
- 1【机器学习】利用机器学习优化陆军战术决策与战场态势感知_机器学习算法应用 战斗力分析
- 2程序员必背单词!!!_current和common
- 3springcloud的组件及原理_springcloud组件
- 4CVPR 2023 | 浙大提出全归一化流模型PyramidFlow:高分辨率缺陷异常定位新范式
- 5昇思25天学习打卡营第9天|Shufflenet图像分类
- 6(毕设)SSM+redis+shiro_(三)
- 7【Windows取证篇】Window日志分析基础知识(一)_windows系统日志
- 8「分享」最全AI合集 全是好玩意!
- 9群晖7.2 安装了mariadb,如何开启外网访问权限
- 10vue ui命令打开页面是空白的!_comfyui打开白屏
机器学习(三)
赞
踩
4.回归和聚类算法
4.1 线性回归
4.1.1 线性回归的原理
-
线性回归应用场景
- 房价预测
- 销售额度预测
- 贷款额度预测
-
什么是线性回归
-
定义与公式
-
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
-
特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归。
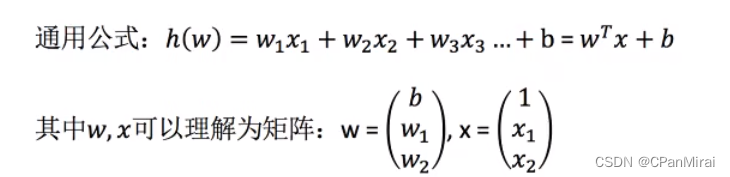
-
-
-
线性回归当中线性模型有两种,一种是线性关系,另一种是非线性关系。
-
线性关系
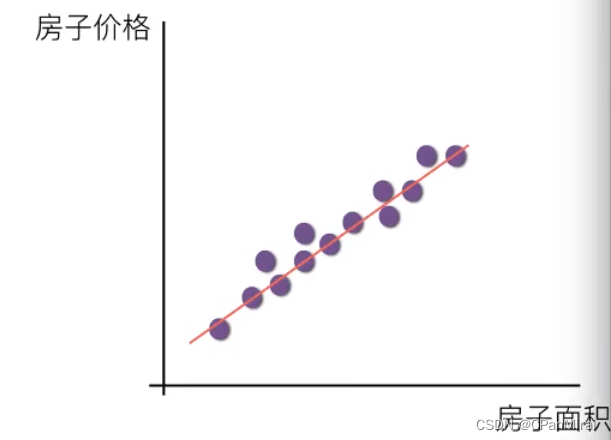
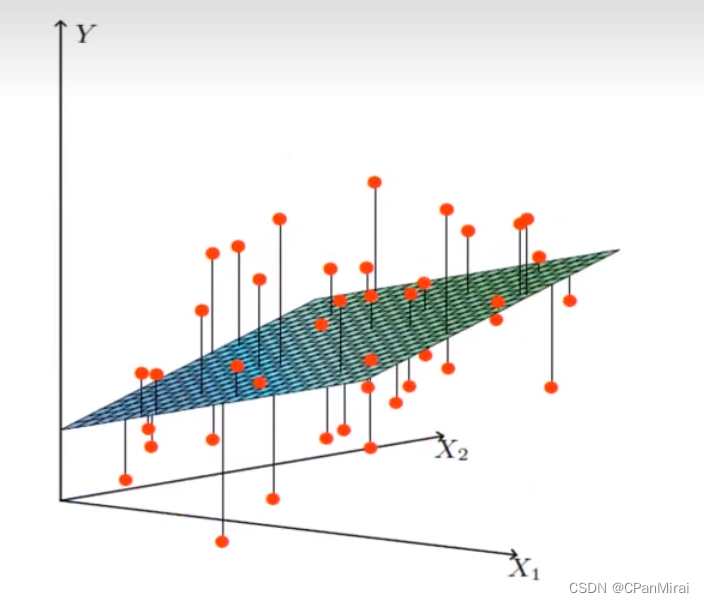
注:单特征与目标值的关系呈现直线关系,两个特征与目标值呈现平面的关系。
-
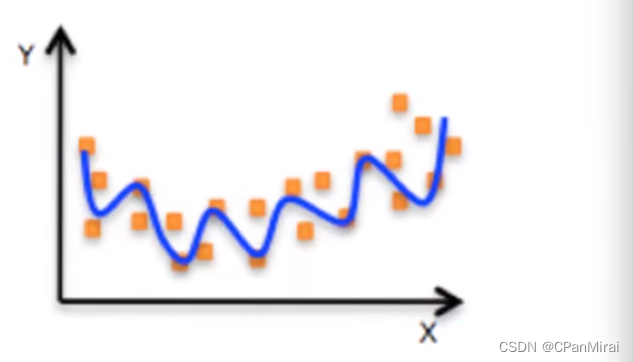
非线性关系(可以理解为 W1*X1 + W2X22+W3*X33+b)
-
-
4.1.2 线性回归的损失和优化原理
真实的线性关系和我们预测的线性关系存在一定误差,那么存在,我们需要把这个误差进行衡量出来(使用损失函数),我们想办法去减少误差,去修正(优化损失),不断地去逼近真实的线性关系,从而预测的结果更加准确。
-
损失函数(最小二乘法):

-
优化损失
如何去求模型当中的W,使得损失最小?(目的是找到最小损失对应的W值)
线性回归中经常用两种优化算法:
-
正规方程(直接求解得到W,使用高数里面求最小值的方法,进行求导)

-
梯度下降(不断试错,最终找到合适的)
-
4.2 欠拟合与过拟合
4.2.1 定义
欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模拟过于简单)
过拟合:一个假设在训练数据上能够很好的拟合,但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
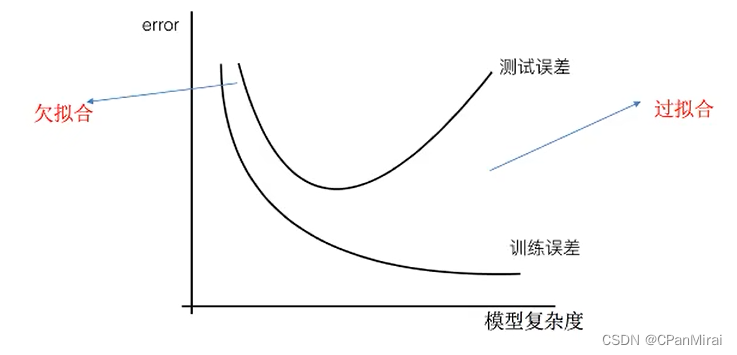
4.2.2 原因以及解决方法
- 欠拟合原因以及解决方法
- 原因:学习到数据的特征过少
- 解决方法:增加数据的特征数量
- 过拟合原因以及解决办法
- 原因:原始特征过多,存在一些嘈杂特征,模型过于复杂,因为模型尝试去兼顾各个测试数据点。
- 解决方法:正则化

如何解决 ?

4.2.3 正则化
-
L2 正则化
-
作用:可以使得其中一些W的都很小,都接近于0,削弱某个特征的影响。
-
优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
-
加入L2正则化后的损失函数(Ridge回归):

-
-
L1正则化
- 作用:可以使得其中一些W的值直接为0,删除这个特征的影响。
- LASSO回归
4.3 线性回归改进-岭回归
4.3.1 带L2正则化的线性回归-岭回归
岭回归,其实也是一种线性回归。只不过在算法建立回归方程时候,加上正则化的限制,从而达到解决过拟合的效果。
4.3.2 API
# 具有L2正则化的线性回归
sklearn.linear_model.Ridge(alpha = 1.0,fit_intercept = True,solver = 'auto',normalize = False)
# alpha : 正则化力度(惩罚项系数),也叫 λ
# solver : 会根据数据自动选择优化方法 如果数据集、特征都比较大,选择该随机梯度下降优化
# normalize : 数据是否进行标准化
# normalize = False : 可以在fit之间调用preprocessing.StandardScaler标准化数据
# Ridge.coef_ : 回归权重
# Ridge.intercept_ : 回归偏置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Ridge方法相当于SGDRegressor(penalty = ‘L2’, loss = ‘squared_loss’),只不过SGDRegressor实现了一个普通的随机梯度下降学习,推荐使用Ridge(实现了SAG)
从右往左,正则化程度越来越大,weights也就是惩罚项值接近于0.
