- 1软件测试工程师--面试题_uftuif
- 2用Python 开发植物大战僵尸游戏_python中怎么做植物大战僵尸
- 3在MAC系统中使用mysql,出现mysql: command not found的情况_command not found: mysql
- 4【点云论文速读】6D位姿估计
- 5共识问题:区块链如何确认记账权?_区块链候选记账权
- 6python sys os time random模块_pycharm安装sys os time 模块
- 7Git重修系列 ------ Git的使用和常用命令总结
- 8uniapp tabBar角标问题_uniapp再tabbar上添加动态的数字角标
- 915个超实用Python文本处理案例分享,快点码住!_python关于文件经典例子
- 10auditd 用户审计详解
k-means、决策树、svm算法总结_验二:weka分类/聚类: 1、分类:实现knn、决策树、svm、adaboost中至少两组算法,设
赞
踩
一、k-means算法
聚类算法:
一种典型的 无监督 学习算法,主要用于将相似的样本自动归到一个类别中。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
1.1聚类算法在现实中的作用
用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
基于位置信息的商业推送,新闻聚类,筛选排序
图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
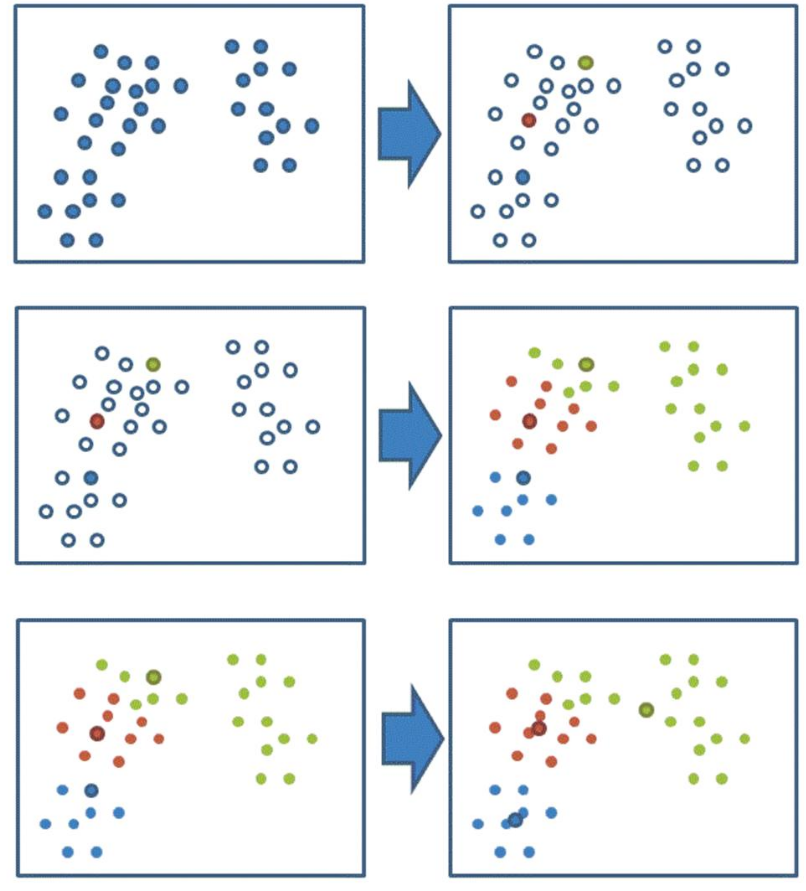
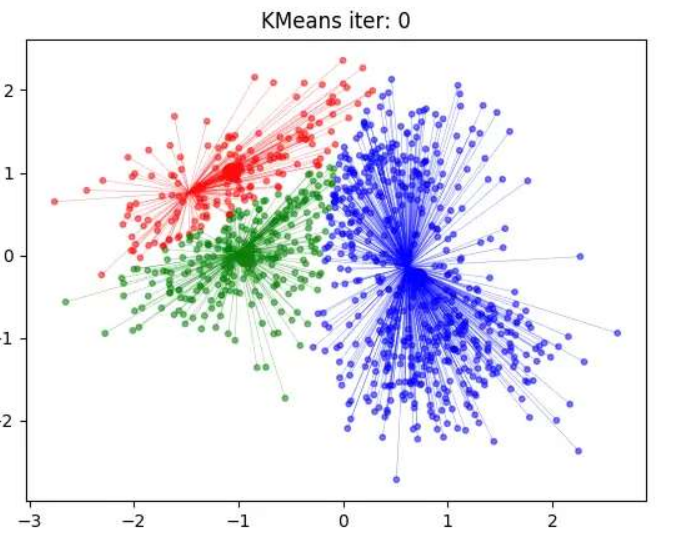
1.2 k-means聚类步骤
k-means其实包含两层内容:K表示初始中心点个数(计划聚类数),means求中心点到其他数据点距离的平均值。
具体步骤如下:
1.随机设置K个特征空间内的点作为初始的聚类中心。
2.对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别。
3.接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)。
4.如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程。
K-means聚类实现流程:
事先 确定常数K ,常数K意味着最终的聚类类别数;
随机 选定初始点为质心 ,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,
接着,重新计算 每个类的质心(即为类中心),重复这样的过程,直到 质心不再改变,
最终就确定了每个样本所属的类别以及每个类的质心。
注意:由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
二、决策树算法
决策树是监督学习的分类算法, 训练决策树需要有标签的数据。
训练决策树模型需要考虑的问题:
1.特征选择:
选择哪个特征开始生长决策树,挑选分类能力强的特征
2.决策树的生长决策树的剪枝









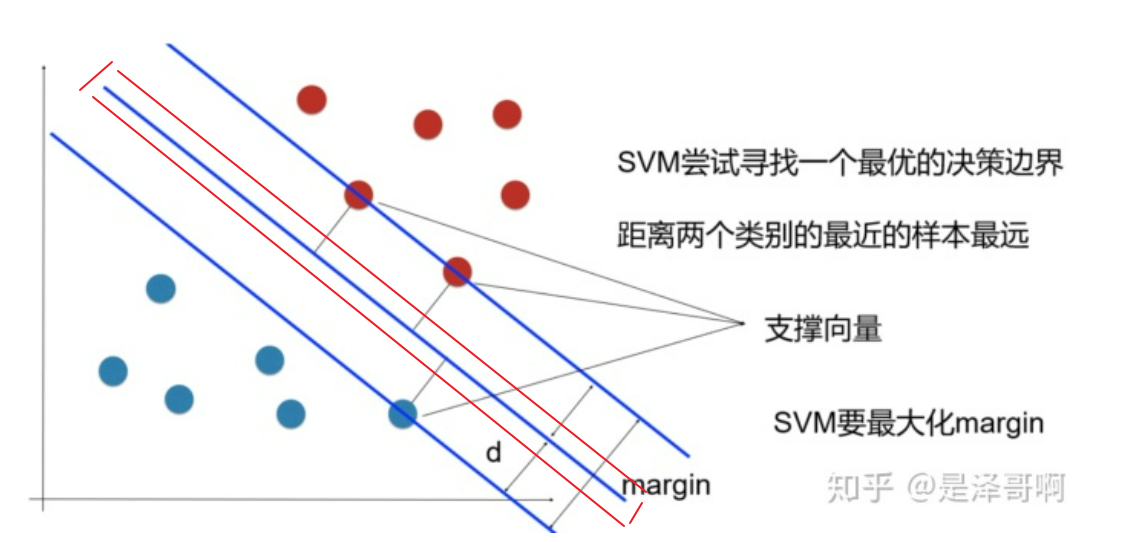
三、SVM算法
找下图红色的线。