
- 1【云原生进阶之PaaS中间件】第四章RabbitMQ-3-RabbitMQ安装_rabbitmq搭建
- 2【研发日记】C/C++开发避坑秘籍(一)——CAN接收Buffer溢出Bug_c++can接收
- 3Android系统签名看这一篇就够了!
- 4参考阿里云DMS快速开发数据管理平台_数据管理dms 可编程对象 实战
- 5SQL入门:第二天 --> leetCode196:删除重复的电子邮箱_id是该表的主键列。 该表的每一行包含一封电子邮件。电子邮件将不包含大写字母。
- 6亚马逊云科技云从业者认证考试 50% 折扣券限量赠送,先到先得!
- 7【Ubuntu】奇技淫巧-代码雨&小火车_没有出现安装小火车
- 8Kotlin语法快速入门-区间(3)
- 9uni-app点击给当前元素动态添加class_uniapp 点击添加class
- 10四轴飞行器入门——基础知识_h型无人机和x型无人机区别
大模型培训老师叶梓:通过微调提升小型语言模型的复杂推理能力
赞
踩
在人工智能的快速发展中,复杂推理能力的提升一直是研究者们追求的目标。最近,一项发表在arXiv上的研究成果【1】,提出了一种创新的方法,即通过微调小型语言模型(LMs),并将其与大型语言模型(LLMs)的协作,以显著提升复杂推理能力。这一方法的核心在于利用大型教师模型的思维链(Chain-of-Thought,CoT)推理能力来指导小模型解决复杂任务。
大型语言模型,如GPT-3,已经展示出在多步推理任务中的卓越性能。然而,这些模型的计算要求和推理成本非常庞大,这限制了它们在实际应用中的大规模部署。相比之下,小型模型虽然在计算成本上更为经济,但在处理复杂任务时往往力不从心。
微调思维链方法
为了解决这一问题,研究者提出了一种名为微调思维链的方法。该方法的关键在于使用大型教师模型生成推理样本,然后用这些样本来微调小型学生模型。这种方法不仅保留了基于prompting的思维链方法的多功能性,而且模型规模相对较小,更适合实际应用。
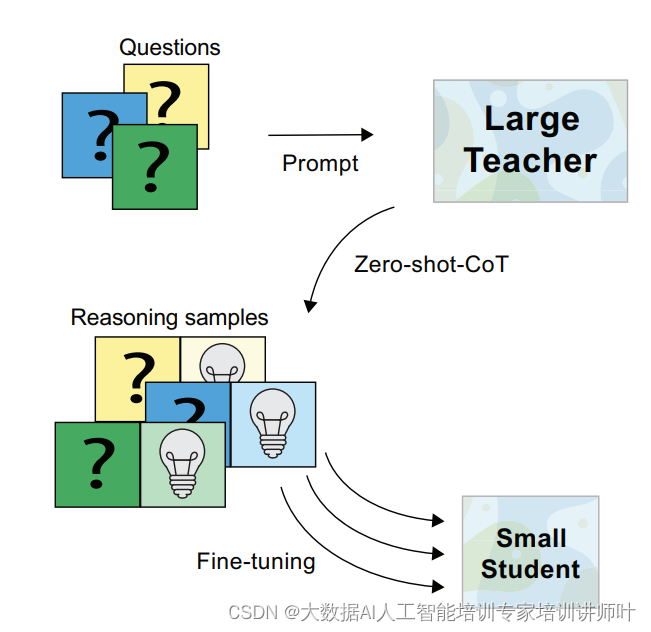
该方法包括以下几个关键步骤:
a. 推理生成
首先,使用一个大型教师模型来生成针对特定问题的推理链。这些推理链不仅包括最终答案,还包括得出答案所需的中间推理步骤。
推理生成是微调思维链方法中的一个关键步骤,它涉及到以下几个环节:
-
选择大型教师模型:首先,研究者会选择一个已经预训练好的大型语言模型作为教师模型。这个模型通常具备强大的语言理解和推理能力,能够处理复杂的查询和任务。
-
问题输入:将需要解决的问题输入到教师模型中。这些问题可以是数学问题、逻辑谜题、科学问题等,需要模型进行多步推理才能得出答案。
-
生成推理链:利用教师模型生成针对每个问题的推理链。这个过程可能涉及到使用特定的提示(prompting)技术,引导模型不仅给出答案,还展示出得出答案的思考过程。这些推理链包括了一系列的逻辑步骤,每个步骤都是解决问题过程中的一个节点。
-
收集和筛选:从教师模型生成的多个推理链中,研究者会收集并筛选出正确且解释清晰的推理路径。这些推理链将作为训练小型学生模型的样本。
-
构建训练集:将筛选出的推理链构建成训练集,其中包含了问题的描述、中间推理步骤以及最终答案。这个训练集将用于后续的微调过程。
-
多样化推理:为了提高学生模型的泛化能力,研究者可能会采用多样化推理的策略,即对于每个问题生成多个不同的推理链。这样可以确保学生模型不会只学习到一种解决问题的方法,而是能够理解多种可能的推理路径。
-
无需额外标注:推理生成的另一个优势是它不需要手动标注的推理解释。教师模型自身就能生成所需的推理链,这大大减少了人工标注的工作量,并降低了成本。
-
准备微调:最后,这些生成的推理样本将作为训练数据,用于微调小型学生模型,使其能够模仿教师模型的推理行为,并在类似任务上表现出类似的推理能力。
推理生成步骤是微调思维链方法能够成功的关键,因为它为小型模型提供了学习和模拟复杂推理所需的示例和指导。通过这种方法,小型模型能够在保持计算效率的同时,提升解决复杂问题的能力。
b. 微调学生模型
接着,利用这些生成的推理样本来微调一个小型的学生模型。这一过程涉及将推理样本作为训练数据,帮助学生模型学习如何执行类似的推理任务。
微调学生模型是微调思维链方法中的第二步,它紧随推理生成之后,涉及以下几个关键环节:
-
选择学生模型:在这一步中,研究者会选择一个小型的语言模型作为学生模型。这个模型的规模相较于教师模型要小,因此它需要通过微调来提升其在特定任务上的推理能力。
-
