
- 1高效数据存储格式Parquet_to_parquet
- 2IDEA连接SqlServer数据库_idea导入sqljdbc后如何与sqlserver连接
- 3【大模型实践】ChatGLM3微调输入-输出模型(六)_chatglm3 prompt
- 4【Git-Git克隆代码与提交代码】使用Git命令方式拉取代码至本地以及上传代码到云端
- 5文件上传漏洞靶场搭建(upload-labs)_upload-labs搭建
- 6Debian/Linux 配置网络教程(包括配置IP)_debian 配置网络
- 7移动通信网络频段大全_n66频段
- 8前端安全——最新:lodash原型漏洞从发现到修复全过程_lodash 漏洞复现
- 9React native拆包之 原生加载多bundle(iOS&Android)_react native加载bundle
- 10华为鸿蒙4谷歌GMS安装教学_华为鸿蒙os安装谷歌gms套件的最便捷方法教程
【论文阅读】Image Super-Resolution with Non-Local Sparse Attention
赞
踩
Image Super-Resolution with Non-Local Sparse Attention
论文地址
【CVPR2021】Image super-resolution with non-local sparse attention
摘要
非局部(NL)操作和稀疏表示对于单图像超分辨率(SISR)都至关重要。在本文中,我们研究了它们的组合,并提出了一种具有动态稀疏注意力模式的新型非局部稀疏注意力(NLSA)。 NLSA 旨在保留 NL 操作的远程建模能力,同时享受稀疏表示的鲁棒性和高效性。具体来说,NLSA 通过将输入空间划分为相关特征的哈希桶的球形局部敏感哈希 (LSH) 来纠正非局部注意力。对于每个查询信号,NLSA 为其分配一个桶,并且只计算桶内的注意力。由此产生的稀疏注意力可以防止模型关注嘈杂和信息较少的位置,同时将计算成本从空间尺寸的二次方降低到渐近线性。大量实验验证了 NLSA 的有效性和效率。通过一些非局部稀疏注意力模块,我们的架构称为非局部稀疏网络 (NLSN),在数量和质量上都达到了 SISR 的最先进性能。
1. 简介
单幅图像超分辨率(SISR)近年来备受关注。通常,SISR的目标是在给定低分辨率对应物的情况下重建高分辨率图像。由于SISR任务的不稳定性,提出了各种图像先验[12,14,24,36,40,46]作为正则因子,包括最具代表性的稀疏和非局部先验,这是本文的重点。
几十年来,稀疏性约束作为许多图像重建问题的强大驱动力得到了很好的探索[4,7,19],尤其是SISR [46]。使用稀疏编码,图像可以很好地表达为预定义的超完备字典(如小波 [11] 和曲线 [9] 函数)中原子的稀疏林耳组合。结合基于示例的方法,稀疏代表使用原始图像补丁[46]或从退化的图像本身 [17, 19] 或外部数据集 [47]。随着用于 SISR 的深度卷积神经网络 (CNN) 的出现,层之间的非线性激活包含了稀疏性先验的好处。董等。提出 SRCNN [16] 首先成功地将卷积连接到经典的稀疏编码,其中 ReLU 激活通过将所有否定条目归零来大致强制执行 50% 的稀疏性。最近,Fan 等人。 [21] 通过明确地对隐藏神经元施加稀疏性约束来超越这一点,并得出结论,特征表示中的稀疏性确实是有益和有利的。广泛证明,稀疏性约束通过大大减少表示图像的元素数量来提高效率。它还在理论上 [10, 20] 和实践中处理反问题时产生更强大和稳健的表达式。
