
- 1手把手带你玩转Spark机器学习-使用Spark构建回归模型_spark线性回归 可视化
- 22024年(第十届)全国大学生统计建模大赛选题参考(二)_统计建模选题
- 3Python中列表的基本操作
- 4Mac OS X 10.10 Yosemite 关闭Dashboard和Spotlight_spotlightv100能删除吗
- 5产品经理 | 职业选择及面试技巧_产品经理面试职业规划
- 6【JAVA】 Java 性能比较差的代码写法及替换方案_java stream int 假发
- 7复刻yolo系列时出现的BUG及解决方法_runtimeerror: "slow_conv2d_cpu" not implemented fo
- 8XZ-Utils后门事件过程及启示_xzuntil
- 9HarmonyOS实战开发-拼图、如何实现获取图片,以及图片裁剪分割的功能。_鸿蒙 分割图片
- 10三款好用的 Docker 可视化管理工具_docker可视化界面管理工具
发现一个好东西,一键本地运行各种大模型!包括最新的Qwen1.5_qwen1_5-7b-chat-q5_k_m.gguf
赞
踩
只要只支持GGUF的大语言模型,都可以一键安装,一键运行,立马开始对话。简直就是...
下载地址:点击下载
"GGUF"代表GPT-Generated Unified Format,是一种由Georgi Gerganov定义发布的大模型文件格式。Georgi Gerganov是著名开源项目llama.cpp的创始人。
GGUF是一种二进制格式文件的规范,旨在使原始的大模型预训练结果经过转换后能够更快地被载入使用,并且消耗更低的资源。GGUF通过采用紧凑的二进制编码格式、优化的数据结构、内存映射等多种技术来保存大模型预训练结果,从而提高效率。
简而言之,GGUF可以理解为一种高效处理和使用大型语言模型的文件格式定义,它通过格式转换优化模型的加载速度和运行效率。
软件目前已经支持苹果的Mac M系列,微软的Windows系统,Linux系统。
除了可以直接对话之外,还支持API,而且硬件要求极低,真是要啥有啥。
本地玩转大模型绝对不是梦了。
今天,就拿Qwen来演示下!
首先当然是获取软件并安装。
安装简单到爆,只要双击EXE就可以了,不用任何配置。
打开后,可以看到一个搜索框,只要输入大模型的名字,或者huggingface的项目地址。就可以找到模型了。
由于Qwen已经和他们那个啥了。所以无需搜索,在软件上可以直接看到。
点一下 Download,就开始下载模型了。
下载过程中,软件底部会有进度条。
下载完成之后,点击顶部中间的下拉菜单,选择模型即可。
在User处输入问题,回车,就可以进行对话了!
一键安装,一键加载,一键聊天。
相当丝滑!!!
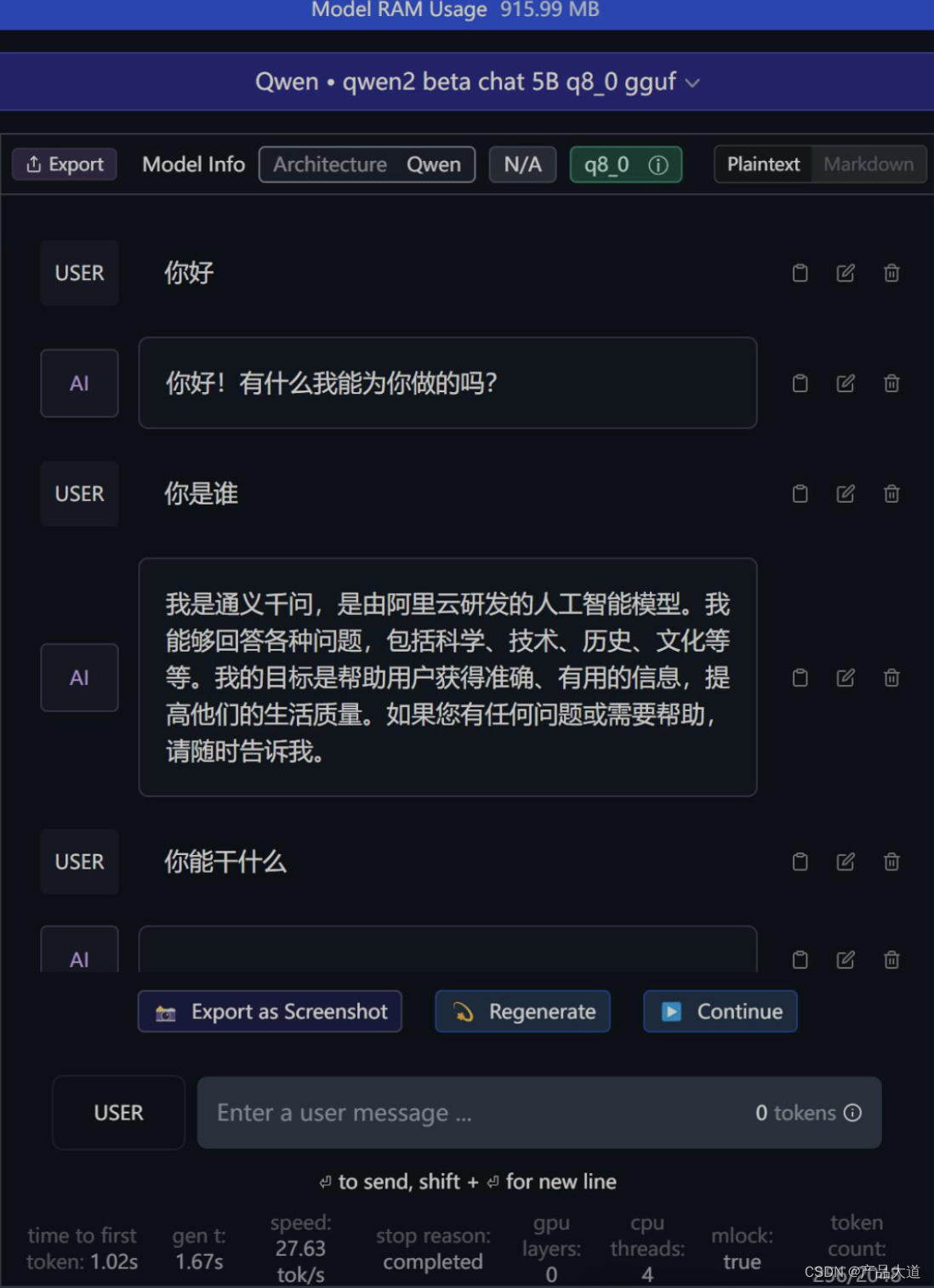
