
- 1当代年轻人,为什么越来越穷?_当今的年轻人行为数据分析
- 2文字溢出自动向上循环滚动_vue3 溢出 自动滚动
- 3AI在前端设计中的创新应用与实战示例
- 4软件设计文档示例模板 - 学习/实践_软件详细设计文档示例
- 5利用开源AI引擎平台:实现企业客户对话分析与优化中的应用|可本地化部署_基于开源原子ai能力,自主部署 ai+内容运营
- 6Java通信原理(1)——TCP/IP协议_java tcp
- 7CentOS命令学习之tar打包与解压
- 8基于self-attention的TCN-GRU时间序列预测Python程序
- 9vue实现滚动加载_vue滚动分页加载
- 10HarmonyOS ArkTS 横竖屏设置_arkts某一页面横屏
连续两年最佳论文!达摩院NLP引领检索增强和实体识别技术,U-RaNER荣膺9项评测冠军...
赞
踩

连续两年获得 Best System Paper,看看阿里达摩院怎么做检索增强和实体识别的。

前言
SemEval(Semantic Evaluation)是自然语言处理领域全球影响力最大的语义评测会议,第 17 届 SemEval 与 ACL 会议在加拿大多伦多同期举办。阿里达摩院在多语言复杂命名实体识别评测中获得 9 项冠军,13 个 track 平均 F1 较排名第二的队伍 +7pt。
同时,论文 A Unified Retrieval-augmented System for Multilingual Named Entity Recognition 在 300+ 篇论文中脱颖而出,荣获唯一 Best System Paper Award,这也是达摩院团队工作连续第二年获得 SemEval 最佳论文奖项。

