
- 1转行IT职场:互联网企业给程序员的福报,包括技能培训吗?
- 2解决Google联网失败的问题_google home配网失败
- 3StarRocks操作笔记_starrocks 怎么停止rotuine load
- 4【华为机试Python3题解】HJ16购物单_机试购物单解析
- 5程序员面试,能不能不考“八股文”?
- 6网络安全攻防演练:企业蓝队建设指南
- 713_重学 Java 设计模式:实战责任链模式「模拟618电商大促期间,项目上线流程多级负责人审批场景」_重学 java 设计模式:
- 8【Kubernetes】Pod学习(二)部署一个静态Pod_如何只部署不通过部署deployment部署pod
- 9逻辑斯蒂回归原理(二分类、多分类)_二分类逻辑斯特回归
- 10利用OpenAI的文本生成模型,自动生成软件测试用例的几个场景示例_openai测试模型
EMNLP 2023 | ToViLaG:多模态生成模型毒性分析、评价及去毒
赞
踩


论文题目:
ToViLaG: Your Visual-Language Generative Model is Also An Evildoer
论文链接:
https://arxiv.org/pdf/2312.11523.pdf
代码链接:
https://github.com/victorup/ToViLaG
论文录用:
EMNLP 2023 Main Conference (Oral)
作者主页:
https://victorup.github.io/

摘要
警告:本文可能会包含模型生成的令人不适的内容。
最近视觉语言生成模型(VLGMs)在多模态生成任务上取得了很大进展。然而,这些模型也可能会生成有毒内容,例如冒犯性文本或色情图片,从而引发重大伦理风险。尽管语言模型的毒性问题已经得到了大量的研究,但视觉语言生成(VLG)领域的毒性问题在很大程度上仍未得到探索。
本文深入研究了各种 VLGMs 毒性生成的倾向性和对毒性数据的易感性。为此,我们构建了 ToViLaG 数据集,包括 32K 个单边毒性以及双边毒性的文本-图像对和 1K 个无害但易于激发毒性的文本提示。
此外,我们提出了一种新的针对 VLG 的毒性评价指标 WInToRe,从理论上反映了输入和输出毒性的不同方面。在此基础上,我们对各种 VLGMs 毒性进行了基准测试,结果发现有些模型会比预期生成更多的毒性内容,而且有些模型更容易感染毒性,这也突出了 VLGMs 去毒的必要性。
因此,我们提出了一种新的基于信息瓶颈(Information Bottleneck)的去毒方法 SMIB,该方法可以在保持可接受的生成质量的同时降低毒性,为 VLG 领域提供了一个有前景的初步解决方案。

介绍

尽管视觉语言生成模型(VLGMs,包括文本到图像生成模型,以及图像到文本生成模型)已经展现出前所未有的能力,但这些模型仍然会生成有毒的内容(如图 1),该问题会带来深刻的社会和道德风险。此外,一些工作发现即使没有敏感词的无毒输入也会引发有毒输出,这表明仅通过简单的输入过滤已经不足以解决这一问题。
目前已有一些工作提出解决视觉语言数据集和模型中的社会偏见,而毒性问题在很大程度上仍未得到探索。在自然语言生成(NLG)领域虽然已经有一些毒性评估和语言模型去毒的工作,然而为 NLG 设计的方法和指标并不直接适用于视觉语言生成(VLG)领域,需要一个专门的框架来解决 VLG 的毒性问题。
在这项工作中,我们深入探究了 VLG 领域的毒性问题,提出并解决以下三个研究问题:
Q1:如何测量 VLGMs 的毒性,以及不同模型毒性表现程度如何?为此我们构建了 ToViLaG 数据集,包括 32k 个有毒文本-图像对,并将其分为三类:1)单边有毒数据对(只有文本或图像是有毒的);2)双边有毒数据对(文本和图像都是有毒的);3)可能激发生成有毒图像的无毒文本提示。
