
- 1Docker-13:Docker安装Hbase
- 2关于快速排序算法的学习心得_排序实验实训总结
- 3OceanBase 分布式数据库【信创/国产化】- OceanBase 数据库整体架构
- 4RK3588 & Android12 调试 RTL8852BE(wifi篇)_rk8852be
- 5VHDL实现数字频率计的设计_数字频率计设计vhdl
- 6基于SSM的文化遗产的保护与旅游开发系统(有报告)。Javaee项目。ssm项目。
- 7讲真,做Python一定不要只会一个方向!
- 8PC电脑 VMware安装的linux CentOs7如何扩容磁盘?_linux虚拟机安装好之后还能设置磁盘大小码
- 9机器学习介绍_setlabelcol
- 10Cesium 核心概念 核心接口_cesuim可以实现的功能
大数据名词及基本原理_大数据基本原理
赞
踩
介绍maxcompute、hadoop、hive、hbase、spark、flink、adb、clickhouse、presto、hawq、greenplum、dremio、kudu、kafka等大数据领域相关技术、工具。
一、MaxCompute:
MaxCompute以表的形式存储数据,支持多种数据类型版本说明(1.0, 2.0, Hive),并对外提供SQL查询功能。您可以将MaxCompute作为传统的数据库软件操作,但其却能处理TB、PB级别的海量数据。