评测官网:
https://multiconer.github.io/
论文标题:
DAMO-NLP at SemEval-2023 Task 2: A Unified Retrieval-augmented System for Multilingual Named Entity Recognition
论文链接:
https://arxiv.org/pdf/2305.03688.pdf
代码链接:
https://github.com/modelscope/AdaSeq/tree/master/examples/U-RaNER

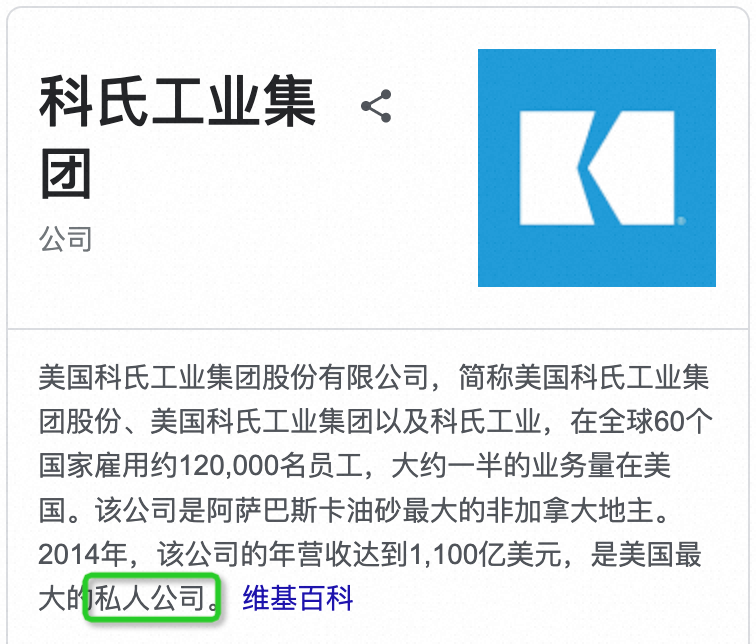
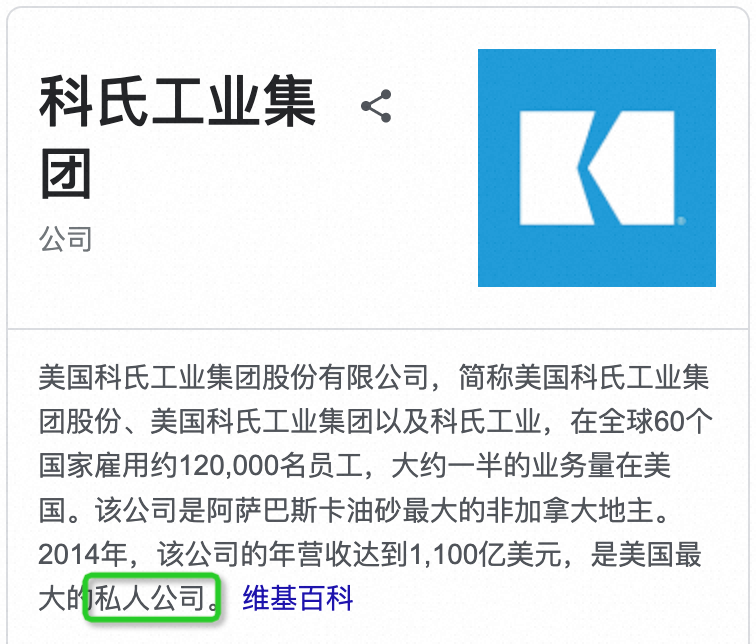
“研究由科式工业美国石油学会和艾克森赞助”,科式工业是私人公司还是上市公司?在解决这种实体知识类问题时,大模型经常会出现知识幻觉,小模型也因为自身容量原因效果非常有限。面对浩如烟海且日新月异的知识,仅依靠内化的权重来学习知识的模型是非常低效的。
U-RaNER 是阿里巴巴达摩院在信息抽取上的集大成之作,延续了 RaNER 系列的检索增强方法(ACL 21/23,EMNLP 22,NAACL 22,COLING 22,SemEval 22),学习像人类一样,从多源渠道查找知识并利用海量的新知识去更好地理解 query。该方法在 SemEval 2023 评测中取得了 9 个 track 第一名,同时也是该系列工作连续第二年获得 Best System Paper!

实体识别能有多难?
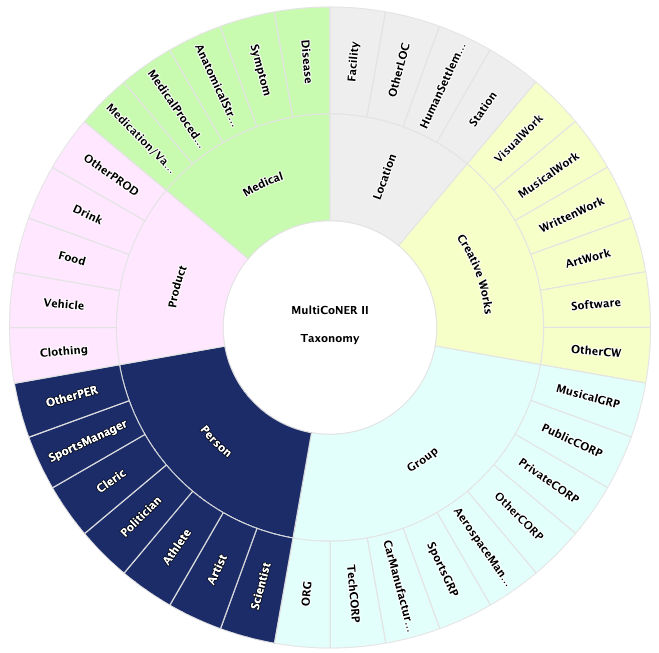
