
- 1后端开发有哪几种语言? - 易智编译EaseEditing_优采平台产品的后端开发语言是哪种
- 2毕业一年后,他转行软件测试成功拿到9.5K薪资,直言互联网行业真香_年后返岗学软件拿高薪
- 3Java基础知识解析:从入门到精通_java从入门到精通
- 4Navicat 连接虚拟机MySQL_navicat连接vmware上的mysql
- 5Home Assistant集成外部MQTT服务_configuration.yaml 找不到 mqtt
- 6AI绘画免费软件哪个好?宝藏AI绘画工具分享
- 7spark运行报错
- 8红蓝攻防基础-认识红蓝紫,初步学习网络安全属于那个队?
- 962、服务攻防——框架安全&CVE复现&Spring&Struts&Laravel&Thinkphp
- 10linux常用命令vim
KITTI 3D目标检测数据集解析(完整版)_kitti数据集
赞
踩
1. KITTI数据集概述
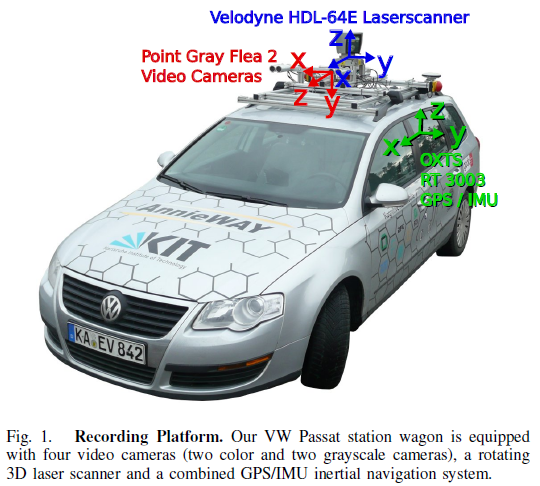
1.1 传感器配置
由于彩色相机成像过程中的拜耳阵列(Bayer Pattern)插值处理过程,彩色图像分辨率较低,而且对于光照敏感性不高,所以采集车配备了两组双目相机,一组灰度的,一组彩色的。个人猜测为了增加相机的水平视场角,每个相机镜头前又各安装了一个光学镜头。
| 传感器类型 | 详细信息 | ||
|---|---|---|---|
| 灰度相机 | 2台140像素的PointGray Flea2灰度相机, FL2-14S3M-C | ||
| 彩色相机 | 2台140万像素PointGray Flea2彩色相机, FL2-14S3C-C | ||
| 光学镜头 | 4个Edmund光学镜头,焦距4mm,90°水平孔径,35°垂直孔径角 | ||
| 激光雷达 | 1台Velodyne HDL-64E激光,扫描频率10Hz,64线,0.09°角度分辨率,2cm探测精度,每秒130万点数,探测距离120m | ||
| GPS/IMU惯导系统 | 1个OXTS TR3003惯导,6轴,采集频率100Hz,L1/L2信号波段,0.02m和0.1°的精度 | ||
传感器车身排布如下图所示。

1.2 数据采集