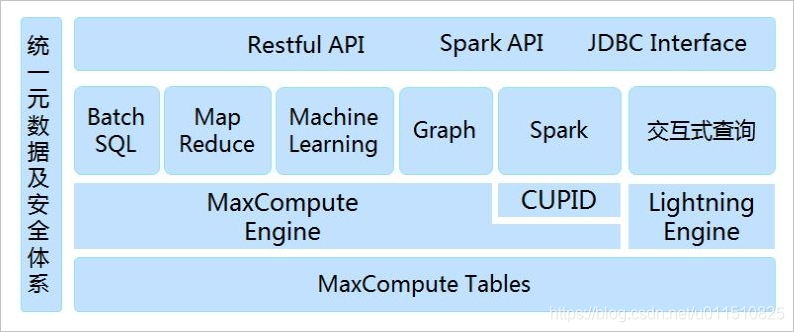
二、hadoop
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。
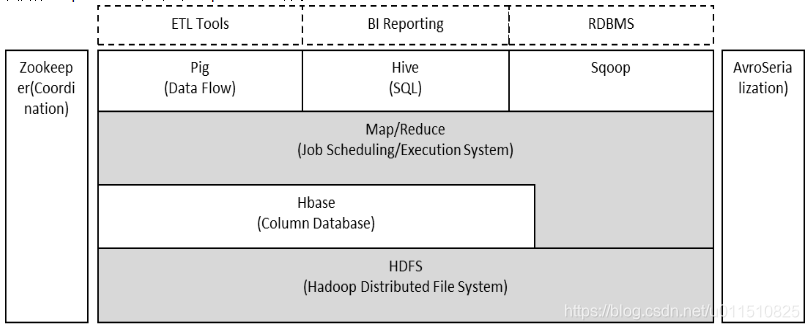
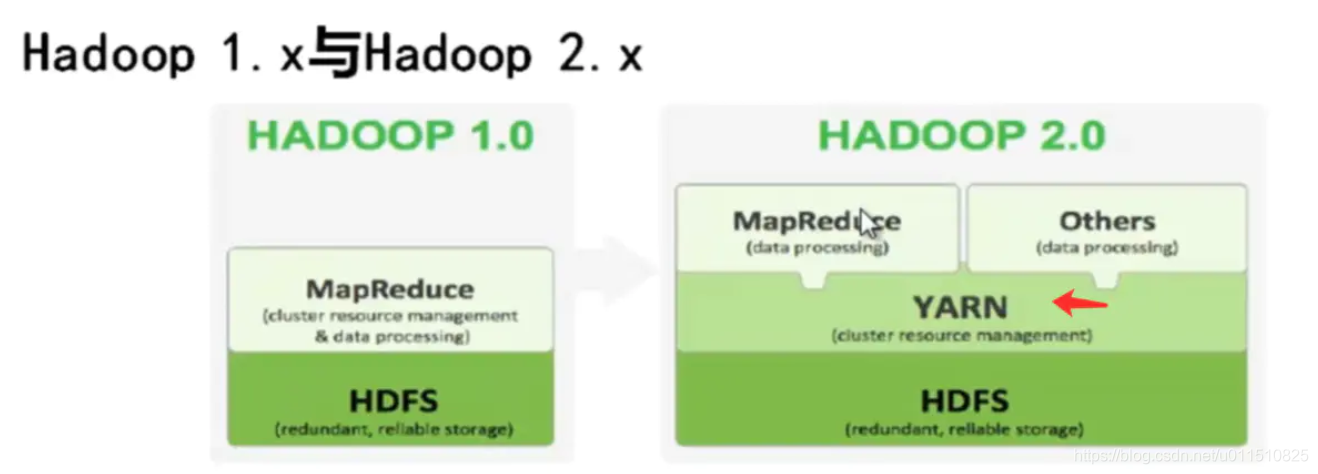
2.1 Hive(数据仓库工具)
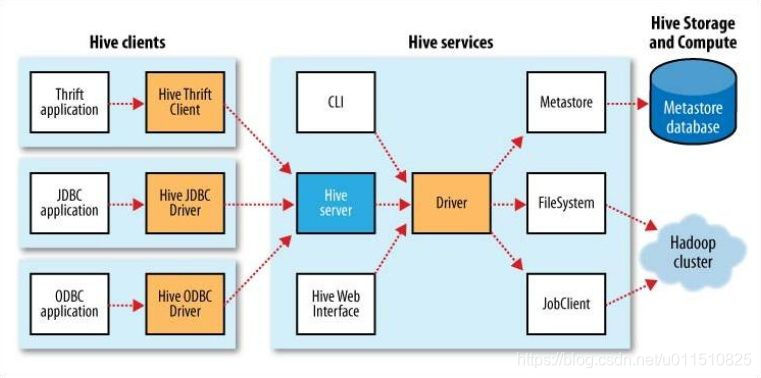
hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。
Hive选择Hadoop来存储和处理数据,因为Hadoop有较好的性价比。Hive设计的目标是让精通SQL技能(Java较弱的)分析师,能够从存放在HDFS的大规模数据集上,运行查询。
表模式等元数据存放在名为metastore的数据库中。默认的metastore在本地运行。此时创建的Hive表在本地上,无法与其它用户共享。
2.2HBase
HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
