
- 1组件的概念理解
- 2Docker的一个简单例子(二)_最简单的docker案例
- 3服务器端通过nginx部署项目(含websoket)_websocket服务端配置项
- 4SpringBoot + RabbitMQ 死信队列中出现Execution of Rabbit message listener failed.的错误解决_execution of rabbit message listener failed, and t
- 5【常见总线接口协议】学习笔记1_axi ahb spi iic
- 6自然语言处理(NLP)-第三方库(工具包):NLTK(更适合英文数据集,在中文数据集上效果不好)【命名实体识别、分词、词性标注、依存句法分析、语义角色标注、语料库】_nltk库命名实体识别器
- 7谷歌裁员1.2万人,CEO年薪达15亿,网友:“地表最强 CEO !”
- 8java获取当前的具体时间(年月日时分秒)_java获取当前时间年月日时分秒
- 9Hexo bamboo主题配置(三)_hexo theme bamboo
- 10启动rabbitmq_rabbirmq启动
Python中15种Seaborn可视化图表详解_python seaborn
赞
踩
可视化是以图形形式表示数据或信息的过程,在本文中,将介绍Seaborn的最常用15个可视化图表。
Seaborn是一个非常好用的数据可视化库,它基于Matplotlib,并且提供了一个高级接口,使用非常见简单,生成图表也非常的漂亮。

安装
安装非常简单:
Pip install seaborn
- 1
在使用时只要导入就可以了。
import seaborn as sns
- 1
Seaborn提供了一些内置的数据集,这里我们使用Seaborn的Iris数据集。
data=sns.load_dataset('iris')
data[10:15]
- 1
- 2

我们看看数据量
data['species'].value_counts()
- 1

1、条形图
条形图用于表示分类变量,它只显示平均值(或其他估计值)。我们为x轴选择一个分类列,为y轴(花瓣长度)选择一个数值列,我们看到它创建了一个为每个分类列取平均值的图。
sns.barplot(x='species',y='petal_length',hue='species',data=data)
- 1

2、散点图
散点图是由几个数据点组成的图。x轴表示花瓣长度,y轴表示数据集的萼片长度。
sns.scatterplot(x='petal_length',y='sepal_length',hue='species',style='species',s=90,data=data)
- 1

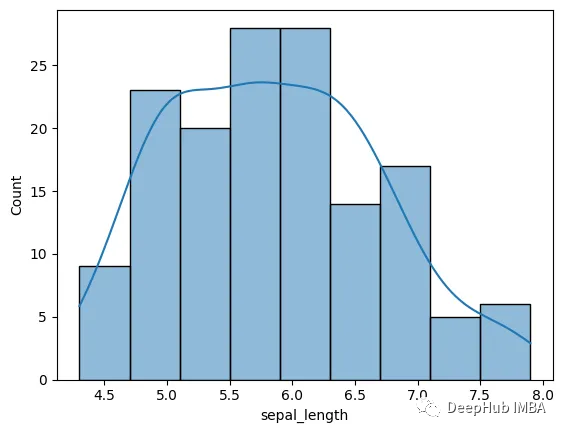
3、直方图
直方图通常用于可视化单个变量的分布,但它们也可用于比较两个或更多变量的分布。除了直方图之外,KDE参数还可以用来显示核密度估计(KDE)。这里,我们使用萼片长度。
sns.histplot(x='sepal_length',kde=True,data=data)
- 1
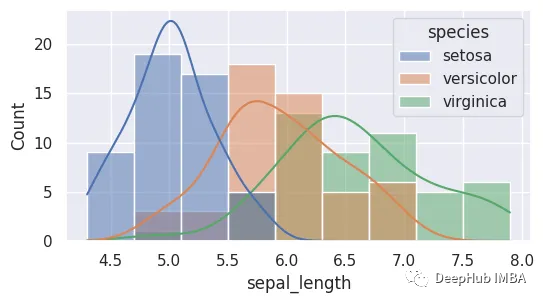
sns.histplot(x='sepal_length',kde=True,hue='species',data=data)
- 1
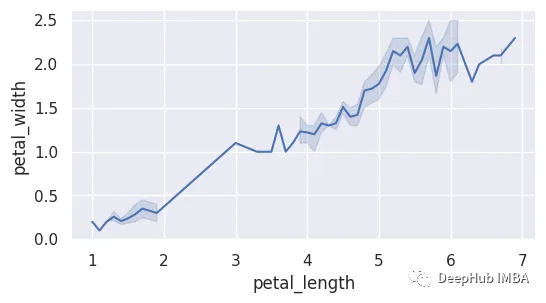
4、线形图
线形图可以用来可视化各种不同的关系。它们易于创建和分析,在线形图中每个数据点由直线连接。
sns.lineplot(x='petal_length',y='petal_width',data=data)
- 1
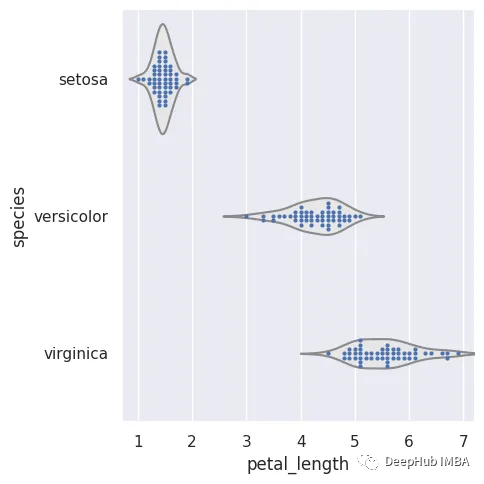
5、小提琴图
小提琴图可以表示数据的密度,数据的密度越大的区域越胖。“小提琴”形状表示数据的核密度估计,每个点的形状宽度表示该点的数据密度。
sns.violinplot(x='species',y='petal_length',data=data,hue='species')
- 1

