
- 1flutter面试_flutter面试题
- 2Flyway介绍和使用_flyway使用
- 3CentOS7.6 安装rabbitmq并实现远程连接_centos的rabbitmq开启远程访问
- 4负载均衡简介
- 5XGBoost原理和公式推导_xgbboost模型公式
- 6【Flink】taskmanager到底设置多少内存为好_taskmanager.memory.process.size
- 7拆分又遇变数,传赛门铁克或将出售VERITAS,这又是挖的什么坑?
- 8Gitlab更改密码后 git 命令推送代码失败
- 9VScode&Git 拉取提交推送代码_vscodegit拉取代码到本地
- 10通过机器学习让医疗数据更好用
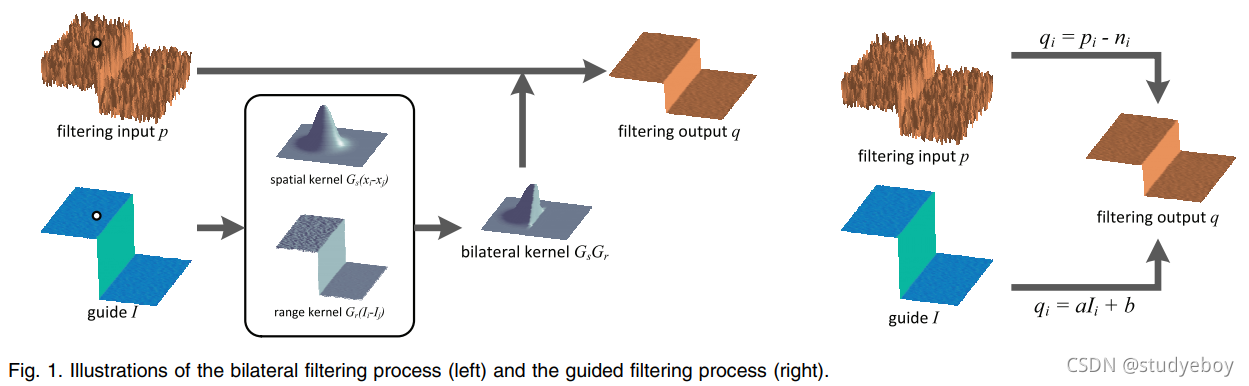
引导图像滤波(Guided Image Filtering)
赞
踩
[Paper] Guided Image Filtering(2013)
引导图像滤波
摘要——在本文中,我们提出了一种新的显式图像滤波器,称为引导滤波器。从局部线性模型导出,引导滤波器通过考虑引导图像的内容来计算过滤输出,引导图像可以是输入图像本身或另一个不同的图像。引导过滤器也是一个比平滑更通用的概念:它可以将引导图像的结构传输到过滤输出,从而实现新的过滤应用,例如去雾和引导羽化。此外,无论内核大小和强度范围如何,引导滤波器自然具有快速且非近似的线性时间算法。目前,它是最快的边缘保留滤波器之一。实验表明,引导滤波器在各种计算机视觉和计算机图形应用中既有效又高效,包括边缘感知平滑、细节增强、HDR 压缩、图像抠图/羽化、去雾、联合上采样等。
概述
计算机视觉和计算机图形学中的大多数应用涉及图像过滤以抑制和/或提取图像中的内容。具有显式内核的简单线性平移不变 (LTI) 滤波器,例如均值、高斯、拉普拉斯和 Sobel 滤波器 [2],已广泛应用于图像恢复、模糊/锐化、边缘检测、特征提取等。或者,LTI 滤波器可以通过求解泊松方程隐式执行,如高动态范围 (HDR) 压缩 [3]、图像拼接 [4]、图像抠图 [5] 和梯度域操作 [6]。滤波内核由齐次拉普拉斯矩阵的逆隐式定义。
LTI 滤波内核在空间上是不变的,并且与图像内容无关。但通常人们可能想要考虑来自给定引导图像的附加信息。各向异性扩散的开创性工作 [7] 使用滤波图像本身的梯度来引导扩散过程,避免平滑边缘。加权最小二乘 (WLS) 滤波器 [8] 利用滤波输入(而不是 [7] 中的中间结果)作为指导,并优化二次函数,这相当于具有非平凡稳态的各向异性扩散。在许多应用中,除了过滤输入之外,引导图像也可以是另一幅图像。例如,在着色 [9] 中,色度通道不应跨亮度边缘渗色;在图像抠图 [10] 中,alpha 抠图应该捕获合成图像中的薄结构;在去雾[11]中,深度层应该与场景一致。在这些情况下,我们分别将色度/alpha/深度层作为要过滤的图像,将亮度/复合/场景作为引导图像。[9]、[10] 和 [11] 中的过滤过程是通过优化由引导图像加权的二次成本函数来实现的。解决方案是通过求解一个仅依赖于指南的大型稀疏矩阵来给出的。这个非齐次矩阵隐含地定义了一个平移变量过滤内核。虽然这些基于优化的方法 [8]、[9]、[10]、[11] 通常会产生最先进的质量,但它伴随着昂贵的计算时间的代价。
利用引导图像的另一种方法是将其显式构建到过滤器内核中。在 [12]、[13] 和 [1] 中独立提出并随后在 [14] 中推广的双边滤波器可能是此类显式滤波器中最受欢迎的一种。它在一个像素上的输出是附近像素的加权平均值,其中权重取决于引导图像中的强度/颜色相似性。引导图像可以是过滤器输入本身 [1] 或另一个图像 [14]。双边滤波器可以平滑小波动并同时保留边缘。尽管此过滤器在许多情况下都有效,但它可能会在边缘附近产生不需要的梯度反转伪影 [15]、[16]、[8](在第 3.4 节中讨论)。双边滤波器的快速实现也是一个具有挑战性的问题。最近的技术 [17]、[18]、[19]、[20]、[21] 依靠量化方法来加速,但可能会牺牲准确性。
在本文中,我们提出了一种新的显式图像过滤器,称为引导过滤器。滤波输出是引导图像的局部线性变换。一方面,引导滤波器与双边滤波器一样具有良好的边缘保留平滑特性,但不会受到梯度反转伪影的影响。另一方面,引导滤波器可以在平滑之外使用:在引导图像的帮助下,它可以使滤波输出比输入更结构化,平滑度更低。我们证明了引导滤波器在各种应用中表现非常好,包括图像平滑/增强、HDR 压缩、闪光/无闪光成像、抠图/羽化、去雾和联合上采样。此外,对于灰度和高维图像,无论内核大小和强度范围如何,引导滤波器自然都具有 O(N)时间(以像素数 N)1 的非近似算法。通常,我们的 CPU 实现每百万像素执行 40 ms 执行灰度过滤:据我们所知,这是最快的边缘保留过滤器之一。
本文的初步版本发表在 ECCV '10 [22] 上。值得一提的是,导向滤波器从那时起见证了一系列新的应用。引导滤波器实现了高质量的实时 O(N) 立体匹配算法 [23]。在[24]中独立提出了一种类似的立体方法。引导滤波器也已应用于光流估计 [23]、交互式图像分割 [23]、显着性检测 [25] 和照明渲染 [26]。我们相信引导滤波器在计算机视觉和图形方面具有巨大的潜力,因为它具有简单、高效和高质量的特点。我们提供了一个公共代码以方便未来的研究 [27]。
相关工作
我们将在本节中回顾边缘保留过滤技术。我们将它们分类为显式/隐式加权平均过滤器和非平均过滤器。
显式加权平均滤波器
双边滤波器 [1] 可能是显式加权平均滤波器中最简单、最直观的滤波器。它将每个像素的滤波输出计算为相邻像素的平均值,由空间和强度距离的高斯加权。双边滤波器在保留边缘的同时平滑图像。它已广泛应用于降噪[28]、HDR压缩[15]、多尺度细节分解[29]和图像抽象[30]。它被推广到 [14] 中的联合双边滤波器,其中权重是从另一个引导图像而不是滤波输入计算的。当要过滤的图像不能可靠地提供边缘信息时,联合双边滤波器特别受欢迎,例如,当它非常嘈杂或者是中间结果时,例如在闪光/非闪光去噪 [14]、图像上采样 [ 31]、图像去卷积[32]、立体匹配[33]等。
尽管双边过滤器很受欢迎,但它也有局限性。在 [15]、[16] 和 [8] 中已经注意到双边滤波器可能会受到“梯度反转”伪影的影响。原因是当一个像素(通常在边缘)周围几乎没有相似的像素时,高斯加权平均值是不稳定的。在这种情况下,结果可能会出现边缘周围不需要的轮廓,通常在细节增强或 HDR 压缩中观察到。
关于双边过滤器的另一个问题是效率。一个蛮力实现是 O ( N r 2 ) O(Nr^2) O(Nr2)耗时,内核半径为 r。 Durand 和 Dorsey [15] 提出了一个分段线性模型并启用基于 FFT 的过滤。Paris 和 Durand [17] 将灰度双边滤波器公式化为空间范围域中的 3D 滤波器,如果 Nyquist 条件近似为真,则对该域进行下采样以加快速度。在框空间内核的情况下,Weiss [34] 提出了一种基于分布直方图的 O ( N l o g r ) O(N log r) O(Nlogr) 时间方法,Porikli [18] 提出了第一个使用积分直方图的 O ( N ) O(N) O(N) 时间方法。我们指出,构建直方图本质上是在空间范围域中执行 2D 空间过滤器,然后是 1D 范围过滤器。在这种观点下,[34] 和 [18] 都沿距离域对信号进行采样,但不对其进行重构。Yang [19] 提出了另一种 O(N)时间方法,该方法沿范围域进行插值以允许更积极的子采样。以上所有方法都是线性复数 w.r.t. 采样强度的数量(例如,线性块或直方图箱的数量)。它们需要粗略采样才能达到令人满意的速度,但如果奈奎斯特条件严重破坏,则会以质量下降为代价。
空间范围域被推广到更高维度的颜色加权双边滤波 [35]。高维 kd 树 [20]、Permutohedral Lattices [21] 或 Adaptive Manifolds [36] 可以减少由于高维而造成的昂贵成本。但是这些方法的性能与灰度双边滤波器相比没有竞争力,因为它们花费了大量额外的时间来准备数据结构。
鉴于双边滤波器的局限性,人们开始研究快速保边滤波器的新设计。O(N)时间边缘避免小波(EAW)[37]是具有显式图像自适应权重的小波。但是小波的核在图像平面上稀疏分布,核大小受限(到2的幂),这可能会限制应用。最近,Gastal 和 Oliveira [38] 提出了另一种 O(N)时间滤波器,称为域变换滤波器。关键思想是迭代和可分离地应用一维边缘感知滤波器。O(N)时间复杂度是通过积分图像或递归滤波来实现的。 我们将在本文中与此过滤器进行比较。
隐式加权平均滤波器
一系列的方法优化一个二次代价函数,求解一个线性系统,相当于用逆矩阵隐式过滤图像。在图像分割 [39] 和着色 [9] 中,该矩阵的亲和度是颜色相似度的高斯函数。在图像抠图中,抠图拉普拉斯矩阵 [10] 旨在将 alpha 抠图强制为图像颜色的局部线性变换。该矩阵也用于去除雾霾 [11]。[8] 中的加权最小二乘滤波器根据图像梯度调整矩阵亲和度,并产生无晕边缘保留平滑。
尽管这些基于优化的方法通常会产生高质量的结果,但求解线性系统非常耗时。由于需要内存的“填充”问题[40]、[41],像高斯消元这样的直接求解器并不实用。Jacobi 方法、连续过度松弛 (SOR) 和共轭梯度 [40] 等迭代求解器收敛速度太慢。尽管精心设计的预处理器 [41] 大大减少了迭代次数,但计算成本仍然很高。多重网格方法 [42] 被证明是齐次 Poisson 方程的 O ( N ) O(N) O(N) 时间复数,但是当矩阵变得更加不齐次时,它的质量会下降。根据经验,通过预处理 [41] 或多重网格 [8],隐式加权平均滤波器至少需要几秒钟来处理 1 百万像素的图像。
已经观察到这些隐式过滤器与显式过滤器密切相关。在[43]中,Elad 表明双边滤波器是求解高斯亲和矩阵的一次 Jacobi 迭代。分层局部自适应预处理器 [41] 和边缘避免小波 [37] 以类似的方式构造。在本文中,我们表明引导滤波器与抠图拉普拉斯矩阵 [10] 密切相关。
非平均滤波器
边缘保留滤波也可以通过非平均滤波器来实现。中值滤波器 [2] 是众所周知的边缘感知算子,是局部直方图滤波器 [44] 的特例。直方图过滤器以双边网格的方式具有 O ( N ) O(N) O(N)时间实现。总变异 (TV) 滤波器 [45] 优化了 L1 正则化成本函数,并且显示为等效于迭代中值滤波 [46]。L1 成本函数也可以通过半二次分裂 [47] 进行优化,在二次模型和软收缩(阈值)之间交替。最近,巴黎等人[48] 提出操纵每个像素周围拉普拉斯金字塔的系数以进行边缘感知滤波。徐等人 [49] 建议优化 L0 正则化成本函数,有利于分段常数解。非平均滤波器通常在计算上很昂贵。
导向过滤器
我们首先定义一个通用的线性平移变量滤波过程,它涉及引导图像
I
I
I、滤波输入图像
p
p
p 和输出图像
q
q
q。
I
I
I 和
p
p
p 都是根据应用预先给出的,它们可以是相同的。像素
i
i
i 处的滤波输出表示为加权平均值:
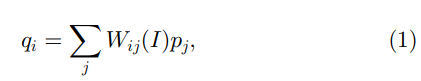
其中
i
i
i和
j
j
j 是像素索引。 滤波器内核
W
i
j
W_{ij}
Wij 是引导图像
I
I
I 的函数,与
p
p
p 无关。 该滤波器相对于
p
p
p 是线性的。
这种滤波器的一个例子是联合双边滤波器 [14](图 1(左))。双边滤波核
W
b
f
W^{bf}
Wbf 由下式给出
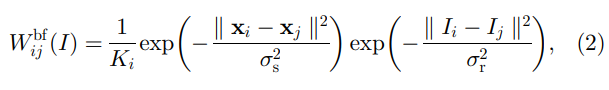
其中
x
x
x 是像素坐标,
K
i
K_i
Ki 是标准化参数,以确保
∑
j
W
i
j
b
f
=
1
\sum_j W^{bf}_{ij}=1
∑jWijbf=1。参数
σ
s
\sigma_s
σs 和
σ
r
\sigma_r
σr 分别调整空间相似性和范围(强度/颜色)相似性的灵敏度。当
I
I
I 和
p
p
p 相同时,联合双边滤波器降级为原始双边滤波器 [1]。
隐式加权平均滤波器(在第 2.2 节中)优化二次函数并以这种形式求解线性系统:

其中
q
q
q 和
p
p
p 分别是连接
q
i
q_i
qi 和 $p_i的
N
×
1
N×1
N×1 向量,
A
A
A 是仅取决于
I
I
I 的
N
×
N
N×N
N×N 矩阵。(3) 的解,即
q
=
A
−
1
p
q=A^{-1}p
q=A−1p,与 (1) 具有相同的形式,其中
W
i
j
=
(
A
−
1
)
i
j
W_{ij}=(A^{-1})_{ij}
Wij=(A−1)ij。
定义
现在我们定义引导过滤器。引导滤波器的关键假设是引导
I
I
I 和滤波输出
q
q
q 之间的局部线性模型。我们假设
q
q
q 是
I
I
I 在以像素
k
k
k 为中心的窗口
w
k
w_k
wk 中的线性变换:
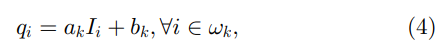
其中
(
a
k
,
b
k
)
(a_k, b_k)
(ak,bk)是假设在 窗口
w
k
w_k
wk 中为常数的一些线性系数。我们使用半径为
r
r
r 的方形窗口。这个局部线性模型确保只有当
I
I
I 有边时
q
q
q 才有边,因为
∇
q
=
a
∇
I
\nabla q = a \nabla I
∇q=a∇I。该模型已被证明可用于图像超分辨率 [50]、图像抠图 [10] 和去雾 [11]。
确定线性系数
(
a
k
,
b
k
)
(a_k, b_k)
(ak,bk),我们需要来自过滤输入
p
p
p 的约束。我们将输出
q
q
q 建模为输入
p
p
p 减去一些不需要的分量
n
n
n,如噪声/纹理:

我们寻求一种在保持线性模型 (4) 的同时最小化
q
q
q 和
p
p
p 之间差异的解决方案。 具体来说,我们在窗口
w
k
w_k
wk 中最小化以下成本函数:
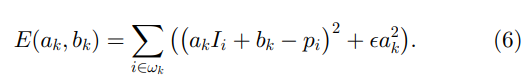
这里
ϵ
\epsilon
ϵ,是惩罚大
a
k
a_k
ak 的正则化参数。我们将在 3.2 节研究它的直观含义。方程(6)是线性岭回归模型[51]、[52],其解由下式给出
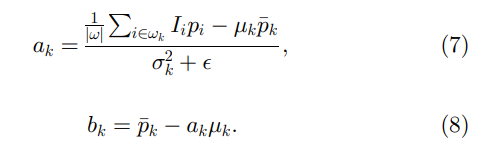
这里,
μ
k
\mu_k
μk 和
σ
k
2
\sigma^2_k
σk2 是
w
k
w_k
wk 中
I
I
I 的均值和方差,
∣
w
∣
\vert w \vert
∣w∣是
w
k
w_k
wk 中像素的数量,
p
ˉ
k
=
1
∣
w
∣
∑
i
∈
w
k
p
i
\bar p_k = \frac{1}{\vert w \vert}\sum_{i \in {w_k}}p_i
pˉk=∣w∣1∑i∈wkpi 是
w
k
w_k
wk 中
p
p
p 的均值 。已获得线性系数
(
a
k
,
b
k
)
(a_k, b_k)
(ak,bk),我们可以通过(4)计算过滤输出
q
i
q_i
qi。图 1(右)显示了引导过滤过程的图示。
然而,覆盖i的所有重叠窗口 w k w_k wk中都涉及一个像素 i i i,因此在不同窗口计算时,式(4)中 q i q_i qi的值并不相同。一个简单的策略是平均所有可能的 q i q_i qi 值。 所以在计算 ( a k , b k ) (a_k,b_k) (ak,bk) 之后; 对于图像中的所有窗口 w k w_k wk,我们计算过滤输出
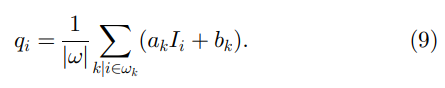
注意到
∑
k
∣
i
∈
w
k
a
k
=
∑
k
∈
w
i
a
k
\sum_{k\vert i \in w_k}a_k = \sum_{k\in w_i}a_k
∑k∣i∈wkak=∑k∈wiak 由于框窗口的对称性,我们将(9)改写为

其中
a
ˉ
i
=
1
∣
w
∣
∑
k
∈
w
i
\bar a_i = \frac{1}{\vert w \vert} \sum_{k \in w_i}
aˉi=∣w∣1∑k∈wi 和
b
ˉ
i
=
1
∣
w
∣
∑
k
∈
w
i
\bar b_i = \frac{1}{\vert w \vert} \sum_{k \in w_i}
bˉi=∣w∣1∑k∈wi 是所有与
i
i
i 重叠的窗口的平均系数。重叠窗口的平均策略在图像去噪中很流行(参见 [53]),并且是非常成功的 BM3D 算法 [54] 的构建块。
随着(10)中的修改, ∇ q \nabla q ∇q 不再是 ∇ I \nabla I ∇I 的缩放,因为线性系数 ( a ˉ i , b ˉ i ) (\bar a_i, \bar b_i) (aˉi,bˉi) 随空间变化。但是作为 ( a ˉ i , b ˉ i ) (\bar a_i, \bar b_i) (aˉi,bˉi) 是均值滤波器的输出,它们的梯度可以预期比靠近强边缘的 I I I 小得多。在这种情况下,我们仍然可以有 ∇ q ≈ a ˉ ∇ I \nabla q \approx \bar a \nabla I ∇q≈aˉ∇I,这意味着 I I I 中的突然强度变化可以大部分保留在 q q q 中。
等式(7)、(8)和(10)是引导滤波器的定义。伪代码在算法 1 中。在该算法中, f m e a n f_{mean} fmean 是一个窗口半径为 r r r 的均值滤波器。相关性(corr)、方差(var)和协方差(cov)的缩写表示这些变量的直观含义。我们将在部分4讨论快速实现和计算细节。

边缘保留过滤
给定引导滤波器的定义,我们首先研究边缘保留滤波特性。图 2 显示了具有各种参数集的引导滤波器的示例。在这里,我们研究引导
I
I
I 与过滤输入
p
p
p 相同的特殊情况。我们可以看到引导滤波器表现为边缘保留平滑算子(图 2)。