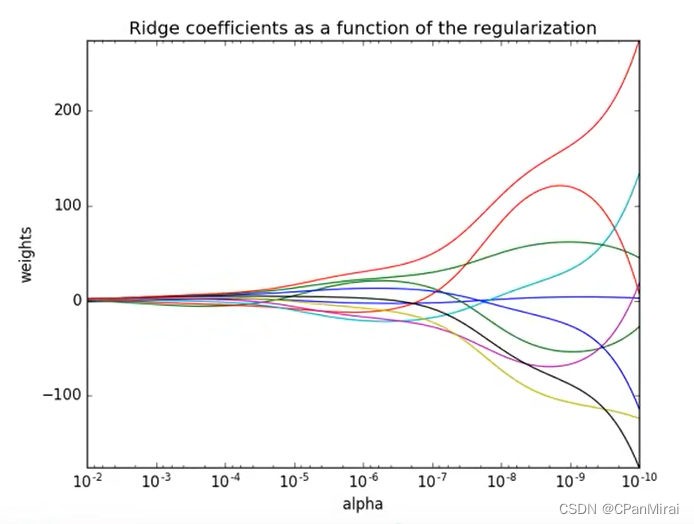
4.4 分类算法-逻辑回归与二分类
4.4.1 定义
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广泛。
4.4.2 逻辑回归的应用场景
- 广告点击率
- 是否为垃圾邮件
- 是否患病
- 金融诈骗
- 虚假账号
4.4.3 逻辑回归的原理
-
输入(是线性回归的结果)
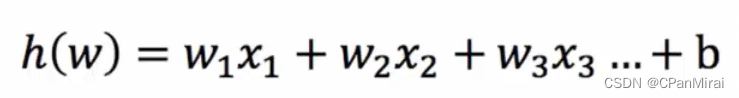
-
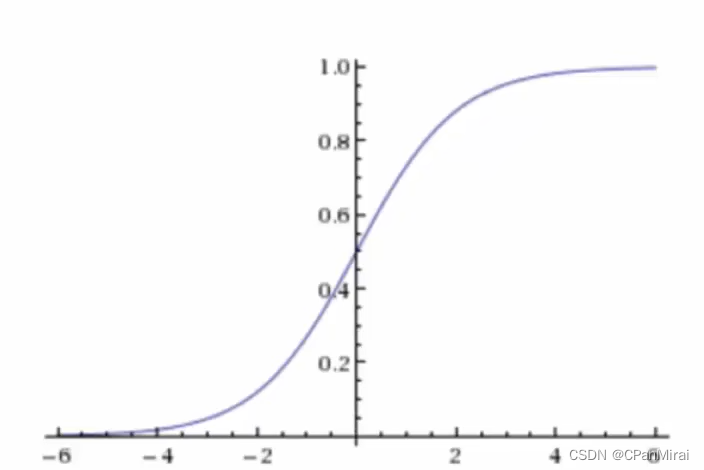
激活函数
-
sigmoid函数
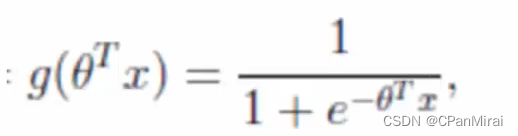
-
分析
- 回归的结果输入到sigmoid函数中去
- 输出结果:[0,1]区间中的一个概率值,默认为0.5为阈值
-
逻辑回归最终的分 类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外一个类别标记为0(反例)
-
损失以及优化
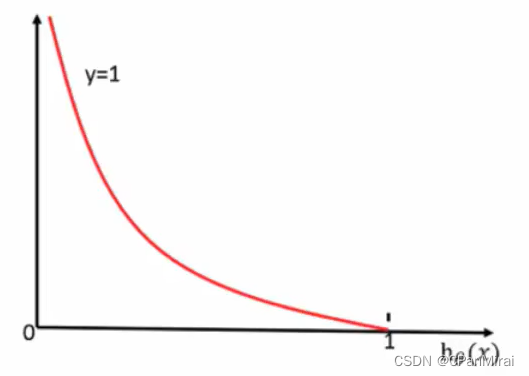
逻辑回归的损失,称之为对数似然损失,公式如下:
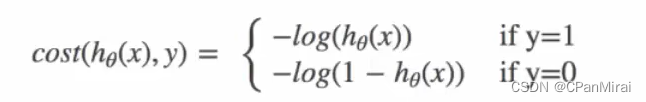
当 y = 1时:
当 y = 0时:
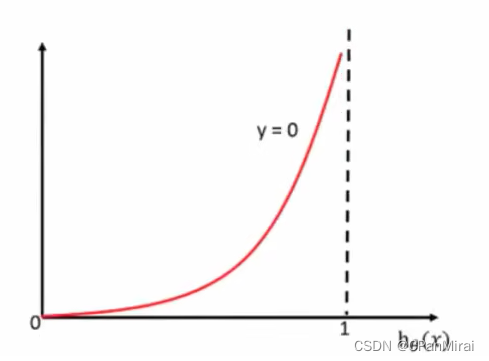
其中h(x)是预测值,y是真实值,坐标纵轴是损失值。h(x) = y 时无损失,否则损失趋于无穷。
-
综合完整损失函数
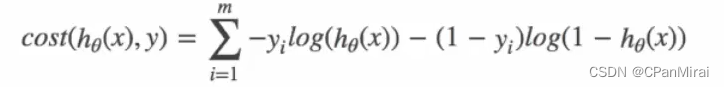
优化:同样使用梯度下降优化算法,去减少损失函数的值,这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。
4.4.4 逻辑回归API
sklearn.linear_model.LogisticRegression(solver = 'liblinear',penalty = 'l2',C = 1.0)