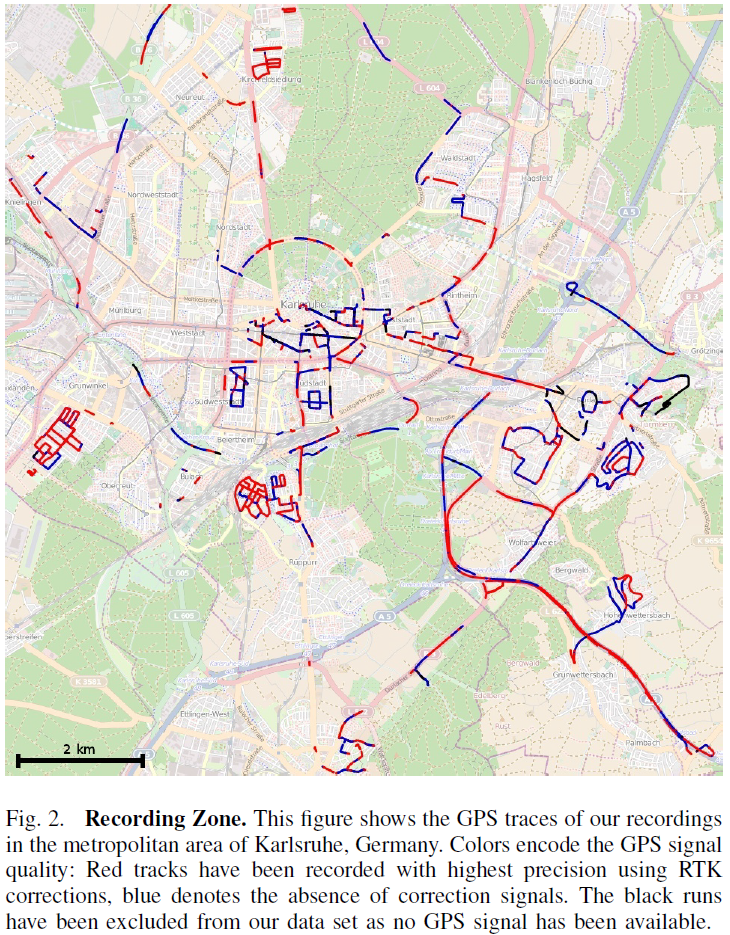
KITTI整个数据集是在德国卡尔斯鲁厄采集的,采集时长6小时。KITTI官网放出的数据大约占采集全部的25%,去除了测试集中相关的数据片段,按场景可以分为“道路”、“城市”、“住宅区”、“校园”和“行人”5类。
采集车形式路径如下图所示,用红蓝黑区分GPS信号的质量,红色是精度最高的,有RTK矫正;蓝色无矫正信号;黑色缺失GPS信号,该部分数据已从数据集中剔除。

- 图像:采用8bit PNG格式保存。裁剪掉了原始图像的引擎盖和天空部分,并且根据相机参数进行了畸变矫正,最终图片为50万像素左右。
- 激光:逆时针旋转,采用浮点数二进制文件保存。保存了激光点 ( x , y , z ) (x,y,z) (x,y,z)坐标和反射率 r r r信息,每一帧平均12万个激光点。
- 图像和激光同步:相机曝光时机是由激光控制的,当激光扫描到正前方(即相机朝向角度)时,会触发相机快门,KITTI会记录激光3个时间戳,旋转起始和结束的时刻,以及触发相机曝光的时刻。
1.3 数据标注
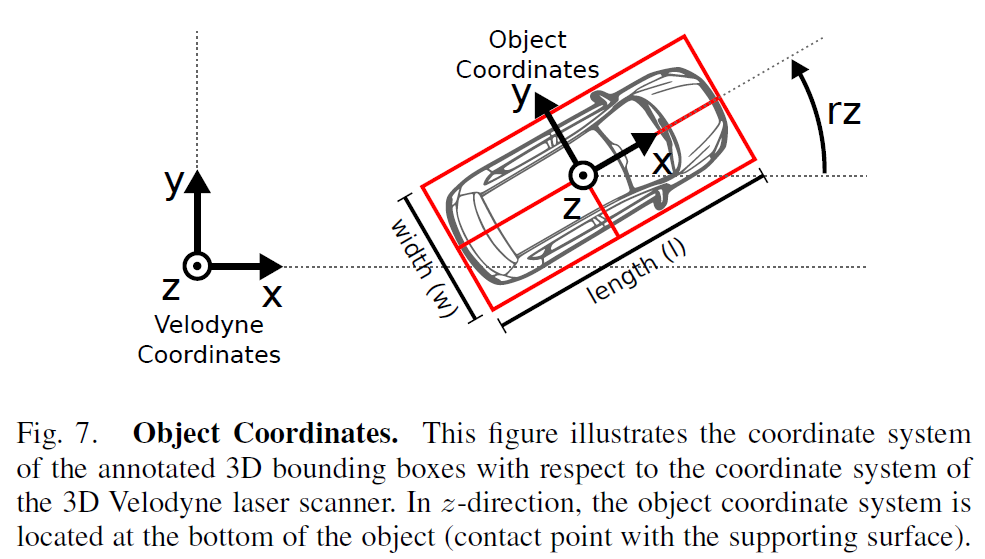
对于相机视野内的每个动态目标,KITTI都提供了基于激光坐标系的3D标注信息,定义了小车、面包车、 卡车、行人、坐着的人、自行车、有轨电车7种目标类型,其他比如拖车、代步车的小众类型目标统一归为“Misc”类别。3D标注信息包括目标尺寸、世界坐标以及偏航角(翻滚角和俯仰角默认等于0)。
1.4 传感器标定
为了尽可能降低时间来带的系统偏差,KITTI每天采集完数据后,都会对所有传感器重新进行一次标定。
传感器同步
使用激光雷达的时间戳作为基准类同步其他传感器。对于相机,通过激光雷达触发相机快门的方式来最小化动态目标带来的偏差。GPS/IMU无法进行同步,但是由于采集频率较高,最大的时间误差也只有5ms。所有传感器的时间戳使用系统时钟记录。
相机标定
4个相机光心均对齐到同一平面上。由于成像存在枕形畸变,畸变矫正图像均从
1392
×
512
1392\times512
1392×512裁剪到
1224
×
370
1224\times370
1224×370像素大小。
激光标定
首先根据左侧灰度相机的位置安装激光雷达,然后基于选择50个手工选点的标定误差进行最优化,并根据KITTI立体视觉榜单Top3方法的性能变化来保证标定的鲁棒性。
