
- 1【学习笔记】C# 机械学习 ML.net_c# 机器学习
- 2CNN内部计算及卷积核、通道数关系_卷积核通道数
- 3ADB命令用法大全
- 4uniapp使用uview - DatetimePicker 时间选择器 /时间戳转化_uview datetimepicker 数据回显
- 5XTuner 低成本微调实战
- 6vue3.0+antdv的admin管理系统vue-admin-beautiful推荐
- 7Rabbitmq安装及连接错误问题_com.rabbitmq.client.connectionfactory$1$$externals
- 8Open Ai 常见接口参数说明以及常见报错总结_openai.error.invalidrequesterror: this model's max
- 9JVM常用性能分析工具_jvm分析工具
- 10全面了解Kotlin_kotlin实现android自动化
spark结课之tip2
赞
踩
spark常用方法总结:
一、从内部创建RDD
(1).通过并行化集合(Parallelized Collections):
可以使用SparkContext的parallelize方法将一个已有的集合转换为RDD。
基本语法:
parallelize(collection, numSlices=None)
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- val conf = new SparkConf().setAppName("ParallelizeExample").setMaster("local")
- val sc = new SparkContext(conf)
-
- val data = Array(1, 2, 3, 4, 5)
- val rdd = sc.parallelize(data)
-
- rdd.foreach(println)
-
- sc.stop()
效果展示:

(2).makeRDD()创建
版本的 Spark 中,通常使用 parallelize() 方法来创建 RDD,这个方法与 makeRDD() 类似,都是用来从集合创建 RDD。
基本语法:
parallelize(collection, numSlices=None)
基础代码示例:
- from pyspark import SparkContext
-
- # 创建 SparkContext 对象
- sc = SparkContext("local", "parallelize Example")
-
- # 创建一个列表
- data = [1, 2, 3, 4, 5]
-
- # 使用 parallelize() 方法创建 RDD
- rdd = sc.parallelize(data)
-
- # 打印 RDD 中的元素
- for element in rdd.collect():
- print(element)
效果展示:

二、从外部创建RDD
Spark提供了多种方式来读取外部存储系统中的数据,通过外部存储系统(如HDFS、HBase等)读取数据创建RDD基础方式有五种:
1.文本文件:textFile
textFile() 方法是 Apache Spark 中用于从文件系统中读取文本文件的函数
基本语法:
textFile(path, minPartitions=None, use_unicode=True)
基础代码示例:
- from pyspark import SparkContext
-
- # 创建 SparkContext 对象
- sc = SparkContext("local", "textFile Example")
-
- # 读取文本文件
- lines = sc.textFile("path/to/file.txt")
-
- # 打印每一行
- for line in lines.collect():
- print(line)
2.Sequence文件:sequenceFile() [扩充]
sequenceFile() 方法用于在 Apache Spark 中读取 Hadoop SequenceFile 格式的文件,并将其作为 RDD 返回。SequenceFile 是 Hadoop 中一种常用的二进制文件格式,通常用于存储键-值对数据。
基本语法:
sequenceFile(path, keyClass=None, valueClass=None, keyConverter=None, valueConverter=None, minSplits=None, batchSize=0)
解释:
| 用法 | 解读 |
| collection | 是要转换为 RDD 的集合,通常是一个列表 |
| path | 要读取的 SequenceFile 文件的路径 |
| keyClass | 键的类名(可选) |
| valueClass | 值的类名(可选) |
| keyConverter | 键的转换器(可选) |
| valueConverter | 值的转换器(可选) |
| minSplits | 最小分片数(可选) |
| batchSize | 批处理大小(可选) |
基础代码示例:
- from pyspark import SparkContext
-
- # 创建 SparkContext 对象
- sc = SparkContext("local", "sequenceFile Example")
-
- # 读取 SequenceFile 文件并创建 RDD
- data = sc.sequenceFile("hdfs://path/to/sequence_file")
-
- # 打印 RDD 中的元素
- for key, value in data.collect():
- print(key, value)
3.对象文件(Object files):
objectFile() 方法用于在 Apache Spark 中读取以序列化形式保存的对象文件,并将其作为 RDD 返回。这种文件格式通常用于将对象序列化为字节流,并存储在文件中,以便在后续操作中进行读取和处理。
基本语法:
objectFile(path, minPartitions=None, batchSize=0)
基础代码示例:
- from pyspark import SparkContext
-
- # 创建 SparkContext 对象
- sc = SparkContext("local", "objectFile Example")
-
- # 读取对象文件并创建 RDD
- data = sc.objectFile("hdfs://path/to/object_file")
-
- # 打印 RDD 中的元素
- for obj in data.collect():
- print(obj)
4.Hive表:sql() 函数
在Spark中配置了Hive支持,你可以使用 sql() 函数执行Hive查询并将结果作为RDD返回。sql() 方法是 SparkSession 类的一个成员方法,用于执行 SQL 查询并返回结果作为 DataFrame。sql() 方法可以让你直接在 Spark 中执行 SQL 查询,而不需要编写基于 RDD 的代码。
基本语法:
DataFrame = sql(sqlQuery)
基础代码示例:
- from pyspark.sql import SparkSession
-
- # 创建 SparkSession 对象
- spark = SparkSession.builder \
- .appName("SQL Example") \
- .getOrCreate()
-
- # 创建 DataFrame
- df = spark.createDataFrame([(1, 'Alice'), (2, 'Bob'), (3, 'Charlie')], ["id", "name"])
-
- # 注册临时表
- df.createOrReplaceTempView("people")
-
- # 执行 SQL 查询
- result = spark.sql("SELECT * FROM people")
-
- # 显示结果
- result.show()