# solver : 优化求解方式(默认开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数)
# penalty : 正则化的种类
# C:正则化力度
- 1
- 2
- 3
- 4
LogisticRegression方法相当于SGDClassifier(loss = ‘log’,penalty=’ '),GDClassifier实现了一个普通的随机梯度下降学习,也支持平均随机梯度下降法(ASGD),可以通过设置average=True。而使用LogisticRegression(实现了SAG)。
4.4.5模型评估
-
精确率和召回率
-
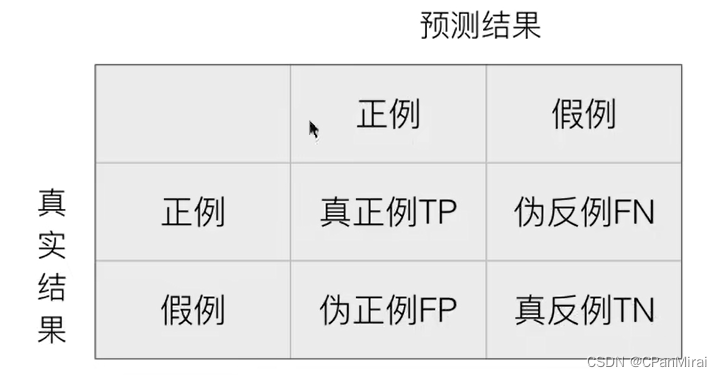
混淆矩阵
-
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)。
-
-
精确率和召回率
-
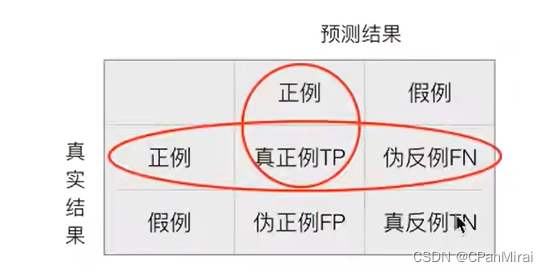
精确率:预测值为正例样本中真实为正例的比例。

-
召回率:真实为正例的样本中预测结果为正例的比例。
-
-
-
分类评估报告API
sklearn.metrics.classification_report(y_true,y_pred,labels=[],target_names=None) # y_true:真实值 # y_pred:估计器预测目标值 # labels:指定类别对应的数字 # target_names:目标类别名称 # return:每个类别精确率与召回率- 1
- 2
- 3
- 4
- 5
- 6
-
ROC曲线与AUC指标(在样本不均衡下评估)
-
TPR(召回率)与FPR
- TPR = TP/(TP+FN) 所有真实类别为1的样本中,预测类别为1的比例。
- FPR = FP/(FP+TN) 所有真实类别为0的样本中,预测类别为1的比例。
-
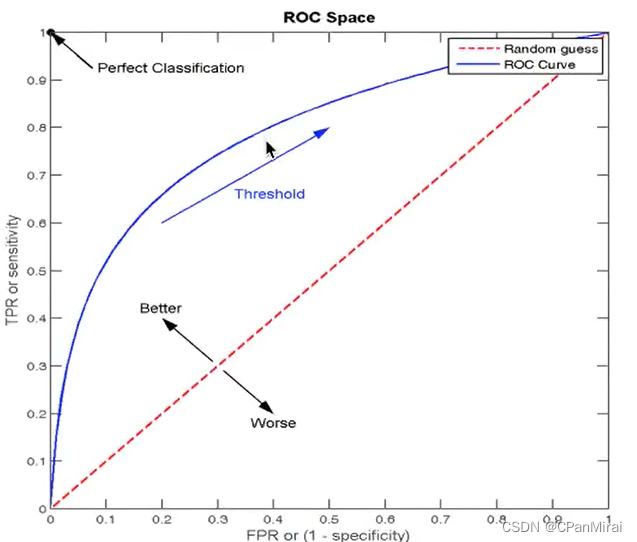
ROC曲线
-
ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5
-
-
AUC指标
- AUC的概率意义是随机取一对正负样本,正样本得分大于负样本的概率。
