
- 1SqlServer各版本下载(2016-2019)_sql server 2019 standard (x64) - dvd 英文
- 2计算机程序设计c语言题,计算机程序设计(C语言)-中国大学mooc-题库零氪
- 32024推荐给开发者的15个AI工具_ai工具集
- 4Unity插件——AVPro Movie Capture 全景视频录制插件使用入门_avpromoviecapture
- 5mac提示“已损坏,无法打开。 您应该将它移到废纸篓“的终极解决方案_已损坏,无法打开,您应该将它移到废纸篓
- 6Flink部署
- 7就业季来临,旺盛的需求和劲头搞崩了BOSS直聘,那你如何选择才不崩溃?
- 8机器学习-KNN算法(鸢尾花分类实战)_鸢尾花knn算法
- 9谈谈Java语言的垃圾收集器_java技术提供了一个系统级的线程,即垃圾收集器线程,来跟踪每一块分配出去的内存空
- 10详解Spring Boot的RedisAutoConfiguration配置
探索大模型技术及其前沿应用——TextIn 文档解析技术
赞
踩
目前大模型训练和应用过程中面临训练 Token 耗尽、训练语料质量要求高、LLM 文档问答应用中文档解析不精准的问题。目前互联网能够提供的语料资源预计将在 2026 年耗尽,提升大模型应用效果需要更多更高质量的语料。同时文档类语料(chart-pdf 或 chart-excel 等)识别精度很差,严重影响模型应用效果。
而目前提高大模型训练效果最佳场景集中于书籍、论文等文档中,而它们往往都是 PDF 格式,甚至是图片扫描件。我们再训练时需要对这些文档进行文档格式识别、图表内容及标题提取、版面正确解析、阅读顺序处理的转换,同时要确保转换速度足够快。比如下面这个 gpt 阅读文档的例子:
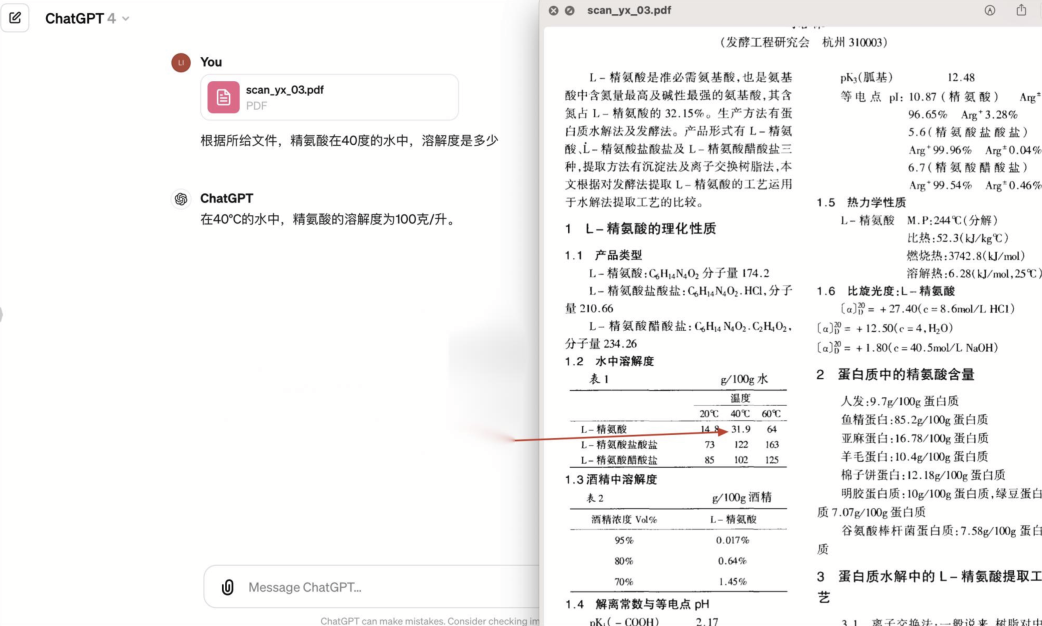
在这个例子中,由于文章包含一个非标准的列表,使得大模型没有识别到内容。