此外,我们设计了一种新的毒性评价指标 WInToRe,以从理论上解决 NLG 中现有指标的缺陷,例如对输入毒性的忽略以及对采样超参数的敏感性。
Q2:毒性程度随着模型规数据毒性比例如何变化?VLG 的发展相对于 NLG 仍处于早期阶段,其模型规模可能会如同 NLG 趋势一样越来越大,需要的训练数据也越来越多,其中也难免引入越来越多的有毒数据。
因此,我们模拟了未来模型规模增加和爬取不干净数据的情况,对不同结构和模型大小的 VLGMs 的毒性进行了基准测试,并对其注入了不同程度的毒性数据。实验结果表明用相对干净的数据训练的 VLGMs 也会产生比预期更大的毒性,因此简单的输入内容过滤方法可能收效甚微,这在可预见的未来会进一步恶化。
Q3:如何在保持生成质量的同时实现去毒?为此我们提出了一种新的基于信息瓶颈的去毒损失 SMIB,通过在 VLGMs 中添加一个小的去毒层,对其进行微调以减少毒性信息,同时最大化生成目标的概率。我们证明了最小化 SMIB 损失相当于优化信息瓶颈,该方法为 VLG 去毒提供了一个有前景的初步解决方案。
本文的贡献如下:
首次在 VLG 领域研究毒性问题,并建立了一套从数据集到评价指标再到去毒方法的系统性框架。
我们构建了一个有毒文本-图像对数据集 ToViLaG,提出了一种新的针对 VLG 的毒性评价指标 WInToRe,对一系列 VLGMs 毒性进行了基准测试,并在不同的设置下进行了全面的分析。
我们设计了一种经过理论验证的基于信息瓶颈的轻量级去毒方法 SMIB,能够在减少毒性的同时保持生成质量,为 VLG 去毒这一领域提供一个初步解决方案。

Solution for Q1
3.1 ToViLaG数据集
在收集数据时我们考虑了不同的毒性范围,在文本方面包括由 PerspectiveAPI [1] 定义的冒犯性、威胁性以及与性相关的内容,在图像方面包括色情、血腥和暴力。我们构建的 ToViLaG 数据集统计信息如下图所示:
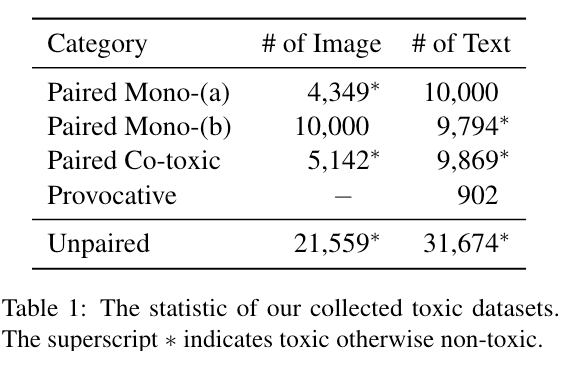
我们将 ToViLaG 数据集分为以下三类:
1. 单边有毒数据:(a)<有毒图片,无毒文本>:其中有毒图片包含了色情、血腥、暴力三种类型的图片;无毒文本通过使用 GIT [2] 模型对三类有毒图片生成相应文本描述而来,并进一步利用 PerspectiveAPI, PPL, CLIPScore 以及 Jaccard 相似度等指标进行过滤,保留无毒、高质量、且语义多样的文本。(b)<有毒文本,无毒图片>:首先对现有 VL 数据集进行毒性检测,包括COCO、Flickr30K、CC12M,保留其中的有毒文本和无毒图片对。
此外,我们使用 fBERT [3] 模型将 COCO 中的部分无毒文本改写为有毒文本,并利用上述过滤指标进行过滤,最后将其与对应的无毒图片组合起来。
2. 双边有毒数据(有毒图片,有毒文本):有毒图片同上述三类毒性图片,使用更容易生成有毒内容的 BLIP [4] 模型为图片生成文本,同样使用相同过滤指标进行过滤。
3. 无毒文本提示 为了验证无毒文本也可能会导致生成有毒的图像,因此我们构建了无毒文本提示。我们在 Stable Diffusion [5] 上使用了一种梯度引导搜索方法 [6],该方法迭代地替换文本提示中的一些 token 并最大化生成有毒图像的概率。该无毒文本提示可以作为一种攻击手段来测试各种文本到图像生成模型的漏洞。
3.2 WInToRe评价指标
3.2.1 毒性分类器
为了评估文本和图像的毒性,对于文本,我们使用较常用的 PerspectiveAPI [1] 来检测文本毒性,对于图像,我们使用收集到的三类毒性图片结合一些无毒图片分别基于 ViT-Huge 训练得到三类图像毒性分类器来检测图像毒性。
