
- 1JAVA实现单链表快速排序_java单链表快速排序
- 22018年安徽省机器人大赛单片机与嵌入式系统应用技能竞赛试题(1)_单片机与嵌入式竞赛简答题
- 3Out of Vocabulary处理方法
- 4linux /proc/net/tcp 文件分析_seq_operations
- 5RDP连接Ubuntu远程桌面
- 6Kaggle入门比赛:灾难推文的自然语言处理 详细教程_kaggle自然语言处理入门项目
- 7TS学习笔记_ts笔记
- 8python学习-结构化的文本文件_中文文本结构化实例python
- 9【保姆级教程】如何订阅OnlyFans?如何在OnlyFans上面支付?OnlyFans虚拟卡订阅教程_onlyfuns
- 10【C2】【字符串】【入门】删除单词后缀_除该描述 给定一个单词,如果该单词以er、ly或者ing后缀结尾, 则删除该后缀(题目保
潞晨科技尤洋:中小企业同样追求大模型,但最先进AI训练成本还是太高 | MEET 2023...
赞
踩
明敏 整理自 MEET2023
量子位 | 公众号 QbitAI
AI模型急速增大与硬件算力缓慢增长的矛盾,已愈加尖锐。
尤其在AI落地进入深水区的背景下,如何降本增效成为了行业热点议题。
但具体到实际动作,该怎么做?
在MEET 2023智能未来大会现场,潞晨科技创始人、新加坡国立大学校长青年教授尤洋指明了一个方向:
未来,我们迫切需要一个可扩展性的高效计算基础设施。
而且,潞晨科技已经用实际行动给出论证,它们推出的Colossal-AI系统,在过去一年里迅速成长为开源加速方案中的明星项目,GitHub上揽星超过7k。

为了完整体现尤洋的分享及思考,在不改变原意的基础上,量子位对他的演讲内容进行了编辑整理。
关于MEET 智能未来大会:MEET大会是由量子位主办的智能科技领域顶级商业峰会,致力于探讨前沿科技技术的落地与行业应用。今年共有数十家主流媒体及直播平台报道直播了MEET2023大会,吸引了超过300万行业用户线上参会,全网总曝光量累积超过2000万。
演讲要点
AI落地正面临一个大问题:大模型/最先进AI技术训练成本太高了。
我们迫切需要一个可扩展性的高效计算基础设施。
Colossal-AI由三部分组成:高效内存管理系统、自动N维并行技术、大规模优化技术
Colossal-AI积极融入全球生态系统,为PyTorch、Hugging Face、PyTorch Lighting提供支持
(以下为尤洋演讲全文)
AI大模型落地成本太高了
我今天分享的主题为《Colossal-AI:一种全新深度学习系统,面向未来各种大模型应用场景的低成本落地》。
在此先简单介绍一下Colossal-AI的团队成员。
我自己是新加坡国立大学校长青年教授,在加州大学伯克利分校获得博士学位,并很荣幸获得了IEEE Early Career Excellence Award。

另一位主要成员是James Demmel教授,他是UC伯克利前计算机系主任和EECS院长,也是UC伯克利杰出教授,美国科学院、工程院院士。
还有几位是负责Colossal-AI开发推广的朋友(如图所示)。

下面进入正题——
Colossal-AI到底想解决什么样的问题?
