
- 1大厂面试八股文——计算机网络_计算机面试八股
- 2手把手教你从0到1搭建web ui自动化框架(python3+selenium3+pytest)_ui自动化框架python+pytest
- 3Python3-selenium自动化测试框架,结合HTMLTestRunner测试报告!_python selenium3 脚手架 开源
- 4fanuc机器人与plc的通讯_FANUC机器人EtherNet/IP通讯
- 5FinClip | 7月做出了一些微不足道的贡献
- 6Cloudflare Workers 付费文档
- 7fanuc机器人与视觉通信_视觉检测(FANUC)与OFFSET补偿方式分类
- 8Redis desktop manager for windows 下载_redis-desktop-manager 下载
- 9Flex debug : Flash player not found_fr_flash:not found
- 10git的忽略规则_gitlab 忽略文件
Windows下安装Hive_windows hive安装
赞
踩
Windows 下安装Hive
一、hive与hadoop的兼容选择
hive官网下载地址:https://archive.apache.org/dist/hive/
hadoop官网下载地址:https://archive.apache.org/dist/hadoop/common/
以hive-2.3.5为例
1、下载apache-hive-2.3.5-src.tar.gz
2、解压后,查看apache-hive-2.3.5-src/pom.xml文件
部分内容如下(line 141: <hadoop.version>2.7.2</hadoop.version>
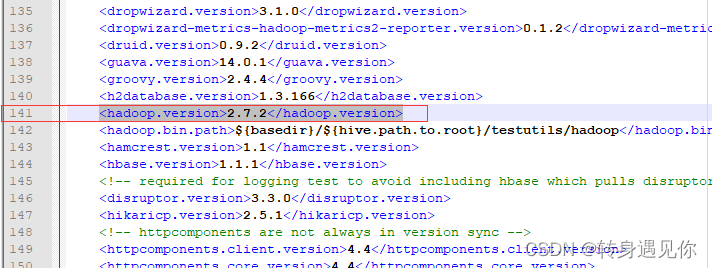
即,hive-2.3.5对应的hadoop版本号是2.7.2
参考资料: https://blog.csdn.net/m0_67401228/article/details/123936108
二、JDK安装
jdk版本:jdk1.8.0_211
1、下载解压至自定义路径下
2、环境变量配置,依次点击我的电脑-属性-高级系统设置-环境变量-新建系统变量,如下图所示:
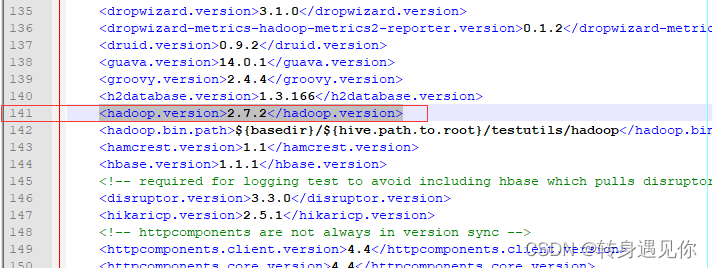
编辑系统变量Path,添加如下图所示两个值(最好将其复制到文本上编辑)
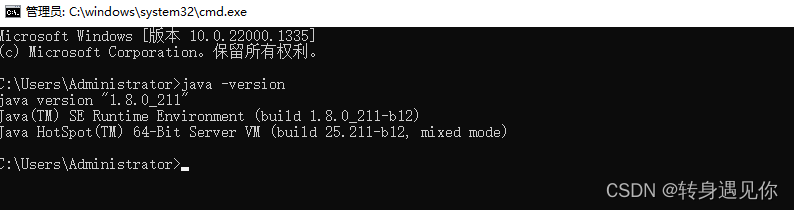
3、检测是否安装成功
打开cmd, 输入命令java -version 如下图所示:
三、安装Hadoop
1、下载hive-2.3.5对应版本的hadoop-2.7.2.tar.gz 文件,并解压至自定义目录下
2、Hadoop环境变量配置
参考JDK环境变量配置,如下图所示:
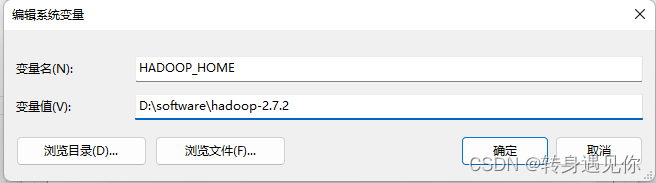
编辑系统变量Path,添加如下图所示值(和jdk的path操作一样):
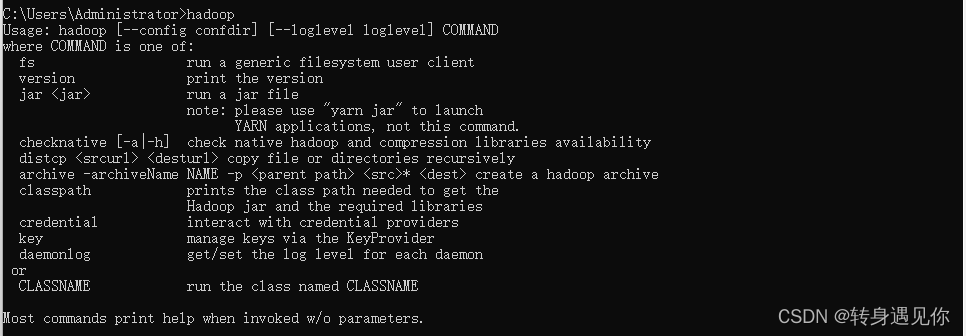
3、测试
打开cmd输入命令: hadoop ,正常应如下图所示:
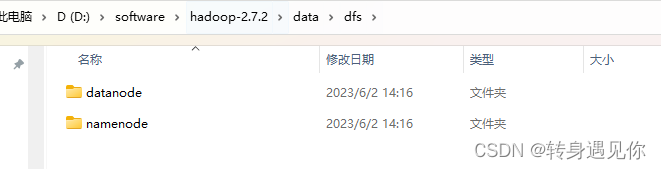
4、新建目录
在D:\software\hadoop-2.7.2目录下新建data/dfs/namenode与data/dfs/datanode 两个目录文件夹,如下图所示:
5、修改配置文件
进入目录:D:\software\hadoop-2.7.2\etc\hadoop 下:
修改core-site.xml文件,添加如下代码:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
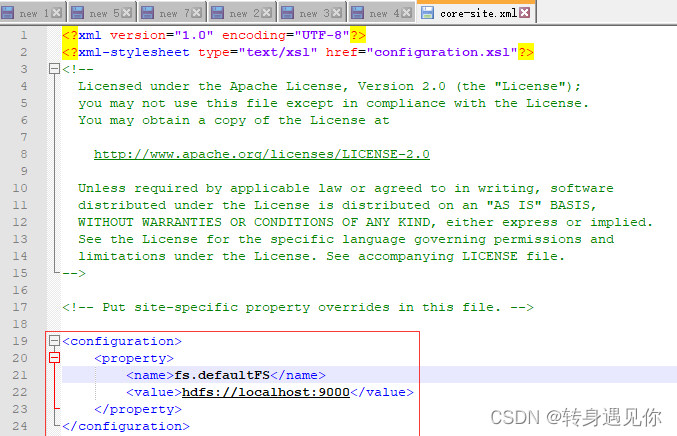
修改hdfs-site.xml文件,并将datanode和namenode改为自己的目录:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/software/hadoop-2.7.2/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/software/hadoop-2.7.2/data/dfs/datanode</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
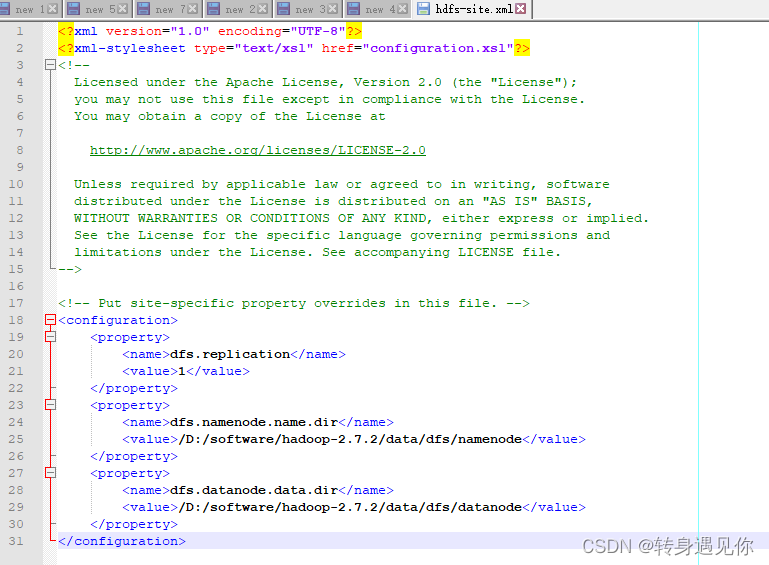
修改mapred-site.xml.template文件,将文件重命名为:修改mapred-site.xml,并添加如下代码:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
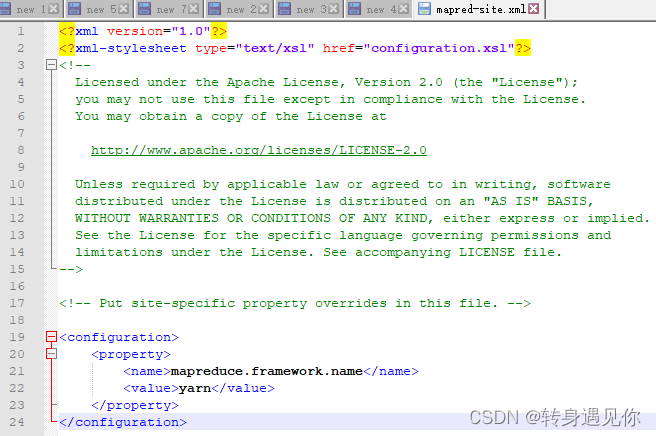
修改yarn-site.xml文件,并添加如下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tghw3ras-1685763806098)(E:\项目\个人\学习\hive\images\12.png)]](https://img-blog.csdnimg.cn/2dbc27e3535a480facc1a7827c5f7aa8.png)