另一个广泛探索的图像先验是非局部 (NL) 先验。对于 SISR,采用 Non-Local Attention 成为一种更普遍的方式 [37, 51] 来利用图像自相似性,因为小模式往往会在同一图像中重复出现 [5]。 NL 操作在全局搜索那些相似的模式,并有选择地对那些相关的特征求和以增强表示。尽管 Non-Local Attention 直观且有望融合特征,但直接将其应用于 SISR 任务会遇到一些不容忽视的问题。首先,深层特征的感受野往往是全局的,因此深层特征之间的互相关计算并不那么准确[33]。其次,全局 NL 注意力需要计算所有像素位置之间的特征相互相似性。它导致关于图像大小的二次计算成本。为了缓解上述问题,一种策略是将 NL 搜索范围限制在局部邻域内。但它以丢失大量全局信息为代价降低了计算成本。
在本文中,对于特定的 SISR 任务,我们的目标是在非局部注意模块中强制执行稀疏性,并大大降低其计算成本。具体来说,我们提出了一种新颖的非局部稀疏注意力(NLSA)并将其嵌入到像 EDSR [32] 这样的残差网络基线中以形成非局部稀疏网络(NLSN)。为了强制 NLSA 的稀疏性,我们将深度特征像素空间划分为不同的组(称为注意力桶在本文中)。同一桶内的特征像素被认为是内容密切相关的。然后,我们在查询像素所属的桶内或排序后跨相邻桶应用非局部 (NL) 操作。我们通过在局部敏感散列 (LSH) 研究 [23] 的基础上构建分区方法来实现这一点,该方法搜索产生最大内积的相似元素。
所提出的 NLSA 将使从二次方降低 NL 的计算复杂性成为可能相对于空间维度渐近线性。在较小的内容相关桶中搜索相似线索也将使模块关注信息量更大且相关性更高的位置。因此,NLSA 保留了标准 NL 操作的全局建模能力,同时享受其稀疏表示的稳健性和效率。
总而言之,我们论文的主要贡献是:
• 我们建议通过一种新颖的非局部稀疏注意 (NLSA) 模块在 SISR 任务的非局部操作中强制执行稀疏性。稀疏性约束迫使模块专注于相关和信息丰富的区域,同时忽略不相关和嘈杂的内容。
•我们通过首先对特征像素进行分组并仅在名为注意力桶的组内进行非局部操作来实现特征稀疏性。我们采用局部敏感哈希(LSH)进行分组,并为每个组分配一个哈希码。所提出的方法显着降低了计算复杂性,从二次到渐近线性。
• 没有任何花哨的功能,一些 NLSA 模块可以将相当简单的 ResNet 骨干驱动到最先进的水平。大量实验证明了 NLSA 相对于标准非局部注意力 (NLA) 的优势。
2. 相关工作
2.1.稀疏表示形式。
在本节中,我们将简要回顾稀疏表示的关键概念。形式上,假设 x1, x2, …, xn ∈ Rd 是超完备字典 Dd×n (d < n) 中的 n 个已知示例。对于查询信号 y ∈ Rd,基于示例的方法 [12, 46] 将其表示为 D:y = α1x1 +α2x2 +…+αnxn (1) 中元素的加权和,其中 αi 是相对于 xi 的系数。设 α =[α1, α2, …, αn],则方程 1 可以写为:y = Dα (2)
当量。 2 产生一个不确定的线性系统。解决 α 成为不适定问题。为了缓解这种情况,稀疏表示假设 y 应该是稀疏表示的,即 α 应该是稀疏的:y=Dα, s.t.∥α∥0 ≤k (3) 其中 ∥.∥0 和 k 计算和限制非-分别为 α 中的零个元素。给定稀疏性约束,像 OMP [38] 这样的优化方法可以有效地近似方程 3 的解。由此产生的稀疏表示已被证明在图像重建领域非常强大 [19,47,53]。受他们成功的激励,我们受到启发将稀疏表示纳入非局部注意力。
