详解(一)杰卡德相似度和余弦相似度使用、缺陷_协同过滤余弦相似度
赞
踩
目录
前言
理解吧同胞们,实在是没办发把wps公式复制到文章上,只能截图了,我服了!!!
协同过滤算法(简称CF)
在早期,协同过滤几乎等同于推荐系统。主要的功能是预测和推荐。协同过滤推荐算法分为两类,分别是:
(英文userCF)
- 基于用户的协同过滤算法(相似的用户可能喜欢相同物品);这个一般适合推荐新闻和皮皮虾之类的,数据跟人有很大关系,而且信息是每日都是更新的。如果你推荐购物这种,因为一个新建的用户可能购买的商品不足全量商品万分之1,商品数据量大,人对商品购买少,很难找到相似的人;随着用户和物品数量的增加,计算复杂度增加,所以需要这种更适合第二种算法。
(英文itemCF)
- 基于物品的协同过滤算法(这种方法通过分析物品之间的相似性,根据用户喜欢的物品,,推荐最大相似度其他物品。比如用户喜欢物品A,然后通过算法的出物品C和A的相似度极高,那么用户有可能喜欢物品C)。当然也有缺点:需要足够的用户-物品交互数据来找出物品之间的相似性。
当然你除此之外,还有基于模型的协同过滤方法。这就属于更高级的推荐了,他一般是多因素,也是现代化推荐系统的主力。
- 利用机器学习算法(如矩阵分解、深度学习等)来预测用户对物品的评分或偏好。
- 优点:能够处理大规模数据集,提高推荐质量。
- 缺点:模型训练可能需要大量计算资源。
下述我会先说下杰卡德相似度 和 余弦相似度,这两者都是衡量相似度的方法,但它们通常不直接被称为协同过滤算法。不过,它们可以用于协同过滤算法中计算用户或物品之间的相似度。
杰卡德相似度
杰卡德相似度用于衡量两个集合之间的相似度。它定义为两个集合交集的大小与它们并集的大小之比。
公式:

其实公式可以理解为:其实就是一组数中有无在另一组中存在于数,并且他的占比是多少。
示例
假设我们有两组数据:
A = {1, 2, 3, 4}
B = {3, 4, 5, 6}
计算它们的杰卡德相似度:

缺陷
用于衡量两个集合的相似度,计算它们共同元素的比例。缺点只能计算两组统一规则数相似度也就是说杰卡德相似度适合用于只关心元素是否存在的情况(例如集合或布尔向量),是不考虑用户的评分或偏好强度。
余弦相似度
余弦相似度用于衡量两个向量在方向上的相似度,广泛用于文本分析和推荐系统中。它通过测量两个向量间的夹角的余弦值来确定它们是否指向同一方向。
算法:
向量相乘除以模相乘