实体识别(NER)被视为信息抽取的重要任务之一,被广泛应用于搜索引擎、机器翻译、对话机器人等系统中。
在海量业务场景中我们面临着相似的数据挑战:
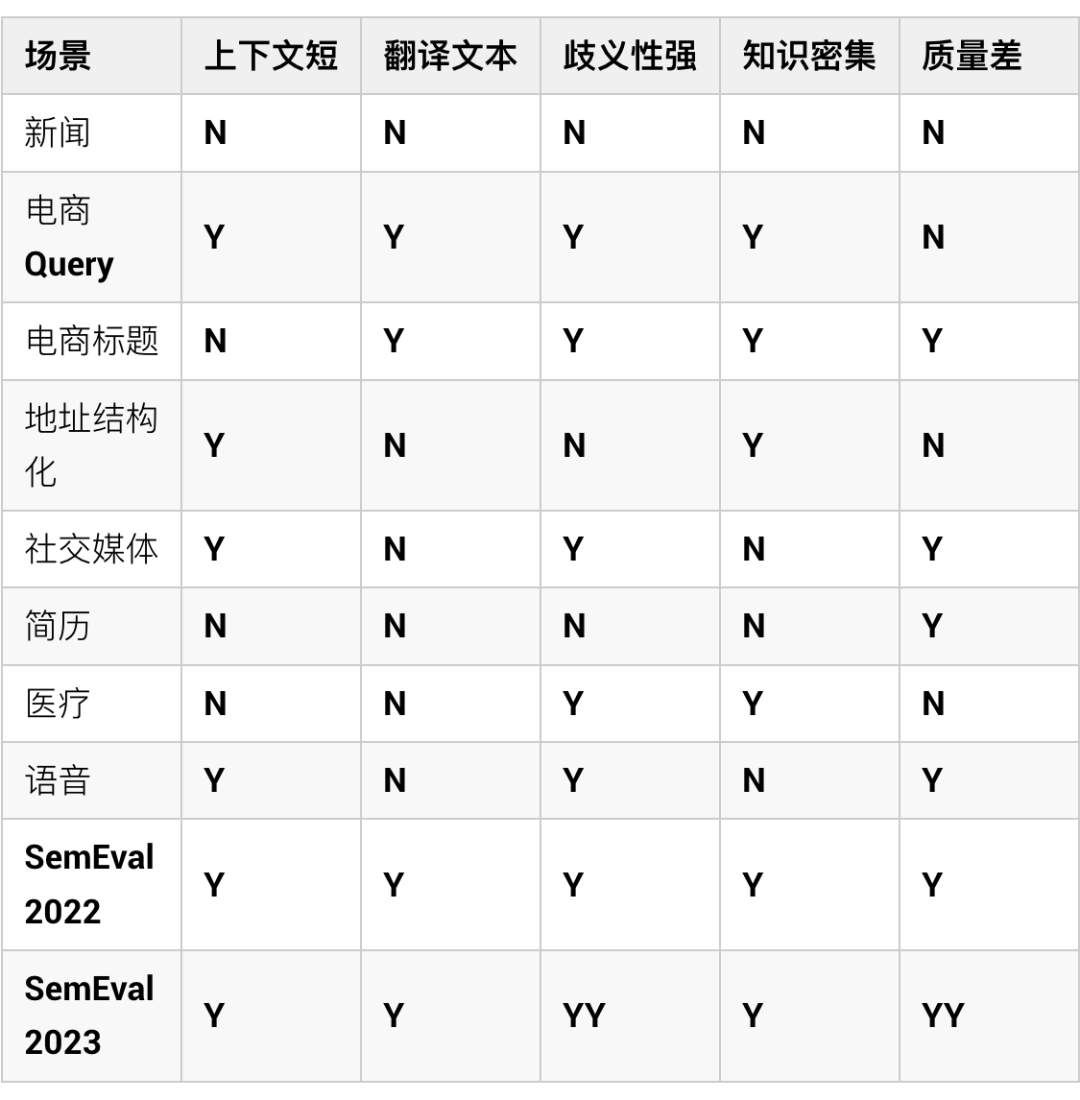
SemEval 2023 task 2 基于真实世界数据,构建了细粒度多语言 NER 评测,吸引了世界范围内 50+ 参赛团队,并且提出了以下挑战:
多语言混合:本次评测包含 12 个语种以及语种之间的混合。其中,低资源语种语料稀疏、数据分布不平衡,直接在不平衡数据上学到的模型在不同语言上性能差距明显。语种之间文法、知识有联系也有冲突,如何有效利用多语言数据,也是难点之一。
细粒度实体类别:在去年评测6大类实体的基础上,今年新增 33 个细分类。要进一步区分私人公司、上市公司、音乐组织、体育组织等类型,即使对人类来说也是不小的挑战。
含有文本噪声:真实场景中文本可能含有拼写错误(可能来自 ASR 或 OCR),这是今年的新增挑战,可能会对基于词典匹配或基于检索的方法带来较大影响。
实体歧义性强:相同的词在不同语境下可能是实体也可能不是,比如 inside out, among us;也可能指的是不同的实体,比如 Bonanza 在不同语境下可能指电影、游戏或者电视节目。
缺少表面特征:首字母大写、标点等表面特征是传统 NER 方法中成效卓著的特征(尤其是对欧洲语系),但在 ASR 或者搜索 query 等真实场景中可能缺少这些特征,本评测模拟了这些场景中的设置,进一步增强了识别实体的难度。
面对这些技术挑战, 研究人员迫切需要进一步探索 NER 模型的性能上限。

大模型能解决实体识别问题吗?