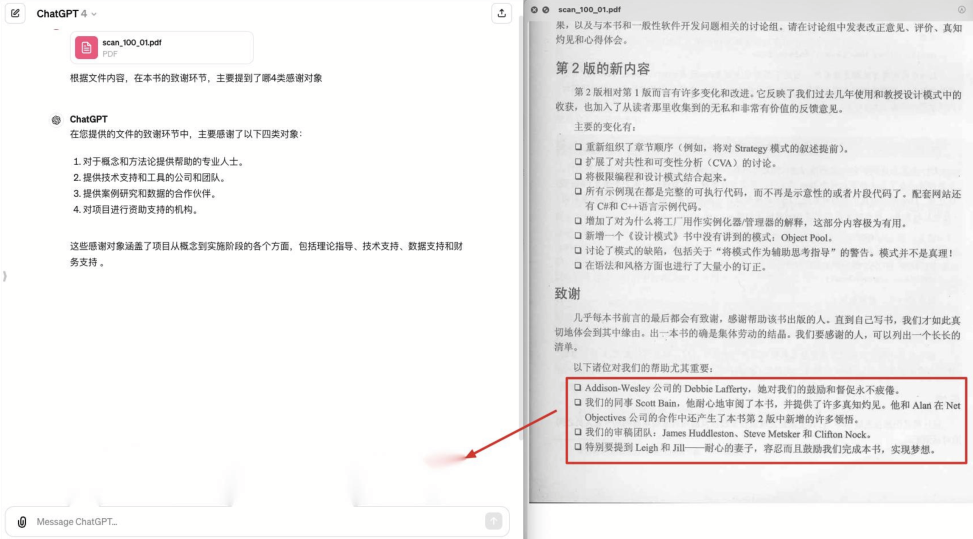
在这个例子中,由于文章包含一个非标准的列表,使得大模型没有识别到内容。
这个例子中,由于双栏排版使得大模型识别到了错误的内容。这些例子都说明目前迫切需要一个具备多文档元素识别、版面分析、高性能的文档解析技术,并将其应用在大模型的准备过程中。
技术难点
由于文档版式多样,模型很难有一个统一的处理方式。比如下面的一些例子:

在这个例子中,页眉的形式多种多样,没有统一的格式。
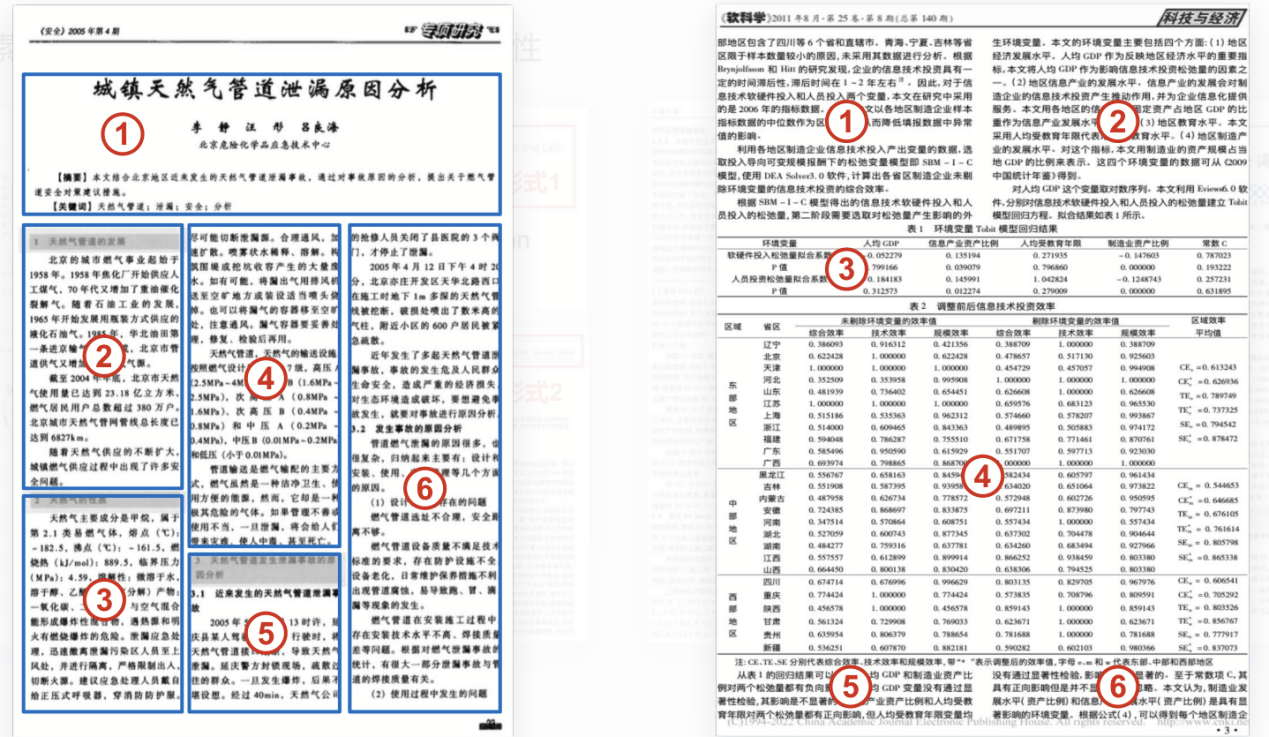
这个例子中表格和多栏排版混合为文档解析增加了困难。
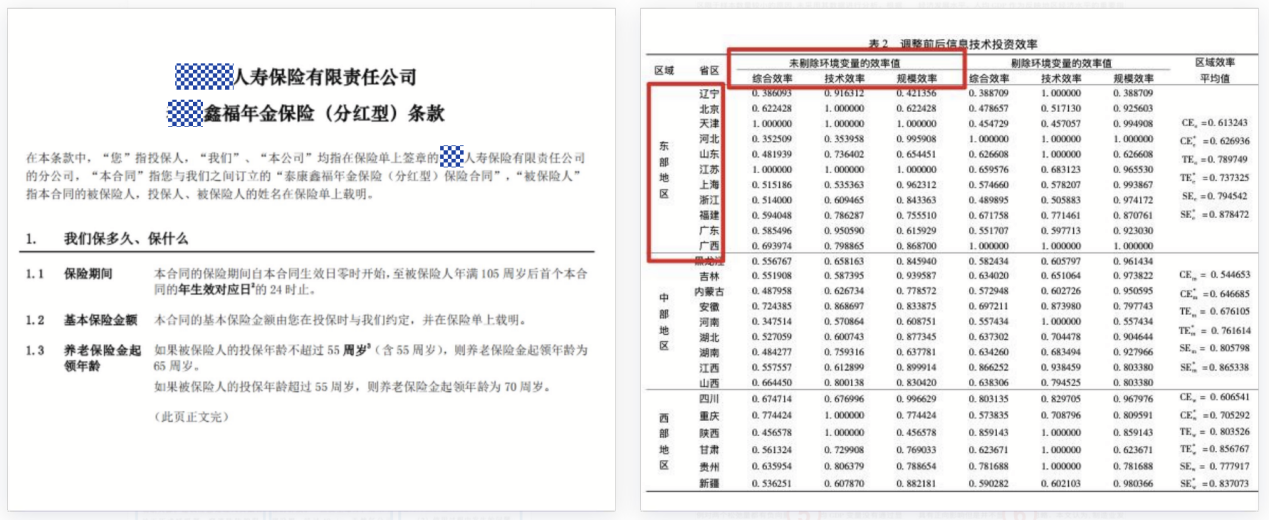
这个例子中无线表格和合并单元格会使得文字无法定位。

这个例子中,公式的出现阻碍了文字信息的识别和提取。
在这些例子里,我们观察到有元素遮盖、重叠,元素(页眉页脚等)有多样性;版式(双栏、跨页、三栏)造成的阅读顺序差异,多栏中插入表格的影响,无线表格以及单元格合并拆分带来的识别困难,单行公式、行内公式以及表格内公式的影响等等一些问题。
TextIn 文档解析技术
针对上面的问题,合合信息研发了 TextIn 文档解析技术,它专注于处理电子档、扫描件。在识别到文档类型后会提取其中的文字,之后基于合合信息多年的技术积累,对文档进行物理和逻辑版面分析。整个处理流程如下:
首先将各种类型的文档进行多页拆分,之后按照文档类型进行对应的预处理,然后提取文档数据,整合为通用文档文字信息。之后再对文档进行物理版面分析以及逻辑版面分析,将其与文字信息合并为一个通用文档层级信息。最后依据模型训练需求,将结果转换为指定的格式。
核心技术
TextIn 的核心技术选用了业界领先的模块,旨在实现高精度的文档解析效果。这些模块涵盖了文档图像预处理算法、版面分析算法框架以及逻辑版面分析算法,具体功能如下:
文档图像预处理算法包括区域提取、干扰去除、形变矫正、图像恢复和图像增强等模块。这些模块的主要任务是提升文字信息提取的准确性和效率。
区域提取可以识别并提取出文档中具有文字信息的区域,确保后续处理聚焦在有用的部分。
形变矫正通过分析形变文档的偏移场,将其矫正为正常的图像,并利用附近的像素点填充缺失部分,确保图像的完整性。
图像恢复和图像增强则进一步优化图像质量,使得文字信息更加清晰和易于识别。图像文档干扰去除算法使用 U2net 卷积提取出图像的背景,然后通过 cab 技术去除干扰,得到一个更高质量的图像。
版面分析算法框架分为物理版面分析和逻辑版面分析两个主要模块。物理版面分析侧重于视觉特征,识别文档中的各个元素,将相关性高的文字聚合到一个区域,这一过程主要关注文档的视觉布局和结构。逻辑版面分析则侧重于语义特征,聚焦于文档结构,其主要任务是通过语义建模将不同的文字块形成层次结构,例如通过树状结构展示文档的语义层次关系。检测模型选用了单阶段的检测模型,关注小规模数据和模型的调优,以提升识别精度
大模型在工作时,先定位目标页面,再寻找相关切片,从而提高运行速度和精度。逻辑版面分析算法通过预测每个段落与上一个段落的关系,将其分为子标题、子段落、合并、旁系、主标题、表格标题等类型。如果是旁系类型,则继续向上查找父节点,并判断其层级关系,直至找到最终的父节点。
通过这一系列技术,TextIn 在文档解析工作上展现了卓越的效果。
此外,在与生成式模型的配合应用上,TextIn 同样表现出色,进一步提升了文档解析和处理的整体性能。
技术解析
DocUNet 网络
DocUNet 模型可以捕获文档级 RE 的三元组之间的本地上下文信息和全局相互依赖性,将文档级 RE 表述为语义分割。具体来说,用一个编码器模块来捕获实体的上下文信息,并引用一个 U 形分割模块来捕获图像样式特征图上的三元组之间的全局相互依赖性。它的主要步骤是:首先通过一个编码器提取输入图像的特征,然后计算相关性并传入 U 形分割模块进行预测,最后通过损失函数调整结果,进行分类。