2.2 Non-Local Attention (NLA) for image SR.
非局部操作假设小块倾向于在同一图像中重新出现,这已被充分证明是自然图像的强先验 [5]。非本地方法旨在利用这些自我复发来恢复潜在信号。非局部操作已广泛应用于许多图像恢复问题,例如超分辨率 [22]、去噪 [1、2、8、13] 和修复 [18]。王等。 [45] 首先将经典的非局部过滤与用于机器翻译的自我注意方法 [43] 联系起来,并进一步将非局部注意 (NLA) 引入深度神经网络以捕获高级任务的全局语义关系。对于图像超分辨率,最近的方法,如 NLRN [33]、SAN [15]、RNAN [51] 和 CSNLN [37],证明了通过采用 NL 注意力来探索远程特征相关性具有相当大的好处。然而,现有的为 SISR 任务设计的 NLA 要么局限于本地邻域,要么大量消耗计算资源。受最近在语言建模的自注意力方法方面取得的进展 [29、39、44] 的推动,我们提出了非局部稀疏注意力 (NLSA) 来包含远程信息并降低复杂性。
3. 非局部稀疏注意力(NLSA)
3.1 稀疏注意力的一般形式
如上所述,图像 SR 的非局部注意力的优点通常是以限制其搜索范围为代价的。为了缓解这个问题,我们建议将标准 NLA 与基于范例的方法联系起来,然后通过施加稀疏性约束来打破僵局。
非局部注意力
一般来说,非局部注意力通过汇总来自所有位置的信息来增强输入特征映射 X ∈ Rh×w×c。为了便于说明,我们将 X 重塑为一维特征 X ∈ Rn×c,其中 n = hw。给定一个查询位置i,对应的输出响应 yi ∈ Rc 可以表示为:

其中 xi 、xj 和 x^j 是 X 上位置 i、j 和 ^j 的像素级特征。 f (., .) 衡量相互相似度,g(.) 是特征转换函数。通过设置 D = [g(x1), …, g(xn)] ∈ Rc×n 和 αi = [f(xi, x1) , …, f(xi, xn)] ∈ Rn, 即 yi = Dαi. Non-Local Attention 的
稀疏约束
给定等式 4,可以通过将 α 的非零条目的数量限制为常数 k 来对非局部注意力施加稀疏约束。因此,可以推导出一种具有稀疏约束的非局部注意力的一般形式:

其中 δi 索引 αi 的非零元素,即 δi = {j | αi[j] ̸= 0},其中αi[j]表示αi中的第j个元素。使用稀疏注意力,可以通过忽略系数为零的元素来大大节省计算成本。
注意力桶
请注意,索引集 δi 表示给定查询应该关注的像素位置组。换句话说,δi 限制了可以从中计算非局部注意力的识别位置。在本文中,我们将这组位置定义为在注意力桶中。图 1 显示了不同 δi 下注意力桶的一些示例。例如,标准的非局部注意力跨越所有可能的位置,这使得聚合特征嘈杂且信息量较少。如果注意力跨越长度为 L 的局部邻域,则这指定了一个窗口 δi = {j||j − i| < L}。在这种情况下,一些远程上下文无法有效聚合。

直观上,更强大的稀疏注意力有望覆盖信息量最大且紧密的位置在全球范围内相关,因此忽略其他元素不会对性能造成损害。一种天真的方法是对所有相互相似性进行排序,然后使用前 k 个条目。然而,它需要先形成一个全注意力,这并没有带来效率的提升。在接下来的部分中,我们将展示如何通过高效地对注意力进行全局建模来为每个查询 i 形成注意力桶。