2. 3D目标检测数据集概述
2.1 数据下载
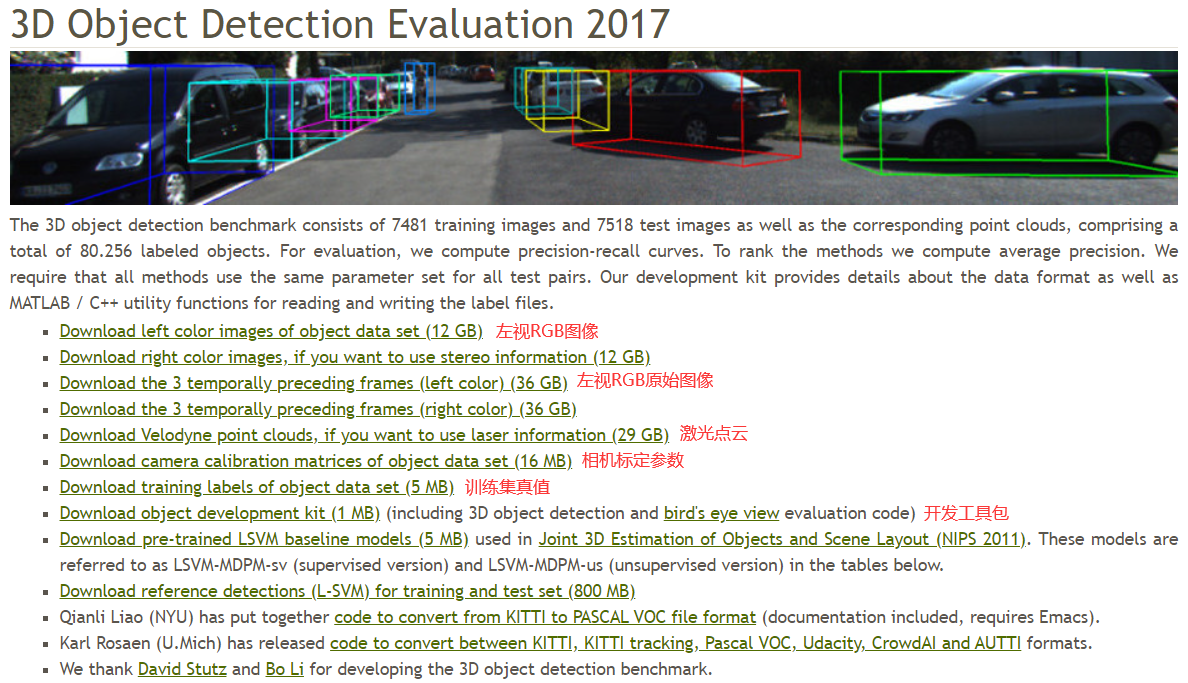
3D目标检测数据集包含7481张训练图片,7518张测试图片,以及相应的点云数据,共包含80256个标注目标。对应的官方下载路径如下(建议复制链接用迅雷下载):
- Download left color images of object data set (12 GB)
- Download the 3 temporally preceding frames (left color) (36 GB) (非必需)
- Download Velodyne point clouds, if you want to use laser information (29 GB)
- Download camera calibration matrices of object data set (16 MB)
- Download training labels of object data set (5 MB)
- Download object development kit (1 MB) (including 3D object detection and bird’s eye view evaluation code)
图片、激光点云、标注真值、标定参数通过图片序号一一对应。
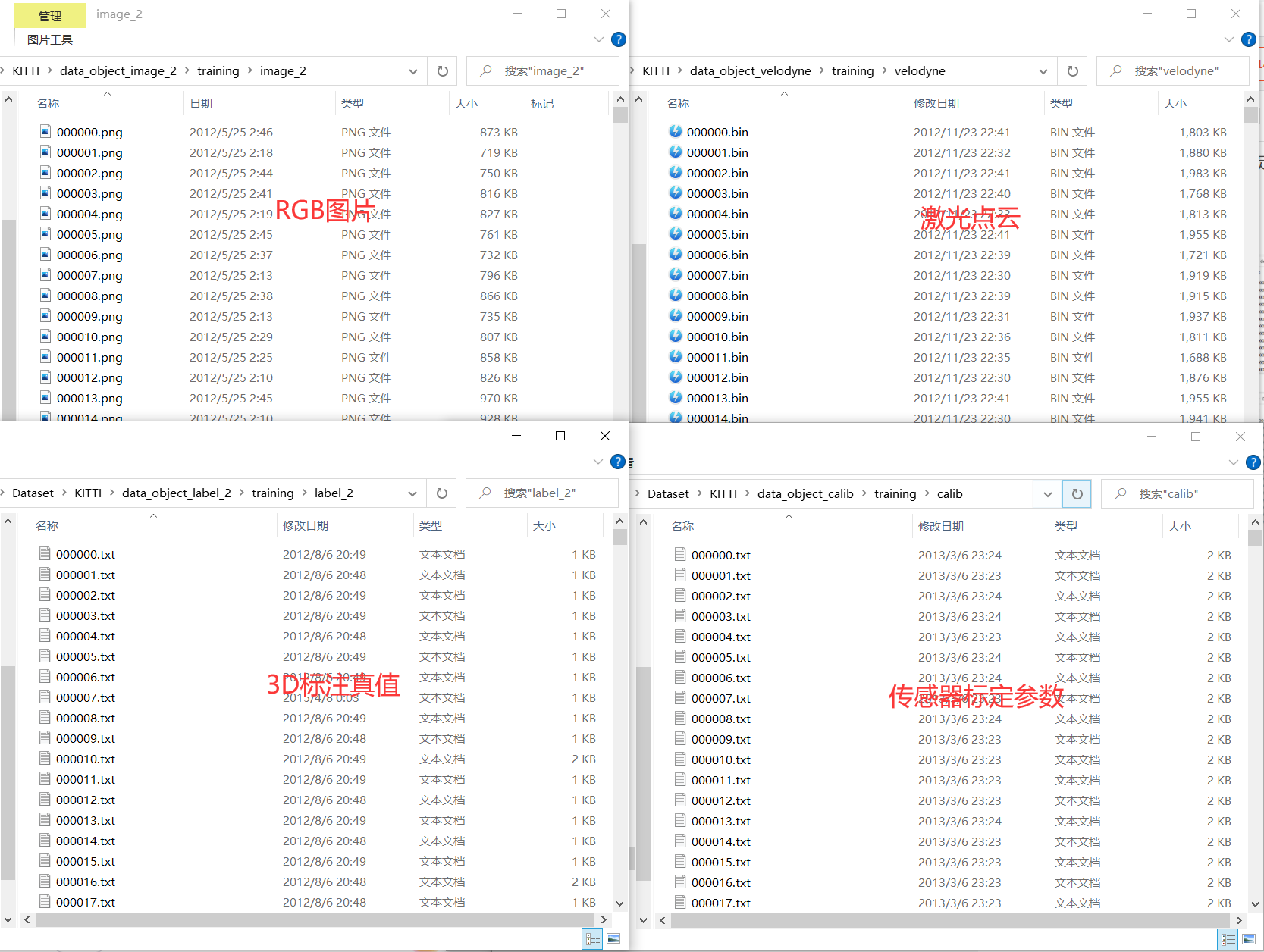
2.2 数据解析
2.2.1 3D框标注
| 字段 | 字段长度 | 单位 | 含义 |
|---|---|---|---|
| Type | 1 | - | 目标类型 |
| Truncated | 1 | - | 目标截断程度:0~1之间的浮点数 表示目标距离图像边界的程度 |
| Occluded | 1 | - | 目标遮挡程度:0~3之间的整数 0:完全可见 1:部分遮挡 2:大部分遮挡 3:未知 |
| Alpha | 1 | 弧度 | 目标观测角: [ − p i , p i ] [-pi, pi] [−pi,pi] |
| Bbox | 4 | 像素 | 目标2D检测框位置:左上顶点和右下顶点的像素坐标 |
