
- 12023!七大最佳Python书籍,入门到精通推荐!_python官方推荐的三本书
- 2Python程序设计与算法基础教程·第八章上机实践_python第八章实战
- 3设计模式简单整理_具有客户端所需简化单个类的设计模式,并调用委托给这些方法处理请求
- 4按键精灵脚本学习-关于天猫抢红包_安卓按键精灵自动抢红包脚本
- 5frp客户端连接出现报错:login to server failed: dial tcp x.x.x.x:7000: i/o timeout_login to the server failed: session shutdown. with
- 6Flink(六)—— Data Source 介绍_flink xadatasource
- 7Android编程:底部弹出的对话框_android studio 底部半屏对话框
- 8MIT6.1810/Fall 2022(which was called 6.S081 then) Lab8-10_mit6.1810 2022
- 9仿牛客论坛项目全面大总结_牛客项目亮点
- 10豆瓣评分预测(如何用自己的数据集进行文本分类)——基于pytorch的 BERT中文文本分类,超详细教程必会(1)_中文文本分类数据
基于Python的社交媒体评论数据挖掘,使用LDA主题分析、文本聚类算法、情感分析实现_python lda主题分析
赞
踩
思路步骤:
数据清洗:
使用pandas读取数据文件,并进行数据清洗和预处理,包括去除重复值、正则清洗和分词。
主要关注点分析:
计算词频并生成词云图,统计文本中词语的出现频率,并使用WordCloud库生成词云图展示结果。
主题分析:
进行一致性和困惑度计算,通过改变主题数量范围,计算不同主题数量下的一致性和困惑度,并绘制折线图展示结果。
使用TF-IDF模型提取文本的关键词,计算每个关键词在文本中的权重,并输出前30个关键词。
进行先验分布的计算,将文本转换为词袋形式,并使用gensim库计算单词的先验分布。
进行主题建模和关键词提取,使用LDA模型对分词结果进行主题建模,并提取每个主题的关键词。
对主题建模结果进行可视化,使用pyLDAvis库生成LDA主题模型的可视化结果,并保存为HTML文件。根据LDA模型计算主题之间的相关性和关键词之间的权重。
数据处理实现:
数据处理的过程如下:
数据清洗主要包括去重和正则清洗两个步骤。
首先,通过使用drop_duplicates函数对原始数据进行去重操作。在代码中,根据内容这一列进行去重,并将去重后的结果重新赋值给新的DataFrame。这样可以确保每条内容的唯一性,避免出现重复的数据。
接下来,进行正则清洗的步骤。正则清洗主要是针对内容,去除除了中英文字符和数字以外的其他字符。具体实现通过使用正则表达式的方式,调用re.sub函数进行替换。在代码中,使用正则表达式[^\u4e00-\u9fa5^a-z^A-Z^0-9^,.,。!:]|,将博文全文中除了中英文字符、数字和部分标点符号(逗号、句号、感叹号、冒号)以外的字符都替换为空格,从而实现清洗效果。