3.2. Attention Bucket from Locality Sensitive Hashing (LSH)
如上所述,理想的注意力不仅应该保持稀疏,还应该包含最相关的元素。在本节中,我们建议采用球形局部敏感哈希 (LSH) [3, 42] 来形成包含全局和相关元素以及查询元素的所需注意力桶。
具体来说,我们建议根据角度距离将嵌入空间空间划分为具有相似特征的桶。因此,即使注意力只跨越一个桶而保持稀疏,它仍然可以捕获大部分相关元素。)而远程元素则不能。球形 LSH 是为角距离设计的 LSH 的一个实例。可以直观地认为它是随机旋转一个内切到超球体中的交叉多胞体,如图2的顶部分支所示。散列函数将一个张量投影到超球体上,并选择最近的多胞体顶点作为其散列代码。因此,如果两个向量的角距离很小,它们很可能落在同一个哈希桶中,这也是定义的注意力桶。带独立同分布的旋转矩阵高斯项,即,x^=A( x) (7) ∥x∥2

哈希码,或分配的静默桶,定义为 h(x) = arg maxi(x^)。在散列所有元素之后,我们设法将空间划分为相关元素的桶,并且 xi 的注意力桶可以通过索引集 δi = {j |h(xj ) = h(xi )} 来识别。
在实践中, spherical LSH 对所有元素同时执行批量矩阵乘法,这只会增加可忽略的计算成本。预先知道要参加哪个桶,该模型可以通过忽略其他嘈杂或不相关的分区来实现高效和鲁棒性。
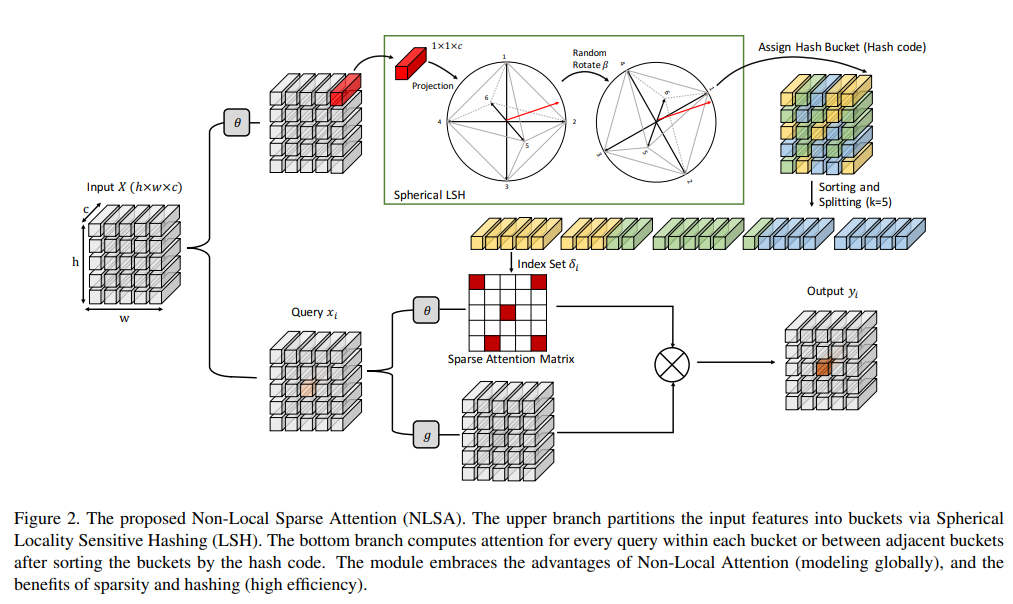
3.3. Non-Local Sparse Attention
一旦查询位置i的注意力桶索引集δi确定,提出的Non-Local Sparse Attention(NLSA) 可以很容易地从等式 6 中推导出来。具体来说,如图 2 所示,NLSA 将 X 中的每个像素级特征分配给一个桶,根据它们的内容相关性共享相同的哈希码,并且只有相应的桶元素有贡献到输出。在下文中,我们描述了在我们的实际实现中使用的一些技术。
处理不平衡的桶 Dealing with Unbalanced Bucketing.
理想情况下,给定总共 m 个桶,每个哈希桶将同样包含 mn 个元素。然而,这在实践中可能并不成立,因为桶往往是不平衡的。这也使得并行计算变得非常困难。为了克服这个困难,我们首先按桶值(哈希码)对特征进行排序,然后将排列定义为 π : i → π(i)。在知道它们的新位置(由上标表示)后,我们将它们分成大小为 k 的块:Cj = [xjk+1, xjk+2, …, x(j+1)k] (8)

其中 Cj 表示第 j 个块。因此,xi的attention bucket被更新到相应的chunk,δi =Index(Cj) ifπ(i)∈[jk+1,(j+1)k] (9)
以上策略更友好的用于并行执行计算。尽管有其优点,但将原始桶拆分为固定大小的块作为更新的注意力桶也会带来一个微妙的问题:一些新块可能会跨越原始桶边界,如图 2 所示。
幸运的是,这个问题可以通过允许注意力也跨越相邻的块来有效缓解。
Multi-round NLSA.