准备训练数据:使用从教师模型生成的推理链构建训练数据集。这个数据集包含了问题的描述、中间推理步骤以及最终答案,它们将作为训练信号指导学生模型的学习。
-
设计微调策略:研究者需要设计一个微调策略,这可能包括选择合适的损失函数、优化算法和学习率等。微调的目标是让学生模型能够模仿教师模型的推理过程,并在给定问题上生成类似的推理链。
-
训练过程:在设计好的微调策略指导下,开始训练学生模型。在训练过程中,学生模型会尝试生成与教师模型相似的推理链,同时学习如何根据问题描述生成正确的答案。
-
评估与迭代:在训练的每个阶段,研究者会评估学生模型的性能,检查其生成的推理链的准确性和完整性。根据评估结果,可能需要对微调策略进行调整,以优化学生模型的学习效果。
-
利用多样化推理:为了提高学生模型的泛化能力,研究者可能会采用多样化推理的策略,即在训练过程中使用多个不同的推理链样本。这样可以防止学生模型过度拟合某一种特定的推理路径。
-
减少过拟合风险:由于学生模型的规模较小,它有更大的风险过拟合于训练数据。因此,在微调过程中,可能需要采用正则化技术、数据增强或早停(early stopping)等策略来减少过拟合。
-
最终评估:在微调完成后,学生模型会在独立的测试集上进行最终评估,以验证其在未见过的样本上的表现。这个测试集包含了新的问题和推理任务,用于测试学生模型的推理能力和泛化性能。
-
部署与应用:一旦学生模型在测试集上展现出满意的性能,它就可以被部署到实际应用中,用于解决需要复杂推理的任务。由于学生模型的规模较小,它在计算资源和部署成本上具有优势。
微调学生模型是微调思维链方法中实现小型模型性能提升的核心环节。通过模仿教师模型的推理行为,学生模型能够在资源受限的环境中,有效地处理复杂的推理任务。
c. 多样化推理
为了提高教学效果,研究者提出了为每个训练样本生成多个推理方案的方法,这种方法称为多样化推理。通过这种方式,学生模型可以学习到多种解决问题的途径,从而提高其泛化能力。
以下是多样化推理的详细说明:
-
推理路径的多样性:在解决复杂的推理任务时,通常存在多种正确的推理路径。多样化推理强调生成多个不同的推理方案,而不是单一的解决方案。这有助于模型理解不同逻辑和推理过程。
-
生成多个推理链:在推理生成阶段,对于每个问题,教师模型被用来生成多个可能的推理链。这些推理链展示了不同的思考过程和逻辑步骤,增加了解决问题的策略多样性。
-
避免单一思维模式:通过多样化推理,学生模型不仅限于学习一种解决问题的方法。它能够接触到多种思维模式,这有助于模型在面对新问题时,能够灵活地选择最合适的推理策略。
-
提高模型的泛化性:多样化推理通过提供不同的推理样本,有助于学生模型学习到更广泛的知识表示和逻辑关系,从而提高其在未见过的问题上的泛化能力。
-
增强模型的鲁棒性:在面对数据中的噪声或异常情况时,多样化推理能够使模型更加鲁棒。即使某些推理路径不适用,模型仍然可以依靠其他的推理链来得出正确答案。
-
训练数据的丰富性:多样化推理增加了训练数据的丰富性。学生模型在训练过程中接触到更多的信息和不同的推理方式,这有助于提升其学习效果。
-
实现方法:实现多样化推理的一种简单方法是通过随机抽样生成多个推理方案。更复杂的方法可能包括使用不同的提示或条件来引导教师模型产生多样化的推理链。
-
评估和选择:在生成多个推理链后,研究者需要评估和选择那些正确且解释清晰的推理链作为训练数据。这一步骤确保了训练数据的质量和多样性。
-
应用到微调中:在微调学生模型时,多样化的推理链被用作训练样本。学生模型通过模仿这些多样化的推理过程,学习如何根据不同问题的特点选择合适的推理策略。
-
最终性能的提升:通过多样化推理的训练,学生模型在解决复杂任务时展现出更高的性能。它不仅能够正确回答问题,还能够提供合理的推理解释,增强了模型的可信度和解释性。
多样化推理是提升小型语言模型在复杂推理任务上性能的有效手段。通过模仿大型教师模型生成的多样化推理链,学生模型能够学习到丰富的推理策略,从而在实际应用中表现出更好的推理能力和泛化性。
结果
研究者在公开的GPT-3模型上进行了实证评估,发现微调方法显著提升了小模型在复杂任务中的推理性能,甚至在某些任务中超过了它们的大模型老师。此外,通过多样化推理,即使在训练样本较少的情况下,小模型也展现出了较高的样本效率和显著的推理性能。
通过微调小型语言模型,并与大型语言模型协作,可以显著提高小模型在复杂推理任务中的表现。这种方法不仅有助于降低计算成本,还为小型模型在更广泛的应用场景中的部署提供了可能。随着进一步的研究和发展,这种方法有望在人工智能领域中发挥更大的作用。
参考文献:
- arXiv论文:微调思维链的方法【1】