从截图中可以看到,我们已经成功和通义千问离线模型对上话了。
从图上数据可以看到,每秒能到达27tok,基本可以流畅对话了。
我本来想当然认为这是用了GPU。
实际上...看了一眼任务管理器,好像并没有用到。
有的话用得也不多。

这个东西就有点牛逼了。默认加载的是70亿参数的模型哦!!!
如果你觉得这个对话速度还是有点慢,那么我们来体验一下Qwen最小的大模型。
直接在搜索框里输入Qwen1.5。
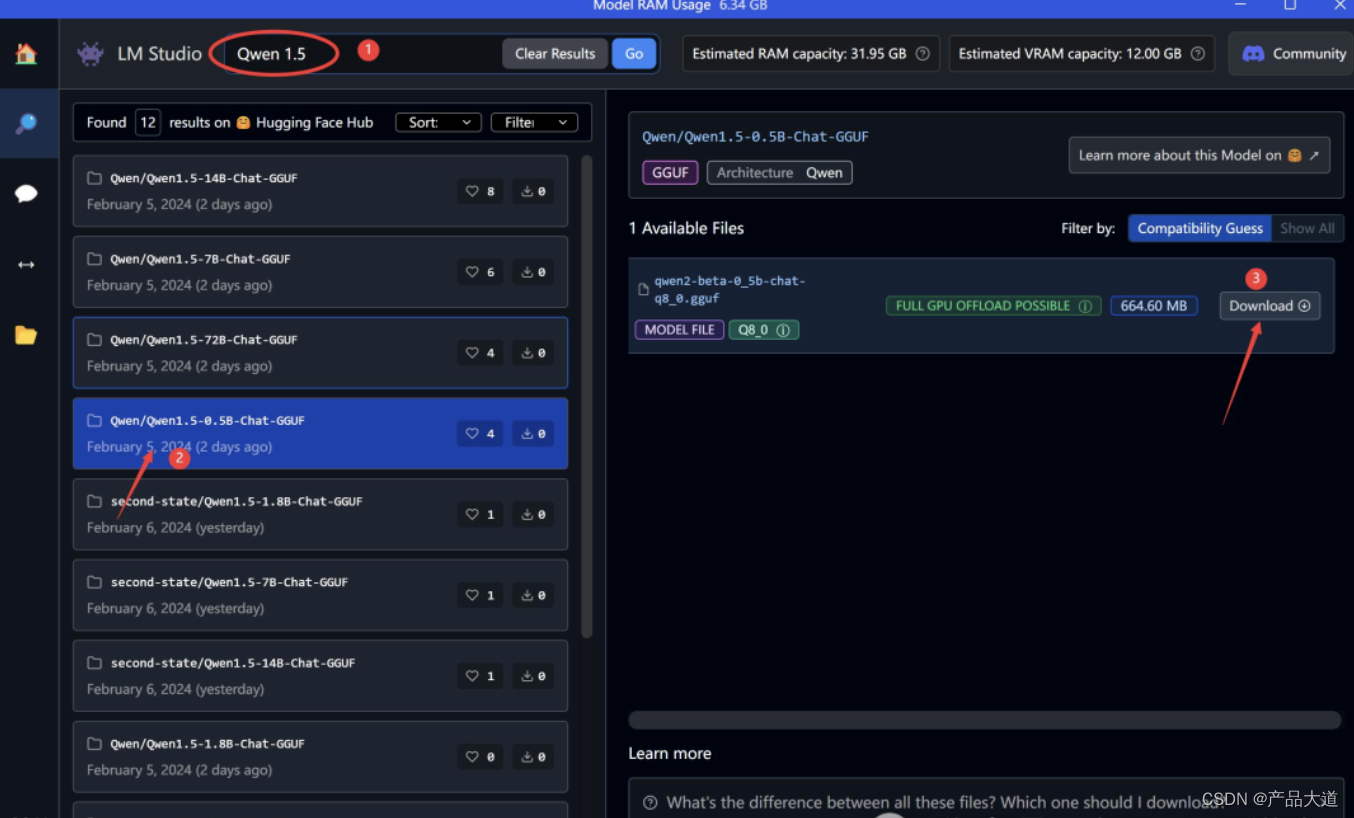
找到0.5B的模型。
从详细信息中可以看到,这个模型只有664MB。
我们以前玩的大模型动不动就是5G起步,对比之下,这个大小实在是太安逸了。
另外,上面说过,这个软件不单单支持Qwen,还支持很多其他大语言模型。
应该是llama.cpp支持的模型都支持。
看着llama.cpp出现,看着基于它的应用出现。
技术发展真的是日新月异,我们都是这个时代的见证人。
由于网络原因,有些人可能无法获取软件或者模型。
我已经把模型放在网盘里了。
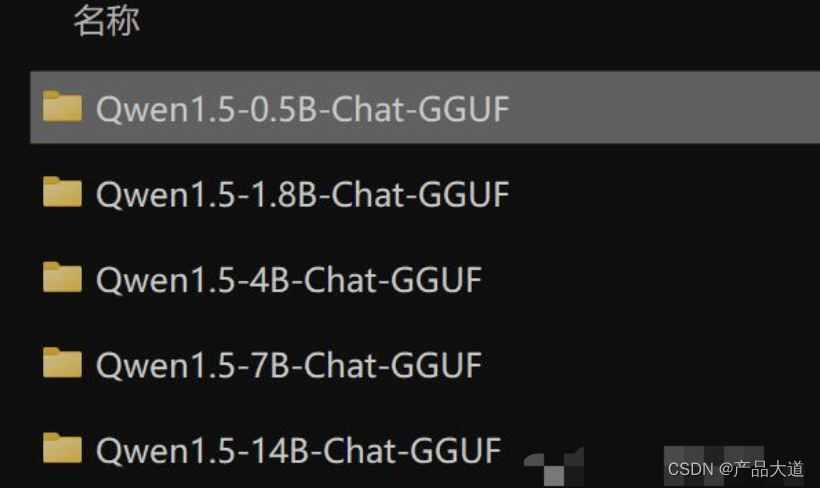
下载Models文件夹,然后通过软件设置模型路径,指向这个文件夹就可以了。
除了72B之外(一般设备也跑不了),另外5类模型全部给你们准备好了。
下载地址:点击获取软件和模型