6、箱线图
箱形图由一个箱形图和两个须状图组成。它表示四分位数范围(IQR),即第一和第三四分位数之间的范围。中位数由框内的直线表示。须状图从盒边缘延伸到最小值和最大值的1.5倍IQR。异常值是落在此范围之外的任何数据点,并会单独显示出来。
sns.boxplot(x='species',y='sepal_length',data=data,hue='species')
- 1

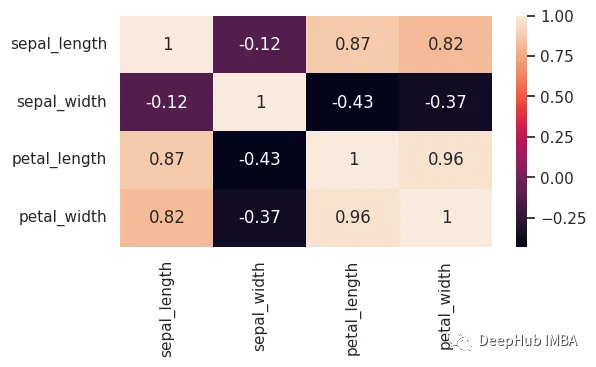
7、热图
热图是数据的二维可视化表示,它使用颜色来显示变量的值。热图经常用于显示数据集中的各种因素如何相互关联,比如相关系数。
heat_corr=data.corr()
sns.heatmap(heat_corr,annot=True)
- 1
- 2
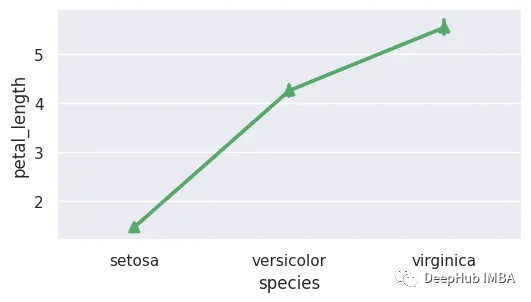
8、点图
点图是一种统计图表,用于显示一组数据及其变异性的平均值或集中趋势。点图通常用于探索性数据分析,可以快速可视化数据集的分布或比较多个数据集。
sns.pointplot(x='species',y='petal_length',data=data,markers ='^',color='g')
- 1
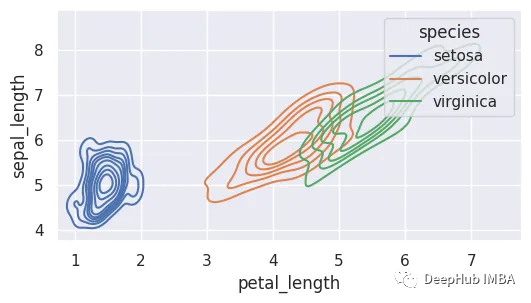
9、密度图
密度图通过估计连续随机变量的概率函数来表示数据集的分布,也称为核密度估计(KDE)图。
sns.kdeplot(x='petal_length',data=data,hue='species',multiple='stack')
- 1

