
- 1浅谈【Stable-Diffusion WEBUI】(AI绘图)的基础和使用_stable diffusion --medvram --theme dark --xformers
- 2Hive(一) Hive概述、三种方式搭建和区别_hive 的安装过程与ha搭建有什么区别
- 3应用连MySQL 报错ERROR 1129 Host is blocked because of many connection errors
- 4PMP证书到期后,有没有必要续证了_pmp证书有必要续吗
- 5Centos7一键安装Docker脚本_centos安装docker 菜鸟 一键脚本
- 6linux搭建raid5命令,命令行操作RAID5
- 7C语言 哈希表的简单实现_用 hash table 实现一个存储学生成绩的程序,你的程序要能处理 collision,请使用
- 8【Redis】sentinel故障转移_sentinel 是如何实现故障转移的
- 9【Super数据结构】堆结构的建立与调整&&堆的应用(含堆排序/topK问题)
- 10【Web前端】JS高级知识总结_前端js高级部分
几个跟数字人项目相关的开源大模型_开源数字人
赞
踩
目前很多大模型如雨后春笋般涌现出来,都有点心慌了。冷静下来还是需要一个个去识别哪些对自己有用。
AI Voice Chat
https://github.com/WeberJulian/AI-voice-chat
它是一个简化版的react app,可以用自己的语音跟chatGPT 语音聊天。
它使用Whisper Large v3来转录,使用openchat 3.5 AWQ作为语言助手,XTTS v2用来文本转语音。
它的优势是语言对语音的几乎无延迟特性。运行在RTX 3090 GPU上。
Diffusion Avatars
https://tobias-kirschstein.github.io/diffusion-avatars/(代码还在开发中)
它用来合成一个高保真的3D头像,提供对姿势和表情的控制。
-
将表情传输到3D头像动画

-
通过 NPHM 制作头像动画
通过底层 NPHM 进行控制。我们通过在几个目标表达式之间进行插值来获得表达式代码 z exp 。使用光栅化和我们基于扩散的神经渲染器,表达代码被转换为具有视点控制的现实化身。

