
- 1解决方案-等级保护网络安全2.0内容-小白白帽子笔记
- 2数字时代网络安全即服务的兴起
- 3做方差分析需要正态性检验吗_医学统计案例研究:采用KruskalWallis H检验心衰病人病情的生化指标差异——【杏花开医学统计】...
- 4springboot宠物咖啡馆平台x9rzc[独有源码]了解毕业设计的关键考虑因素_宠物咖啡店参考文献
- 5AXI Quad SPI IP核子模块_vivado startupe3
- 6积木报表JimuReport跟ureport2对比_润乾 积木 ureport
- 7Java8使用Lambda表达式案例_arraytodelimitedstring
- 8报错 Key is stored in legacy trusted.gpg keyring
- 9split函数python_奇技淫巧 - Python分割字符串的5个示例
- 10保险行业数据分析案例_保险业务数据分析案例
机器学习入门实战1:鸢尾花分类_查看目标变量“target”数值对应的意义(0代表了‘setosa’,1代表了‘versicolor
赞
踩

花名:鸢尾花
别名:爱丽丝、蓝蝴蝶、紫蝴蝶
花语:爱的使者、长久思念
花期:5-6月
颜色:蓝色、紫色、白色、粉色等
鸢尾花主要色彩为蓝紫色,有“蓝色妖姬”的美誉,因花瓣形如鸢鸟尾巴而得名,有蓝、紫、黄、白、红等颜色。鸢尾的英文名Iris,源于希腊语,是希腊神话中彩虹女神爱丽丝的名字。...
错了,这不是一篇植物科普,重来...
假如我们都非常热爱植物,收集到一些鸢尾花,每朵鸢尾花经过测量,得到一些数据:
花瓣长度和宽度,花萼长度和宽度,测量单位均为厘米。
同时,我们得到了一组被植物专家鉴定后的数据,这些花属于setosa、versicolor或virginica三个品种之一。我们想利用机器学习模型,通过已知品种的测量数据,预测鸢尾花的品种。
这里根据上次内容(机器学习machine learning-CSDN博客),可知我们掌握数据中有预期输出,属于监督学习问题。分析问题,我们要在多个选项中预测是否为某一种鸢尾花品种。可知,这是一个分类(classification)问题。鸢尾花的种类(预期输出)叫做类别(class)。测量数据来自的鸢尾花都属于三个类别之一。可推断这是一个三分类问题。单个数据点(一朵鸢尾花测量数据)的预期输出是这朵花的品种,品种又叫做标签(label)。
1. 数据采集
这些鸢尾花(Iris)数据集,其实是机器学习的经典数据集,包含在scikit-learn的datasets模块中(Python这些库为什么这么香是有原因的)。通过load_iris函数加载数据:
- from sklearn.datasets import load_iris
- iris_dataset = load_iris()
- #load_iris返回iris对象是一个Bunch对象,类似字典,包含键和值
- print("Keys of iris_dataset: \n{}".format(iris_dataset.keys()))
结果:
- Keys of iris_dataset:
- dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
数据包含在target和data字段中,data里是花萼长度、花萼宽度、花瓣长度、花瓣宽度等测量数据,格式为NumPy数组;target_names键对应的值是一个字符串数组,里面包含要预测的品种;DESCR键对应的值是数据集的简要说明。feature_names键对应的值是一个字符串列表,对每一个特征进行了说明。
print("Shape of data: {}".format(iris_dataset['data'].shape))
结果:
Shape of data: (150, 4)数组中包含150朵花的测量数据。在机器学习中,个体叫做样本(sample),其属性叫做特征(feature)。data数组的形状(shape)是样本数乘以特征数。取前10个样本特征数值:
print("First ten rows of data:\n{}".format(iris_dataset['data'][:10]))结果:
-
- First ten rows of data:
- [[5.1 3.5 1.4 0.2]
- [4.9 3. 1.4 0.2]
- [4.7 3.2 1.3 0.2]
- [4.6 3.1 1.5 0.2]
- [5. 3.6 1.4 0.2]
- [5.4 3.9 1.7 0.4]
- [4.6 3.4 1.4 0.3]
- [5. 3.4 1.5 0.2]
- [4.4 2.9 1.4 0.2]
- [4.9 3.1 1.5 0.1]]
前五朵宽度都是0.2cm,第六朵花萼最长5.4cm。target数组包含测量过的每朵花品种,是一个Numpy数组:
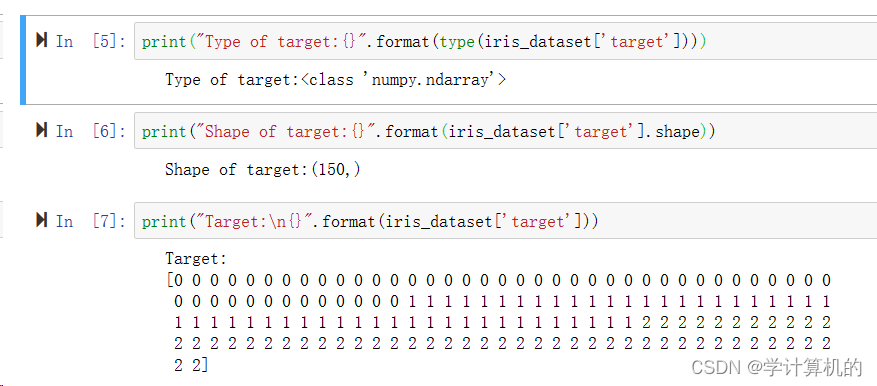
上述数字的代表含义由iris['target_names']数组给出:0代表setosa,1代表versicolor,2代表virginca。
2. 测试模型效果:训练数据&测试数据
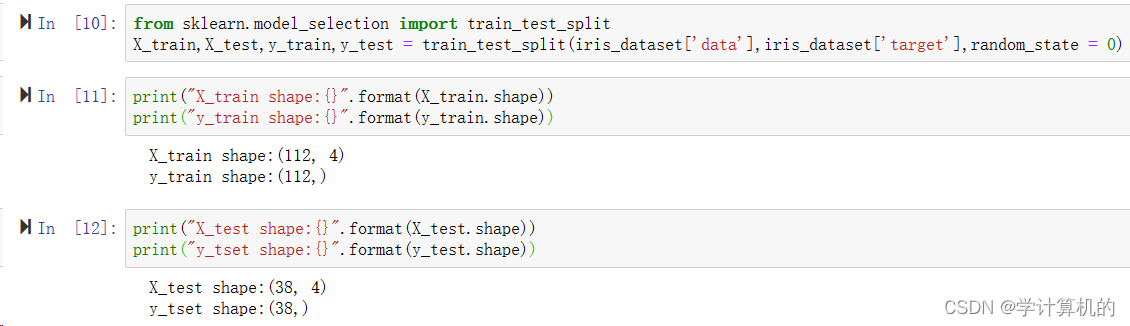
如何相信,我们利用数据构建的这个预测鸢尾花的机器学习模型,它是有效的。还用刚才的训练数据吗?当然不行,他们用于预测时已经是正确的标签了。也就是这些数据无法证明模型的有效性,即泛化(generalize)能力。所以需要用新的数据来评估模型的有效性。也就是没有在训练数据中出现过的。有一种常用的办法,将收集好的带标签的数据(即150朵花的测量数据)分为两组。一组数据用于构建机器学习模型,叫训练数据(training data)或训练集(training set),另一组用来评估模型性能,叫做测试数据(test data),或测试集(test set)。
用什么划分数据集?scikit-learn中的train_test_split函数可以将数据集分组。利用它将75%的数据作为训练集,余下的25%作为测试集。当然75%和25%还可以随意调节,但是这个比例通常效果较好。
scikit-learning中的数据通常用大写的X标识,而标签用小写的y标识,类似数学公式f(x)=y。train_test_split函数利用伪随机数生成器将数据集打乱,避免结果标签因过于集中预测不准。利用random_state参数指定随机生成数据。
3. 观察数据
检查数据,发现异常值和特殊值,比如单位不同,空值等等,有可能需要用数据清洗,使得数据更干净,或可直接使用。还可以将其可视化,绘制散点图(scatter plot)。有些数据特征要多于2个,有可能是3个或4个,无法使用二维图像表示,还可以使用散点图矩阵(pair plot)。绘制训练集中特征的散点图矩阵,方法如下:
需要使用mglearn模块,将Numpy数组转换成pandas DataFrame。用scatter_matrix绘制散点图函数绘制图形。
- #用X_train中的数据创建DataFrame
- #用iris_dataset.feature_names中的字符对数据列进行标记
- iris_dataframe = pd.DataFrame(X_train,columns=iris_dataset.feature_names)
- #利用DataFrame创建散点图矩阵,按y_train着色
- grr = pd.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker='o',hist_kwds={'bins':20},s=60,alpha=.8,cmap=mglearn.cm3)
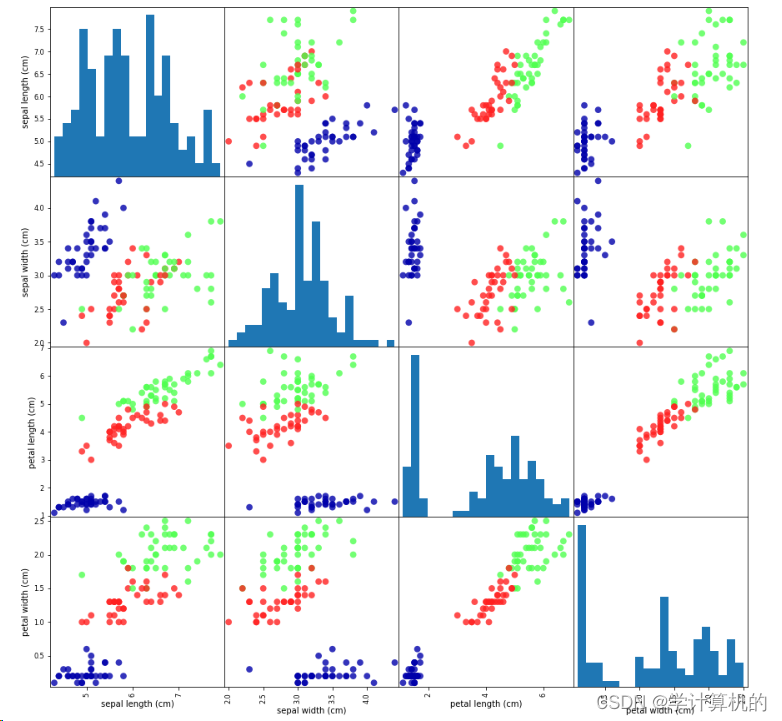
三个颜色三个类别,说明模型有效性。