清洗后的结果保存为新的DataFrame,并将其写入Excel文件。通过这样的数据清洗过程,可以确保数据的准确性和一致性,使得后续的数据分析和处理更加可靠和有效。
数据清洗是数据分析的前提和基础,通过去重和正则清洗等步骤,可以对原始数据进行初步的处理和整理,为后续的数据分析和挖掘提供高质量、准确的数据基础。清洗后的数据具有更好的可用性和可靠性,能够提供更准确、可靠的结果和结论,从而支持决策和解决实际问题的需求。

主要关注点分析(词频分析):
实现主要关注点的词频分析可以按照以下步骤进行:
读取经过数据清洗的微博博文数据。
使用jieba库对每条内容进行分词处理,得到分词后的结果。
创建一个空的列表或字典用于存储词频统计结果。
遍历分词结果列表,对每个词语进行词频统计,将词语及其出现次数添加到词频统计结果中。
对词频统计结果进行排序,可以按照词频降序排列。
根据需求选择关注的主题,筛选出与该主题相关的词语。
可以根据需要设定阈值,过滤掉低频词语,只保留出现频率较高的词语。
将词频统计结果进行可视化展示,可以使用柱状图、词云图等方式进行展示。
分析词频统计结果,根据高频词语来了解内容的关键关注点和问题。
通过词频分析,可以了解内容的关注度和热度,找出内容被用最多的关键词,从而揭示出内容的主要关注点和议题。结果如下:
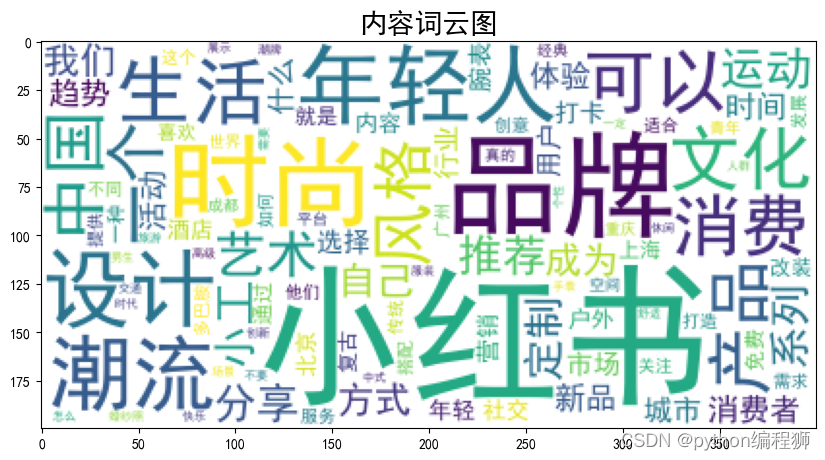
根据词频分析结果,可以看出项目涉及的关键词主要集中在与小红书、品牌、时尚、设计、生活、消费等相关的领域。这些关键词反映了项目所涉及的主题和内容,可以帮助了解用户关注的热点话题和行业趋势。通过词频分析,可以更好地了解用户需求和兴趣,为产品推荐、内容创作、营销策略等提供参考。在数据处理和挖掘的基础上,可以进一步分析关键词之间的关联性,发现潜在的关键词组合规律,为项目的发展和优化提供有益的指导和决策依据。
Lda主题分析
LDA主题分析的实现过程如下:
准备好经过数据清洗和预处理的文本数据。
使用gensim库构建语料库和词袋模型,将文本数据转换为可用于LDA模型的格式。
设置LDA模型的参数,包括主题数量、迭代次数、词频阈值等。
使用LDA模型训练语料库,并得到主题-词语分布和文档-主题分布。
根据需求,选择合适的方法获取每个主题的关键词,可以是按照权重排序或者设定阈值筛选。
可以使用pyLDAvis库对LDA模型进行可视化,生成交互式的主题模型可视化图表,并保存为HTML文件。
分析LDA主题分析结果,根据关键词和文档-主题分布了解每个主题的含义和特点,理解文本数据中不同主题的分布情况。
可以进一步对文本数据进行主题分析,根据文档-主题分布确定每个文档最可能的主题,并将主题信息添加到原始数据中。
通过LDA主题分析,可以发现文本数据中的主题结构和主要内容。主题分析可以帮助我们了解文本数据的内在关联性和分布情况,从而更好地理解文本数据的内容和意义。此外,LDA主题分析还可以用于文本分类、信息检索和推荐系统等领域,提供有关文本数据的深入洞察和应用价值。结果如下:

由一致性和困惑度分析曲线图可知,最优主题数8效果最好。