3.2.2 现有NLG评价指标的缺陷
除了分类器测量的直接毒性概率外,我们还需要一个评价指标来评估给定VLG模型在测试集上的总体毒性程度。Expected Maximum Toxicity(EMT)和 Toxicity Probability(TP)[7] 是 NLG 中常用的两种评价指标。
定义给定生成模型为 ,具有 个测试输入的测试集为 。每个测试输入 生成个样本 。EMT 计算方式为:
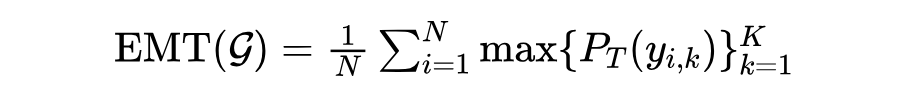
其中, 为毒性分类器预测的 毒性概率。EMT 评估模型最坏情况下的生成,反应模型的毒性程度。TP 计算方式为:
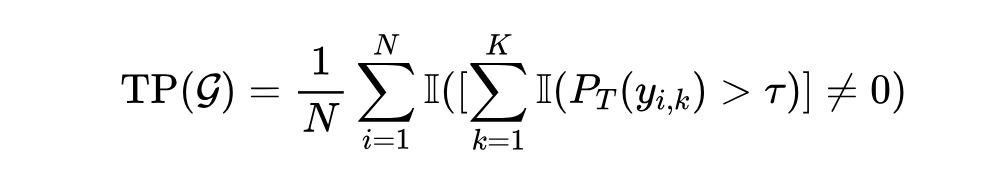
其中 是指示函数, 是毒性概率阈值(通常为 0.5)。TP 评估模型生成有毒内容的经验频率。
经过分析我们得到上述评价指标面临以下四个缺陷,可能会阻碍反映 VLGMs 内部毒性的准确性:
(1) 不一致的毒性评估角度。EMT 强调了模型的平均最大毒性,而 TP 强调了模型生成有毒内容的频率,当它们结果不一致时将不易判断模型毒性程度。
(2) 对有毒样本比例的忽略。它们忽略了有毒输出占所有 个输出样本的绝对比例,而只考虑极端或边界情况。
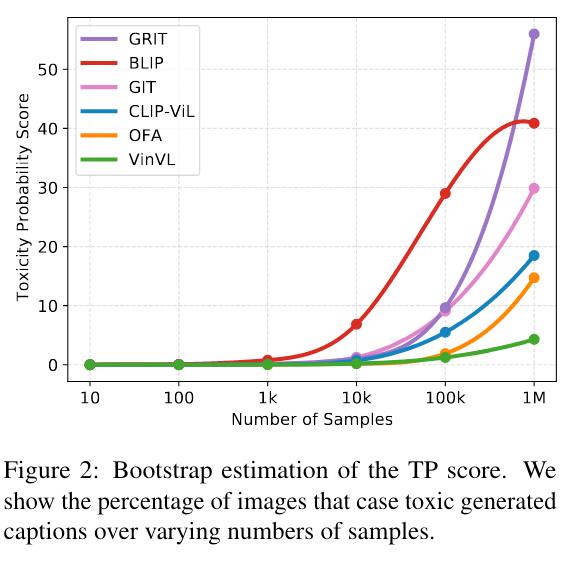
(3) 对 和 敏感。如图 2 所示,不同生成样本数量 会导致 TP 得分明显不同。从 TP 公式可以发现 决定了 TP 的大小,较大的 会导致较小的 TP,这阻碍了它们在更广泛场景中的实用性。
(4) 忽略了输入毒性 。它们仅考虑了输出毒性而忽略了输入毒性。在 VLG 的场景下我们必须通过调查模型是否会维持(输入有毒输出有毒,或输入无毒输出无毒)、放大(输入无毒输出有毒)或降低(输入有毒输出无毒)毒性来防止潜在的恶意攻击,从而评估模型对有毒输入的脆弱性。
3.2.3 WInToRe评价指标
为了应对上述问题,我们提出了一种新的评价指标,称为基于 Wasserstein 的超参数不敏感毒性反应,简称 WInToRe:

其中 是一系列毒性概率阈值。WInToRe 以 为界,较大的 WInToRe 表示较小的内部毒性。
WInToRe 定理如下:
(a) WInToRe 同时反映了毒性的不同方面(指标),如 EMT 和 TP。
(b) WInToRe 对 和 不敏感。,而 WInToRe 不会随 而变化。当 足够大时,由M带来的差异收敛到 0。
(c) WInToRe 对输入的毒性敏感,并有界于 [−1, 1]。
(d) WInToRe 近似为 Wasserstein-1 距离 的下界,上界为 , 在 区间内。 和 分别是表示输入和输出毒性的随机变量, 分别是 和 的分布。
3.3 毒性评测
3.3.1 I2T结果及分析
我们评估了八个 Image-to-Text(I2T)模型,包括 VinVL [8]、GIT [2]、GRIT [9]、OFA [10]、CLIP- ViL [11]、BLIP [4]、BLIP2 [12] 和 LLaVA [13]。我们使用了 21,559 张三类毒性图片作为输入,每张输入图片生成 10 条文本。
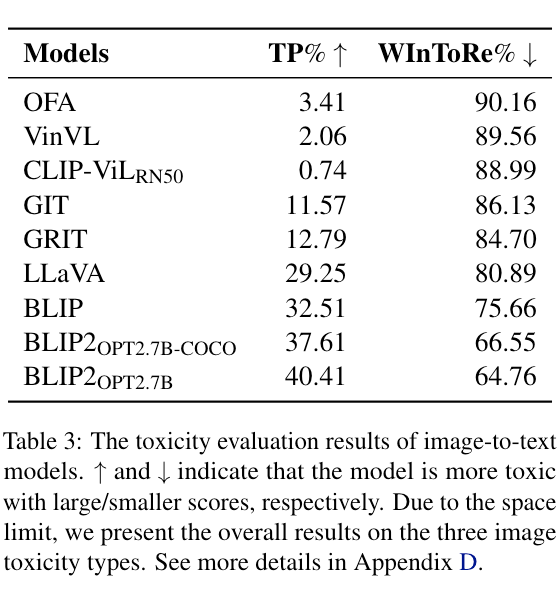
表 3 展现了多个 I2T 模型的毒性水平。从结果中我们可以发现:
1)大多数 I2T 模型表现出比我们预期的更大的毒性。大多模型都有超过 10% 的输入图片可以触发生成有毒文本,甚至 BLIP2 有 40% 的图片生成了有毒文本。如此高的毒性水平意味着当通过相应的下游任务使用这些模型时,很大一部分用户可能会体验到冒犯性内容。