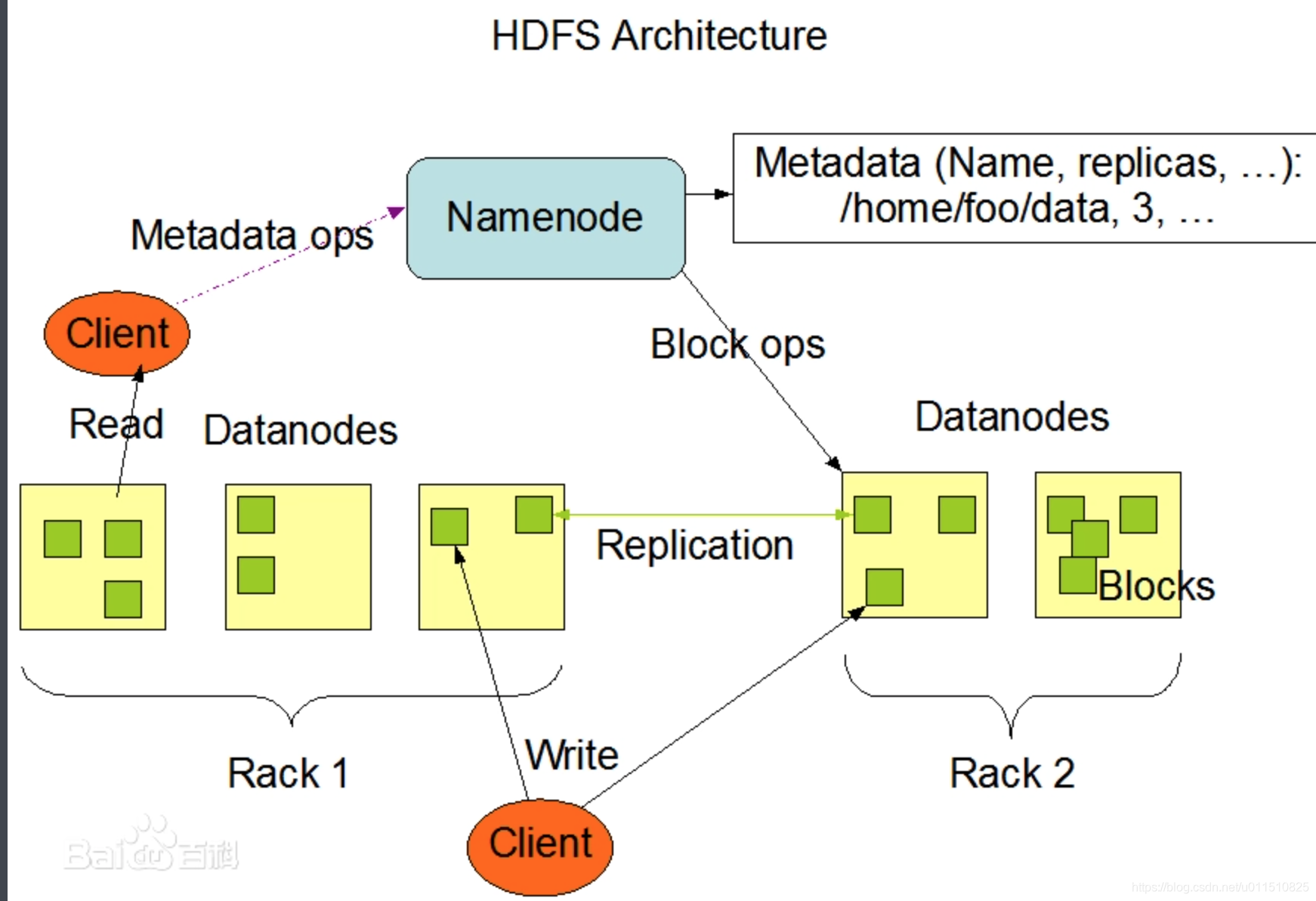
2.3 hdfs
HDFS,全称Hadoop Distributed File System,意思是分布式文件系统。
三、spark
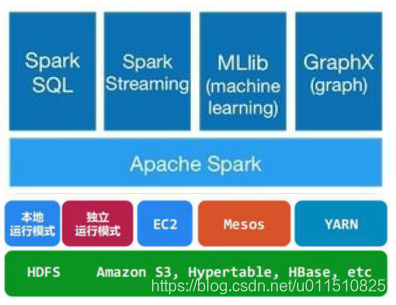
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为
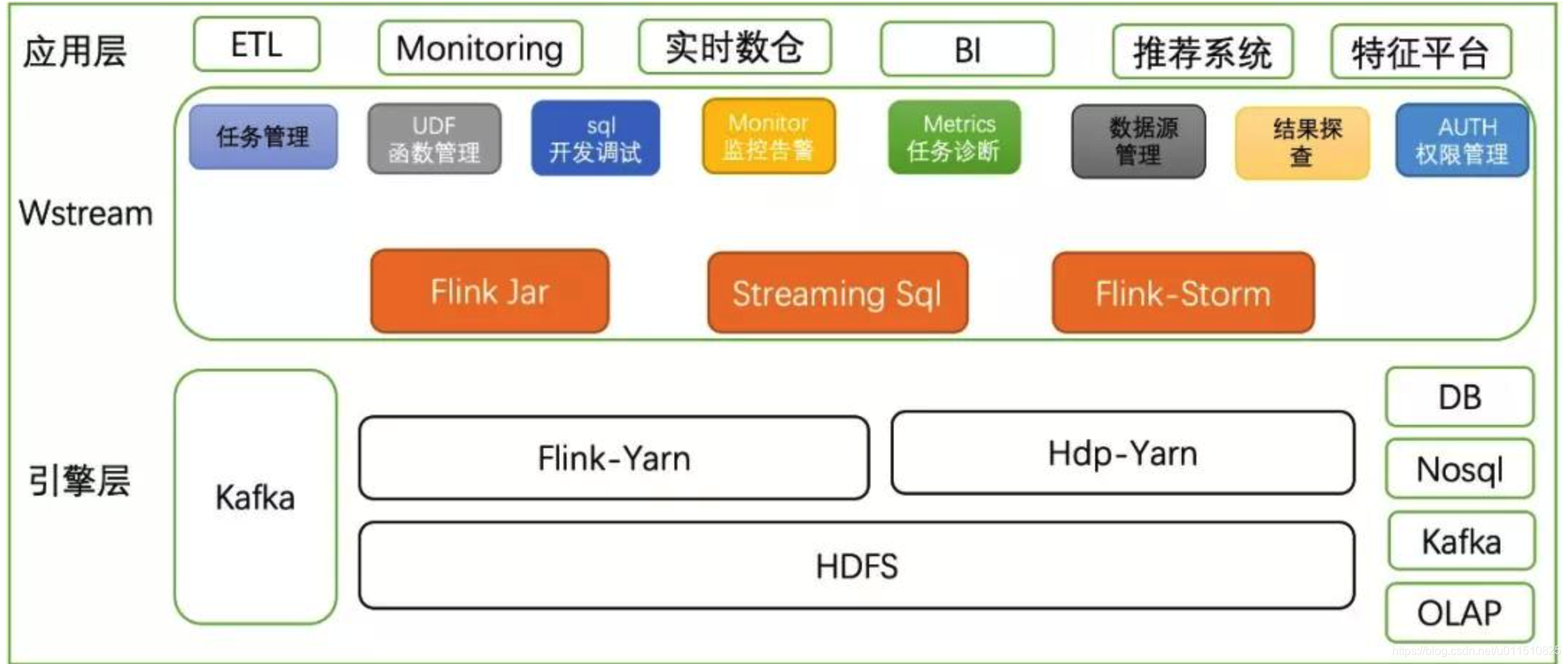
四、Flink
Apache Flink是由Apache软件基金会开发的开源流处理框架。并且能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用。
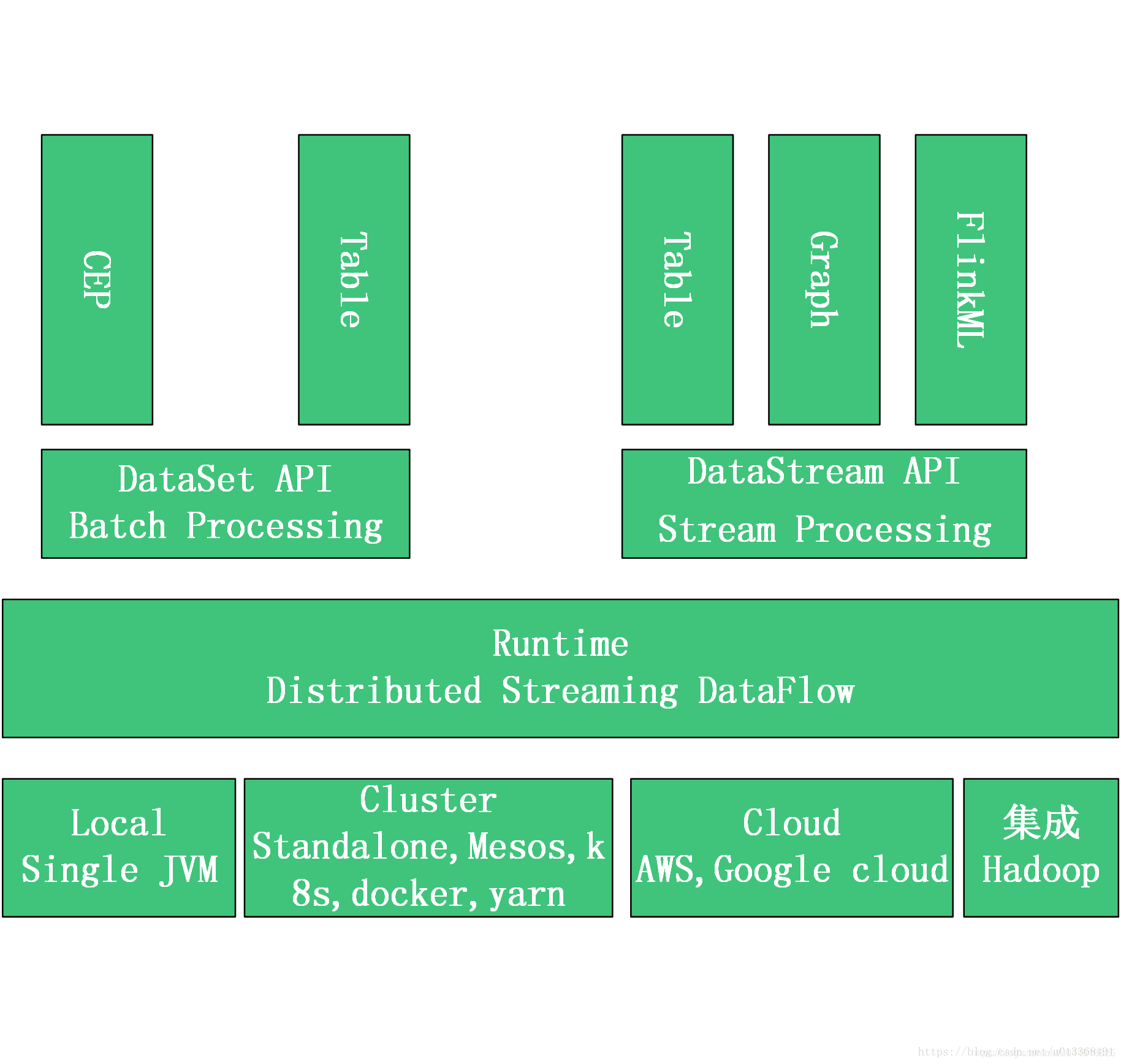
从上图可知,Flink从另一个角度看待流处理和批处理,将2者统一起来。Flink是完全支持流处理,也就是说流处理看待数据是无界限的,批处理作为流处理的一种特殊情况,数据只是被定义为有界的。
Flink可以与Hadoop集成,可以方便读取Hadoop项目中的组件数据,如hive,hdfs及Hbase等。以kafka作为流式的数据源,直接可以重用storm代码。
五、clickHouse
