
- 1优维大模型解密:从提示词工程到场景应用 ,剑指AIOps的牛刀小试_大模型提示词工程和提供训练数据的先后顺序
- 2Spring,SpringMvc,SpringBoot三者之间有什么区别?_spring mvc和spring boot配置组件有何异同
- 3AI短视频制作一本通:文本生成视频、图片生成视频、视频生成视频_ai照片生成视频
- 4Vue中的数据操作_vue data里面用data的数据
- 5Docker - Docker安装MySql并启动_mysql docker 启动
- 6Hadoop之Hbase建表(详细步骤)_hbase创建表
- 7MySQL数据库索引的种类、创建、删除_mysql索引建立
- 8量子信息产业生态研究(一):关于《量子技术公司营销指南(2023)》的讨论
- 9泰迪智能科技携手洛阳理工学院共建“泰迪·洛阳理工数据智能工作室”
- 10【R】【支持向量机分类方法】_r语言svm-rfe怎么看
手把手教你从0到1搭建web ui自动化框架(python3+selenium3+pytest)_ui自动化框架python+pytest
赞
踩
前期准备
为更好的学习自动化框架搭建,你需要提前了解以下知识:
python基础知识
pytest单元测试框架
PO模式
selenium使用
环境
本次我们自动化环境为:
mac+python3+selenium3+pytest==6.2.4
(不管是win还是mac,网上环境安装教程很多,参考下安装即可)
-实战: 从0开始
接下来我们以这个系统的登陆页面作为demo,开始进行web UI框架搭建:
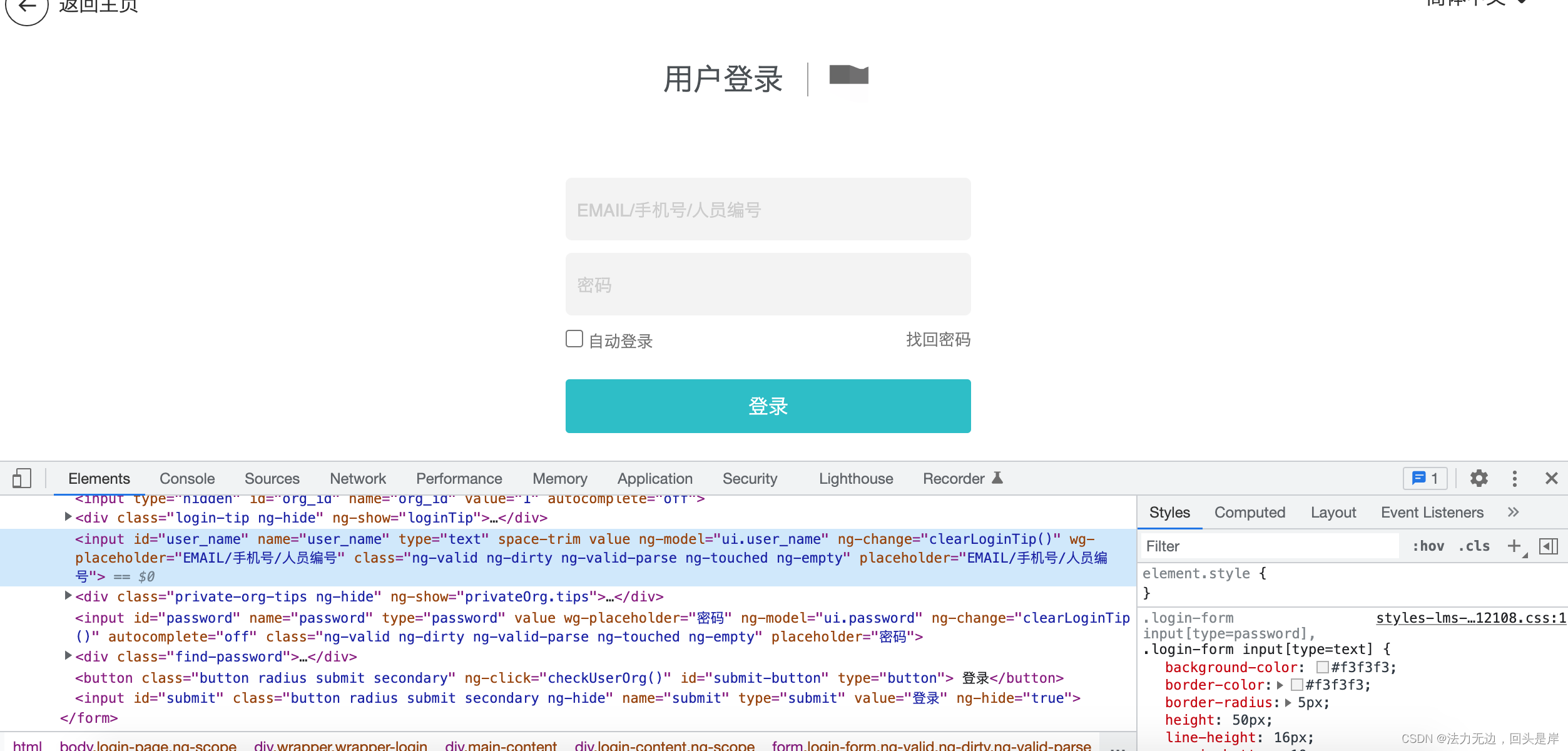
最开始,我们设计了一个test_login.py文件,里完成了登陆脚本的设计:
from selenium.webdriver.support.ui import WebDriverWait url = 'xx' class TestLogin(): def setup(self): self.driver = webdriver.Chrome() self.driver.get(url) self.driver.maximize_window() def teardown(self): self.driver.close() #以下为login页面设计的case #case1:输入正确的用户名密码后页面跳转正常 def test_is_null(self,name,password): self.driver.find_element(By.ID, 'user_name').send_keys(name) self.driver.find_element(By.ID, 'password').send_keys(password) self.driver.find_element(By.ID, 'submit-button').click() assert 'user/index' in self.driver.get_url(),'failed--用户名密码正确时登陆场景失败' print ('case pass') # case2:用户名/密码不匹配 def test_not_match(self, name, password): pass

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
写了1,2个用例时我们觉得没什么,但是随着case数量的增到,我们意识到了问题的严重性:
1.不同的case明明是同一段代码,只是传参不一致,就需要重复写多次,即便复制/粘贴也累啊—》解决:参数化,实现数据分离–创建data层
2.系统中某个页面发生变化,我准备去修改下对应的页面,结果代码写的过于分散,同一个页面的数据分散到了不同py模块,每次都修改不全,严重影响后期维护成本–》解决:引用PO模式(page object)–创建page层
3.系统中存在公共模块(比如系统中存在一个上传下载功能),多个页面/多个case都要使用—》解决:创建一个公共模块(创建public层)
……
诸如此类的问题随着case不断增多的状况下会明显感觉得到,接下来我们就开始逐一解决:
参数化(data):
利用pytest框架提供的@pytest.mark.parametrize()来实现,代码及页面接口设计如下:
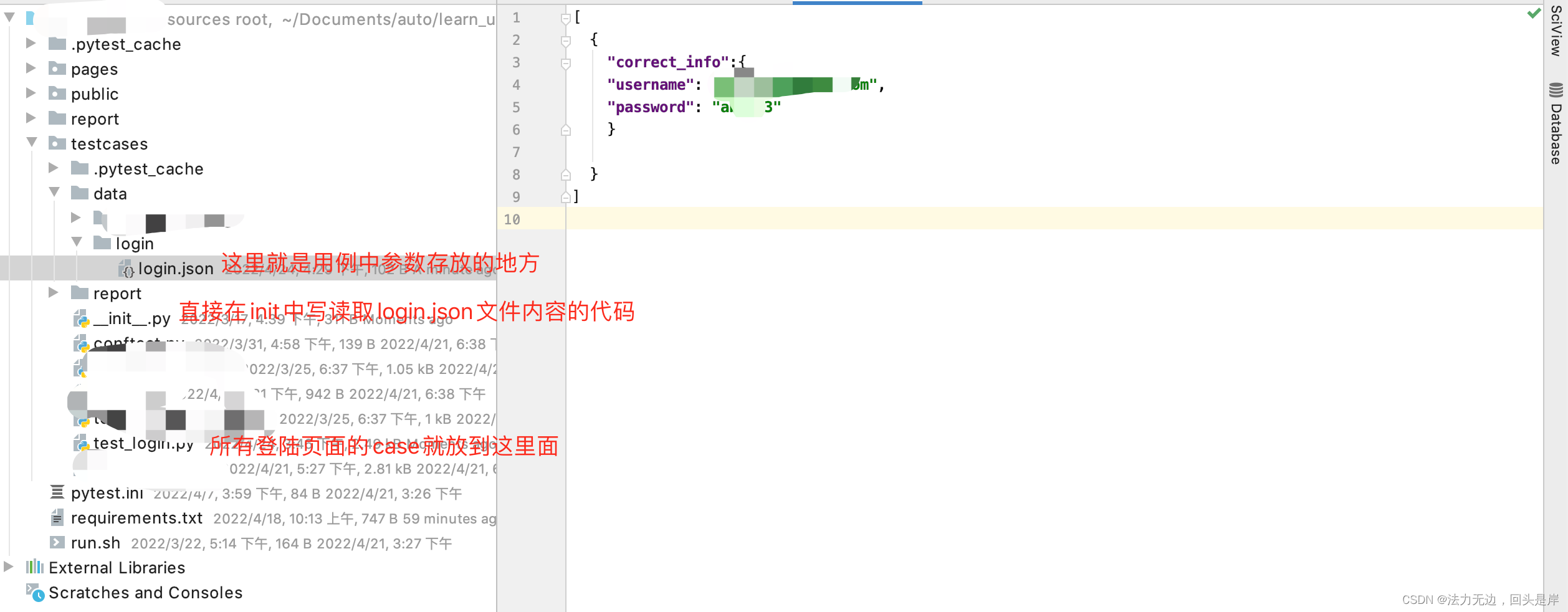
读取json文件的代码:
import os import json current_path = os.path.abspath(__file__) path = os.path.dirname(current_path) def get_json_data(specifypath): try: parent_path = os.path.dirname(current_path) path = f"{parent_path}/data/{specifypath}" with open(path) as file: data = json.load(file) return data except Exception as e: print (e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
用例层调用data改造后的代码:
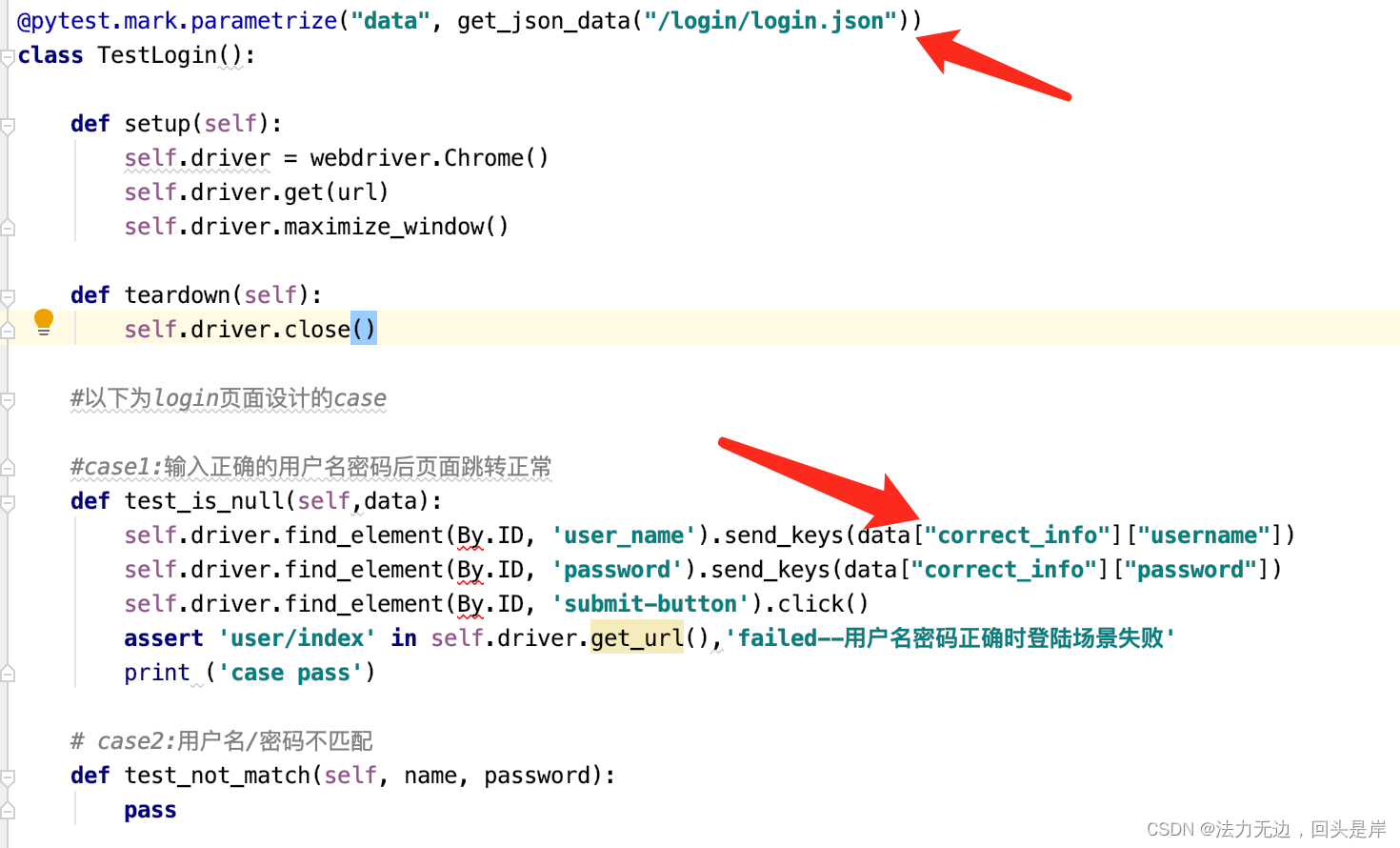 引用PO模式(page object):
引用PO模式(page object):
po模式:
简单来说,就是以一个页面作为一个对象,把一个页面的内容写成一个.py文件;
这个页面对象中包含内容:当前页面的元素定位及操作的整合;