引导滤波器的保边滤波特性可以直观地解释如下。 考虑
I
≡
p
I \equiv p
I≡p 的情况。 在这种情况下,在 (7)中
a
k
=
σ
k
2
/
(
σ
k
2
+
ϵ
)
a_k = \sigma_k^2/(\sigma_k^2+\epsilon)
ak=σk2/(σk2+ϵ),
b
k
=
(
1
−
a
k
)
μ
k
b_k = (1 - a_k)\mu_k
bk=(1−ak)μk。如果
ϵ
=
0
\epsilon = 0
ϵ=0,那么
a
k
=
1
a_k = 1
ak=1,
b
k
=
0
b_k = 0
bk=0。如果
ϵ
>
0
\epsilon > 0
ϵ>0,分为两种情况。
情况 1:“高方差”。 如果图像
I
I
I 在
w
k
w_k
wk 内变化很大,我们有
σ
k
2
≫
ϵ
\sigma^2_k \gg \epsilon
σk2≫ϵ,所以
a
k
≈
1
a_k \approx 1
ak≈1 和
b
k
≈
0
b_k \approx 0
bk≈0。
情况 2:“扁平补丁”。 如果图像
I
I
I 在
w
k
w_k
wk中几乎不变,我们有
σ
k
2
≪
ϵ
\sigma _k^2 \ll \epsilon
σk2≪ϵ ,所以
a
k
≈
0
a_k \approx 0
ak≈0 和
b
k
≈
μ
k
b_k \approx \mu_k
bk≈μk 。
当 a k a_k ak 和 b k b_k bk 平均得到 a ˉ i \bar a_i aˉi 和 b ˉ i \bar b_i bˉi 时,结合(10)得到输出,我们有,如果一个像素在一个“高方差”区域的中间,那么它的值不变( a ≈ 1 , b ≈ 0 , q ≈ p a \approx 1, b \approx 0, q \approx p a≈1,b≈0,q≈p),而如果它位于“平坦块”区域的中间,则其值变为附近像素的平均值 ( a ≈ 0 , b ≈ μ , q ≈ μ ˉ a \approx 0, b \approx \mu, q \approx \bar \mu a≈0,b≈μ,q≈μˉ )。
更具体地说,“平坦补丁”或“高方差”的标准由参数 ϵ \epsilon ϵ给出。方差 ( σ 2 \sigma ^2 σ2) 远小于 ϵ \epsilon ϵ 的补丁被平滑,而方差远大于 ϵ \epsilon ϵ 的补丁被保留。引导滤波器中的 ϵ \epsilon ϵ效果类似于双边滤波器 (2) 中的范围方差 σ r 2 \sigma_r ^2 σr2:两者都确定“应该保留的边缘/高方差块是什么”。
此外,在平坦区域中,引导滤波器变为两个半径为 r r r 的盒式均值滤波器的级联。箱式滤波器的级联是高斯滤波器的良好近似。因此,我们凭经验建立了引导滤波器和双边滤波器之间的“对应关系”: r ↔ σ s r \leftrightarrow \sigma _s r↔σs 和 ϵ ↔ σ r 2 \epsilon \leftrightarrow \sigma_r^2 ϵ↔σr2 。图 2 显示了使用相应参数的两种滤波器的结果。图2中的表“PSNR”显示了相应参数的引导滤波结果与双边滤波结果之间的定量差异。当 P S N R ≥ 40 d B PSNR \geq 40 dB PSNR≥40dB [18] 时,它通常被认为是视觉上不敏感的。
过滤内核
很容易证明,由(7)、(8)和(10)给出的
I
、
p
I、p
I、p 和
q
q
q 之间的关系是(1)式的加权平均形式。实际上,式(7)中的
a
k
a_k
ak 可以改写为
p
:
a
k
=
∑
j
A
k
j
(
I
)
p
j
p:a_k = \sum_jA_{kj}(I)p_j
p:ak=∑jAkj(I)pj 的加权和,其中
A
i
j
A_{ij}
Aij 是仅
P
P
P 依赖于
I
I
I 的权重。出于同样的原因,我们还有来自 (8) 的
b
k
=
∑
j
B
k
j
(
I
)
p
j
b_k = \sum_jB_{kj}(I)p_j
bk=∑jBkj(I)pj 和来自 (10) 的
q
i
=
∑
j
W
i
j
(
I
)
p
j
q_i = \sum_jW_{ij}(I)p_j
qi=∑jWij(I)pj。我们可以证明核权重明确表示为
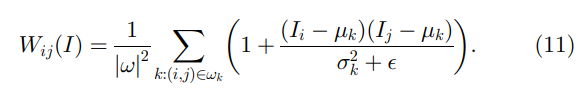
证明。 由于
p
p
p 和
q
q
q 之间的线性相关性,滤波器内核由
W
i
j
=
∂
q
i
/
∂
p
j
W_{ij}= \partial q_i / \partial p_j
Wij=∂qi/∂pj给出。将(8)式代入(10)式并消去
b
b
b,我们得到
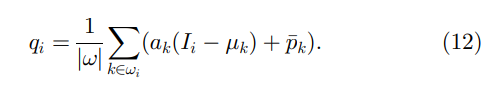
导数给出
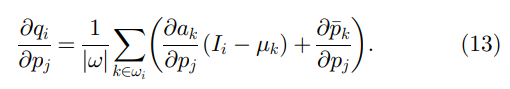
在这个等式中,我们有
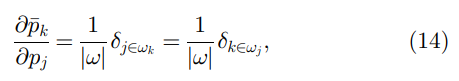
其中,当
j
j
j在窗口
w
k
w_k
wk 中时
δ
j
∈
w
k
\delta_{j \in w_k}
δj∈wk 为 1,否则为 0。另一方面,(13)中的偏导数
∂
a
k
/
∂
p
j
\partial a_k / \partial p_j
∂ak/∂pj可以从(7)计算:
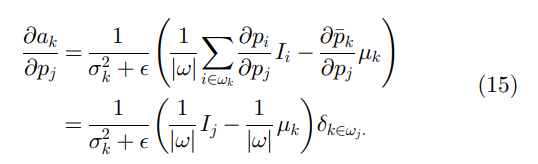
将(14)和(15)代入(13),我们得到
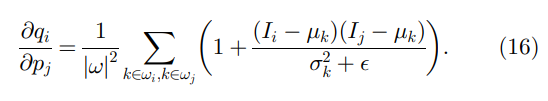
这就是滤波器内核
W
i
j
W_{ij}
Wij 的表达式。一些进一步的代数运算表明
∑
j
W
i
j
(
I
)
≡
1
\sum_jW_{ij}(I) \equiv 1
∑jWij(I)≡1。不需要额外的努力来标准化权重。
边缘保留平滑特性也可以通过研究滤波器内核(11)来理解。以一维信号的理想阶跃边缘为例(图 3)。当
I
i
I_i
Ii 和
I
j
I_j
Ij 位于边的同一侧时,项
I
i
−
μ
k
I_i - \mu_k
Ii−μk和
I
j
−
μ
k
I_j - \mu_k
Ij−μk 具有相同的符号 (+/-),而当两个像素位于不同侧时,它们具有相反的符号。所以在(11)中,
1
+
(
I
i
−
μ
k
)
(
I
j
−
μ
k
)
σ
k
2
+
ϵ
1+\frac{(I_i - \mu_k)(I_j - \mu_k)}{\sigma^2_k + \epsilon}
1+σk2+ϵ(Ii−μk)(Ij−μk) 对于不同边的两个像素比相同边小得多(并且接近于零)。这意味着跨边缘的像素几乎没有被平均在一起。我们也可以从(11)中理解
ϵ
\epsilon
ϵ平滑效果。当
σ
k
2
≪
ϵ
\sigma^2_k \ll \epsilon
σk2≪ϵ(“平坦补丁”)时,内核变为
W
i
j
(
I
)
≈
1
∣
w
∣
2
∑
k
:
(
i
,
j
)
∈
w
k
W_{ij}(I) \approx \frac{1}{{\vert w \vert} ^2}\sum_{k:(i,j)\in w_k}
Wij(I)≈∣w∣21∑k:(i,j)∈wk 1:这是一个 LTI 低通滤波器(它是两个均值滤波器的级联)。
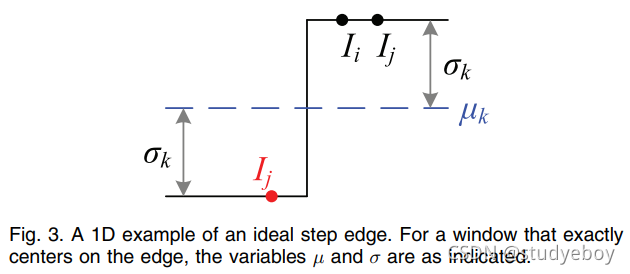
图 4 说明了真实图像中核形状的一些示例。顶行是靠近阶梯边缘的内核。与双边内核一样,引导滤波器内核为边缘另一侧的像素分配几乎为零的权重。中间一行是带有小比例纹理的补丁中的内核。两个滤波器将几乎所有附近的像素平均在一起,并显示为低通滤波器。这在恒定区域(图 4(底行))中更为明显,其中引导滤波器退化为两个平均滤波器的级联。
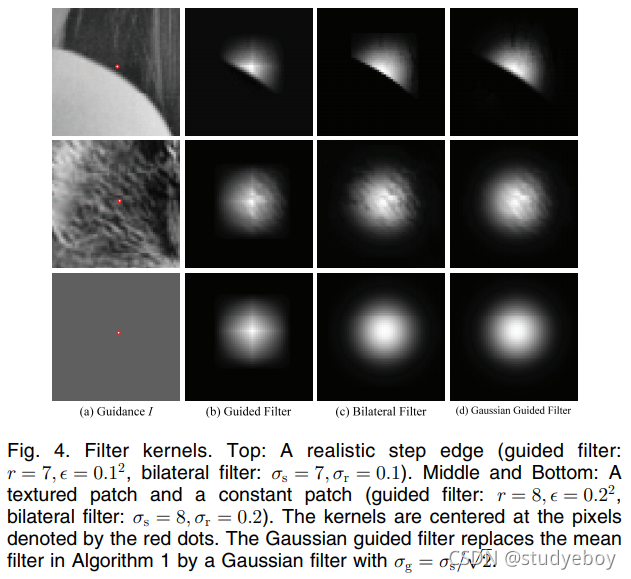
可以在图 4b 中观察到,导向滤波器是旋转不对称的,并且稍微偏向 x/y 轴。这是因为我们在滤波器设计中使用了框窗口。这个问题可以通过使用高斯加权窗口来解决。形式上,我们可以在(6)中引入权重
w
i
k
=
e
x
p
(
−
∥
x
i
−
x
k
∥
2
/
σ
g
2
)
w_{ik} = exp(-\Vert x_i - x_k \Vert ^2 / \sigma^2_g)
wik=exp(−∥xi−xk∥2/σg2):
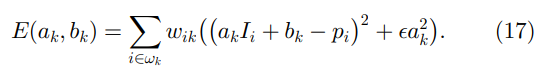
很明显,可以通过用高斯滤波器
f
G
a
u
s
s
f_{Gauss}
fGauss 替换算法 1 中的所有平均滤波器
f
m
e
a
n
f_{mean}
fmean 来计算结果高斯引导滤波器。由此产生的内核是旋转对称的,如图 4d 所示。在第 4 节中,我们将展示高斯引导滤波器与原始引导滤波器一样仍然是
O
(
N
)
O(N)
O(N) 时间。但是因为在实践中我们发现原始引导滤波器总是足够好,所以我们在所有剩余的实验中使用它。
梯度保持过滤
尽管引导滤波器是与双边滤波器一样的边缘保留平滑算子,但它避免了在细节增强和 HDR 压缩中可能出现的梯度反转伪影。对细节增强算法的简要介绍如下(另见图5)。给定输入信号
p
p
p(图 5 中的黑色),其边缘保留平滑输出用作基础层
q
q
q(红色)。输入信号和基础层之间的差异是细节层(蓝色):
d
=
p
−
q
d=p-q
d=p−q 。 它被放大以提升细节。增强信号(绿色)是增强细节层和基础层的组合。在 [15] 中可以找到对这种方法的详细描述。
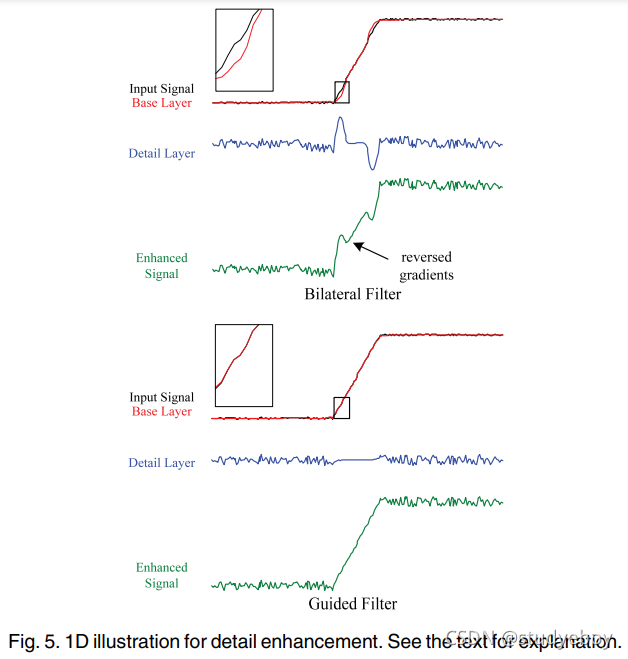
对于双边滤波器(图 5(上)),基础层与边缘像素处的输入信号不一致(参见放大图)。图 6 说明了边缘像素的双边核。因为这个像素没有相似的邻居,高斯加权范围内核不可靠地平均一组像素。更糟糕的是,由于边缘的突然变化,范围内核有偏差。对于图 6 中的示例边缘像素,其滤波值小于其原始值,使得滤波信号
q
q
q 比输入
p
p
p 更锐利。在[15]、[16]、[8]中已经观察到了这种锐化效果。现在假设输入
p
p
p 的梯度为正:
∂
x
p
>
0
\partial _xp > 0
∂xp>0(如图 5 和图 6 所示)。当
q
q
q 锐化时,它给出:
∂
x
q
>
∂
x
p
\partial _x q > \partial_x p
∂xq>∂xp。因此,细节层
d
d
d 具有负梯度
∂
x
d
=
∂
x
p
−
∂
x
q
<
0
\partial_x d = \partial_x p - \partial_x q < 0
∂xd=∂xp−∂xq<0,这意味着它具有相反的梯度方向 w.r.t. 输入信号(见图 5(上))。当细节层被放大并与输入信号重新组合时,边缘出现梯度反转伪影。这种伪影是固有的,不能通过调整参数安全地避免,因为自然图像通常在各种尺度和幅度上都有边缘。
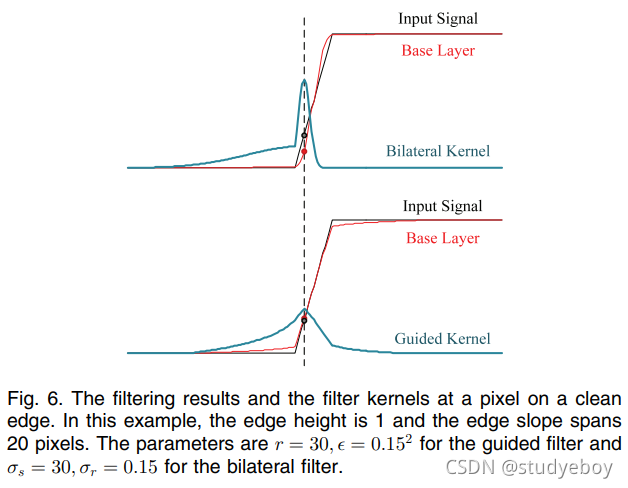
另一方面,引导滤波器在避免梯度反转方面表现更好。实际上,如果我们使用patch-wise模型(4),在自引导过滤( I ≡ p I \equiv p I≡p)的情况下保证不会出现梯度反转。在这种情况下,(7) 给出 a k = σ k 2 / ( σ k 2 + ϵ ) a_k = \sigma^2_k/(\sigma^2_k + \epsilon) ak=σk2/(σk2+ϵ) 并且 b k b_k bk 是一个常数。所以我们有 ∂ x q = a k ∂ x p \partial_xq=a_k \partial_xp ∂xq=ak∂xp和细节层梯度 ∂ x d = ∂ x p − ∂ x q = ( 1 − a k ) ∂ x p \partial_xd = \partial_xp - \partial_xq=(1-a_k)\partial_xp ∂xd=∂xp−∂xq=(1−ak)∂xp,这意味着 ∂ x d \partial_xd ∂xd 和 ∂ x p \partial_xp ∂xp总是在同一个方向。当我们使用重叠模型(9)而不是(4)时,我们有 ∂ x q = a ˉ ∂ x p + p ∂ x a ˉ + ∂ x b ˉ \partial_xq = \bar a \partial_xp + p \partial_x \bar a + \partial_x \bar b ∂xq=aˉ∂xp+p∂xaˉ+∂xbˉ。因为 a ˉ \bar a aˉ和 b ˉ \bar b bˉ是低通滤波图,我们得到 ∂ x q ≈ a ˉ ∂ x p \partial_xq \approx \bar a \partial_xp ∂xq≈aˉ∂xp,上面的结论仍然近似正确。在实践中,我们没有在所有实验中观察到梯度反转伪影。图 5(底部)给出了一个例子。在图 6 中,我们展示了边缘像素的引导滤波器内核。与双边内核不同,引导滤波器为内核较弱的一侧分配一些小而重要的权重。这使得引导内核的偏差较小,避免减少图 5 中示例边缘像素的值。
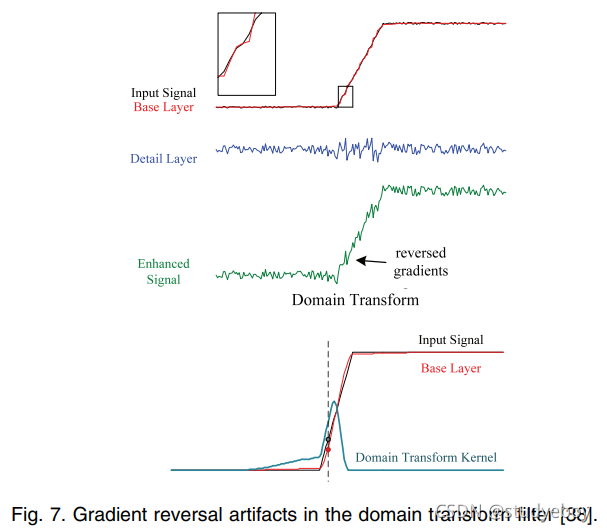
我们注意到梯度反转问题也出现在最近的边缘保留域变换滤波器 [38](图 7)中。这个非常有效的过滤器是从 (1D) 双边核派生出来的,所以它不能安全地避免梯度反转。
颜色过滤的扩展
引导过滤器可以很容易地扩展到彩色图像。在滤波输入
p
p
p 是多通道的情况下,可以直接将滤波器独立地应用于每个通道。在引导图像
I
I
I 为多通道的情况下,我们将局部线性模型(4)重写为
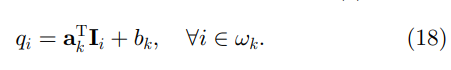
这里
I
i
I_i
Ii 是一个
3
×
1
3 \times1
3×1 颜色向量,
a
k
a_k
ak 是一个
3
×
1
3 \times1
3×1 系数向量,
q
i
q_i
qi 和
b
k
b_k
bk 是标量。 彩色引导图像的引导过滤器变为
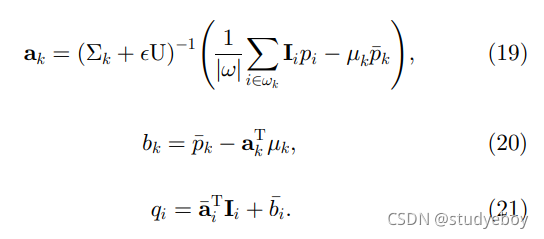
这里,
∑
k
\sum_k
∑k 是
w
k
w_k
wk 中
I
I
I 的
3
×
3
3 \times 3
3×3 协方差矩阵,
U
U
U 是
3
×
3
3 \times 3
3×3 单位矩阵。
彩色引导图像可以更好地保留灰度无法区分的边缘(见图 8)。这也是双边滤波的情况[20]。颜色引导图像在抠图/羽化和去雾应用中也是必不可少的,正如我们稍后展示的那样,因为局部线性模型在 RGB 颜色空间中比在灰度中更有效 [10]。