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。
什么是列式存储?
以下面的表为例:
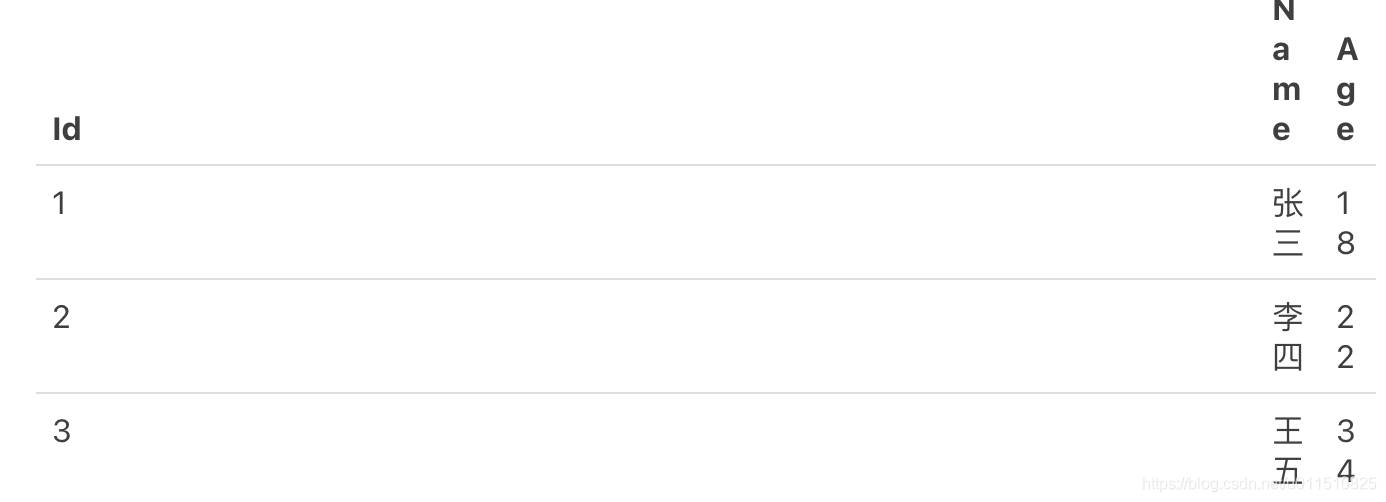
采用行式存储时,数据在磁盘上的组织结构为:
好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。

而采用列式存储时,数据在磁盘上的组织结构为:

这时想查所有人的年龄只需把年龄那一列拿出来就可以了。
clickhouse对于单表查询聚合性能优势很明显。但是对于多表联查,就会有一些性能损耗。
(首先多表关联查询要优化成子查询的方式,比如join关联的表改写成in子查询的语句,其次多个join不要平级写,改成多层嵌套的方式,即多包一层的方式书写,目的是在内层减少数据再和外层的关联,最后若使用的是分布式表的join,那么有个distributed_product_mode参数进行配置,allow\global\local三个选项,默认deny(deny即两张分布式表join会报错,改成allow允许join执行,逻辑是将SQL下发给每台机器,在每台机器上执行join,会在机器之间进行大量的数据shuffle,性能不是很好。global是先将子查询下推给每台机器,然后将数据收集到一台机器上,然后在一台机器上反向推给其它节点,也称为broadcast join,相对于join网络shuffle数据量小些。