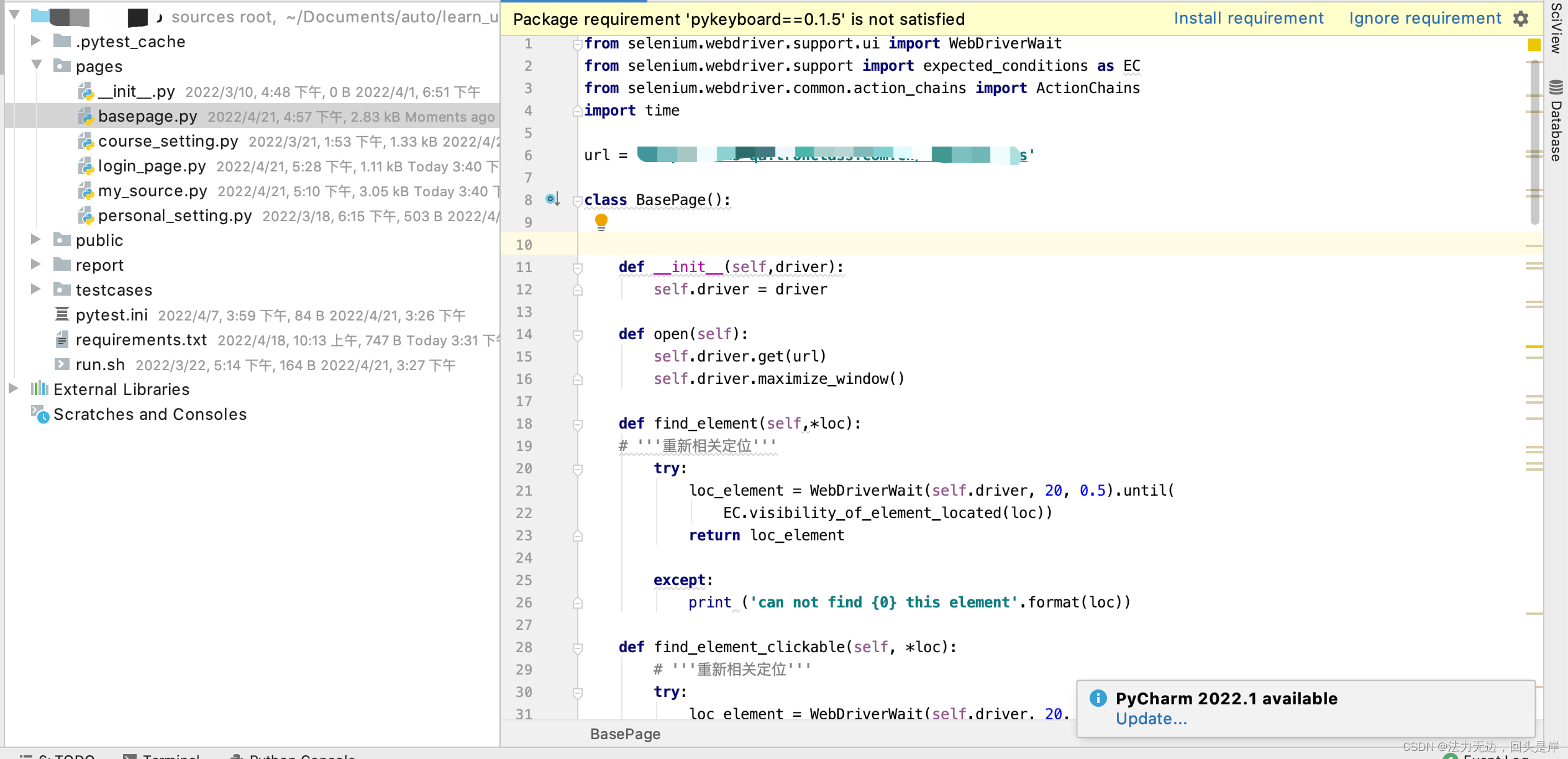
po模式中会引用一个basepage.py,这个文件里面一般包含的是driver相关的操作,比如:elements相关的改造,简单粗暴点理解:就是把self.driver.xx相关的内容都写到这里就行;其他页面都会继承basepage.py中的内容。
按照上面逻辑我们继续改造代码:
basepage.py:
login_page.py
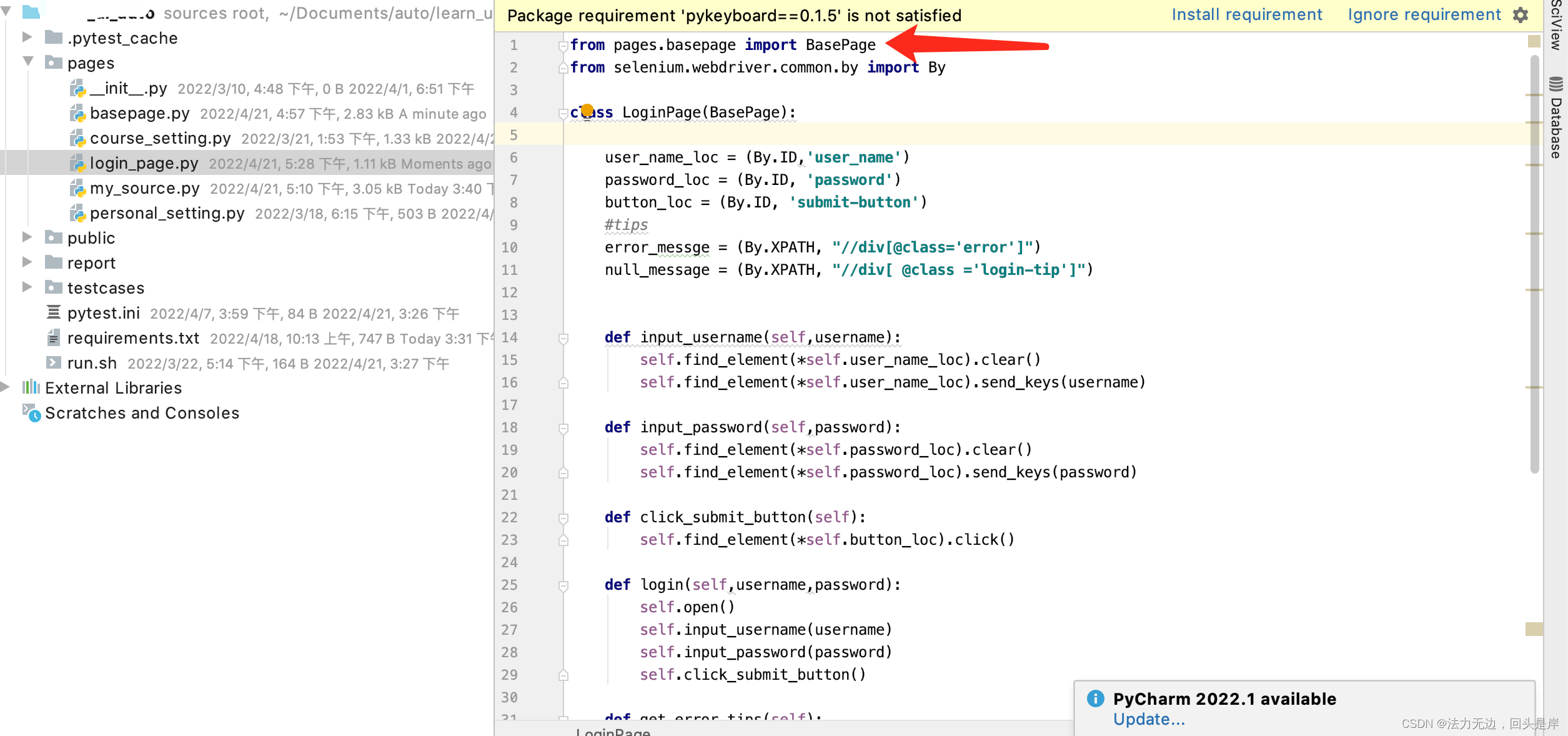
我们看下case层怎么引用:
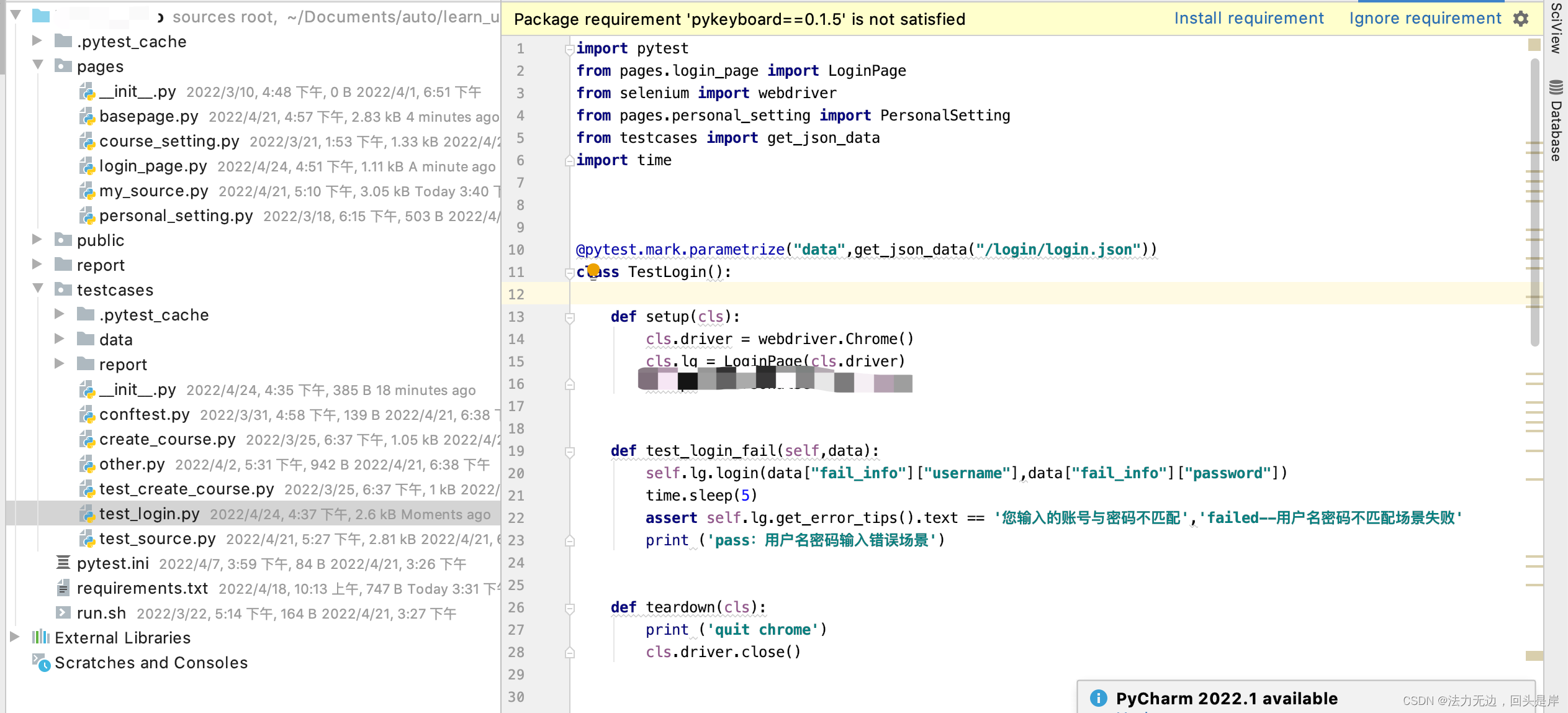 public层:
public层:

比如我登陆页面需要用到public中的内容,直接在login_page.py文件中继承即可使用public中的所有方法:
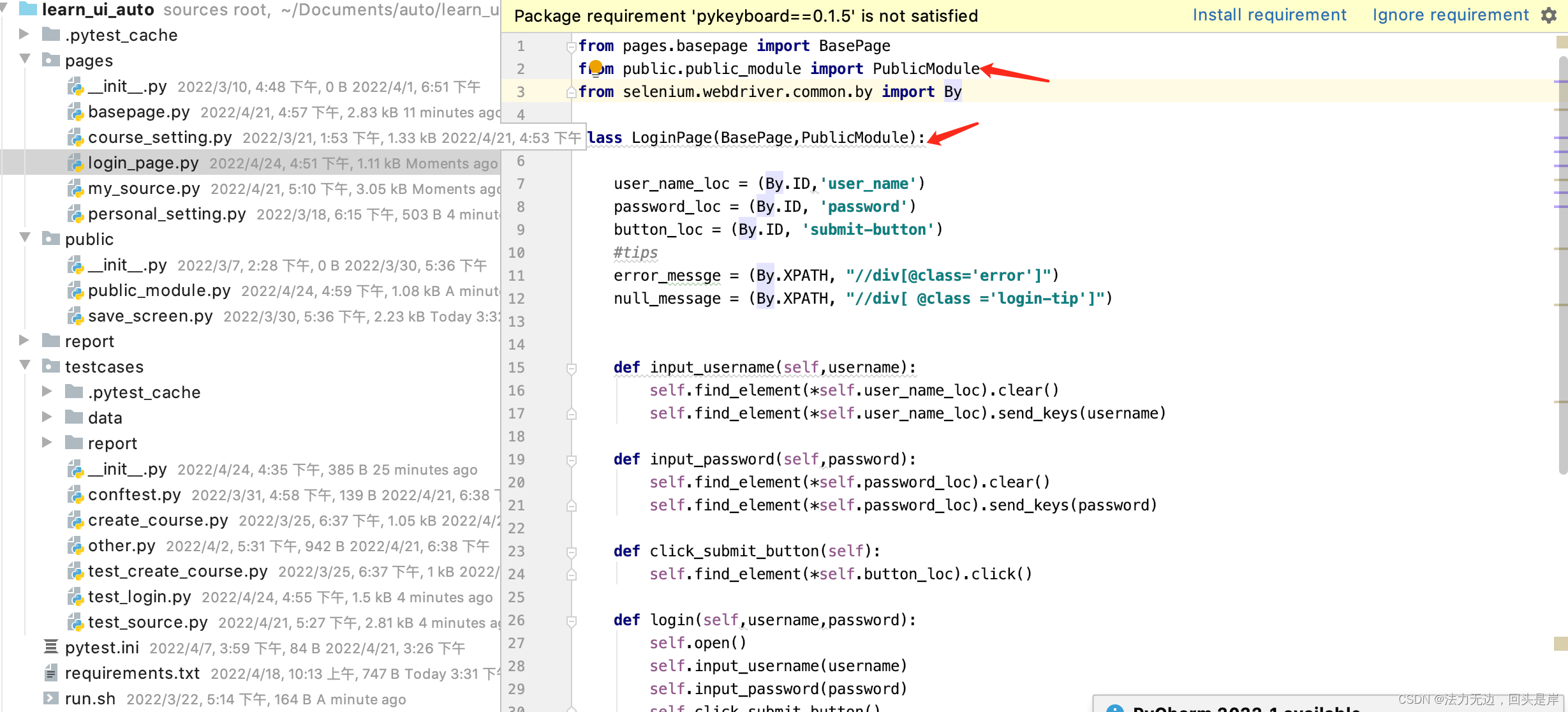