球形 LSH 的性质表明,某些相关元素总是有很小的机会被错误地散列到不同的散列桶中。幸运的是,可以通过独立散列多轮并对所有结果进行并集来减少这种机会。受此观察的启发,我们提出多轮 NLSA 以使散列过程更加健壮。令 δr,i 表示第 r 次哈希的 xi 的结果注意力桶,Att(xi,δr,i) 是等式 1 中定义的相关稀疏注意力。 6, 即,} f(xi,xj)Att(xi,δr,i) = }定义为: xi =} } }j∈δr,i f(xi,xj)donner, i i ^j

直观上,多轮NLSA是每一轮attention结果的加权和,权重系数代表query之间的归一化相似度以及每一轮分配给它的哈希桶中的元素。作为副作用,这种增加会线性增加相对于总哈希轮的计算成本。但我们仍然可以在评估期间动态调整此参数以研究权衡。
计算复杂性。
我们分析了所提出的 NLSA 的时间复杂度。给定输入特征 X ∈ Rn×c,具有 m 个桶的球形 LSH 的成本是矩阵乘法,即 O(ncm)。具有稀疏性约束(注意桶的大小)k 的注意操作(等式 6)的成本是 O(nck)。长度为 n 和 m 个不同数字(桶号)的序列的排序操作增加了一个额外的 O(nm) 和快速排序(并且可以使用高级排序算法进一步优化)。因此,我们的非局部稀疏注意力的总体计算成本是 O(nck + ncm + nm)。 r 轮的散列将增加计算成本 r 倍,导致 O(rnck + rncm + rnm)。 NLSA 仅对输入空间大小采用线性计算复杂度。
实例化。
实例化方程式中定义的非局部注意力。 6,我们为 f (., .) 选择嵌入式高斯,即 f(xi,xj) = exp(θ(xi)T φ(xj)),其中 θ 和 φ 是学习到的线性投影。在本文中,我们使用其变体之一设置 θ = φ 以确保投影特征位于同一子空间中以获得更好的 LSH。我们还发现共享 θ 和 φ 不会影响性能,这将在实验中得到验证。

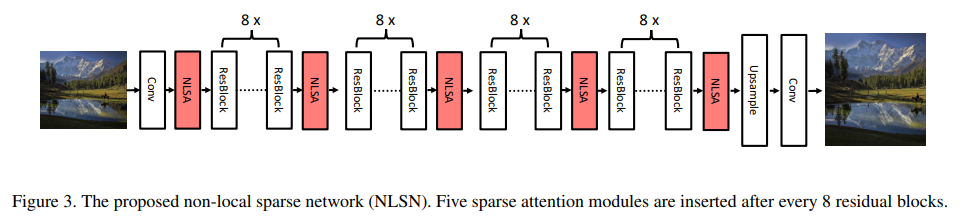
3.4. Non-Local Sparse Network (NLSN)
非局部稀疏网络 (NLSN) 为了证明非局部稀疏注意力的有效性,我们在一个相当简单的 EDSR [32] 主干上构建了我们的非局部稀疏网络 (NLSN),该主干由 32 个残差块组成。如图 3 所示,网络使用总共 5 个注意力块,每 8 个残差块后插入一个。该网络仅使用 L1 重建损失进行训练。
4. 实验
4.1.数据集和指标
遵循 [32, 52],我们使用 DIV2K 作为我们的训练数据集,其中包含 800 张训练图像。我们在 5 个标准基准测试我们的方法:Set5 [6]、Set14 [48]、B100 [34]、Urban100 [27] 和 Manga109 [35]。我们使用转换后的 YCbCr 空间中 Y 通道上的 PSNR 和 SSIM 指标评估所有结果。
4.2.实施和训练细节