U2Net 网络
U2net 是一种用于图像分割的神经网络模型。它的网络结构为大型的 U-net 结构的每一个 block 里面也为 U-net 结构。其中 Block 总共分两种,一种是 Encoder1-4 以及 Decoder1-4,另一种是 Encoder5-6 和 Decoder5。
第一种 block 在 Encoder 阶段,每通过一个 block 后都会通过最大池化层下采样 2 倍,在 Decoder 阶段,通过每一个 block 前都会用双线性插值进行上采样。如下图,绿色代表卷积+BN+ReLU,蓝色代表下采样+卷积+BN+ReLU,紫色代表上采样+卷积+BN+ReLU,在 RSU-7 中下采样了 5 次,也即把输入特征图下采样了 32 倍,同样在 Decoder 阶段上采样了 32 倍还原为原始图像大小。
Transformer 模型
Transformer模型是近年大火的模型。它由多个编码器和解码器块堆叠构成,每个块包括两个子层:多头自注意力层和全连接前馈层。每个子层后增加了一个残差连接,并进行层归一化操作。
多头自注意力层包含若干自注意力层。自注意力层使用权重矩阵得到查询向量Q、键向量K和值向量V,带入公式即可得到输出,最终的输出即为前馈神经网络的输入。全连接前馈层包括一个两层的全连接网络和一个非线性激活函数。
残差连接与归一化层的引入可以解决梯度消失的问题。残差连接需要输入和输出的维度相同,此处将输出维度设置成 . 归一化将每一层神经元的输入都转成均值方差都一样的,可以加快收敛。
解码器相比编码器增加了一个多他自注意力层,并采用了掩码操作,目的是防止Q去对序列中尚未解码的位置施加操作。解码器输出结果经过线性连接后,由一个Softmax层计算预测值。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