/以上就完成的框架设计/
框架设计核心:分层思想、PO模式
自动化框架设计一般都是设计都分为:page层、testcase层、public层、data层、report层(分层都比较灵活的,不管怎么分都是换汤不换药)
给大家看下完整的框架结构:
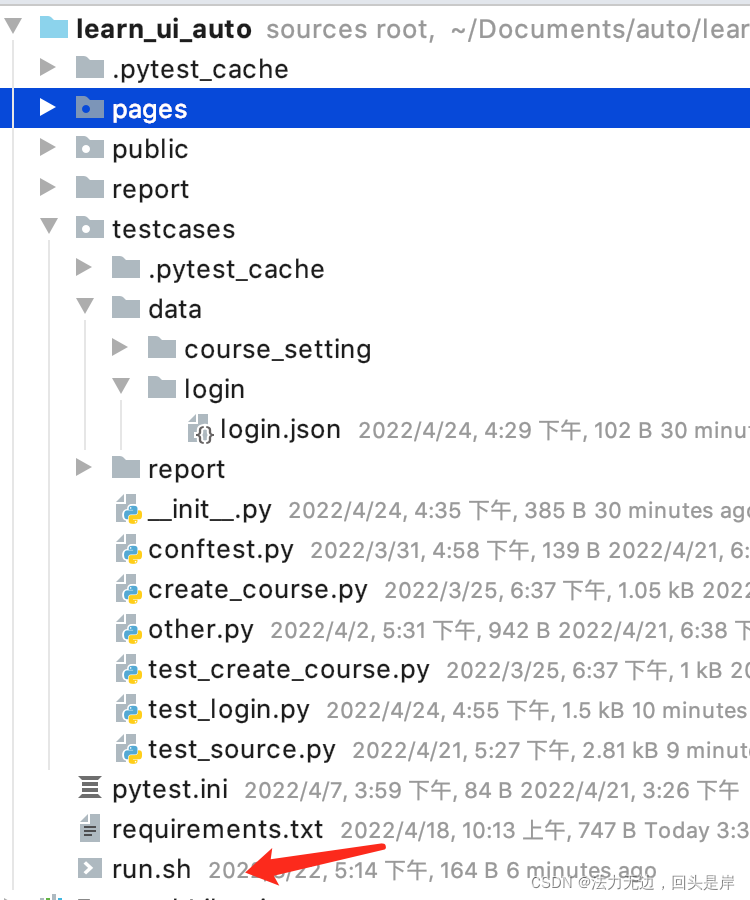
运行所有的case都放在这个run.sh的shell脚本里,后期做jenkins集成也只需要跑这个脚本即可:
echo 'start----------------'
pip install -r requirements.txt
pwd
pytest
echo 'end----------------'
- 1
- 2
- 3
- 4
- 5
关于report大家可以直接用pytest-html来实现,网上有很多教程参考;
后期做jenkins集成直接参考之前写的内容。
///done//