对于非局部稀疏注意力,我们设置注意力桶大小(即块大小)k = 144。哈希桶的相应数量 m = min( hw , 128) 由输入大小 h × w 的除法动态确定和 k 但剪裁为 128。最终的非局部稀疏网络建立在具有 32 个残差块和 5 个附加 NLSA 块的 EDSR 骨干网络上。我们将所有卷积核大小设置为 3 × 3。所有中间特征都有 256 个通道,与 EDSR 中相同,除了那些嵌入在注意力块中的特征有 64 个通道。最后一个卷积层将深度特征转换为具有 3 个过滤器的 n 个 3 通道 RGB 图像。默认情况下,模型使用 r = 4 轮的 NLSA 进行训练和评估。在训练期间,我们从训练示例中随机裁剪 48 × 48 块,形成 16 幅图像的小批量。通过水平翻转和 90、180 和 270 度的随机旋转进一步增强训练图像。我们通过 ADAM 优化器 [28] 优化模型,其中 β1 = 0.9,β2 = 0.99 和 ǫ = 10−8。学习率设置为 10−4,并在 200 个 epoch 后减少 0.5。经过 1000 个 epoch 后得到最终模型。我们的模型使用 PyTorch 实现,并在 Nvdia 1080ti GPUs.4.3 上训练。
4.3. Comparisons with State-of-the-Arts 与最先进技术的比较
为了证明我们的 NLSA 的有效性,我们将它与 12 种最先进技术进行比较,包括
LapSRN [30]、SR-MDNF [49]、MemNet [41]、EDSR[ 32]、DBPN[25]、RDN[52]、RCAN[50]、
NLRN[33]、RNAN[51]、SRFBN[31]、OISR[26]和SAN[15]。
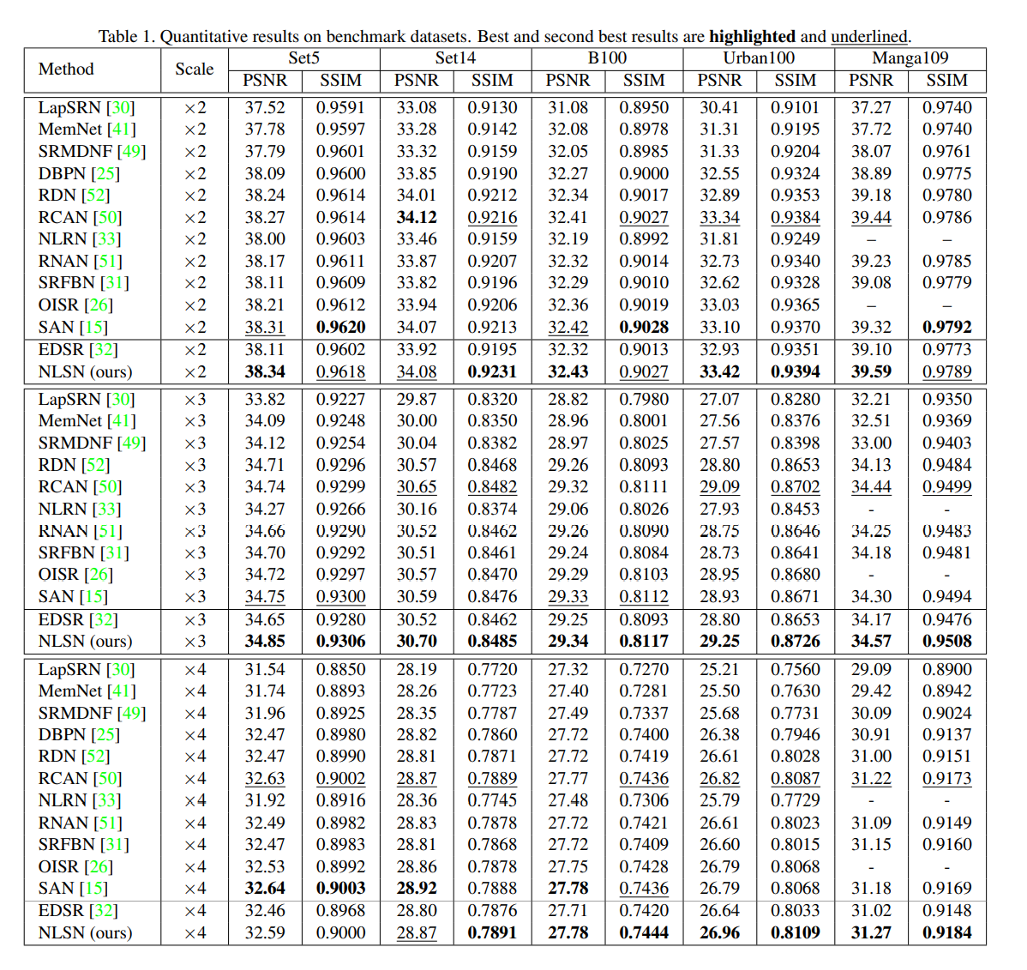
定量结果见表1. 我们的 NLSN 在几乎所有基准测试和所有上采样尺度上都取得了最好的结果。特别是,与其骨干 EDSR 相比,添加额外的 NLSA 在提高性能方面表现出极大的优势,甚至使 EDSR 的性能优于极具竞争力的 RCAN 和 SAN。特别是,所提出的 NLSN 在 Set5 和 Set14 中带来了大约 0.2 dB 的改进,在 B100 中带来了 0.1 dB 的改进,在 Urban100 和 Manga109 中带来了超过 0.4 dB 的改进。这些性能提升表明 NLSA 成功地探索了广泛的全局线索以获得更准确的超分辨率。此外,与之前的 NLRN 和 RNAN 等非局部方法相比,我们的网络在所有 entries。这主要是因为 NLSA 只关注内容相关的位置,从而产生更准确的相关性估计。值得注意的是,所有这些好处都是以增加少量计算为代价的,这大约相当于一些卷积运算,这表明我们的 NLSA 确实有效且高效。 Urban100 上的视觉结果如图 4 所示。我们的 NLSN 通过有效利用全局相似 patches.4.4 有效地恢复了图像细节。
4.4 消融研究
在本节中,我们进行了对照实验来分析所提出的 NLSA。我们用 16 个残差块构建基线模型。对于每个注意力变体,我们在第 8 个残差块之后插入一个相应的块。