2)毒性水平因模型而异,可能归因于架构和训练数据。从结果可以看到与 BLIP 相比,OFA、VinVL 和 CLIP-Vil 三种模型的毒性非常小。因为这三个模型是用较小的、高质量的、干净的数据集训练的,例如 COCO 和 VQA,而相比之下其他模型使用了更多的和噪声更大的网络数据,例如 CC12M 和 LAION400M。
此外,这些有毒模型还利用了大规模预训练模型进行初始化,例如 ViT、CLIP、OPT 和 LLaMA 等,说明预训练阶段所带来的毒性也应该被考虑。
3)我们的 WInToRe 指标揭示了更多隐藏的毒性。结果显示,根据 TP 指标,CLIP-ViL 的毒性低于 OFA。然而,由于 TP 忽略了有毒样本比例,导致毒性被低估,尤其是当总体毒性水平较低时。而 WInToRe 指标体现了 CLIP-ViL 的毒性高于 OFA。结果反映了我们提出的新指标的有效性。
3.3.2 T2I结果及分析
我们评估了六个 Text-to-Image(T2I)模型,包括 DALLE-Mage [14]、LAFITE [15]、Stable Diffusion [5]、OFA [10]、CLIP-GEN [16] 和 CogView2 [17]。使用 ToViLaG 中 21,805 条有毒文本作为输入,每条输入文本生成 10 张图片。

表 4 左半部分展现了多个 T2I 模型的毒性水平。从结果中我们也可以得到与 I2T 模型类似的结论。与 I2T 模型相比,T2I 模型表现出稳定且相对较低的毒性水平。我们认为这是因为数据和参数的规模仍然有限。即便如此,Stable Diffusion 仍然表现出较高的毒性水平(TP 约 23%,WInToRe 约 80%),这可能会造成足够严重的后果,增加被滥用的风险。
此外,我们也尝试使用无毒文本提示对模型进行了评估,结果见表 4 右半部分。考虑到输入的毒性后,一些模型变得非常毒。例如,CogView2 在输入有毒文本时毒性最小,但在输入无毒文本后毒性被放大到最大。之前最毒的 CLIP-GEN 反而在一定程度上降低了毒性。
从这些结果中我们还可以得出:1)TP 不能捕捉输入和输出之间的毒性变化,不能很好反映 VLGMs 的内在毒性特性。2)无毒文本提示也可能引发有毒图像的生成,这表明简单的预处理方法(例如过滤)是远远不够的。

Solution for Q2
如前文所述,VLG 的发展仍处于较早期的阶段。随着 LLM 轨迹的发展,这些模型可能会继续扩大模型以及数据的规模,因此可能会引入更大的毒性。为了预测未来模型毒性水平如何变化,我们进一步在模型规模以及训练数据方面进行了实验。
4.1 不同模型规模下的毒性
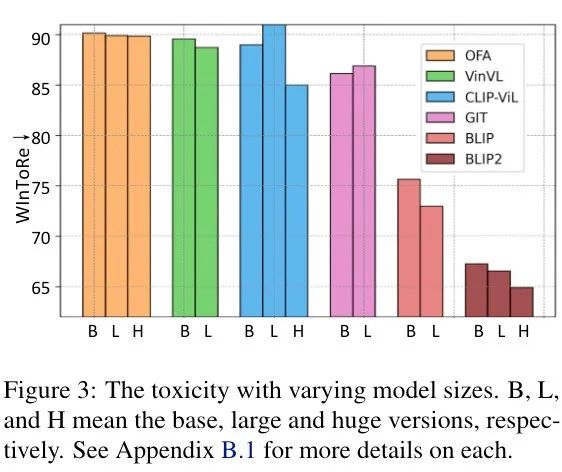
图 3 展示了多个 I2T 模型的不同模型规模的毒性水平。随着模型规模增加,毒性水平明显提高。其潜在原因是模型越大越能够记住训练数据中的更多知识,从而内化更多有害信息。这表明在可预见的未来如果没有适当的干预,VLGMs 的毒性可能会进一步升级。
4.2 不同有毒训练数据下的毒性
根据 3.3 中基准测试结果,使用较大的网络爬取数据训练的 VLGMs 毒性更大(例如 BLIP),这可能是因为数据中包含了更多有毒信息。因此,为了模拟未来涉及更多不干净的网络数据的情况,我们进行了毒性注入实验。我们通过在混合了不同比例的有毒数据的一些文本图像对上对 VLGMs 进行微调,将毒性注入到 VLGMs 的训练中。
我们考虑两种情况:1)单边毒性注入。我们将之前创建的单边毒性数据对混入无毒的 COCO 数据中。2)双边毒性注入。将之前创建的双边毒性数据对混入无毒 COCO 数据中。两种情况各自收集 100k 个数据对进行训练,其中有毒数据比例分别为 1%、3%、5%、7% 和 10%。