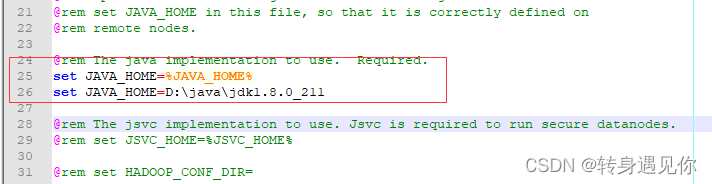
修改hadoop-env.cmd文件设置java目录:
@rem The java implementation to use. Required.
set JAVA_HOME=%JAVA_HOME%
set JAVA_HOME=D:\java\jdk1.8.0_211
- 1
- 2
- 3
位置如下:
6、下载winutils
由于hadoop不能直接直接在windows环境下启动,需要依赖hadoop的winutils
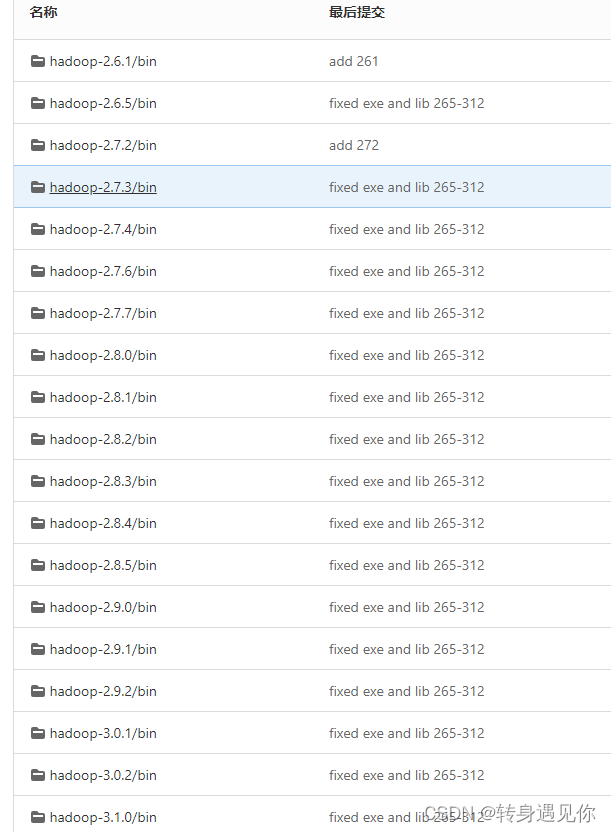
这里给出两个下载路径首先是 githttps://github.com/cdarlint/winutils
如果大家在git上下载不下来,或者下载慢,这里提供一个百度网盘的下载路径 https://pan.baidu.com/s/1a5et7e6oLir2dgABPJkgqg?pwd=yyds
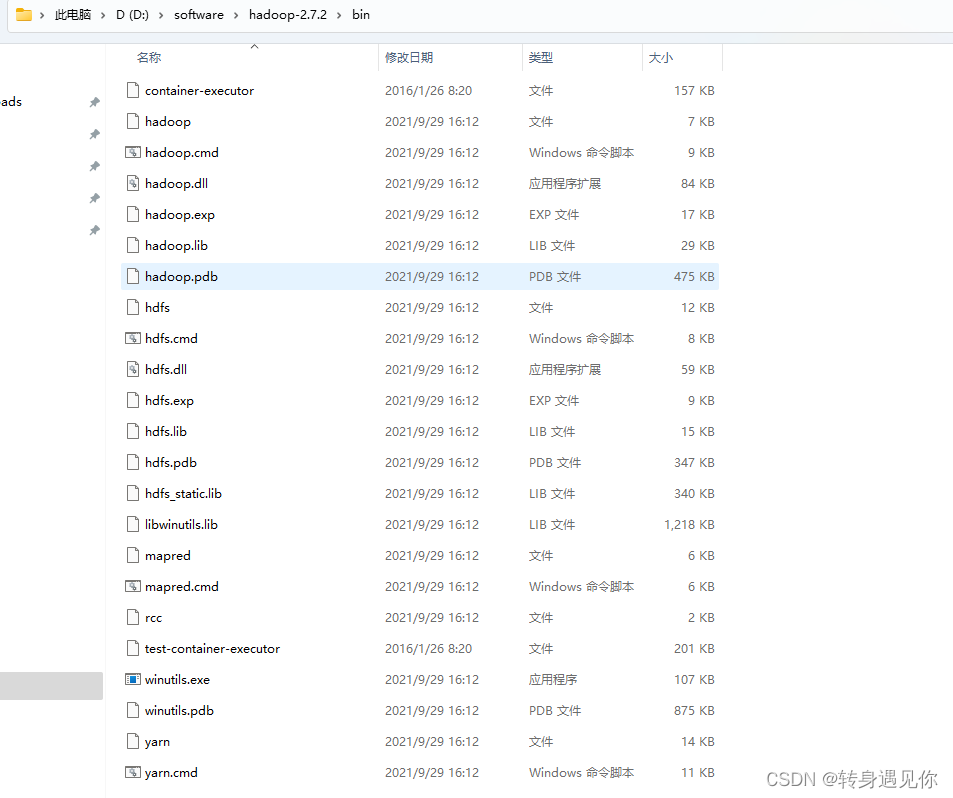
下载好之后,挑选和你hadoop相同的版本,将bin中的内容直接拷贝到你安装的hadoopbin目录下,有重复的替换即可。
原文链接:https://blog.csdn.net/weixin_43850384/article/details/126007016
7、格式HDFS,启动Hadoop
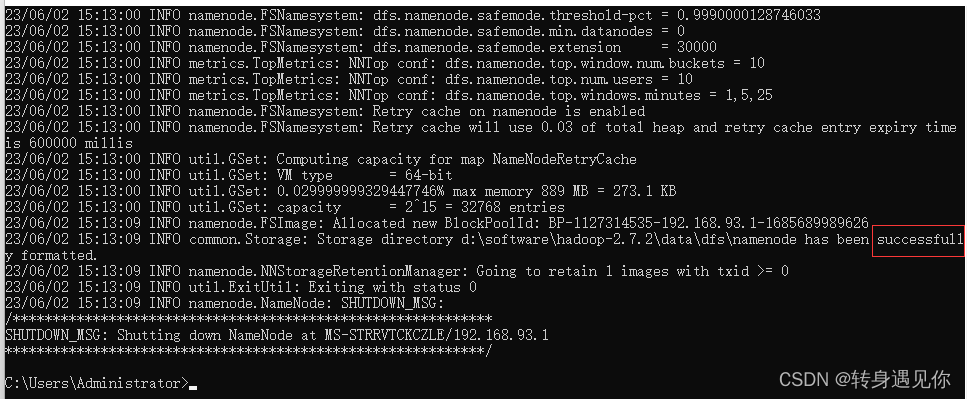
格式化HDFS,打开cmd,输入命令
hadoop namenode -format
- 1
看到successfully证明成功初始化。
之后切换到hadoop安装目录下的sbin目录(D:\software\hadoop-2.7.2\sbin),输入以下内容:
start-all.cmd
- 1
会依次弹出四个命令框,分别为namenode、datanode、resourcemanager、nodemanager
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-omcLglfV-1685763806100)(E:\项目\个人\学习\hive\images\17.png)]](https://img-blog.csdnimg.cn/c2c8e27ee2964782854f2f7effb6c57f.png)
浏览器输入:http://localhost:50070/ 注意:hadoop-3.x版本地址是:http://localhost:9870