不少人认为,大模型的出现能够直接解决机器翻译、情感分析、实体识别等问题,部分 NLP 子任务(尤其是中间任务)再无研究的必要。但研究结果表明,大语言模型在实体识别任务上普遍表现不如预期 [1][2][3],大模型在 zero-shot 或 few-shot 场景下大概是 50-60 分,远低于一个完全训练的小模型 80-95 分。
在本次 SemEval 评测中,达摩院团队也给出了他们的大模型尝试结果。实验结果表明,在复杂实体识别问题上,大模型的 zero-shot 和 few-shot 能力均只有十几分,解决真实场景中的实体识别问题任重道远!
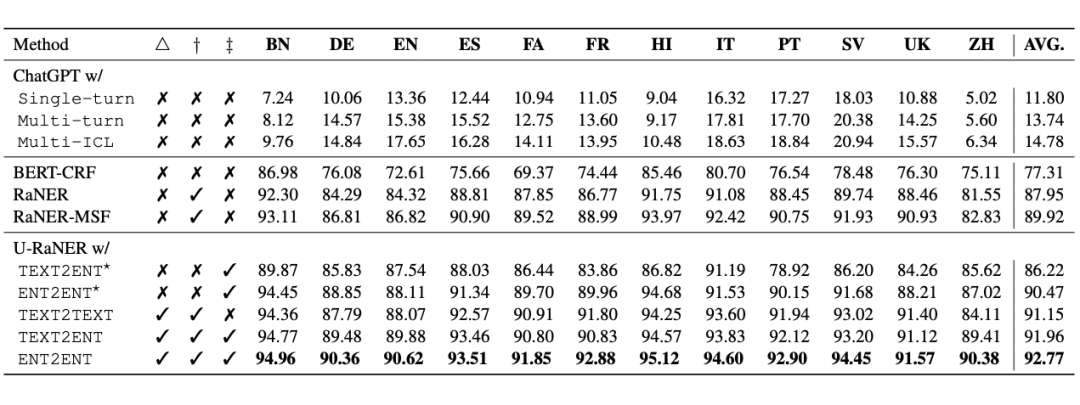

检索增强范式下的NER
仅依靠内化的权重来学习知识的模型是非常低效的。大模型以其庞大的参数量记住了很多知识,但代价却是严重的知识幻觉问题。检索增强技术近年来在开放域问答、机器翻译、信息抽取等领域被广泛研究,也被经常应用在大模型服务中,如 New Bing, ChatGPT Retrieval Plugin, Bard 等。
它为解决这类问题提供了新范式:1)将知识外化,使用检索的方式选择合适的知识,建模 p(z|x),其中 x 表示 query,z 表示辅助知识;2)再利用辅助知识帮助模型进行推理,建模 p(y|x,z),其中 y 表示答案。
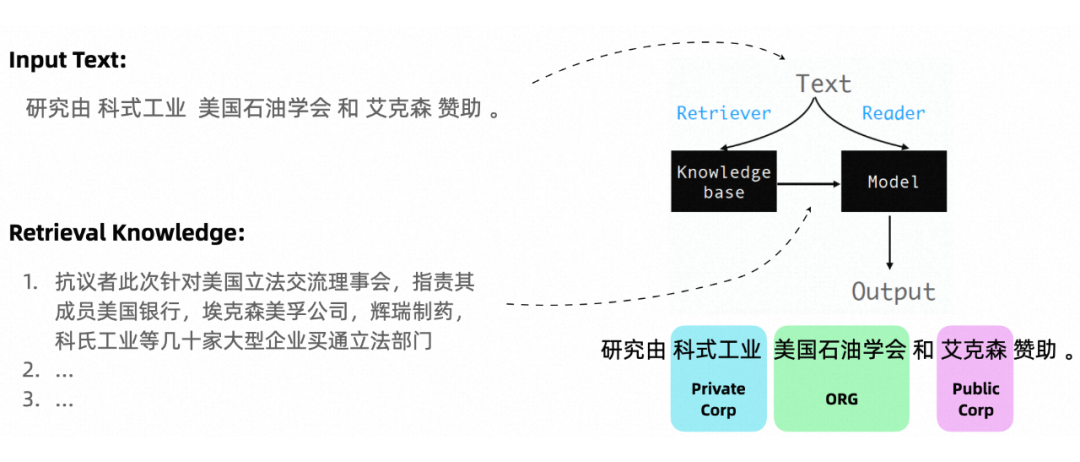
4.1 U-RaNER
U-RaNER 沿用并拓展了检索增强范式下的 NER 方法,做出了以下几点改进:
将传统的单检索源扩展到多源异构检索源,丰富了知识的多样性;
提出了多种检索策略(TEXT2TEXT, TEXT2ENT, ENT2ENT),进一步拓展有效信息的召回率;
提出了知识注入(Knowledge Infusion)的方法,使得长文本可以被编码为向量并输入给模型,从而可以引入更多知识辅助模型理解 query。
U-RaNER 在评测中还使用了很多 NER 优化技巧,如 Multi-stage Finetuning(MSF)、Ensemble 等,并提供了大量的分析性实验,更多细节大家可以去看原文。
这里谈谈该工作在研究中尝试回答的几个问题:
检索哪些信息对模型的提升更大?