local join,当写数据时,采用hash分区将相同key的数据落在同一台机器上,join时就不需要跨节点的join了,只需要将两个分区表改写为local表,然后分别在单台机器上进行join操作,最后将结果汇总起来,这种在hash对齐的情况下,避免了节点间数据shuffle)
六、Presto架构
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎。
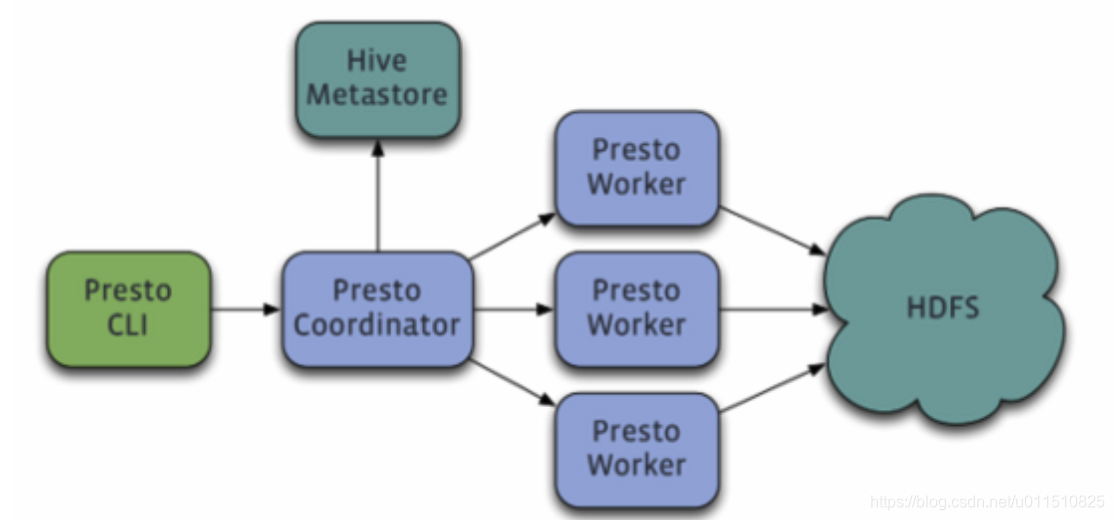
Presto低延迟原理
- 完全基于内存的并行计算
- 流水线式计算作业
- 本地化计算
- 动态编译执行计划
- GC控制
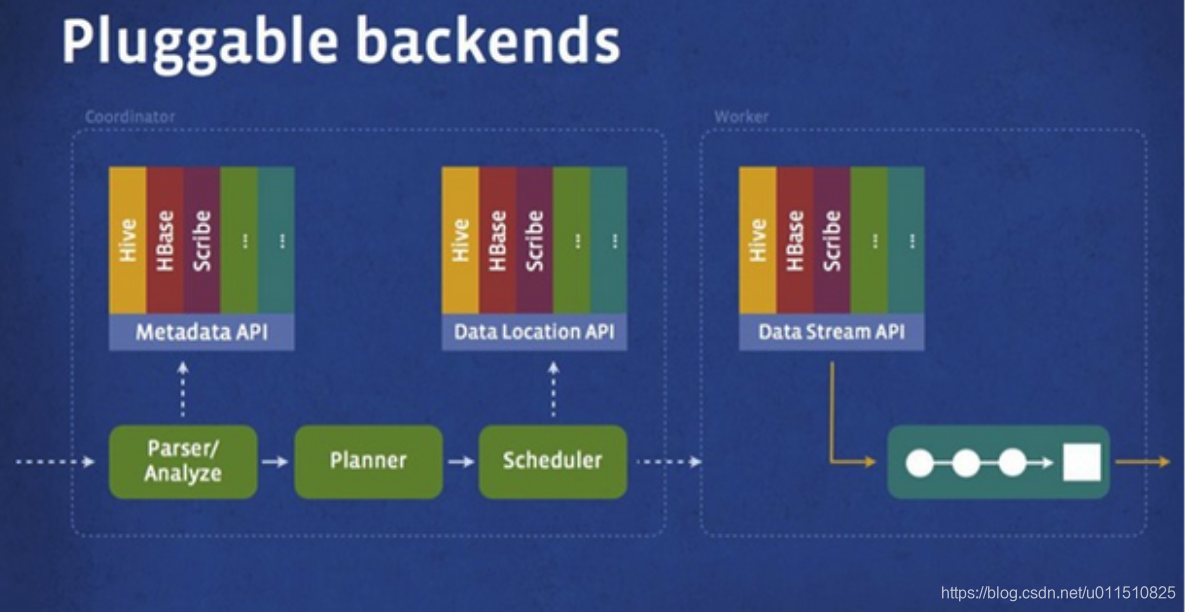
Presto存储插件
- Presto设计了一个简单的数据存储的抽象层, 来满足在不同数据存储系统之上都可以使用SQL进行查询。
- 存储插件(连接器,connector)只需要提供实现以下操作的接口, 包括对元数据(metadata)的提取,获得数据存储的位置,获取数据本身的操作等。
- 除了我们主要使用的Hive/HDFS后台系统之外, 我们也开发了一些连接其他系统的Presto 连接器,包括HBase,Scribe和定制开发的系统