结构传递过滤
有趣的是,引导滤波器不仅仅是一个平滑滤波器。由于
q
=
a
I
+
b
q = aI + b
q=aI+b的局部线性模型,输出
q
q
q 是引导
I
I
I 的局部缩放(加上偏移量)。这使得可以将结构从引导
I
I
I 转移到输出
q
q
q,即使滤波输入
p
p
p 是平滑的(见图 9)。
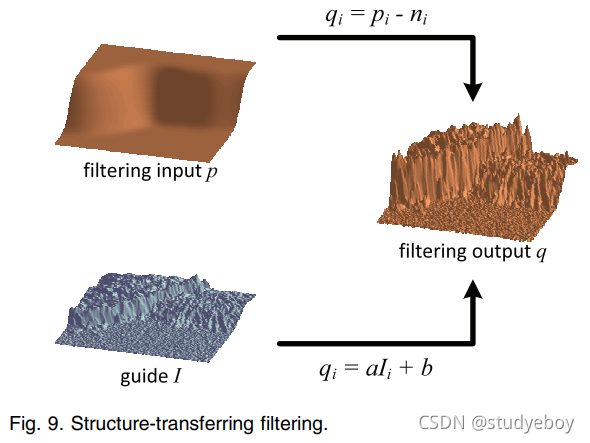
为了展示结构转换过滤的示例,我们引入了引导羽化的应用:改进了二进制蒙版以在对象边界附近出现 alpha 遮罩(图 10)。二值掩码可以从图形切割或其他分割方法中获得,并用作过滤器输入
p
p
p。指导
I
I
I 是彩色图像。 图 10 显示了三个滤波器的行为:引导滤波器、(联合)双边滤波器和最近的域变换滤波器 [38]。我们观察到引导过滤器忠实地恢复了头发,即使过滤输入
p
p
p 是二进制的并且非常粗糙。双边滤波器可能会丢失一些薄结构(参见放大)。这是因为双边滤波器由像素级色差引导,而引导滤波器具有补丁级模型。我们还观察到域变换滤波器没有良好的结构转移能力,只是简单地平滑了结果。这是因为该滤波器基于像素的测地距离,其输出是一系列具有自适应跨度的 1D 盒式滤波器 [38]。