可以先来看看这张图。
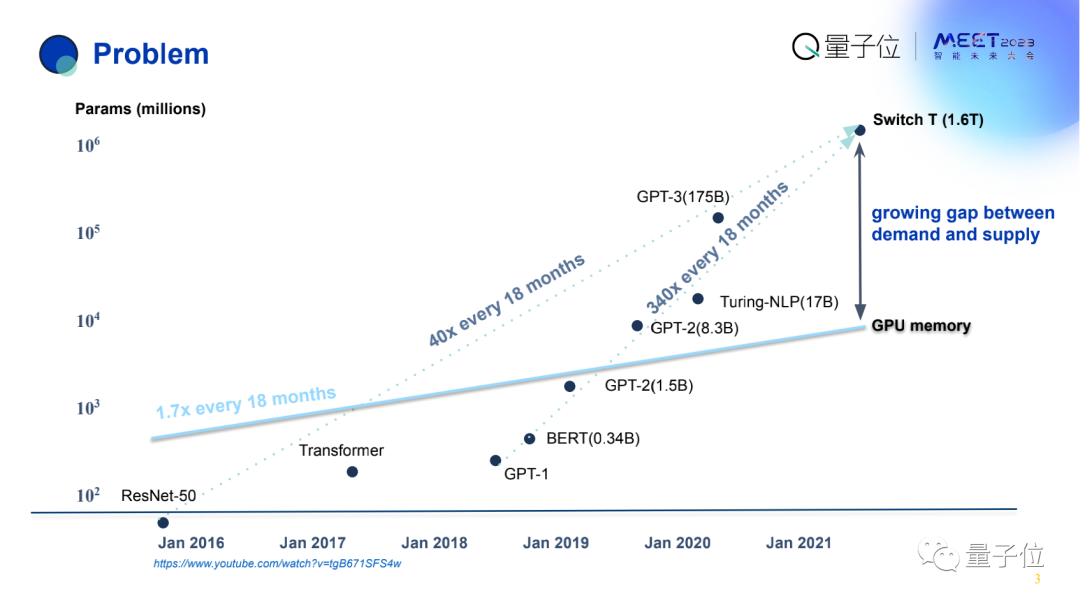
横坐标为时间,纵坐标为AI模型的参数量。
图中有3条线,第一条从2016-2021年,模型大小从200多万增长到了1.6万亿,翻了成千上万倍,量化起来是每18个月翻40倍。
如果从2018年算起就更夸张了,每18个月翻了340倍。
与之形成鲜明对比的是,GPU显存增长相对有限,每18个月只翻了1.7倍。
在未来,训练AI大模型是一种必然。
但目前如OpenAI等顶尖AI公司,他们训练AI的时候用了成百上千个GPU才能完成这件事。
核心在于:
第一模型计算量太大
第二参数量很大,导致显存需求也很大
即使用模型微调或推理,也需要几千GB的内存,这就是今天要面对的问题。
未来,我们迫切需要一个可扩展性的高效计算基础设施。
所以我们就专注这一点,打造了Colossal-AI这个系统。
另外,中小型企业的需求也十分重要。比如GPT-2、Transformer,都是谷歌、微软等科技巨头的产物,中小型企业到底是什么情况?
右边这张图可以说明情况。
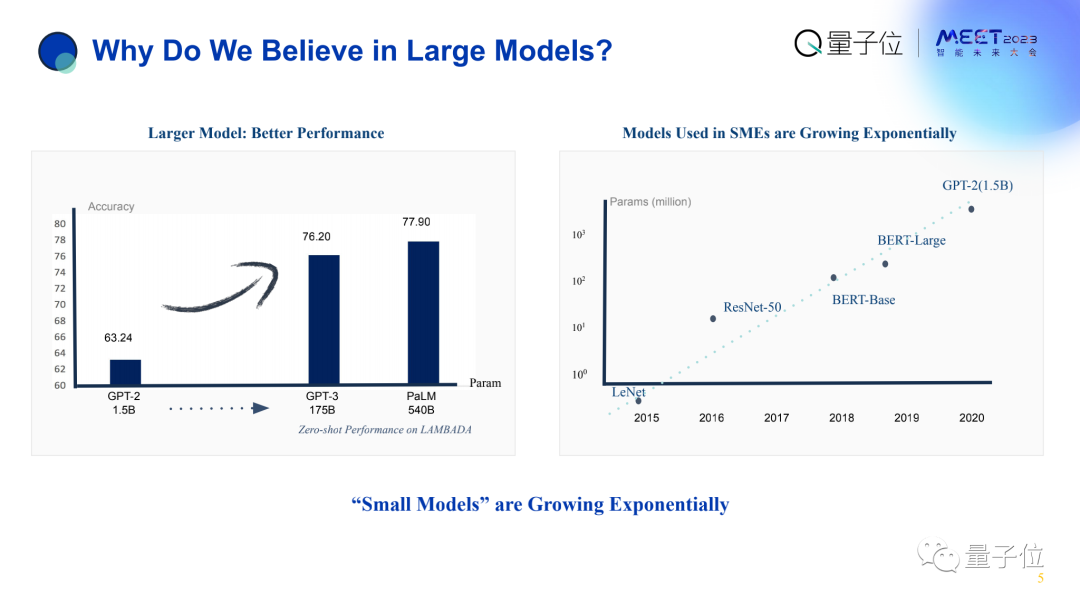
横坐标是时间,纵坐标是AI模型的参数量。
从这里可以看出,中小型企业使用的模型量也呈指数级上升。
这有一个很有意思的现象,不论企业大小,大家普遍都在把模型做得更大,核心的原因在于模型更大性能可以更好。
如上左图表明,横坐标体现了模型参数不断增大,纵坐标则是性能表现。
总结起来,AI在落地方面正面临着一个很大的问题,大模型或者是最先进的AI技术训练成本太高了。
Stability AI每年光计算就需要花费约2000万美元,这显然是小公司、科研单位难以承受的。
即使只拿大模型去做微调和推理,本地应用的挑战也很大,需要好几千GB的内存。
最终,想把大模型部署到生产线上,如果一个企业或者单位从零开始自己做,需要的人力为70人左右,而在欧美地区光是养活70个人,成本就需要2000万美金。
所以说大模型的训练成本提高、和自身复杂性使得整个生态变得更加困难。

何为Colossal-AI?
由此,我们打造了Colossal-AI整个系统。
它主要包括3个部分:
高效内存管理系统(因为大模型本质上还是太吃内存,无法直接容纳)
自动N维并行技术,提升计算效率
大规模优化技术提升扩展性
从三方面把AI模型训练部署的性能提到最高。
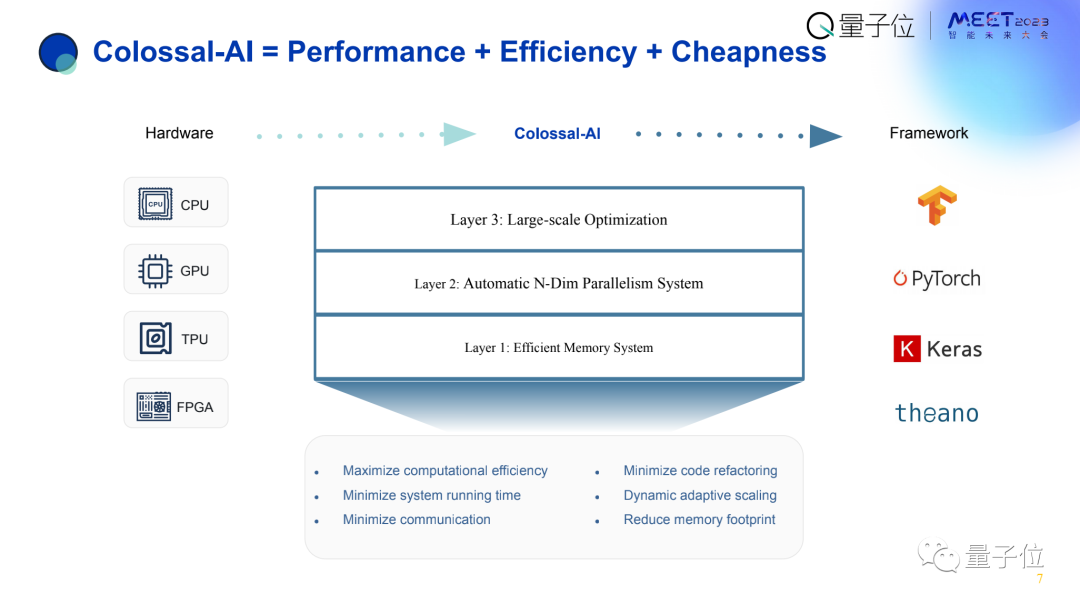
目前来看,目标是希望用户只需要在自己的单机笔记本上写好代码,通过Colossal-AI能够无缝地部署到云端或者是超级计算机上。
我来简单谈一下背景。
目前训练大模型大概有3种并行方式:数据并行、张量并行以及流水线并行。
数据并行是指,比如有1万个数据表把它分到10台机器上,每台机器获得1000个数据。
张量并行,是在层内划分数据。
流水线并行,是在层与层之间去划分数据。
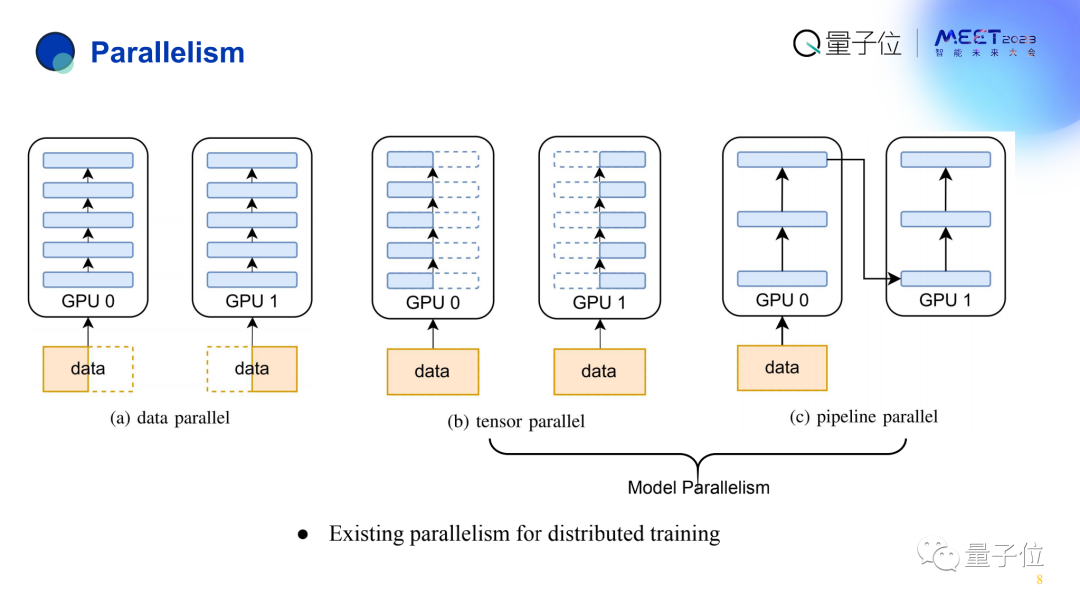
对于我们而言,之前在数据并行上已经做了很多工作。
比如说,我们设计的LARS、LAMB方法,先后帮助腾讯、索尼、谷歌等公司把模型训练时间从1小时缩短到1分钟,我们的LAMB方法,也帮助谷歌把BERT训练时间从3天缩短到76分钟。
Colossal-AI的解决方案,首先是支持了上述主流并行方案,然后我们创新地打造了2D张量并行、2.5D张量并行以及3D张量并行,以及提出了数据序列并行,还提供了降低显存消耗的异构内存管理和大规模并行优化,把它们整合起来提供一套自动并行的解决方案。

其实AI工程师、研究员不需要理解背后的技术细节,只需要提供模型信息和计算资源,就可以自动地把计算资源能力发挥到最大化,同时完成虚拟模型训练和自动部署,轻松低成本应用AI大模型。
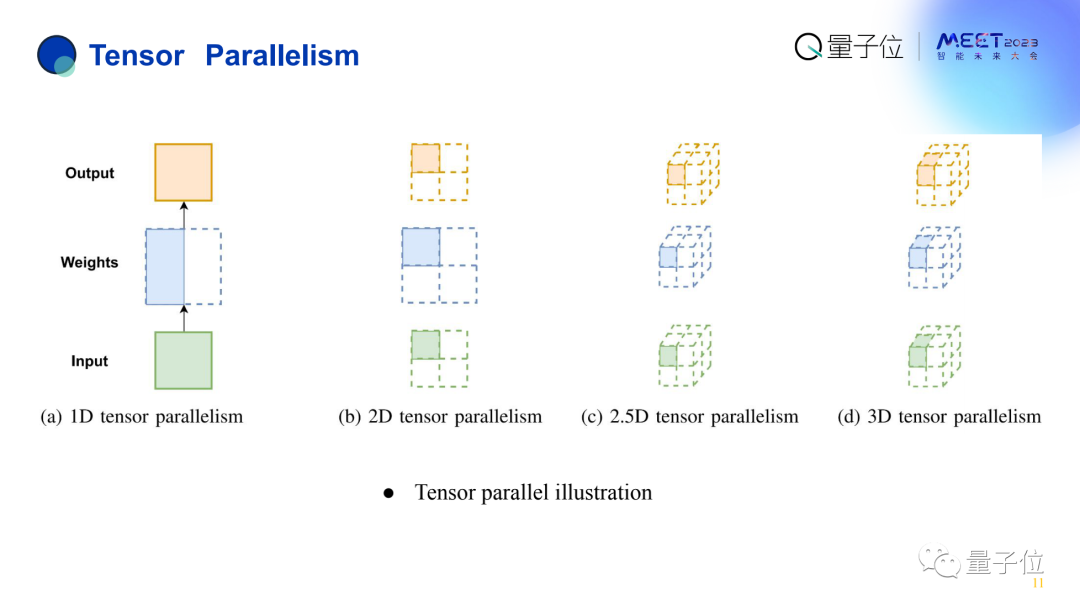
在此简单讲一下张量并行。
一维张量并行是最简单的层内划分,二维张量并行也是层内划分,但逻辑上把这些数据移动按二维的方式进行分布。
这样的好处是,通过我们精心的设计算法,可以使得传输数据通信的时候,每一个机器只用和同维度的机器打交道就行了。
原本一维情况下,1台机器需要和1万台机器打交道,现在只需要跟数百个机器打交道。
三维的效果更明显,在100万台机器的情况下,每台机器都需要跟其他每一台机器打交道,即1000000-1台。但现在只需要100万的根号3次方,即100个机器打交道就行了,进一步降低了它的通信复杂度。
这张图可以展示二维张量并行和三维张量并行以及跟其他并行方式的区别。
与此同时,我们也提出了数据序列并行。
原因在于,未来真实AI运行中,往往是长序列数据。这些长数据非常棘手,为什么?
因为本身模型应用已经很大了,如果在蛋白质折叠或者5G、元宇宙场景,长数据再来增加内存开销的话,会直接导致系统崩溃。
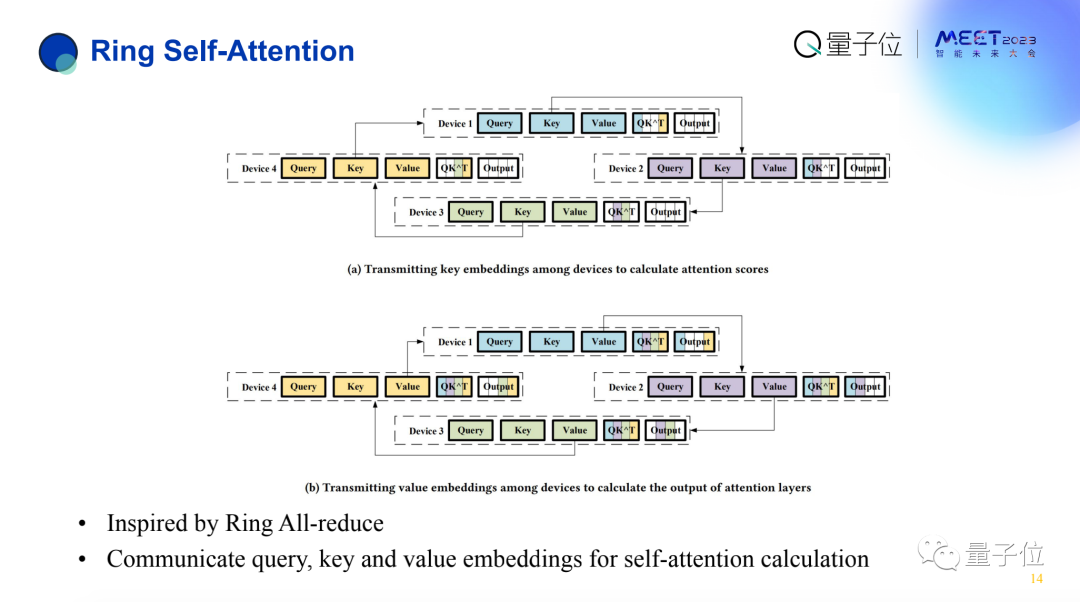
为了减缓系统的崩溃,我们引入了数据序列并行,主要有两个点:
对MLP层比较友好。因为它本身就是相互独立的。更麻烦的是要在Transformer中算Attention score的时候,需要所有token。
这里有一个问题是,如果用比较简单的方法,每个机器需要跟所有机器打交道,显然得不偿失。
比如有p个GPU,通信代价就变成了p的平方,100个GPU通信需要每步循环1万个消息,不划算。
由此,我们设计了环状self-attention分析算法,核心思路是每次从左手邻居获得一个k,通过p-1次就可以把这件事解决,将通信次数从1万降低到99。
同时也提供自动并行技术。
自动并行的作用,使得用户只需把模型写好,不需要知道并行计算分布式系统下层的各种软件基础设施。
因为这些东西的学习负担太高了,用户只需告诉我们有多少个机器、多少资源、训练多少模型,就能自动把模型划分到它的计算资源上,从而帮助完成训练、部署。

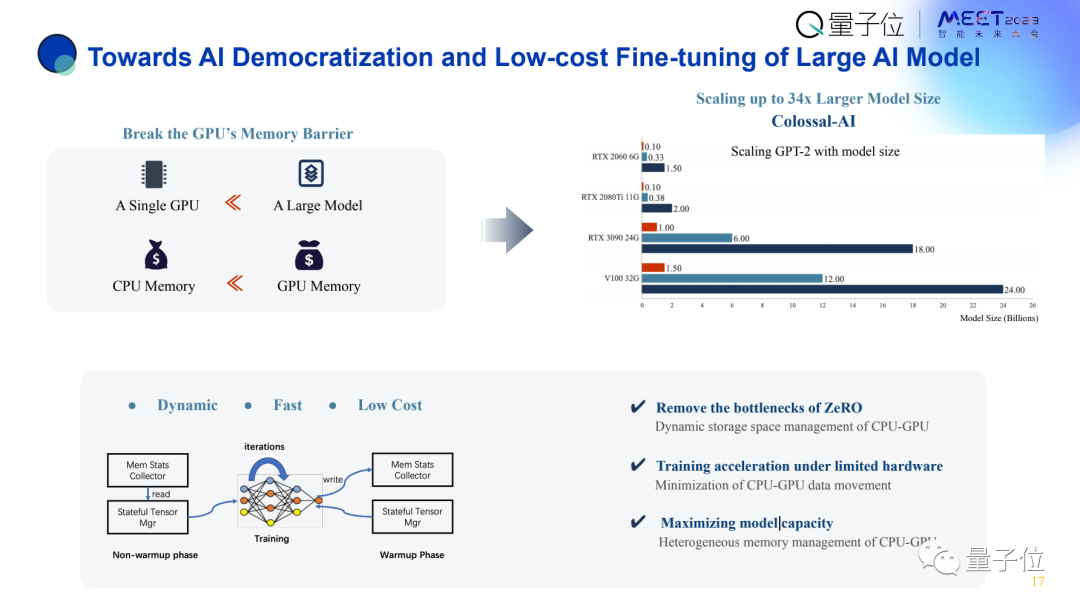
另一个方面是内存优化技术。
众所周知GPU内存是非常有限的,假如只用GPU内存,比如说用PyTorch baseline训练GPT-3,至少需要几百个GPU才能完成。
毕竟每个GPU都只有16/40/80G内存。
所以我们需要充分利用各个层级的内存。
GPU内存放不下,就把部分数据迁移到CPU上,CPU放不下再放到NVMe硬盘上。
但要知道,数据移动开销是远大于计算的,也就是GPU和CPU之间的数据传输,远慢于CPU和NVMe之间的数据移动。所以要如何尽可能多地把数据移出CPU、GPU,同时能够减少移动量。
这就需要动态的智能系统,所以我们打造了Colossal-AI系统有4个模块去统计tensor信息、确定tensor状态,可以实时移动合适的tensor。
总之,通过这种方式可以大幅提升效率。
这有一个比较,右上角图中红色代表普通PyTorch。可以看出在6G内存的情况下,用PyTorch只能训练1亿参数,但是用Colossal-AI可以训练15亿参数,扩大了15倍。