使用的检索信息是不是越多越好?
检索信息过长怎么输入给模型?
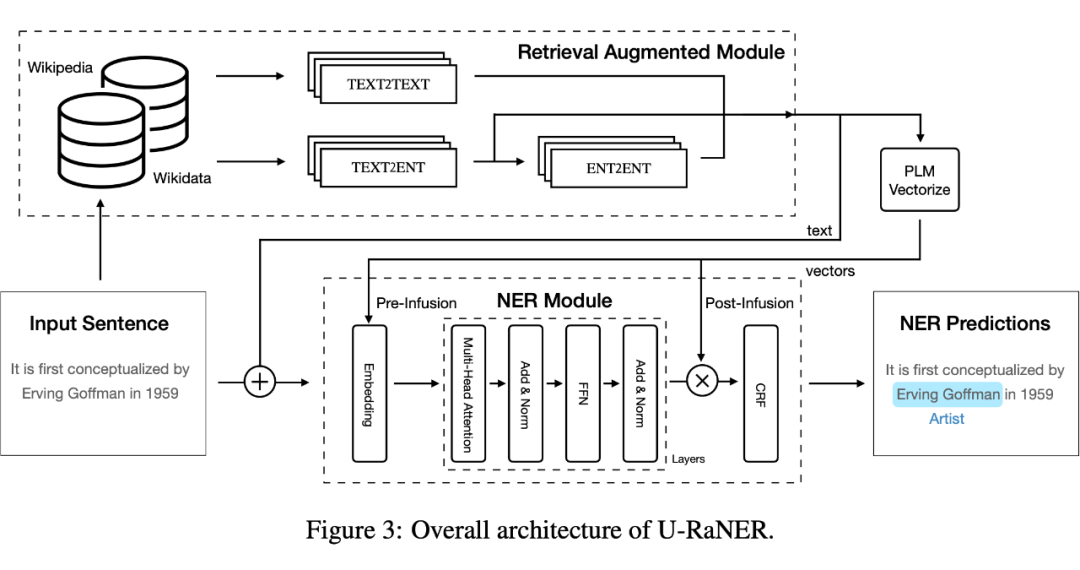
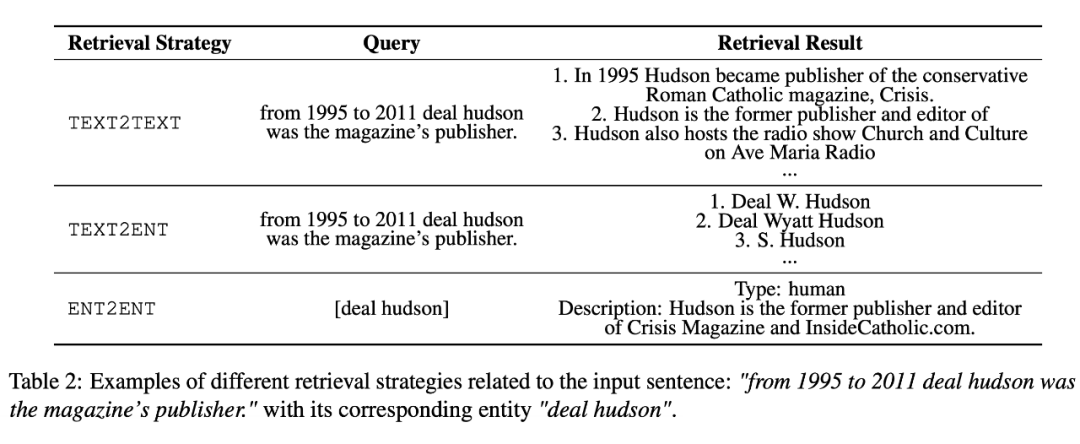
4.2 检索哪些信息对模型的提升更大?