结构传递滤波是引导滤波器的一个重要特性。它支持新的基于过滤的应用程序,包括羽化/消光和去雾(第 5 节)。它还可以在 [23] 和 [24] 中实现基于高质量过滤的立体匹配方法。
与隐式方法的关系
引导滤波器与抠图拉普拉斯矩阵 [10] 密切相关。这为理解此过滤器提供了新的见解。
在 matting [10] 的封闭形式解决方案中,matting Laplacian 矩阵来自局部线性模型。与为每个窗口计算局部最优值的引导滤波器不同,封闭形式的解决方案寻求全局最优值。为了求解未知的 alpha 遮罩,此方法最小化了以下成本函数:
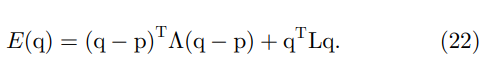
这里,
q
q
q 是表示未知 alpha 遮罩的
N
×
1
N×1
N×1 向量,
p
p
p 是约束(例如,trimap),
L
L
L 是
N
×
N
N\times N
N×N 抠图拉普拉斯矩阵,并且
Λ
\Lambda
Λ是使用约束权重编码的对角矩阵。这个优化问题的解是通过求解一个线性系统给出的

抠图拉普拉斯矩阵的元素由下式给出
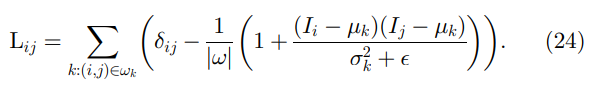
δ
i
j
\delta_{ij}
δij是Kronecker delta。比较(24)和(11),我们发现消光拉普拉斯矩阵的元素可以直接由引导滤波器核给出:
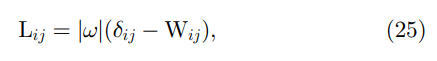
遵循 [43] 中的策略,我们证明了引导滤波器的输出是优化 (22) 中的一次 Jacobi 迭代:
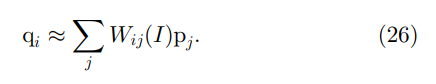
证明。 (25) 的矩阵形式为
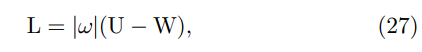
其中 U 是与 L 大小相同的单位矩阵。为了在线性系统 (23) 上应用 Jacobi 方法 [40],我们需要矩阵的对角线/非对角线部分。我们将
W
W
W 分解为对角线部分
W
d
W_d
Wd 和非对角线部分
W
o
W_o
Wo,因此
W
=
W
d
+
W
o
W = W_d + W_o
W=Wd+Wo。 从(27)和(23)我们有
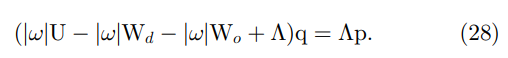
请注意,这里只有
W
o
W_o
Wo 是非对角线的。使用
p
p
p 作为初始猜测,我们计算 Jacobi 方法的一次迭代:
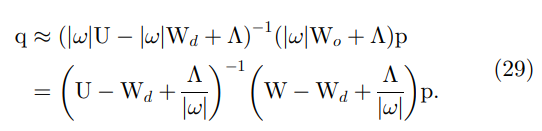
在(29)中,唯一的卷积是矩阵乘法
W
p
W_p
Wp。其他矩阵都是对角线和逐点运算。为了进一步简化(29),我们让矩阵
Λ
\Lambda
Λ满足:
Λ
=
∣
w
∣
W
d
\Lambda = \vert w \vert W_d
Λ=∣w∣Wd或者,等价地,
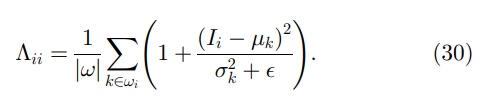
(30)中
Λ
i
i
\Lambda_{ii}
Λii的期望值为2,这意味着(22)中的约束是软的。等式 (29) 然后简化为