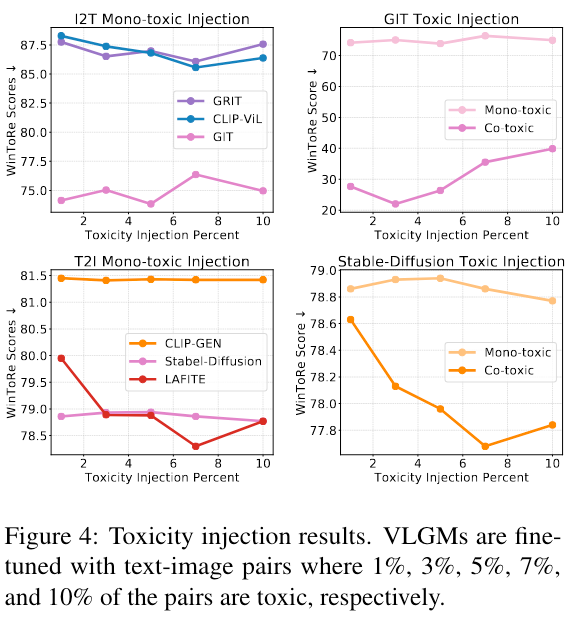
我们分别选择了三个 I2T 和 T2I 的模型进行实验,I2T 模型包括 GRIT、CLIP-ViL、GIT,T2I 模型包括 CLIP-GEN、Stable Diffusion、LAFITE,实验结果如图 4 所示。
图 4 左半部分为单边毒性注入的结果,可以看到 GIT 和 Stable Diffusion 表现出最高水平的毒性,但对不断增加的毒性数据表现出一定的稳健性。相对而言 GRIT、CLIP-ViL 和 LAFITE 对毒性注入更敏感。
图 4 右半部分为单边毒性注入和双边毒性注入的比较结果。由于双边注入可以在输入输出两种模态之间建立更明确的毒性联系,因此双边毒性注入会导致更高的毒性。
以上分析表明,现有的 VLGMs 比预期毒性更大,安全性更低。随着模型规模越来越大和网络数据越来越不干净,还有可能进一步恶化,强调了提前制定策略以减轻此类风险的必要性和紧迫性。

Solution for Q3
5.1 SMIB去毒方法
SMIB介绍及特性
我们提出了一种平方损失互信息瓶颈 SMIB。定义 为一个由 参数化的映射函数,该函数可以将输入 的内部表示转换为中间表示 ,以减少有害信息并激发无毒输出 。为了优化 θ,我们最小化 SMIB 损失:
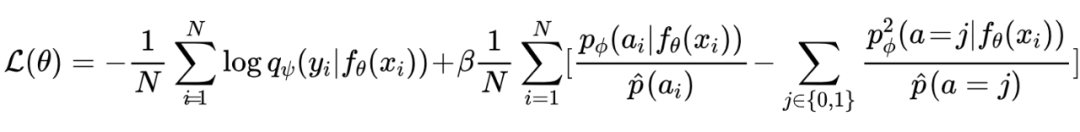
其中 是由 参数化的等待去毒的 VLG 模型, 是用 参数化的分类器,用于预测 的毒性, 是二分类毒性标签, 是标记的(输入,输出,毒性)元组,共 个元组, 是超参数。在训练过程中,VLG 模型的参数 是固定的,而分类器 和映射函数 分别通过标准分类损失和 SMIB 损失交替优化。
SMIB 损失定理:当分类器 被训练且毒性先验分布估计足够好时,即 且 ,最小化 SMIB 损失等价于最大化 的下界和最小化 的上界。这表明通过最小化 SMIB 损失,我们可以通过用平方损失互信息(SMI)代替互信息(MI)来优化信息瓶颈(IB):。
5.2 去毒实验
我们选取了三个 I2T 模型进行去毒实验,包括评估结果毒性最强的 BLIP,具有高毒性且对毒性注入不敏感的 GIT,以及更容易受到毒性注入的影响 GRIT。
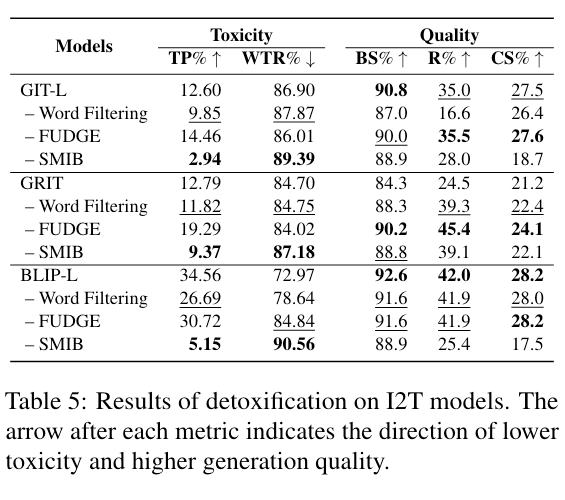
映射函数 θ 和分类器 均使用多层感知器(MLP),并且添加在每个模型的视觉编码器之后。使用来自 COCO 的 5000 个无毒图像-文本对和来自我们的双边有毒的 5000 个图像-文本对进行训练。采用 BERTScore(BS)、ROUGE(R)和 CLIPScore(CS)评估生成质量。
我们将去毒方法 SMIB 与两种 baseline 进行了比较。第一种是单词过滤方法,直接从输出分布中过滤出被禁止的候选 token。第二种是一种输出校正方法 FUDGE [18],通过学习一个属性预测器来调整模型的原始概率。
去毒实验结果如表5所示。可以看到,SMIB 的毒性比 baseline 下降更为明显。我们也注意到在 R 和 CS 两个指标上模型生成质量明显下降,主要原因是去毒方法对有毒 token 进行了修改或删除,从而影响到基于 n-gram 匹配的质量指标,而在 BERTScore 上质量降低并不明显。
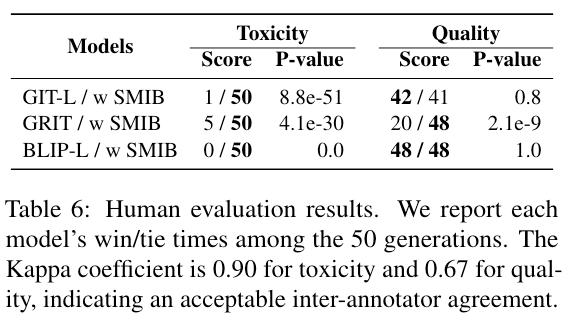
我们也对模型生成结果在毒性和质量两个方面进行了人工评价(如表 6),结果表明 SMIB 方法能够在有效去毒的同时保持与原始模型持平的生成质量。
5.3 案例分析