5.JDBC连接:
使用 jdbc() 函数来连接关系型数据库,并通过执行SQL查询来创建RDD。
基本语法:
- jdbcDF = spark.read \
- .jdbc(url="jdbc:postgresql:dbserver", table="schema.tablename",
- properties={"user": "username", "password": "password"})
基础代码示例:
- from pyspark.sql import SparkSession
- spark = SparkSession.builder \
- .appName("JDBC Example") \
- .config("spark.driver.extraClassPath", "path/tobc-driver.jar") \
- .getOrCreate()
-
- jdbcDF = spark.read \
- .format("jdbc") \
- .option("url", "jdbc:postgresql://database_server:port/database_name") \
- .option("dbtable", "table_name") \
- .option("user", "username") \
- .option("password", "password") \
- .load()
- jdbcDF.show()
- spark.stop()
操作算子:
Scala集合提供了丰富的计算算子,用于实现集合/数组的计算,这些计算子一般针对于List、Array、Set、Map、Range、Vector、Iterator等都可以适用
1.map()方法:
map() 方法用于对集合(如列表、数组、映射等)中的每个元素应用一个函数,并返回结果的新集合。
基本语法:
def map[B](f: (A) ⇒ B): List[B]
基础代码示例:
- val list = List(1, 2, 3, 4, 5)
- val incremented = list.map(x => x + 1)
- // incremented: List[Int] = List(2, 3, 4, 5, 6)
效果展示:

2.sortBy() 方法:
sortBy() 方法用于根据指定的标准对集合中的元素进行排序,并返回排序后的新集合。
基本语法:
def sortBy[B](f: (A) ⇒ B)(implicit ord: Ordering[B]): List[A]
基础代码示例:
- val list = List(3, 1, 4, 1, 5, 9, 2, 6)
- val sortedList = list.sortBy(x => x)
- // sortedList: List[Int] = List(1, 1, 2, 3, 4, 5, 6, 9)
效果展示:

3.collect() 方法:
用于对集合中的元素进行筛选和转换,并返回符合条件的新集合。
基本语法:
def collect[B](pf: PartialFunction[A, B]): List[B]
基础代码示例:
- val list = List(1, 2, 3, "four", 5.5, "six")
-
- val transformedList = list.collect {
- case i: Int => i * 2 // 对于整数类型的元素,将其乘以2
- }
-
- // transformedList: List[Int] = List(2, 4, 6)
-
-
效果展示:
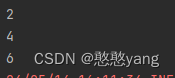
4.flatMap()方法:
flatMap() 方法是集合类(如列表、数组等)的常见操作之一,它结合了 map() 和 flatten() 两个操作,常用于在集合的元素上应用一个函数,并将结果展平成一个新的集合。
基本语法:
def flatMap[B](f: (A) => IterableOnce[B]): IterableOnce[B]
基础代码示例:
- val list = List(1, 2, 3, 4)
- val result = list.flatMap(x => List(x, x * 2))
-
- // result: List[Int] = List(1, 2, 2, 4, 3, 6, 4, 8)
效果展示:

5.take()方法:
take() 方法用于从集合中获取指定数量的元素,返回一个新的集合。
基本语法:
def take(n: Int): Repr
基础代码示例:
- val list = List(1, 2, 3, 4, 5)
-
- // 取前3个元素
- val result1 = list.take(3)
- // result1: List[Int] = List(1, 2, 3)
-
- // 对于空集合,take() 方法返回一个空集合
- val emptyList = List.empty[Int]
- val result2 = emptyList.take(3)
- // result2: List[Int] = List()
-
- // 如果指定的数量大于集合中的元素数量,将返回整个集合
- val result3 = list.take(10)
- // result3: List[Int] = List(1, 2, 3, 4, 5)
效果展示:

转换操作:
1.union()方法:
union() 方法用于将两个集合合并成一个新的集合,去除重复的元素。它是集合类的方法之一,适用于 Set 和 Seq 类型的集合。
基础代码示例:
- val set1 = Set(1, 2, 3)
- val set2 = Set(3, 4, 5)
-
- val result = set1.union(set2)
- // result: Set[Int] = Set(1, 2, 3, 4, 5)
效果展示:
2.filter() 方法:
基础代码示例:
- val list = List(1, 2, 3, 4, 5)
-
- val evenNumbers = list.filter(_ % 2 == 0)
- // evenNumbers: List[Int] = List(2, 4)
效果展示:
![]()
用于从集合中筛选出满足特定条件的元素,然后返回一个包含满足条件的元素的新集合。
3.distinst()方法:
distinct() 方法用于从集合中移除重复的元素,并返回一个包含唯一元素的新集合。这个方法适用于 Seq、Set 和 Map 类型的集合。
基础代码示例:
- val list = List(1, 2, 2, 3, 3, 4, 5, 5)
-
- val uniqueList = list.distinct
- // uniqueList: List[Int] = List(1, 2, 3, 4, 5)
效果展示:

4.intersection() 方法:
用于获取两个RDD(弹性分布式数据集)之间的交集。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object RDDIntersectionExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("RDDIntersectionExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建两个RDD
- val rdd1 = sc.parallelize(Seq(1, 2, 3, 4, 5))
- val rdd2 = sc.parallelize(Seq(4, 5, 6, 7, 8))
-
- // 计算两个RDD的交集
- val intersectionRDD = rdd1.intersection(rdd2)
-
- // 打印结果
- intersectionRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

5.subtract() 方法:
用于从一个 RDD 中移除另一个 RDD 中包含的元素,得到两个 RDD 的差集。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object RDDSubtractExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("RDDSubtractExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建两个RDD
- val rdd1 = sc.parallelize(Seq(1, 2, 3, 4, 5))
- val rdd2 = sc.parallelize(Seq(4, 5, 6, 7, 8))
-
- // 计算两个RDD的差集
- val subtractRDD = rdd1.subtract(rdd2)
-
- // 打印结果
- subtractRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

6.cartesian() 方法:
用于计算两个 RDD 的笛卡尔积(Cartesian product)。笛卡尔积是两个集合之间的所有可能的组合,其中一个元素来自第一个集合,另一个元素来自第二个集合。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object RDDCartesianExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("RDDCartesianExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建两个RDD
- val rdd1 = sc.parallelize(Seq("A", "B", "C"))
- val rdd2 = sc.parallelize(Seq(1, 2, 3))
-
- // 计算两个RDD的笛卡尔积
- val cartesianRDD = rdd1.cartesian(rdd2)
-
- // 打印结果
- cartesianRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

创建键值对RDD的方法:
1.reduceByKey():
用于将具有相同键的元素进行归约操作。它接收一个函数作为参数,该函数定义了对具有相同键的值进行合并的方式,并返回一个新的 RDD。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object ReduceByKeyExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("ReduceByKeyExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建一个包含键值对的RDD
- val data = Seq(("a", 1), ("b", 2), ("a", 3), ("b", 4), ("c", 5))
- val rdd = sc.parallelize(data)
-
- // 对具有相同键的值进行求和
- val result = rdd.reduceByKey(_ + _)
-
- // 打印结果
- result.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

2.groupBykey():
用于将具有相同键的元素进行分组。它接收一个键值对 RDD 作为输入,并返回一个新的 RDD,其中的元素是按键分组的。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object GroupByKeyExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("GroupByKeyExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建一个包含键值对的RDD
- val data = Seq(("a", 1), ("b", 2), ("a", 3), ("b", 4), ("c", 5))
- val rdd = sc.parallelize(data)
-
- // 按键分组
- val groupedRDD = rdd.groupByKey()
-
- // 打印结果
- groupedRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