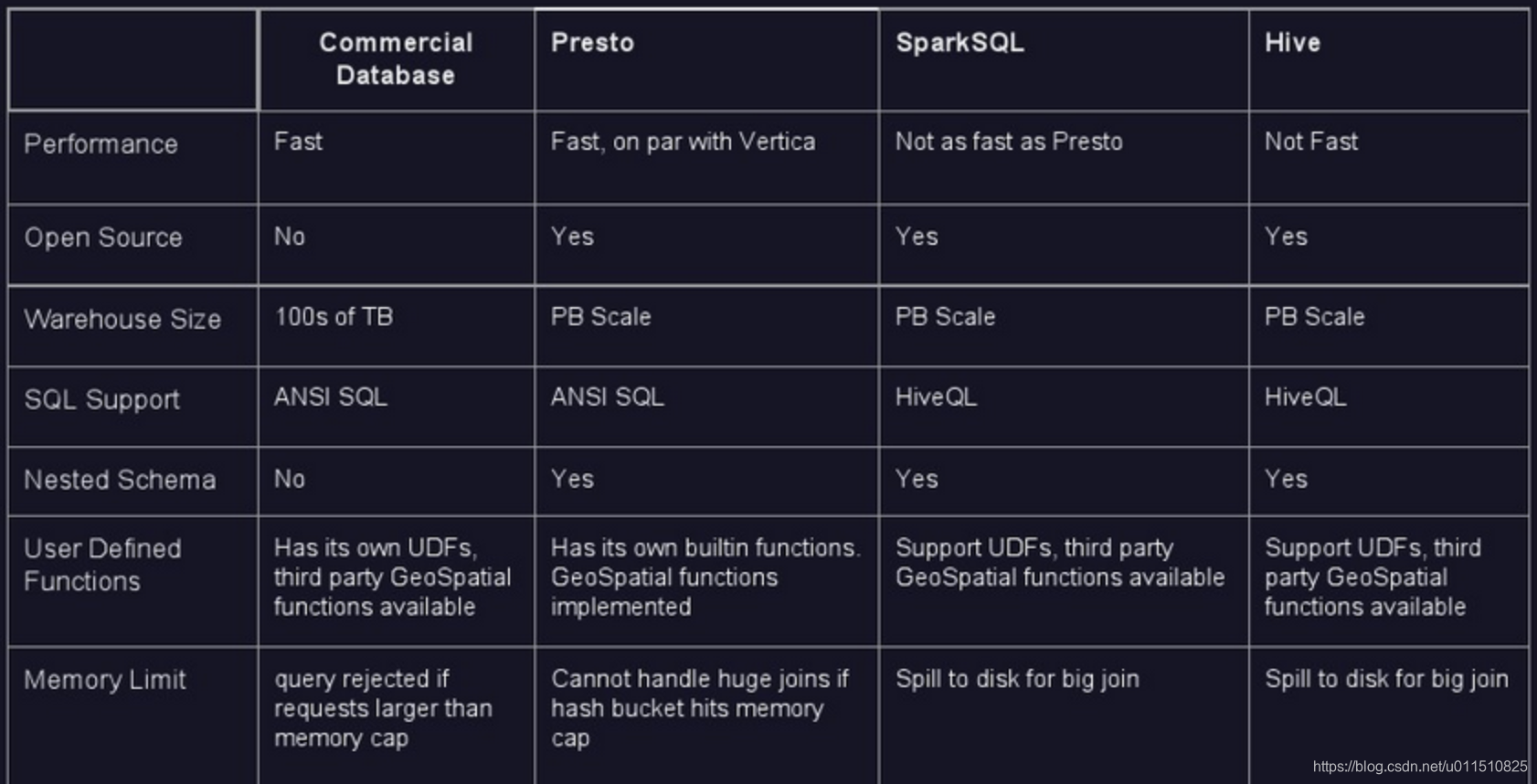
presto引擎对比:
与hive、SparkSQL对比结果图
七、Greenplum:
提供新型企业级数据仓库(EDW), 专注于OLAP系统数据引擎开发。海量并行处理(Massively Parallel Processing) DBMS:
Greenplum的架构采用了MPP(大规模并行处理),在 MPP 系统中,每个 SMP节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution) 。
基于PostgreSQL 8.2开源版本, 基于PostgreSQL增加了并行度的处理;。
八、KUDU
KUDU 的定位是 「Fast Analytics on Fast Data」,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
KUDU在 HDFS 和 HBase 这两个中平衡了随机读写和批量分析的性能,既支持了SQL实时查询,也支持了数据更新插入操作
kudu和hbase的区别和联系?
前提