例子
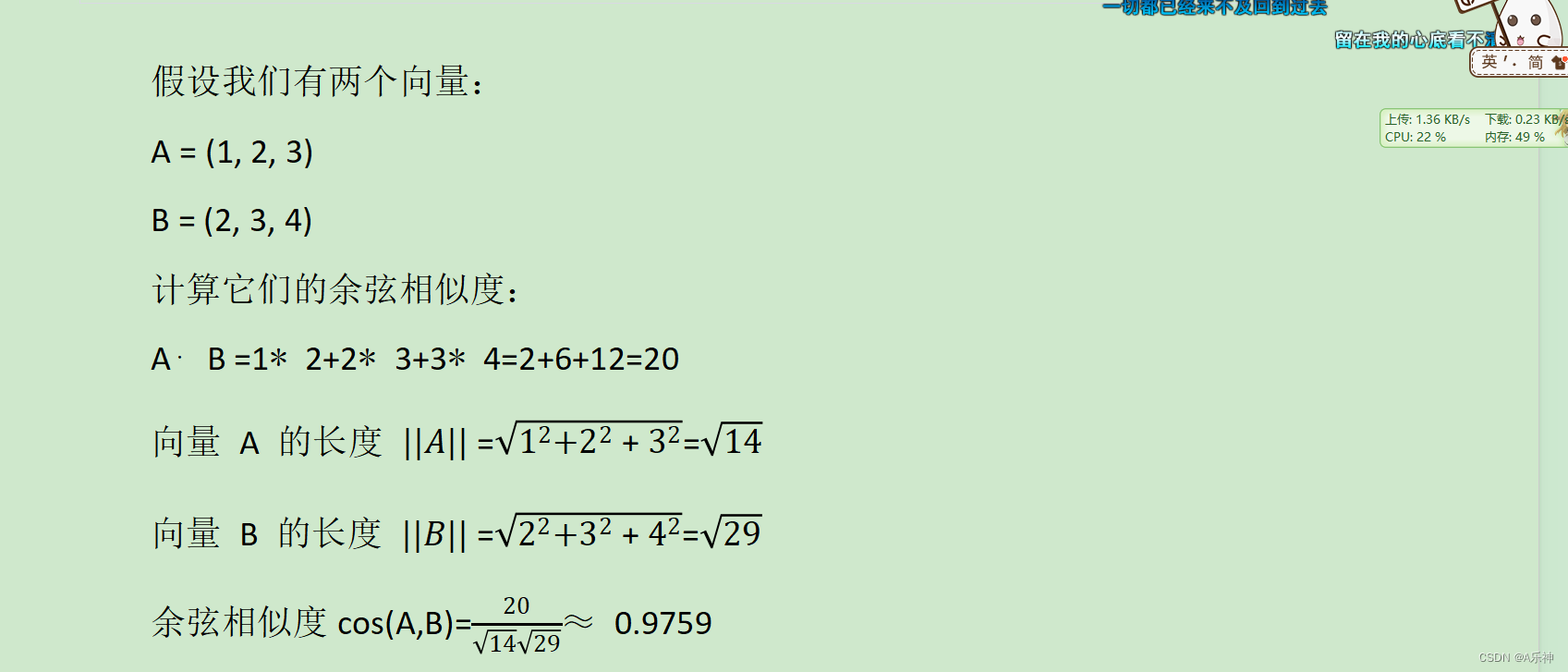
所以,向量 A 和 B 的余弦相似度大约是 0.9759,表示它们在方向上非常接近。
下图也是个例子只不过他是模拟生产的,是我从b站上截个图拿的觉得讲的不错。经过计算Alice和用户1相似度极高,所以Alice物品5可以是代号3

缺陷以及和皮尔森系数对比
余弦相似度在计算机系统推荐开发中被广泛使用,特别是在处理文本数据和用户偏好时。尽管它有很多优点,但也存在一些局限性。以下是余弦相似度的一些缺点,特别是当与皮尔森相关系数相比较时:
不考虑评分的大小:
余弦相似度主要关注向量的方向而不是大小。这意味着它可能会忽略评分的规模差异。例如,如果一个用户对所有项目都给出很高的评分,而另一个用户对相同的项目给出较低的评分,即使他们的兴趣相似,余弦相似度也可能显示他们不相似。
相比之下,皮尔森相关系数会考虑用户的评分偏差,因此在处理不同用户的评分习惯时更加有效。
对稀疏数据以及冷启动问题:
在推荐系统中,用户-物品交互矩阵通常是稀疏的,而余弦相似度在处理稀疏数据时可能不够有效,因为它依赖于非零项的存在。余弦相似度在处理新用户或新物品(即冷启动问题)时面临挑战,因为缺乏足够的数据来计算准确的相似度。
皮尔森相关系数在处理稀疏数据时可能稍微强一些,因为它通过考虑用户的整体评分趋势来减轻这一问题。皮尔森相关系数同样受到冷启动问题的影响,但由于考虑了用户评分的平均值,可能在某些情况下更能处理新用户的推荐。
总结
如果想看皮尔森相关系数的请看我的下片文章,在我的算法区,叫 推荐系统算法 协同过滤算法详解(二)皮尔森相关系数
这是链接不知道能否使用,不行就直接在我的博客搜索
推荐系统算法 协同过滤算法详解(二)皮尔森相关系数-CSDN博客
------------------------------------------与正文内容无关------------------------------------
如果觉的文章写对各位读者老爷们有帮助的话,麻烦点赞加关注呗!作者在这拜谢了!
混口饭吃了!如果你需要Java 、Python毕设、商务合作、技术交流、就业指导、技术支持度过试用期。请在关注私信我,本人看到一定马上回复!