sns.kdeplot(x='petal_length',y='sepal_length',data=data,hue='species')
- 1
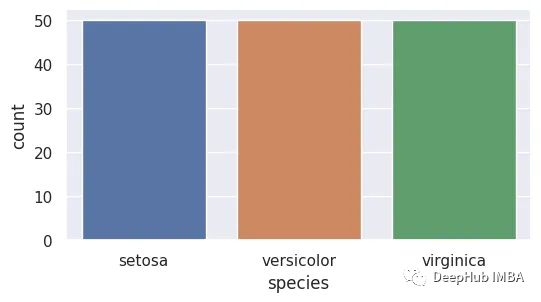
10、计数图
计数图是一种分类图,它显示了分类变量的每个类别中观测值的计数。它本质上是一个柱状图,其中每个柱的高度代表特定类别的观测值的数量。
sns.countplot(x='species', data=data)
- 1
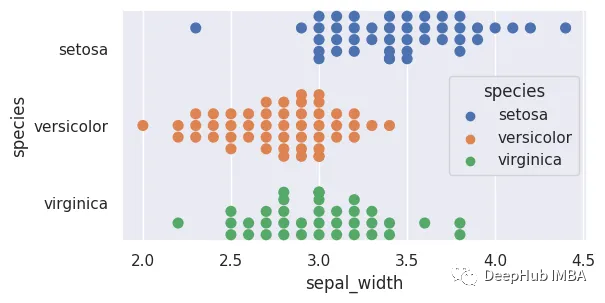
11、分簇散点图
分簇散点图与条形图相似,但是它会修改一些点以防止重叠,这有助于更好地表示值的分布。在该图中,每个数据点表示为一个点,并且这些点的排列使得它们在分类轴上不会相互重叠。
sns.swarmplot(x='sepal_width',y='species',data=data,hue='species',dodge=True,orient='h',size=8)
- 1
12、配对图
配对图可视化了数据集中几个变量之间的成对关系。它创建了一个坐标轴网格,这样所有数值数据点将在彼此之间创建一个图,在x轴上具有单列,y轴上具有单行。对角线图是单变量分布图,它绘制了每列数据的边际分布。
`sns.set(rc = {"figure.figsize":(6,3)})` `sns.pairplot(data=data,hue='species')`
- 1

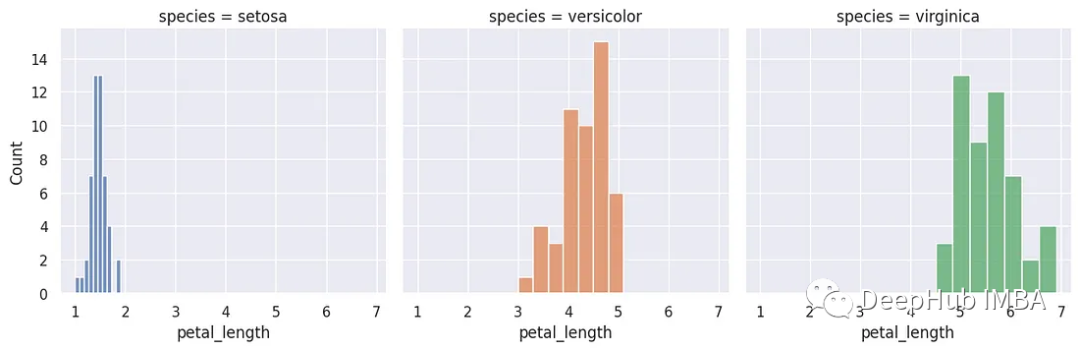
13、Facet Grid
Seaborn中的FacetGrid函数将数据集和一个或多个分类变量作为输入,并创建一个图表网格,每种类别变量的组合都有一个图表。网格中的每个图都可以定制为不同类型的图,例如散点图、直方图或箱形图。
g=sns.FacetGrid(data, col="species",height=4,hue='species')
g.map(sns.histplot, "petal_length")
- 1
- 2
14、联合分布图
联合分布图将两个不同的图组合在一个表示中,可以展示两个变量之间的关系(二元关系)。
sns.jointplot(x="sepal_length", y="sepal_width", data=data,
palette='Set2',hue='species')
- 1
- 2

15、分类图
cat图(分类图的缩写)是Seaborn中的定制的一种图,它可以可视化数据集中一个或多个分类变量与连续变量之间的关系。它可用于显示分布、比较组或显示不同变量之间的关系。
sns.catplot(data=data, x="petal_length", y="species", kind="violin", color=".9", inner=None)
sns.swarmplot(data=data, x="petal_length", y="species", size=3)
- 1
- 2
总结
Seaborn对于任何使用Python处理数据的人来说都是一个非常好用的工具,它易于使用,并且提供更美观的图形使其成为探索和交流数据最佳选择。它与其他Python数据分析库(如Pandas)的集成使其成为数据探索和可视化的强大工具。
当下这个大数据时代不掌握一门编程语言怎么跟的上时代呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板