这是引导过滤器。
在 [55] 中,我们通过共轭梯度求解器 [40] 展示了引导滤波器和消光拉普拉斯矩阵之间的另一种关系。在第 5 节中,我们将此属性应用于图像消光/羽化和去雾,这提供了一些相当不错的初始猜测 p p p。这是过滤器结构传递特性的另一个角度。
计算和效率
引导滤波器相对于双边滤波器的主要优点是它自然具有 O ( N ) O(N) O(N) 时间非近似算法,与窗口半径 r r r 和强度范围无关。
(1) 中的过滤过程是平移变量卷积。当内核变大时,它的计算复杂度会增加。我们不是直接执行卷积,而是根据算法 1 的定义(7)、(8)和(10)计算滤波器输出。主要的计算负担是具有半径为
r
r
r 的框窗口的均值滤波器
f
m
e
a
n
f_{mean}
fmean。幸运的是,可以使用积分图像技术 [57] 或简单的移动求和方法(参见算法 2)在
O
(
N
)
O(N)
O(N) 时间内有效地计算(非标准化)盒式滤波器。考虑到盒式滤波器的可分离性,任一方法沿每个
x
/
y
x/y
x/y 方向对每个像素进行两次操作(加/减)。因此,平均滤波器
f
m
e
a
n
f_{mean}
fmean每像素进行五次加法/减法运算和一次@除法(归一化)。

使用
O
(
N
)
O(N)
O(N) 时间均值滤波器,算法 1 中的引导滤波器自然是
O
(
N
)
O(N)
O(N) 时间。同样,(19)、(20)和(21)中的颜色指导版本可以用类似的
O
(
N
)
O(N)
O(N) 方式计算。公共 Matlab 代码在 [22] 中可用,包括灰度和彩色版本。
在表 1 中,我们总结了不同场景所需的均值滤波器的数量。这里,
d
I
d_I
dI 和
d
p
d_p
dp 分别是
I
I
I 和
p
p
p 中的通道数。我们还列出了
I
≡
p
I \equiv p
I≡p 的特殊情况,因为
I
I
I 和
p
p
p 的重复节省了一些均值过滤器。
I
≡
p
I \equiv p
I≡p 的情况在实践中最受关注。

我们在配备 Intel core i7 3.0 GHz CPU 和 8 GB RAM 的 PC 中测试运行时间。实现是在 C++ 中。 除非另有说明,否则所有算法都是基于单核的,没有 SIMD 指令(例如 SSE)。在我们的实验中,平均滤波器大约需要 5-7 ms/Mp。 运行时间如表 1 所示。
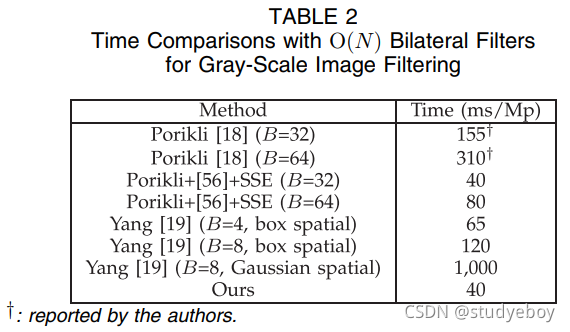
我们想强调的是,灰度图像边缘保留平滑 ( I ≡ p , d p = 1 ) (I \equiv p, d_p = 1) (I≡p,dp=1) 仅需要 40 ms/Mp。作为比较(见表 2),[18] 中的 O ( N ) O(N) O(N) 时间双边滤波器使用 32-bin 直方图报告为 155 ms/Mp,使用 64-bin 报告为 310 ms/Mp,如 [ 18]。[18] 中描述的方法使用积分直方图,每个像素需要 6B 次加/减运算来构建直方图。相反,我们可以采用 [56] 中的移动直方图,这需要每个像素 2 B + 2 2B + 2 2B+2 次操作。使用 SSE,我们对 [18]+[56] 的实现实现了 40 ms/Mp ( B = 32 B=32 B=32) 和 80 ms/Mp ( B = 64 B= 64 B=64)。由于[56]中的移动直方图仅用于中值滤波,据我们所知,[18]+[56]的组合是文献中未发表的双边滤波的最新技术。当 B = 8 时,Yang 的 O ( N ) O(N) O(N) 算法 [19] 大约需要 120 ms/Mp(使用作者的公共代码,带有框空间内核)。
请注意,
O
(
N
)
O(N)
O(N) 时间引导滤波器是非近似的,适用于任何范围的强度。相反,由于范围二次采样,
O
(
N
)
O(N)
O(N) 时间双边滤波器可能具有明显的量化伪影。图 11 显示了一个示例,其中要过滤的信号处于高动态范围内。Porikli 的方法 [18] 即使在 B = 32 时也有明显的量化伪影。 由于范围插值(但需要更多时间,见表 2),Yang 的方法 [19] 中类似的伪影在 B =8 时不太明显,但在 B = 4 因为奈奎斯特采样条件变得严重破坏。

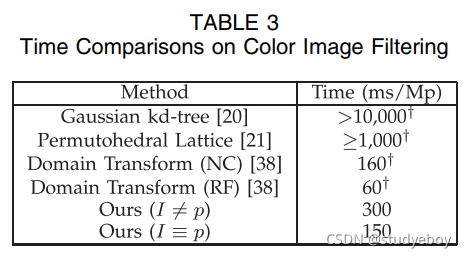
对于彩色图像滤波(见表 3),引导滤波器在
I
≠
q
I \neq q
I=q 时需要 300 ms/Mp,当
I
≡
q
I \equiv q
I≡q 时需要 150 ms/Mp。这比高维双边滤波器算法快得多,例如高斯 kd-tree [20] (> 10 s/Mp) 和最先进的 Permutohedral Lattice [21] (> 1 s/Mp) 。在 [22] 中发布引导滤波器之后,最近的 [38] 提出了
O
(
N
)
O(N)
O(N) 时域变换滤波器。如 [38] 中的报告,其归一化卷积 (NC) 版本需要 160 ms/Mp,其递归滤波器 (RF) 版本需要 60 ms/Mp 进行彩色图像过滤。虽然域变换非常快,但它并不能避免梯度反转(图 7),也不适合转移结构(图 10)。
使用
O
(
N
)
O(N)
O(N) 时间递归高斯滤波器 [58],第 3.3 节中讨论的高斯引导滤波器也是
O
(
N
)
O(N)
O(N) 时间。递归高斯滤波器比盒式滤波器更昂贵(每个
x
/
y
x/y
x/y 方向每个像素 15 个操作与 2 个操作)。
实验
接下来,我们在各种计算机视觉和图形应用程序中试验引导滤波器。
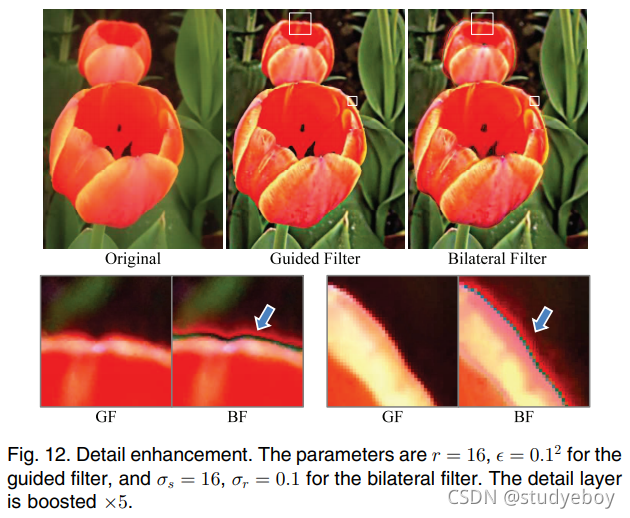
细节增强和 HDR 压缩。 细节增强的方法在 3.4 节中描述。HDR 压缩以类似的方式完成,但压缩基础层而不是放大细节层(参见 [15])。图 12 显示了细节增强的示例,图 13 显示了 HDR 压缩的示例。还提供了使用双边滤波器的结果。如放大补丁所示,双边滤波器导致梯度反转伪影。请注意,梯度反转伪影通常会在边缘周围引入新的轮廓。