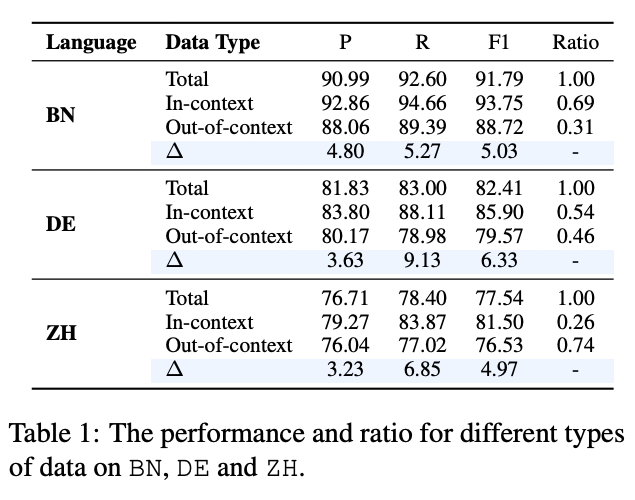
NER 任务为分析相关性收益提供了便利,该工作将 query 中的实体根据 是否被检索到的辅助知识(context)覆盖分为 In-context 和 Out-of-context 两类,从 BN、DE、ZH 三种语料上来观察,In-context 实体比 Out-of-context 实体更容易被识别,在 F1 指标上高 5-6%。实验结果从这个角度验证了,检索知识与 query 实体越相关,带来的增益越明显。
4.3 使用的检索信息是不是越多越好?
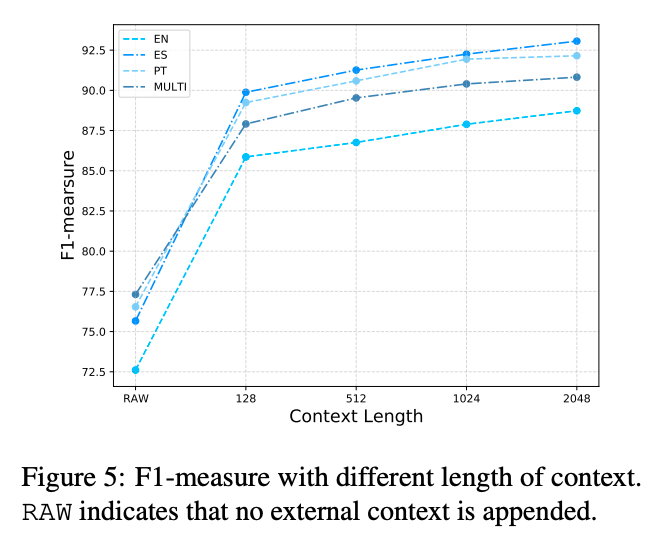
是的。该工作在 EN、ES、PT、MULTI 四种语料上测试了不同检索信息(Context)长度对模型效果带来的影响。实验结果表明,检索信息中的知识容量随着长度递增,使用越多检索信息模型效果提升越多。
4.4 检索信息过长怎么输入给模型?