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dMMCnrMQ-1685763806100)(E:\项目\个人\学习\hive\images\18.png)]](https://img-blog.csdnimg.cn/9cf05673ad8d48cfba5753ee7416552b.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UGpmaecF-1685763806101)(E:\项目\个人\学习\hive\images\20.png)]](https://img-blog.csdnimg.cn/2eb4488ea4c2494d9b58230665f3793b.png)
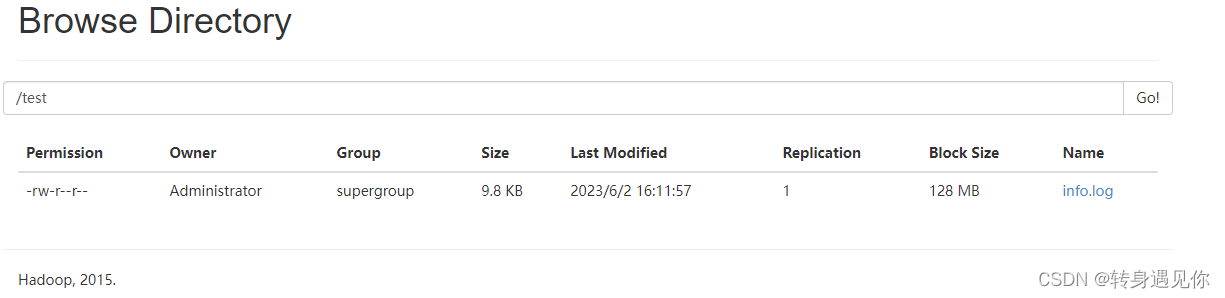
8、测试文件上传
切换到hadoop下的bin目录,输入
hadoop fs -mkdir /test
- 1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BGAnO3Of-1685763806101)(E:\项目\个人\学习\hive\images\19.png)]](https://img-blog.csdnimg.cn/b1cf06aa71c54444964091d34e653d2b.png)
随意上传一个文件:hdfs dfs -put “你的文件路径” /test
hadoop dfs -put /D:/tmp/info.log /test
- 1
四、HVIE安装
1、下载apache-hive-2.3.5-bin.tar.gz 文件,并解压至自定义目录下,并重命名为hive-2.3.5
注意当前版本没有cmd命令可以从以前的版本拷贝至相同的目录下
2、Hive环境变量配置
参考JDK环境变量配置,如下图所示:
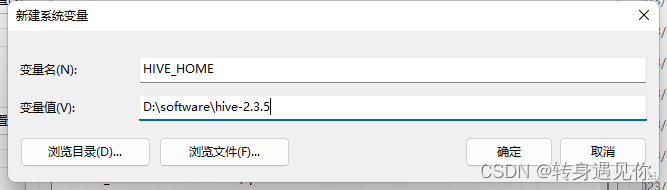
编辑系统变量Path,添加如下图所示值(和jdk的path操作一样):
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7yatGt0Q-1685763806102)(E:\项目\个人\学习\hive\images\23.png)]](https://img-blog.csdnimg.cn/65aa360e1ec24d9990d2c3af0af4a911.png)
3、新建目录
创建如下四个空目录:
D:\software\hive-2.3.5\data_hive\operation_logs