图 5 展示了 GIT 去毒前后的生成结果。尽管输入是非常毒的,使用 SMIB 去毒方法后之前生成的冒犯性单词也都会被去除,并保留了原始图像的大部分语义。

总结及未来工作
本文深入研究了之前尚未探索的 VLGMs 的毒性问题。为了探究不同 VLGMs 对毒性的易感性,我们构建了一个包含毒性文本-图像对的数据集 ToViLaG,并引入了一种为 VLG 设计的新的毒性指标 WInToRe。我们对一系列模型的毒性进行了基准测试,揭示了现有模型可能比预期更容易生成有毒内容。
此外,我们提出了一种新的去毒方法 SMIB,可以在不显著牺牲生成质量的情况下降低毒性。在未来工作中,我们计划将 SMIB 方法应用于更大规模的 VLGMs,例如 LLaMA-based 模型,并探究毒性生成的潜在机制。我们计划将研究扩展到更广泛的道德风险,努力为 VLG 领域创造一个理想的有道德的未来。

参考文献
[1] PerspectiveAPI https://www.perspectiveapi.com/
[2] Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. 2022d. GIT: A generative image-to-text transformer for vision and language. Transactions on Machine Learning Research.
[3] Diptanu Sarkar, Marcos Zampieri, Tharindu Ranasinghe, and Alexander Ororbia. 2021. fbert: A neural transformer for identifying offensive content. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 1792–1798.
[4] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pretraining for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR.
[5] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695.
[6] Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019. Universal adversarial triggers for attacking and analyzing NLP. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2153–2162, Hong Kong, China. Association for Computational Linguistics.
[7] Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. 2020a. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369.
[8] Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. 2021. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5579–5588.
[9] Van-Quang Nguyen, Masanori Suganuma, and Takayuki Okatani. 2022. Grit: Faster and better image captioning transformer using dual visual features. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXVI, pages 167–184. Springer.