| Dimensions | 3 | 米 | 3D目标尺寸:高、宽、长 |
| Location | 3 | 米 | 目标3D框底面中心坐标: ( x , y , z ) (x, y,z) (x,y,z),相机坐标系, |
| Rotation_y | 1 | 弧度 | 目标朝向角: [ − p i , p i ] [-pi, pi] [−pi,pi] |
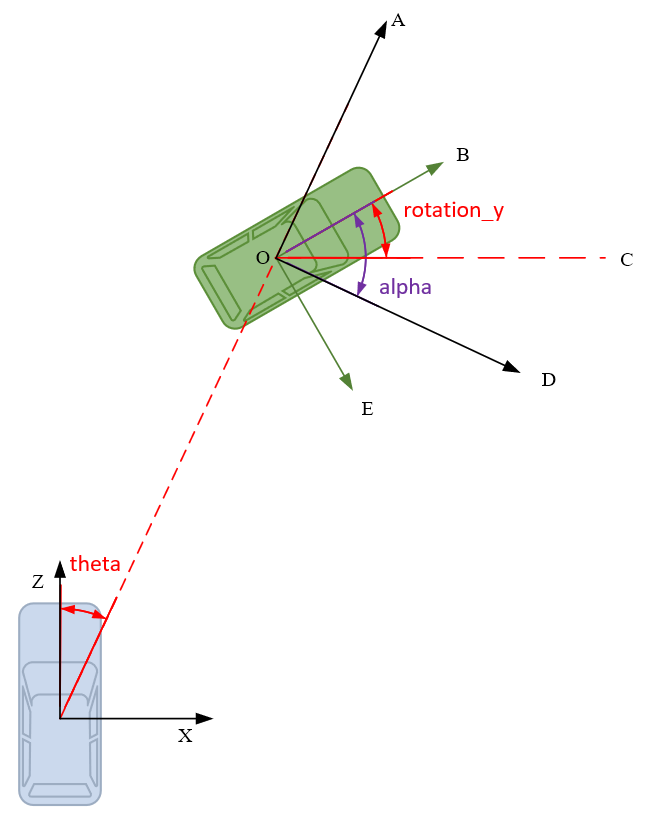
3D框标注信息格式如下,这里说明一下Alpha和Rotaion_y的区别和联系:
- Rotation_y是目标的朝向角,即车头方向和相机 x x x轴正方向的夹角(顺时针方向为正),描述的是目标在现实世界中的朝向,不随目标位置的变化而变化,如图 ∠ B O C \angle BOC ∠BOC所示。
- Alpha是目标观测角,描述的是目标相对于相机视角的朝向,随目标方位角theta变化而变化,如图 ∠ B O D \angle BOD ∠BOD所示。
- Rotation_y和Alpha之间可以相互转换。因为 ∠ A O C = 90 ° − t h e t a \angle AOC=90°-theta ∠AOC=90°−theta,所以有 ∠ A O B = ∠ A O C − ∠ B O C = 90 ° − t h e t a − r o t a i o n _ y \angle AOB=\angle AOC-\angle BOC=90°-theta-rotaion\_y ∠AOB=∠AOC−∠BOC=90°−theta−rotaion_y又因为 ∠ A O B + ∠ B O D = 90 ° \angle AOB+ \angle BOD=90° ∠AOB+∠BOD=90°可得 a l p h a = ∠ B O D = 90 ° − ∠ A O B = t h e t a + r o t a t i o n _ y alpha=\angle BOD=90°-\angle AOB=theta + rotation\_y alpha=∠BOD=90°−∠AOB=theta+rotation_y考虑到rotation_y和alpha都是逆时针方向为负,所以有 − a l p h a = t h e t a − r