D:\software\hive-2.3.5\data_hive\querylog
D:\software\hive-2.3.5\data_hive\resources
D:\software\hive-2.3.5\data_hive\scratch
- 1
- 2
- 3
- 4
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3nMJPjAM-1685763806102)(E:\项目\个人\学习\hive\images\24.png)]](https://img-blog.csdnimg.cn/5217fceb20a84c72aff168cdc03d3eba.png)
4、MySql驱动配置
将mysql-connector-java-5.1.47-bin.jar复制到D:\software\hive-2.3.5\lib目录下,如下图
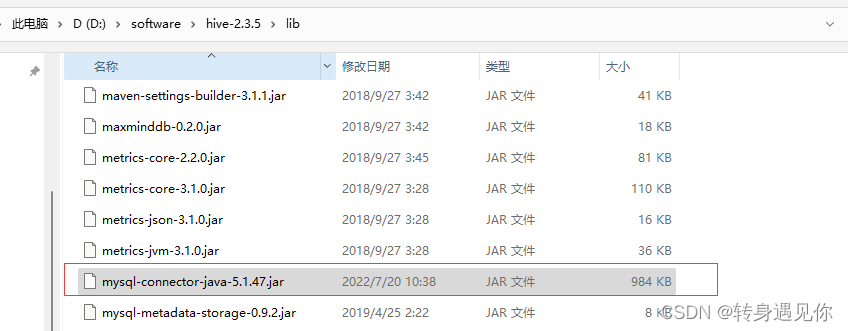
5、修改配置文件
进入D:\software\hive-2.3.5\conf目录下:
将 hive-log4j2.properties.template 重命名为 hive-log4j2.properties
将 hive-exec-log4j2.properties.template 重命名为 hive-exec-log4j2.properties
修改hive-env.sh文件 ,将hive-env.sh.template文件重命名为hive-env.sh
新增以下内容,路径注意修改为自己的
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=D:\software\hadoop-2.7.2
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=D:\software\hive-2.3.5\conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=D:\software\hive-2.3.5\lib
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
修改hive-site.xml文件,hive-default.xml.template文件重名为hive-site.xml
路径注意修改为自己的
<property>
<name>hive.exec.local.scratchdir</name>