hbase的物理模型是master和regionserver,regionserver存储的是region,region里边很有很多store,一个store对应一个列簇,一个store中有一个memstore和多个storefile,store的底层是hfile,hfile是hadoop的二进制文件,其中HFile和HLog是hbase两大文件存储格式,HFile用于存储数据,HLog保证可以写入到HFile中;
kudu的物理模型是master和tserver,其中table根据hash和range分区,分为多个tablet存储到tserver中,tablet分为leader和follower,leader负责写请求,follower负责读请求,总结来说,一个ts可以服务多个tablet,一个tablet可以被多个ts服务(基于tablet的分区,最低为2个分区);
联系
1、设计理念和想法是一致的;
2、kudu的思想是基于hbase的,之前cloudera公司向对hbase改造,支持大数据量更新,可是由于改动源码太大,所以todd直接开发了kudu;
3、hbase基于rowkey查询和kudu基于主键查询是很快的;
九、总结
流行的开源OLAP引擎/数据库:

Impala,Presto,SparkSQL,HAWQ都是内存式引擎,本身不存储数据。GreenPlum,ClickHouse都是DBMS,有自己的数据存储机制。
Impala: 目前我们正在使用的内存引擎,CDH力推,与hive共享metadata。优点是快,缺点是容易爆内存,不支持update/delete(OLAP的通病),不支持ORC格式,UDF不支持SQL编写。不支持PLSQL(hive2后有hplsql)但默认是MR引擎,在impala中不能用。
Presto: 优点是快,跨数据源查询,支持标准SQL。
SparkSQL: 优点是稳定,适合跑批,对ORC,parquet格式有原生支持,UDF使用方便。缺点是对JVM的实际使用内存过高,且不同的spark app之间缺乏有效的共享内存机制, 之前调查过Tachyon 和ignite,都是可以实现spark的共享式RDD。
HAWQ: 全名(hadoop with query)hadoop自家出的大数据平台MPP架构的内存式分布式引擎,设计之初参考Greenplum,早期叫GOH(greenplum on hadoop),对Hive/hbase/hdfs有原生的支持,速度快,支持全语言的UDF编写(包含SQL),符合TPC-DS规格(完全兼容SQL标准),支持窗口函数和高级聚合函数,支持kerberos对表级别的权限控制。线性扩展。但现在CDH和HDP合并之后对HAWQ兼容性不能保证,因此未来不太看好。
GreenPlum: MPP架构的开源产品。
ClickHouse: MPP架构开源产品。