o t a t i o n _ y -alpha=theta-rotation\_y −alpha=theta−rotation_y即 a l p h a = r o t a t i o n _ y − t h e t a alpha=rotation\_y-theta alpha=rotation_y−theta有兴趣的同学也可以自己用KITTI标签数据验证一下,会发现总是会有零点几度的偏差,估计是KITTI保存有效位数造成的数据损失。
2.2.2 激光点云
激光点云数据采用二进制存储,逐点保存,每个激光点对应4个float数据 ( x , y , z , r ) (x,y,z,r) (x,y,z,r),依次解析即可,python解析代码如下:
import numpy as np import struct def read_lidar_info(file_path): size = os.path.getsize(file_path) point_num = int(size / 16) assert point_num * 16 == size lidar_pt_list = np.zeros((point_num, 4), np.float) with open(file_path, 'rb') as f: for i in range(point_num * 4): data = f.read(4) val = struct.unpack('f', data) row = int(i / 4) col = i % 4 lidar_pt_list[row][col] = val[0] lidar_pt_list = lidar_pt_list.transpose() return lidar_pt_list

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.2.3 标定数据
为了尽可能减少标定的系统误差,KITTI每天都会重新对传感器进行一次标定,因此每张图片都有一个对应的txt标定参数文件,如下图所示。

| 参数名称 | 含义 |
|---|---|
| P0~P3 | 3 × 4 3 \times 4 3×4的相机投影矩阵,0~3分别对应左侧灰度相机、右侧灰度相机、左侧彩色相机、右侧彩色相机 |