<value>D:/software/hive-2.3.5/data_hive/scratch</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>D:/software/hive-2.3.5/data_hive/resources/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
6、创建数据库(mysql5.7.*)
创建数据库,注意字符集和排序规则的设置属性
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZLTUsd7g-1685763806103)(E:\项目\个人\学习\hive\images\26.png)]](https://img-blog.csdnimg.cn/1e194f3715424224bf7a12edfc46906b.png)
7、再次编辑hive-site.xml文件配置数据库
注意改成自己的
<property> <name>javax.jdo.option.ConnectionPassword</name> <value>password6</value> <description>password to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>Username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:13305/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
8、测试
启动hadoop
进入D:\software\hadoop-2.7.2\sbin目录下,点击start-dfs.cmd启动两个窗口服务即成功
初始化hive数据库
打开cmd输入下面命令:
hive --service schematool -dbType mysql -initSchema
- 1
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-69q9lGy7-1685763806103)(E:\项目\个人\学习\hive\images\27.png)]](https://img-blog.csdnimg.cn/c4f067b4a83f492c8abfccf836a06305.png)
9、启动hive操作数据库
开的cmd命令窗口,输入:hive 如下图进入hive
![[外链图片转存中...(img-VkK6HVb4-1685763806104)]](https://img-blog.csdnimg.cn/8ddebb40592744d899c70bce5632384a.png)