-
自己制作头像动画
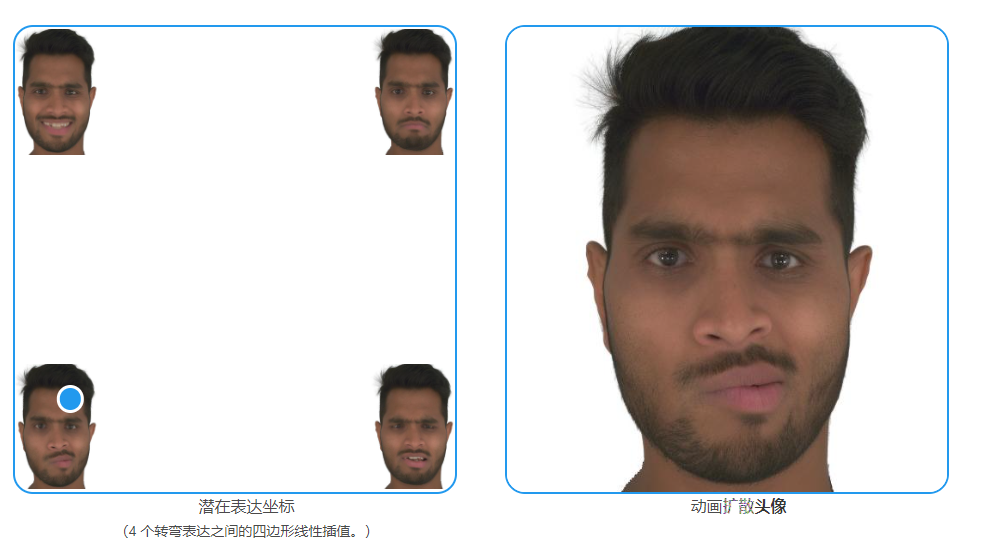
通过拖动蓝色点到相应的表情,完成3D人物表情的改变,中间的过渡很流畅。
PoseGPT: 通过对话的方式实时生成3D人物姿态
https://yfeng95.github.io/posegpt/(代码还在开发中)
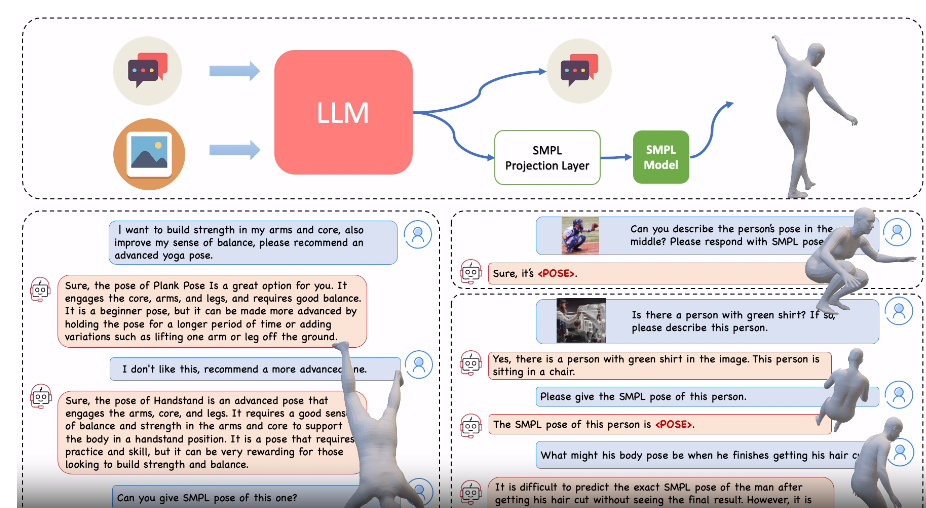
这是一个采用大型语言模型 (LLM) 来从图像或文本描述中理解和推理 3D 人体姿势的框架。源于人类从单个图像或简短描述中直观地理解姿势的能力,这是一个将图像解释、世界知识和对肢体语言的理解交织在一起的过程。传统的人体姿势估计方法,无论是基于图像的还是基于文本的,通常缺乏整体场景理解和细致入微的推理,导致视觉数据与其现实世界含义之间的脱节。PoseGPT 通过将 SMPL 姿势嵌入为多模态 LLM 中的独特信号标记来解决这些限制,从而能够从文本和视觉输入直接生成 3D 身体姿势。从而促进两项高级任务:推测性姿势生成和姿势估计推理。这些任务涉及推理人类从微妙的文本查询中生成 3D 姿势,可能还伴有图像。我们为这些任务建立了基准,超越了传统的 3D 姿态生成和估计方法。此外,PoseGPT 能够基于复杂推理理解和生成 3D 人体姿势,为人体姿势分析开辟了新的方向。
Animate Anyone
https://humanaigc.github.io/animate-anyone/
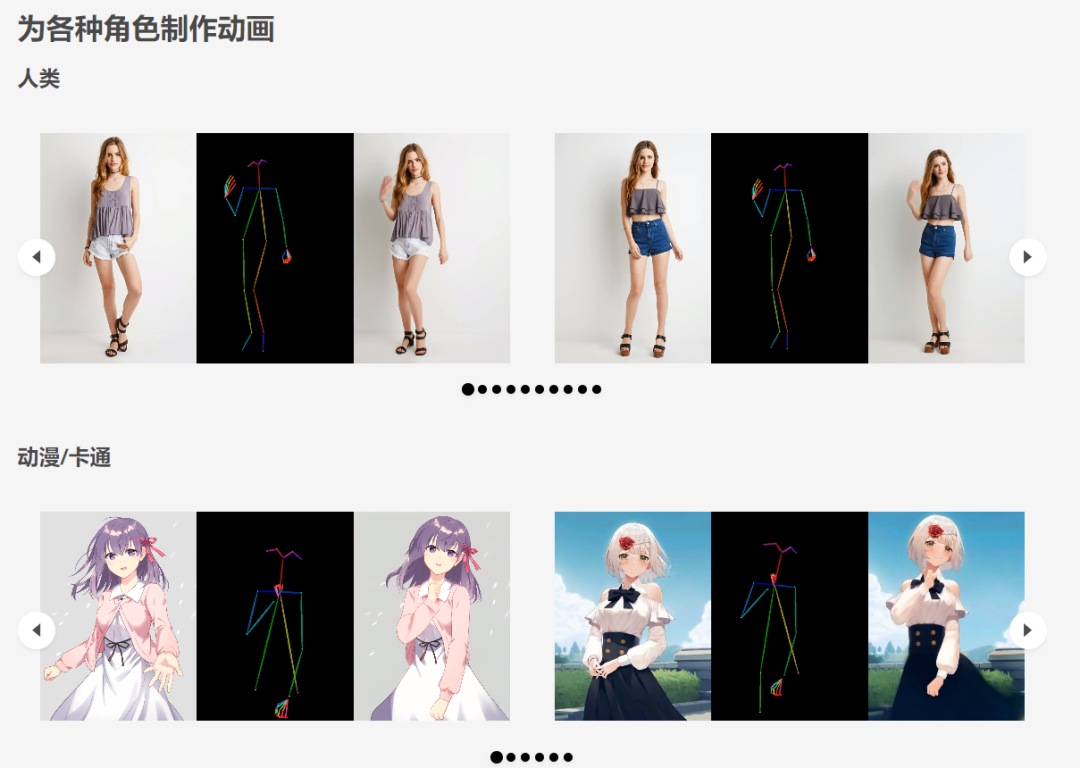
这个模型实现从静止图像到人物动态视频。这个用来实现角色动画的一致性。引入了有效的姿势引导器来指导角色的运动,并采用有效的时间建模方法来确保视频帧之间平滑的帧间过渡。
最后分享两个从文本到3D模型的流程:
https://3d.csm.ai/ 用来图片生成3D模型。
https://www.krea.ai/ 用来做参考制作理想模型
https://magnific.ai/ 用来将图片更加清晰
https://runwayml.com/ 做成动画
图生成法向图导入Blender处理:
https://huggingface.co/spaces/flamehaze1115/Wonder3D-demo