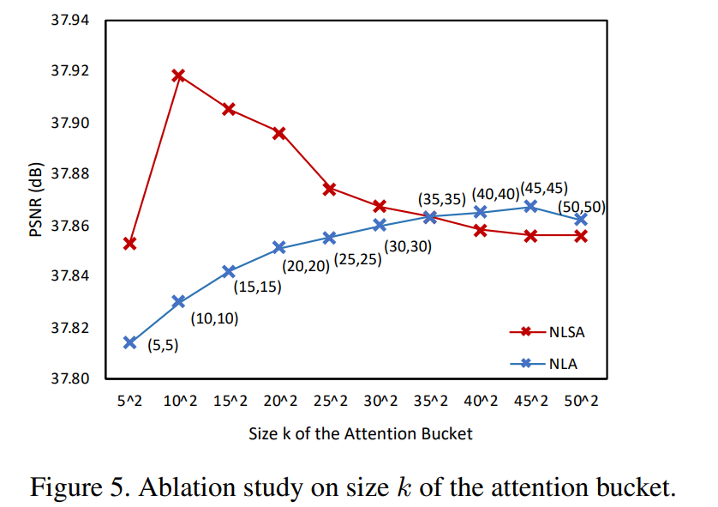
Size k of the Attention Bucket.
如上所述,NLSA 的稀疏性由注意力桶 k 的大小(块大小)控制。如果成功识别出大多数相关元素,小的 k 应该足以产生高质量的超分辨率。在这里,我们研究了不同 k 的影响,并将其与标准非局部注意进行比较,标准非局部注意具有恰好覆盖 k 个元素的局部窗口感受野。具体来说,我们设置 k = {52, 102, 152, 202, 252, 302, 402, 502}。如图 5 所示,NLSA 的性能在 k = 102 时达到峰值,这明显优于相同 cov- 的 NLA频率约为0.1分贝。此外,关注这100个位置甚至比NL注意力的最佳整体表现要好得多,NL注意力在2000多个位置(452)个位置。这些结果表明,我们的NLSA能够在全球范围内确定信息量最大的职位。这也表明,知道去哪里参加比参加更多更重要。
当进一步扩大注意力桶时,NLSA 变得更加密集。它的性能也开始接近预期的标准 NLA。这主要是因为较大的 k 通过减少哈希位数来降低 LSH 的有效性,并且更有可能跨越多个桶边界制作块。在 k 等于图像像素数的极端情况下,NLSA 将与标准的非局部注意相同。
Similarity Grouping via Spherical LSH.
球形 LSH 将空间划分为相关元素的注意力桶,它在 NLSA 中起着关键作用。我们通过将其与其他分区选项进行比较来研究其有效性。我们首先将其与随机哈希进行比较,即将元素分配给随机桶。如表 2 所示,随机哈希并没有像预期的那样带来比基线明显的改进。相比之下,Spherical LSH 比随机版本和基线提高了 0.1 dB 以上。
我们还实施了本地窗口策略,其中元素完全根据位置收集。我们设置窗口大小 q = 12,等于注意范围 (k = 144) 以进行公平比较。表 2 显示 Spherical LSH 优于局部窗口策略。这表明球形 LSH 确实有效地识别了局部邻域之外更有用的全局线索。

Multi-round NLSA
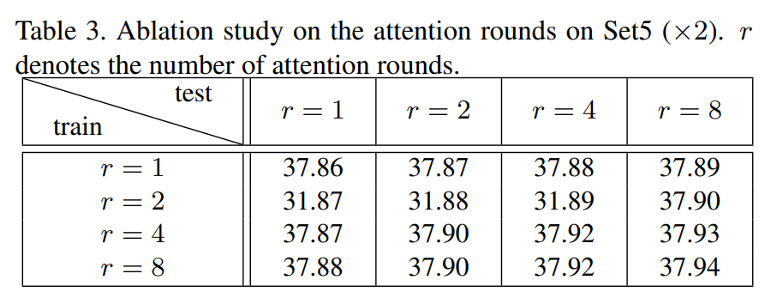
如上所述,更多轮的散列提高了 NLSA 的稳健性,但代价是计算成本线性增加。幸运的是,在测试过程中可以灵活调整注意力轮数 r。不同轮次训练和评估模型的结果如表 3 所示。结果表明,在训练或评估中增加哈希轮次可以不断提高超分辨率精度。正如预期的那样,在训练和测试期间,最大的轮数可获得最佳结果,但它也会产生最差的计算成本,
Shared linear projection in embedded Gaussian
即 θ = φ。我们研究了它对标准非局部注意力的影响。如表 4 所示,具有共享线性投影的模型产生的结果与未共享的模型相当,甚至略好。也就是说,这种修改不会对性能带来任何伤害。

Robustness.