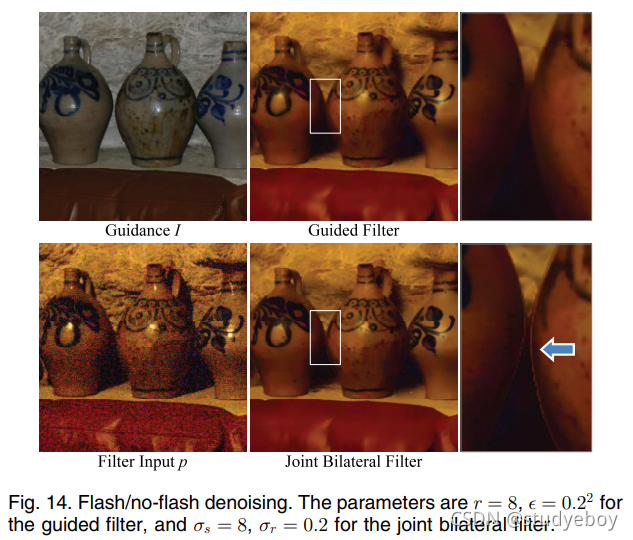
闪光/无闪光去噪。 在[14]中,建议在其闪存版本的指导下对非闪存图像进行去噪。图 14 显示了使用联合双边滤波器和引导滤波器的比较。在联合双边滤波器结果中的某些边缘附近,梯度反转伪影很明显。
引导羽化/消光。 我们在第 3.6 节中介绍了引导羽化应用程序。 商业软件 Adobe Photoshop CS4 提供了一个类似的工具,称为“Refine Edge”。精确的遮罩也可以通过封闭形式的遮罩 [10] 来计算。 图 15 显示了比较。我们的结果在视觉上与这个短发案例中的封闭式解决方案相当。我们的方法和 Photoshop 都为这个 6 兆像素的图像提供了快速反馈(< 1 秒),而封闭形式的解决方案需要大约两分钟才能解决一个巨大的线性系统。

在一般的抠图情况下,模糊区域很大; 我们可以采用颜色采样策略 [59] 在过滤之前估计更可靠的初始猜测。结合全局采样方法 [59],引导滤波器是 alphamatting 基准(www.alphamatting.com,2012 年 6 月的性能报告)中性能最好的基于过滤的抠图方法。
单幅图像去雾。 在[11]中,雾度透射图是使用暗通道先验粗略估计的,并通过求解消光拉普拉斯矩阵进行细化。相反,我们只是在朦胧图像的引导下对原始透射图进行过滤(我们首先应用一个最大过滤器来抵消最小过滤器的形态效应(参见 [11]),并将其视为 导向过滤器)。结果在视觉上相似(图 16)。 图 16 中的放大窗口也展示了滤波器的结构传递特性。对于这幅
600
×
400
600\times 400
600×400 幅图像,引导滤波器的运行时间约为 40 毫秒,而在 [11] 中使用 matting Laplacian 矩阵则为 10 秒。

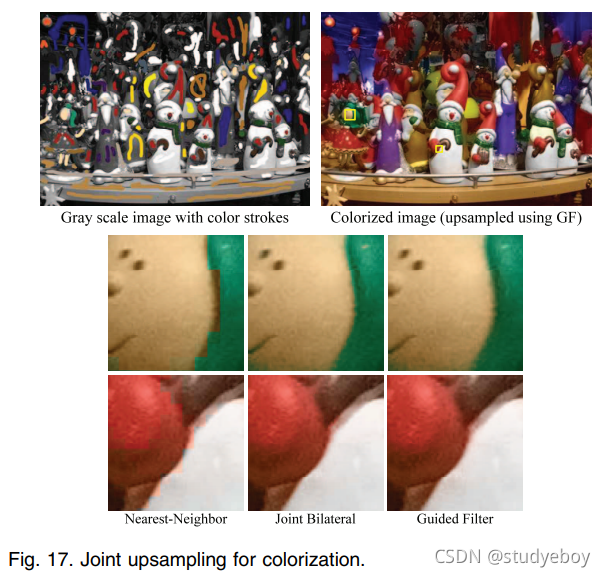
联合上采样 联合上采样 [31] 是在另一幅图像的指导下对一幅图像进行上采样。以着色的应用[9]为例。灰度亮度图像通过优化过程着色。为了减少运行时间,色度通道以粗分辨率求解,并在全分辨率亮度图像的指导下由联合双边滤波器 [31] 进行上采样。
该上采样过程可以由引导滤波器执行。该算法与算法 1 略有不同,因为现在我们有两个尺度的引导图像(例如,亮度)和仅粗尺度的滤波输入(例如,色度)。在这种情况下,我们在粗尺度上使用(7)和(8)计算线性系数
a
a
a 和
b
b
b,将它们双线性上采样到精细尺度(替换
a
a
a 和
b
b
b 上的均值滤波器),并通过
q
=
a
I
+
b
q = aI + b
q=aI+b 在精细尺度上计算输出。结果在视觉上与联合双边上采样相当(图 17)。在我们的实现中,联合双边上采样每兆像素输出需要 180 ms(在 [31] 中报告为 2s/Mp),而引导滤波器上采样需要大约 20 ms/Mp。
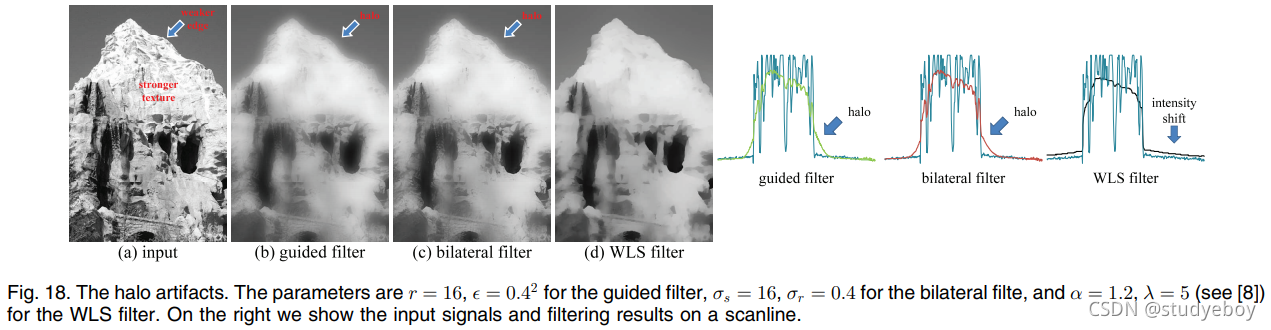
限制 引导过滤器与其他显式过滤器有一个共同的限制——它可能会在某些边缘附近出现光晕。 “光晕”是指边缘不需要平滑处理的伪影。(相反,“梯度反转”是指边缘不需要锐化的伪影。在文献中,一些研究没有区分这两种伪影,简单地将它们称为“光晕”。我们在本文中分别讨论它们 因为这些工件的原因是不同的。)当过滤器被迫平滑某些边缘时,局部过滤器不可避免地会出现光晕。例如,如果要平滑强纹理(见图 18),则弱边缘也将被平滑。 像引导/双边滤波器这样的局部滤波器会将模糊集中在这些边缘附近并引入光晕(图 18)。基于全局优化的过滤器(例如 WLS 过滤器 [8])将更全局地分布这种模糊。光晕以全局强度转移为代价被抑制(见图 18(右))。
结论
在本文中,我们提出了一种广泛适用于计算机视觉和图形的新型过滤器。与最近加速双边滤波器的趋势不同 [17]、[18]、[19]、[20]、[21],我们设计了一种新的滤波器,它展示了边缘保留平滑的良好特性,但可以计算 有效地和非近似地。我们的过滤器比“平滑”更通用,适用于结构转移,实现基于过滤的羽化/消光和去雾的新应用。由于局部线性模型 (4) 是一种无监督学习,因此可能会应用其他高级模型/特征来获得新的过滤器。 我们将其留作将来的研究。