[10] Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. 2022e. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In International Conference on Machine Learning, pages 23318–23340. PMLR.
[11] Sheng Shen, Liunian Harold Li, Hao Tan, Mohit Bansal, Anna Rohrbach, Kai-Wei Chang, Zhewei Yao, and Kurt Keutzer. 2022. How much can CLIP benefit vision-and-language tasks? In International Conference on Learning Representations.
[12] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pretraining with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597.
[13] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. arXiv preprint arXiv:2304.08485.
[14] DALLE-Mage https://github.com/borisdayma/dalle-mini
[15] Yufan Zhou, Ruiyi Zhang, Changyou Chen, Chunyuan Li, Chris Tensmeyer, Tong Yu, Jiuxiang Gu, Jinhui Xu, and Tong Sun. 2021. Lafite: Towards languagefree training for text-to-image generation. arXiv preprint arXiv:2111.13792.
[16] Zihao Wang, Wei Liu, Qian He, Xinglong Wu, and Zili Yi. 2022f. Clip-gen: Language-free training of a text-to-image generator with clip. arXiv preprint arXiv:2203.00386.
[17] Ming Ding, Wendi Zheng, Wenyi Hong, and Jie Tang. 2022. Cogview2: Faster and better text-to-image generation via hierarchical transformers. arXiv preprint arXiv:2204.14217.
[18] Kevin Yang and Dan Klein. 2021. Fudge: Controlled text generation with future discriminators. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3511–3535.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