| R0_rect | 3 × 3 3 \times 3 3×3的旋转修正矩阵 |
| Tr_velo_to_cam | 3 × 4 3 \times 4 3×4的激光坐标系到Cam 0坐标系的变换矩阵 |
| Tr_imu_to_velo | 3 × 4 3 \times 4 3×4的IMU坐标系到激光坐标系的变换矩阵 |
目标3D框到图像的投影
目标在相机坐标系下的坐标 X = ( x , y , z , 1 ) T X=(x,y,z,1)^T X=(x,y,z,1)T到图像像素坐标系 Y = ( u , v , 1 ) T Y=(u,v,1)^T Y=(u,v,1)T的投影遵循: Y = P r e c t ( i ) X Y=P^{(i)}_{rect}X Y=Prect(i)X激光点云到图像的投影
目标在激光坐标系下的坐标
X
=
(
x
,
y
,
z
,
1
)
T
X=(x,y,z,1)^T
X=(x,y,z,1)T到图像像素坐标系
Y
=
(
u
,
v
,
1
)
T
Y=(u,v,1)^T
Y=(u,v,1)T的投影遵循:
Y
=
P
r
e
c
t
(
i
)
R
r
e
c
t
(
0
)
T
v
e
l
o
c
a
m
X
Y=P^{(i)}_{rect}R^{(0)}_{rect}T^{cam}_{velo}X
Y=Prect(i)Rrect(0)TvelocamX其中
P
r
e
c
t
(
i
)
P^{(i)}_{rect}
Prect(i)对应标定参数的P0~P3,因为这里使用的左侧彩色相机,所以用的是P2投影矩阵。另外,
R
r
e
c
t
(
0
)
R^{(0)}_{rect}
Rrect(0)和
T
v
e
l
o
c
a
m
T^{cam}_{velo}
Tvelocam在标定文件中是
3
×
3
3\times 3
3×3的矩阵,实际使用时需要用0扩充到
4
×
4
4\times4
4×4大小,并赋值
R
r
e
c
t
(
0
)
(
3
,
3
)
=
1
R^{(0)}_{rect}(3, 3)=1
Rrect(0)(3,3)=1,
T
v
e
l
o
c
a
m
(
3
,
3
)
=
1
T^{cam}_{velo}(3,3)=1
Tvelocam(3,3)=1。
最终效果如下:



