
热门标签
热门文章
- 1windows下启动rabbitmq_windows启动rabbitmq
- 2使用GitHub制作一个高逼格的在线简历_在线简历word模板 github
- 3C++(运算符重载+赋值拷贝函数+日期类的书写)
- 4如何在Linux环境下安装Jenkins_linux安装jenkins
- 5mysql复制sql语句_MySQL复制表结构 表数据sql语句总结
- 6Milvus入门手册1.0_milvus中文文档
- 7Android11 open failed: EACCES (Permission denied)的解决方法_android open failed: eacces (permission denied)
- 8图论的基本知识
- 9数据结构之二叉搜索树底层实现洞若观火!
- 10GPT-4 API平替?性能媲美同时成本降低98%,斯坦福提出FrugalGPT,研究却惹争议
当前位置: article > 正文
用gbm包来提升决策树能力_gbm包怎么处理因子型变量
作者:IT小白 | 2024-04-21 23:31:14
赞
踩
gbm包怎么处理因子型变量
中国有句老话:三个臭皮匠,顶个诸葛亮。这个说法至少在变形金刚中得到了体现,没有组合之前的大力神只是五个可以被柱子哥随手秒掉工地苦力。但组合之后却是威力大增。在机器学习领域也是如此,一堆能力一般的“弱学习器”也能组合成一个“强学习器”。前篇文章提到的随机森林就是一种组合学习的方法,本文要说的是另一类组合金刚:提升方法(Boosting)。提升方法是一大类集成分类学习的统称。它用不同的权重将基学习器进行线性组合,使表现优秀的学习器得到重用。在R语言中gbm包就是用来实现一般提升方法的扩展包。根据基学习器、损失函数和优化方法的不同,提升方法也有各种不同的形式。
自适应提升方法AdaBoost
它是一种传统而重要的Boost算法,在学习时为每一个样本赋上一个权重,初始时各样本权重一样。在每一步训练后,增加错误学习样本的权重,这使得某些样本的重要性凸显出来,在进行了N次迭代后,将会得到N个简单的学习器。最后将它们组合起来得到一个最终的模型。
梯度提升方法Gradient Boosting
梯度提升算法初看起来不是很好理解,但我们和线性回归加以类比就容易了。回忆一下线性回归是希望找到一组参数使得残差最小化。如果只用一次项来解释二次曲线一定会有大量残差留下来,此时就可以用二次项来继续解释残差,所以可在模型中加入这个二次项。
同样的,梯度提升是先根据初始模型计算伪残差,之后建立一个基学习器来解释伪残差,该基学习器是在梯度方向上减少残差。再将基学习器乘上权重系数(学习速率)和原来的模型进行线性组合形成新的模型。这样反复迭代就可以找到一个使损失函数的期望达到最小的模型。在训练基学习器时可以使用再抽样方法,此时就称之为 随机梯度提升算法stochastic gradient boosting 。
在gbm包中,采用的是决策树作为基学习器,重要的参数设置如下:
下面我们用mlbench包中的数据集来看一下gbm包的使用。其中响应变量为diabetes,即病人的糖尿病诊断是阳性还是阴性。
Accuracy Kappa Accuracy SD Kappa SD
0.78 0.504 0.0357 0.0702
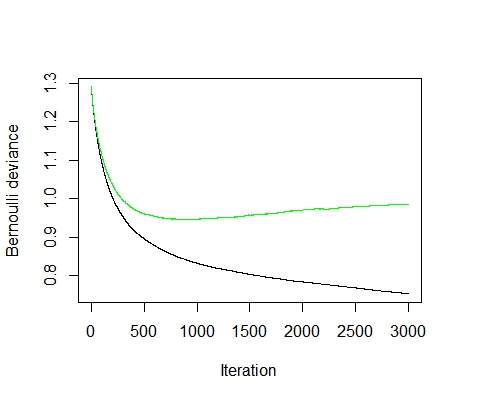
观察到gbm迭代到800次左右最优,得到的预测正确率为0.78,这个比随机森林的正确率还要略高一些。 提升算法继承了单一决策树的优点,例如:能处理缺失数据,对于噪声数据不敏感,但又摒弃了它的缺点,使之能拟合复杂的非线性关系,精确度大为提高。通过控制迭代次数能控制过度拟合,计算速度快。但由于它是顺序计算的,所以不好进行分布式计算。
参考资料:
http://cran.r-project.org/web/packages/gbm/vignettes/gbm.pdf
http://en.wikipedia.org/wiki/Gradient_boosting
http://www.cnblogs.com/LeftNotEasy/archive/2011/03/07/random-forest-and-gbdt.html
自适应提升方法AdaBoost
它是一种传统而重要的Boost算法,在学习时为每一个样本赋上一个权重,初始时各样本权重一样。在每一步训练后,增加错误学习样本的权重,这使得某些样本的重要性凸显出来,在进行了N次迭代后,将会得到N个简单的学习器。最后将它们组合起来得到一个最终的模型。
梯度提升方法Gradient Boosting
梯度提升算法初看起来不是很好理解,但我们和线性回归加以类比就容易了。回忆一下线性回归是希望找到一组参数使得残差最小化。如果只用一次项来解释二次曲线一定会有大量残差留下来,此时就可以用二次项来继续解释残差,所以可在模型中加入这个二次项。
同样的,梯度提升是先根据初始模型计算伪残差,之后建立一个基学习器来解释伪残差,该基学习器是在梯度方向上减少残差。再将基学习器乘上权重系数(学习速率)和原来的模型进行线性组合形成新的模型。这样反复迭代就可以找到一个使损失函数的期望达到最小的模型。在训练基学习器时可以使用再抽样方法,此时就称之为 随机梯度提升算法stochastic gradient boosting 。
在gbm包中,采用的是决策树作为基学习器,重要的参数设置如下:
- 损失函数的形式(distribution)
- 迭代次数(n.trees)
- 学习速率(shrinkage)
- 再抽样比率(bag.fraction)
- 决策树的深度(interaction.depth)
下面我们用mlbench包中的数据集来看一下gbm包的使用。其中响应变量为diabetes,即病人的糖尿病诊断是阳性还是阴性。
# 加载包和数据
library(gbm)
data(PimaIndiansDiabetes2,package='mlbench')
# 将响应变量转为0-1格式
data <- PimaIndiansDiabetes2
data$diabetes <- as.numeric(data$diabetes)
data <- transform(data,diabetes=diabetes-1)
# 使用gbm函数建模
model <- gbm(diabetes~.,data=data,shrinkage=0.01,
distribution='bernoulli',cv.folds=5,
n.trees=3000,verbose=F)
# 用交叉检验确定最佳迭代次数
best.iter <- gbm.perf(model,method='cv')
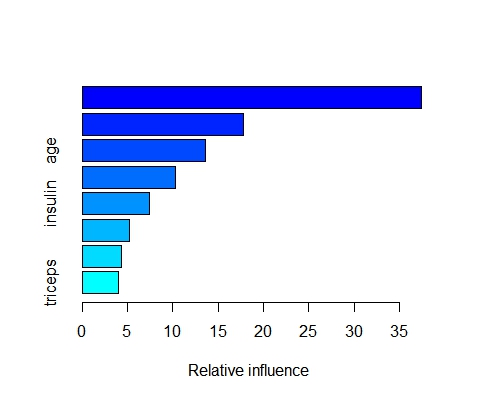
# 观察各解释变量的重要程度
summary(model,best.iter)
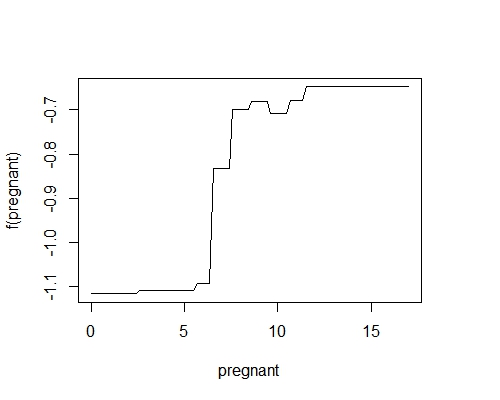
# 变量的边际效应
plot.gbm(model,1,best.iter)
# 用caret包观察预测精度
library(caret)
data <- PimaIndiansDiabetes2
fitControl <- trainControl(method = "cv", number = 5,returnResamp = "all")
model2 <- train(diabetes~., data=data,method='gbm',distribution='bernoulli',trControl = fitControl,verbose=F,tuneGrid = data.frame(.n.trees=best.iter,.shrinkage=0.01,.interaction.depth=1))
model2Accuracy Kappa Accuracy SD Kappa SD
0.78 0.504 0.0357 0.0702
观察到gbm迭代到800次左右最优,得到的预测正确率为0.78,这个比随机森林的正确率还要略高一些。 提升算法继承了单一决策树的优点,例如:能处理缺失数据,对于噪声数据不敏感,但又摒弃了它的缺点,使之能拟合复杂的非线性关系,精确度大为提高。通过控制迭代次数能控制过度拟合,计算速度快。但由于它是顺序计算的,所以不好进行分布式计算。
参考资料:
http://cran.r-project.org/web/packages/gbm/vignettes/gbm.pdf
http://en.wikipedia.org/wiki/Gradient_boosting
http://www.cnblogs.com/LeftNotEasy/archive/2011/03/07/random-forest-and-gbdt.html
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/465688
推荐阅读
相关标签