相同硬件下,在GPT-2上的效果也更好,使用PyTorch本来只能训练1亿参数,通过Colossal-AI可以扩大到120亿。

加速效果还可以比Megatron-LM更快。

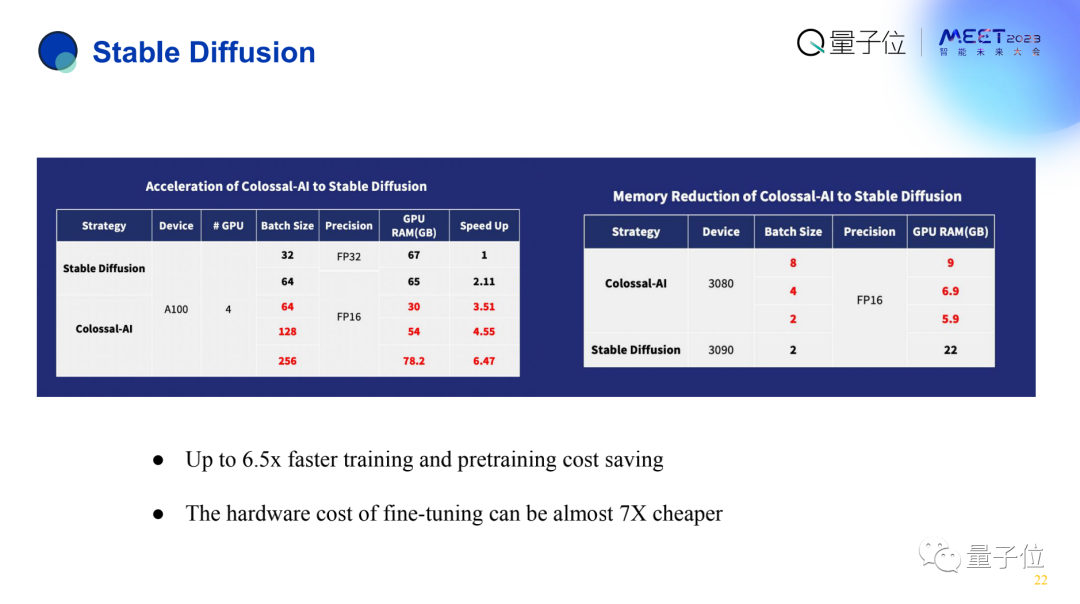
像Stable Diffusion这样的新模型上,Colossal-AI也能取得6.5倍加速,并可以把成本降到原本的1/7。
Colossal-AI也支持推理,比如在一台服务器上可以很好把1750亿参数的OPT部署起来。

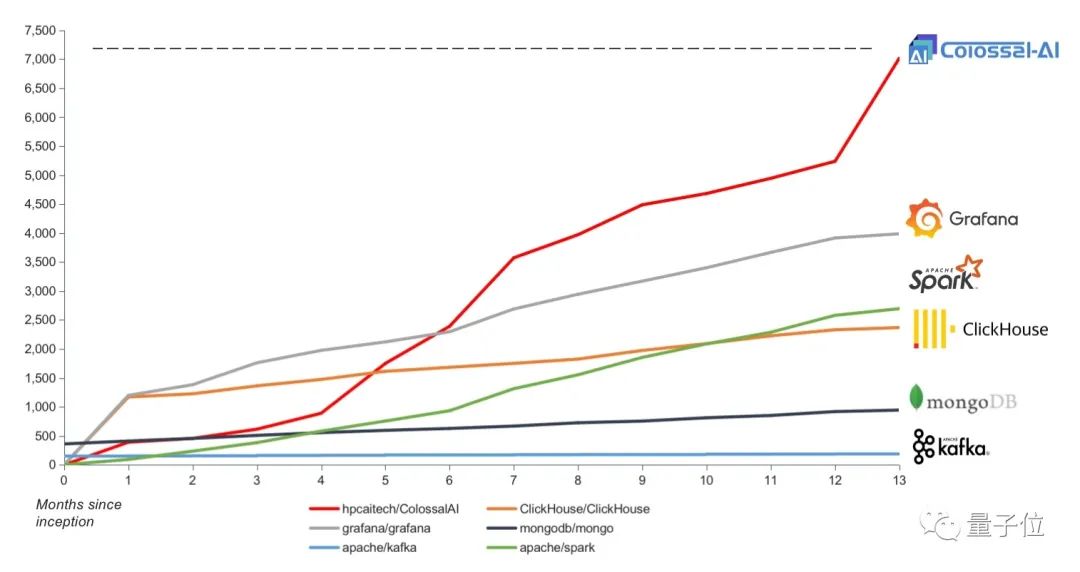
目前,Colossal-AI在开源后的增长情况还是非常好的,和之前比较成功的开源软件Grafana、Spark等相比,至少在前13个月Colossal-AI的增长速度是远超它们的,目前达到7k颗GitHub Star。
Colossal-AI的用户也是遍布于全球的,包括中国、美国、欧洲、印度、东南亚等。
与此同时,Colossal-AI还在积极融入全球生态系统。