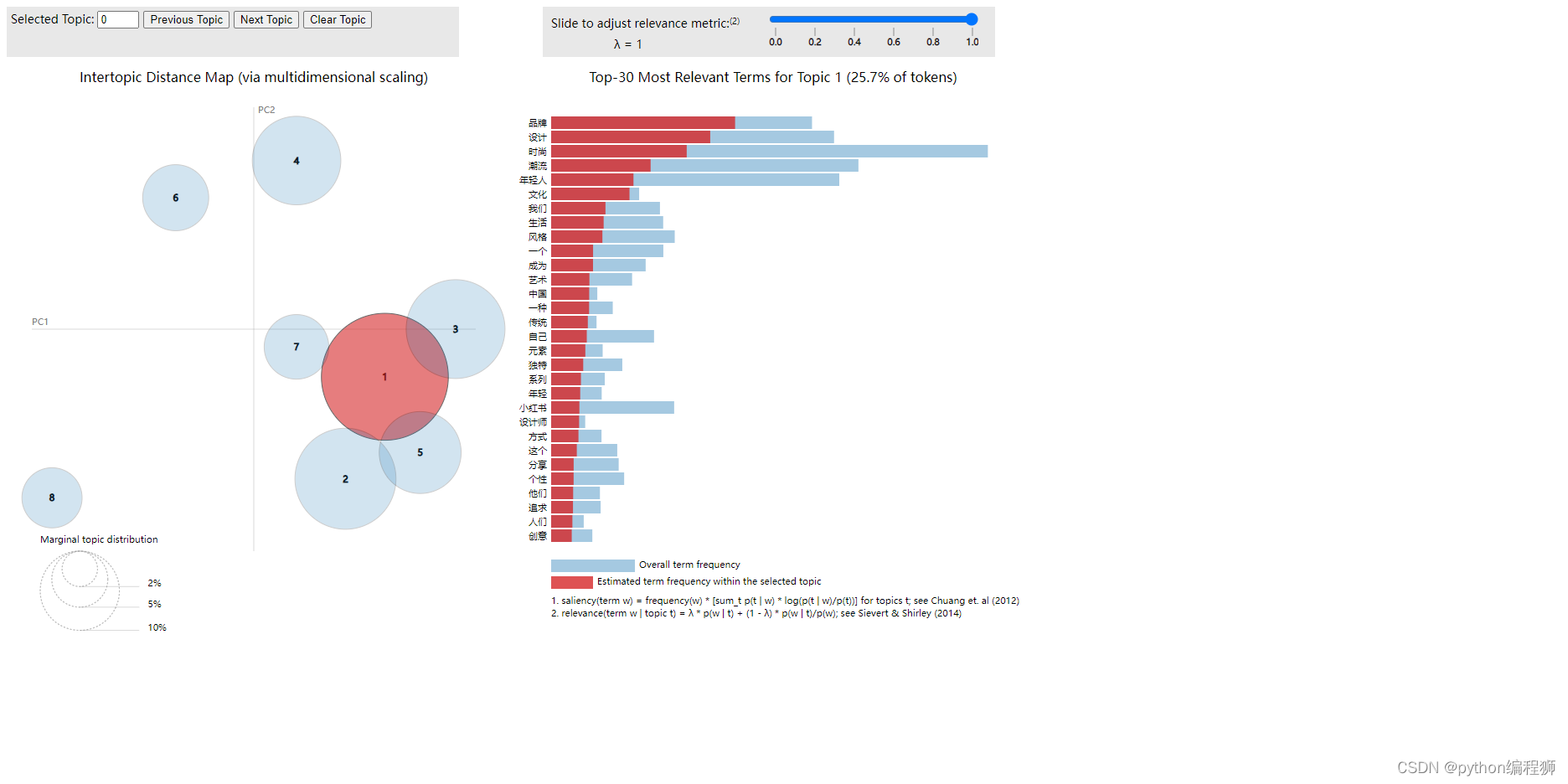
主题分析结果,可以看出各主题下的关键词权重反映了不同主题的核心内容和关注点。例如,主题1涉及用户需求、消费行为、市场营销等方面,主题2涵盖品牌、设计、时尚、文化等内容,主题3关注婚礼、酒店、时尚潮流等话题,而主题8则以话题、潮流活动、年轻人、时尚为主要关键词。通过主题分析,可以更好地了解不同主题下的关键词分布及权重,帮助识别用户需求、行业趋势和内容热点,为项目的内容策划、营销推广等提供重要参考,有助于精准定位目标受众和内容方向,提升用户体验和内容吸引力。
聚类分析:
聚类分析是一种常用的数据挖掘技术,旨在将数据集中的样本划分为具有相似特征的群组,以便发现数据中的潜在模式和结构。在给定文本数据集中,聚类分析可以帮助识别文本之间的相似性,从而将文本聚合成不同的类别或簇。在上述Python代码中,首先对文本数据进行了预处理,包括分词、去除特殊字符和停用词等操作,然后构建了文本特征矩阵,使用TF-IDF方法表示文本特征。接着通过KMeans算法对文本数据进行聚类,根据不同的K值寻找最优的聚类数量,然后获取每个聚类的关键特征和所属文本样本。最后通过降维和可视化技术,将聚类结果展示在二维空间中,以便更直观地观察不同聚类之间的关系和文本分布情况。通过聚类分析,可以帮助用户理解文本数据的结构和相似性,发现潜在的文本主题和群组,为进一步的文本分类、信息检索和内容推荐提供有益的参考。
聚类分析结果

根据给定的聚类结果和代码实现,可以看出数据集中的文本样本被划分为了四个不同的聚类。在聚类1中,出现了"冰西"、"龚俊"、"工现"、"州王"、"工丰"等关键词,这些关键词可能代表了某种主题或话题;而在聚类2、3、4中,也分别出现了不同的关键词组合,反映了不同的文本特征和聚类结构。通过观察不同聚类中的关键词,可以推测不同聚类之间的主题或内容差异,有助于理解文本数据的潜在结构和特征。聚类分析可以帮助用户更好地理解文本数据之间的相似性和差异性,发现隐藏在数据背后的模式和规律,为进一步的文本分类、主题提取和内容推荐提供参考和指导。
情感分析实现与结果可视化
情感分析是一种通过自然语言处理技术来识别文本中的情感倾向的方法。在给定的代码中,首先使用 SnowNLP 库对微博内容进行情感分析,将情感分数划分为积极、中性和消极三种情感类别。然后,通过对各类别的微博数量进行统计,生成了情感分析占比的可视化图表。通过遍历微博内容并使用 SnowNLP 库进行情感分析,将分数划分为不同的情感类别,并将结果存储在新的列表中。随后,利用 Pandas 的 groupby 方法对情感分析结果进行分组统计,得到各情感类别下微博数量的统计结果。最后,利用 Matplotlib 库绘制了饼图,展示了不同情感类别在微博内容中的占比情况。
通过这一系列操作,实现了对微博内容进行情感分析并可视化呈现不同情感类别的占比情况,为进一步分析用户情感倾向提供了重要参考。这样的分析和可视化有助于了解用户对特定话题或事件的情感态度,为舆情监控和情感分析提供了有益的信息支持。