3.combineByKey() :
用于执行基于键的聚合操作的高级转换函数之一。它提供了一种灵活的方式来对每个键的值进行聚合,而不需要事先进行预先聚合或排序。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object CombineByKeyExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("CombineByKeyExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建一个包含键值对的RDD
- val rdd = sc.parallelize(Seq(("apple", 3), ("banana", 5), ("apple", 7), ("banana", 2), ("orange", 1)))
-
- // 使用combineByKey方法进行基于键的聚合操作
- val aggregatedRDD = rdd.combineByKey(
- createCombiner = (v: Int) => (v, 1), // 初始化值为(v, 1),其中v是值,1表示计数
- mergeValue = (acc: (Int, Int), v: Int) => (acc._1 + v, acc._2 + 1), // 将新值合并到已存在的聚合值中,并更新计数
- mergeCombiners = (acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) // 合并不同分区的聚合值,并更新计数
- )
-
- // 打印结果
- aggregatedRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

RDD的连接方法:
1.join()方法:
用于将两个 RDD 按照键进行连接操作。它接收另一个键值对 RDD 作为参数,并返回一个新的 RDD,其中的元素是两个原始 RDD 中具有相同键的元素的笛卡尔积。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object JoinExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("JoinExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建两个包含键值对的RDD
- val rdd1 = sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3)))
- val rdd2 = sc.parallelize(Seq(("a", "apple"), ("b", "banana"), ("c", "cherry")))
-
- // 使用join方法进行连接操作
- val joinedRDD = rdd1.join(rdd2)
-
- // 打印结果
- joinedRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

2.rightOuterJoin():
右外连接是一种数据库连接操作,它返回两个数据集中所有右表(第二个数据集)的记录,以及左表(第一个数据集)中与右表匹配的记录。如果左表中没有匹配的记录,则会为其添加 null 值。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object RightOuterJoinExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("RightOuterJoinExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建两个包含键值对的RDD
- val rdd1 = sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3)))
- val rdd2 = sc.parallelize(Seq(("a", "apple"), ("b", "banana"), ("d", "date")))
-
- // 使用rightOuterJoin方法进行右外连接操作
- val joinedRDD = rdd1.rightOuterJoin(rdd2)
-
- // 打印结果
- joinedRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:
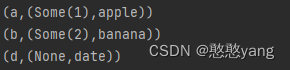
3.leftOuterJoin():
左外连接是一种数据库连接操作,它返回两个数据集中所有左表(第一个数据集)的记录,以及右表(第二个数据集)中与左表匹配的记录。如果右表中没有匹配的记录,则会为其添加 null 值。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object LeftOuterJoinExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("LeftOuterJoinExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建两个包含键值对的RDD
- val rdd1 = sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3)))
- val rdd2 = sc.parallelize(Seq(("a", "apple"), ("b", "banana"), ("d", "date")))
-
- // 使用leftOuterJoin方法进行左外连接操作
- val joinedRDD = rdd1.leftOuterJoin(rdd2)
-
- // 打印结果
- joinedRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

4.fullOuterJoin():
全外连接是一种数据库连接操作,它返回两个数据集中所有记录的并集,并将匹配的记录组合在一起。如果两个数据集中都没有匹配的记录,则会为其添加 null 值。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object FullOuterJoinExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("FullOuterJoinExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建两个包含键值对的RDD
- val rdd1 = sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3)))
- val rdd2 = sc.parallelize(Seq(("a", "apple"), ("b", "banana"), ("d", "date")))
-
- // 使用fullOuterJoin方法进行全外连接操作
- val joinedRDD = rdd1.fullOuterJoin(rdd2)
-
- // 打印结果
- joinedRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:
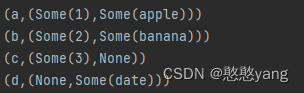
5.zip() :
用于将两个 RDD 中的元素一一配对的方法之一。它将两个 RDD 中的元素按顺序一一配对,形成新的 RDD,其中每个元素是一个由两个 RDD 中对应位置的元素组成的元组。
基础代码示例:
- import org.apache.spark.{SparkConf, SparkContext}
-
- object ZipExample {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf().setAppName("ZipExample").setMaster("local[*]")
- val sc = new SparkContext(conf)
-
- // 创建两个包含元素的RDD
- val rdd1 = sc.parallelize(Seq(1, 2, 3, 4))
- val rdd2 = sc.parallelize(Seq("apple", "banana", "orange", "grape"))
-
- // 使用zip方法将两个RDD进行配对
- val zippedRDD = rdd1.zip(rdd2)
-
- // 打印结果
- zippedRDD.collect().foreach(println)
-
- sc.stop()
- }
- }
效果展示:

大家有什么好的方法和建议,可以发布在评论区或者留言给我, 小杨还有待改进的地方,望各位大师监督!