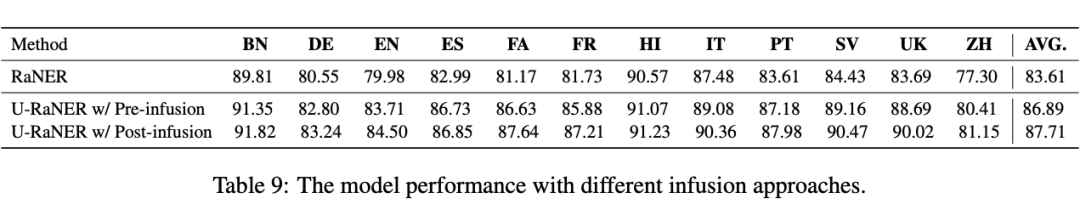
文章中的模型底座基于 xlm-roberta-large,输入长度限制为 512。为了突破长度限制,使用更多的检索信息作为上下文,该工作提出了知识注入(Knowledge Infusion)的方法。如 Figure 3 所示,检索信息通过一个外部的 PLM 被编码成定长的知识向量,以向量的形式参与模型训练和推理。实验结果表明,在使用相同长度检索信息的前提下,知识注入方法显著优越于拼接的方法;同时,知识注入方法可以让模型引入更长的检索信息,进一步提高模型效果上限。
4.5 评测排名
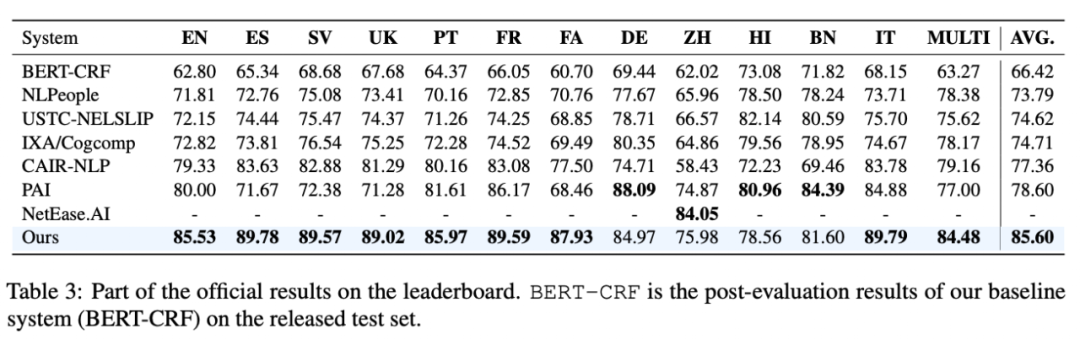
这篇非常有启发性的工作,在评测中的表现也十分亮眼。SemEval 2023 Task 2 评测吸引了 50+ 国内外的参赛队伍。阿里达摩院 U-RaNER 在 9 个赛道获得冠军,平均分比第二名高 7 个点。

总结
达摩院该工作提出的 U-RaNER 方法,延续并拓展了 RaNER 系列的检索增强方法,学习像人类一样,从多源渠道查找知识并利用海量的新知识去更好地理解 query。该工作使用了多源异构检索源,丰富了知识的多样性,并提出了多种检索策略,进一步拓展有效信息的召回率;同时,提出了知识注入的方法,使得长文本可以被编码为向量并输入给模型,从而可以引入更多知识辅助模型理解 query,提升了模型在复杂 NER 场景下的表现。
ChatGPT、GPT4 等大模型的出现,给 NLP 工作带来了新的思路和巨大变革。然而,大模型也存在一些问题,其中最重要的问题之一就是知识幻觉问题,检索增强就是改善知识幻觉的一种行之有效的方法,通过检索相关信息,有效提高模型的可靠性和鲁棒性,进一步优化大模型的性能表现,降低知识幻觉的风险。本文中提到的检索增强优化方法也为大模型训练和优化提供了新的思路。

参考文献
[1] Wei, Xiang, Xingyu Cui, Ning Cheng, Xiaobin Wang, Xin Zhang, Shen Huang, Pengjun Xie, Jinan Xu, Yufeng Chen, Meishan Zhang, Yong Jiang and Wenjuan Han. “Zero-Shot Information Extraction via Chatting with ChatGPT.”
[2] Wang, Shuhe, Xiaofei Sun, Xiaoya Li, Rongbin Ouyang, Fei Wu, Tianwei Zhang, Jiwei Li and Guoyin Wang. “GPT-NER: Named Entity Recognition via Large Language Models.”
[3] Qin, Chengwei, Aston Zhang, Zhuosheng Zhang, Jiaao Chen, Michihiro Yasunaga and Diyi Yang. “Is ChatGPT a General-Purpose Natural Language Processing Task Solver?”
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