比如目前世界上第一大AI生态系统是Facebook的PyTorch,它最好的模型是OPT,在OPT的官网上直接指向了Colossal-AI。
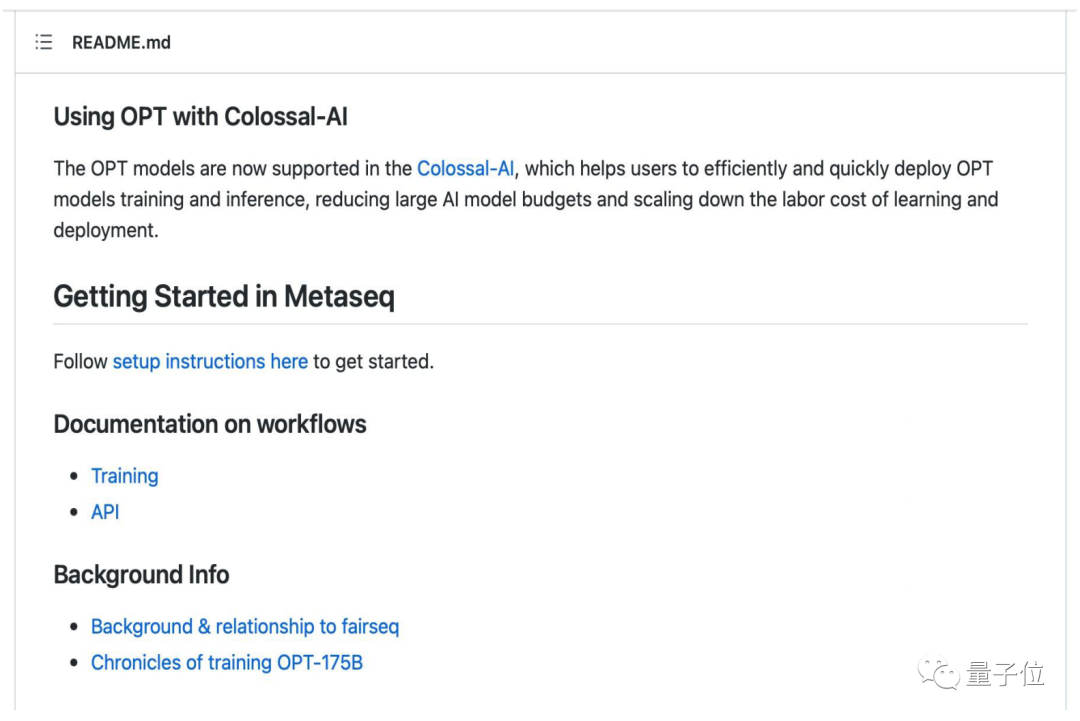
第二大生态系统Hugging Face也找我们做了优化。
第三大AI生态系统PyTorch Lighting依赖于Colossal-AI,他们的用户能直接应用Colossal-AI提升效率。
如下目前开源社区上Colossal-AI的用户,都是一些国内外大型企业。

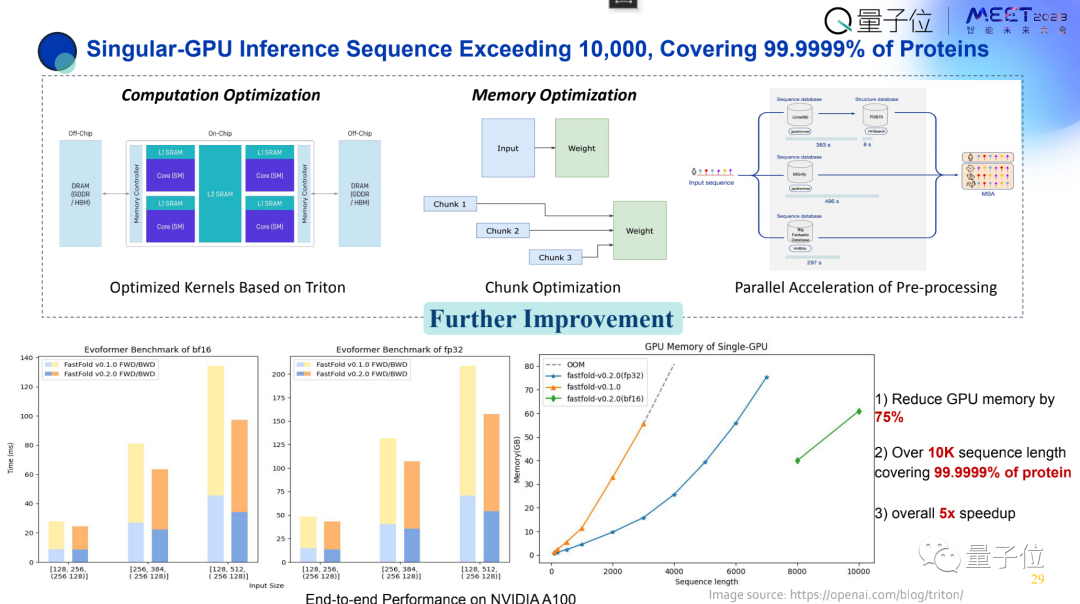
Colossal-AI还有很多具体行业的落地应用,比如蛋白质折叠,可以大幅提升效率。
Colossal-AI现已对外开源,代码公开免费,可以自由使用。
如果有问题,可以访问Colossal-AI的GitHub主页进行提问,我们免费提供技术咨询,也有微信群可以交流讨论。

我今天的演讲就到这里,有问题也可以随时联系我交流,感谢大家关注。
(最后,如果想回看大会全程,请点击阅读原文)