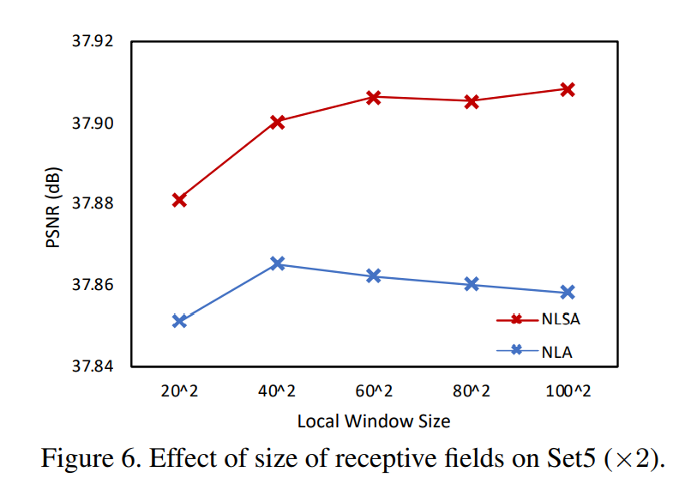
与标准的非本地注意力不同,我们的NLSA本质上对感受野具有鲁棒性,因为它避免了参加信息较少和相关性较低的地点。如图 6 所示,NLSA 和 NLA 都局限于本地窗口。这表明,对于相同的窗口大小,我们的 NLSA 始终优于 NLA。这证明 NLSA 捕获更准确的相关性并且对噪声信息更稳健。进一步增加感受野也略微改善了 NLSA,因为它可以从更远距离的上下文中捕获额外的信息。相反,随着更多信息被考虑在内,Non-Local Attention 的性能逐渐下降,这损害了它的相关性估计效率。
Efficiency.
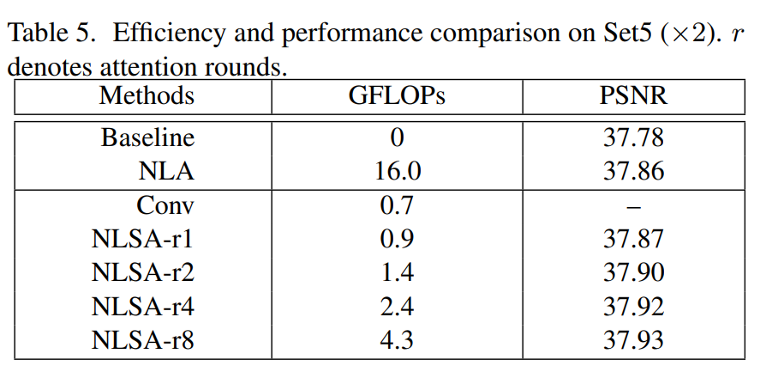
我们在计算效率方面将 NLSA 与标准非局部注意力进行了比较。表 5 报告了增量计算成本和相关性能。假设输入的空间大小为 100 × 100,输入和输出通道都设置为 64。为了更好地说明,我们还添加了正常 3×3 卷积运算的条目。如表 5 所示,NLSA 在获得卓越性能的同时显着降低了 NLA 的计算成本。例如,最高效的单轮 NLSA-r1 具有与卷积相似的计算成本,但通过标准 NL 运算实现了可比的性能。最好的结果是 NLSA-r8 的 8 轮注意力,它仍然比标准的非局部注意力高大约 3 倍。补充材料中提供了更多效率比较。
5. 结论
本文提出了一种新颖的非局部稀疏算法(NLSA),同时具有稀疏表示和非局部操作的优点。NLSA在全球范围内确定信息量最大的地点,而不关注不相关的区域,从而实现了大规模和高效的全球建模操作。进一步将其插入深度网络,我们的非本地稀疏网络在多个基准上设定了新的技术水平。广泛的评估表明,我们的NLSA优于标准的非局部注意力,并且确实有利于准确的图像超分辨率。