- AUC的最小值为0.5,最大值为1,取值越高越好。
- AUC=1,完美分类器,采用这个预测模型时,不管设定什么值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定值的话,能有预测
价值。
注:最终AUC的范围在[0.5,1]之间,并且越接近1越好。
-
AUC计算API
-
总结
- AUC只能用来评价二分类
- AUC非常适合样本不平衡中的分类器性能
from sklearn.metrics import roc_auc_score sklearn.metrics.roc auc_score(y_true,y_score) # 计算ROC曲线面积,即AUC值 # "y_true:每个样本的真实类别,必须为0(反例),1(正例)标记 # "y_score:预测得分,可以是正类的估计概率、置信值或者分类器方法的返回值- 1
- 2
- 3
- 4
- 5
-
4.5 模型保存和加载
4.5.1 sklearn模型的保存和加载API
import joblib
# 保存:joblib.dump(rf,'test.pkl')
# 加载:estimator = joblib.load('test.pkl')
- 1
- 2
- 3
4.6 无监督学习 K-means算法
4.6.1 无监督学习包含算法
- 聚类
- K-means(k均值聚类)
- 降维
- PCA
4.6.2 K-means原理
-
效果图
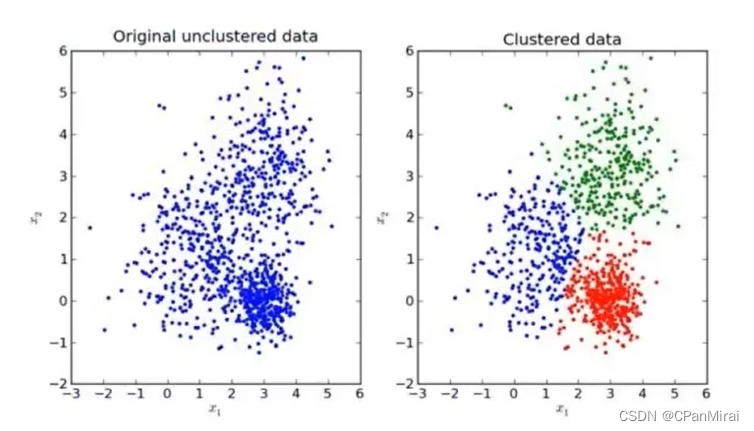
-
K-means聚类步骤
- 随机设置K个特征空间内的点作为初始的聚类中心
- 对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
-
K-means API
sklearn.cluster.KMeans(n_clusters = 8,init = 'k-means++') # n_clusters:开始聚类中心的数量 # init:初始化方法,默认为'K-means++' # labels_:默认标记的类型,可以和真实值进行比较- 1
- 2
- 3
- 4
-
Kmeans性能评估
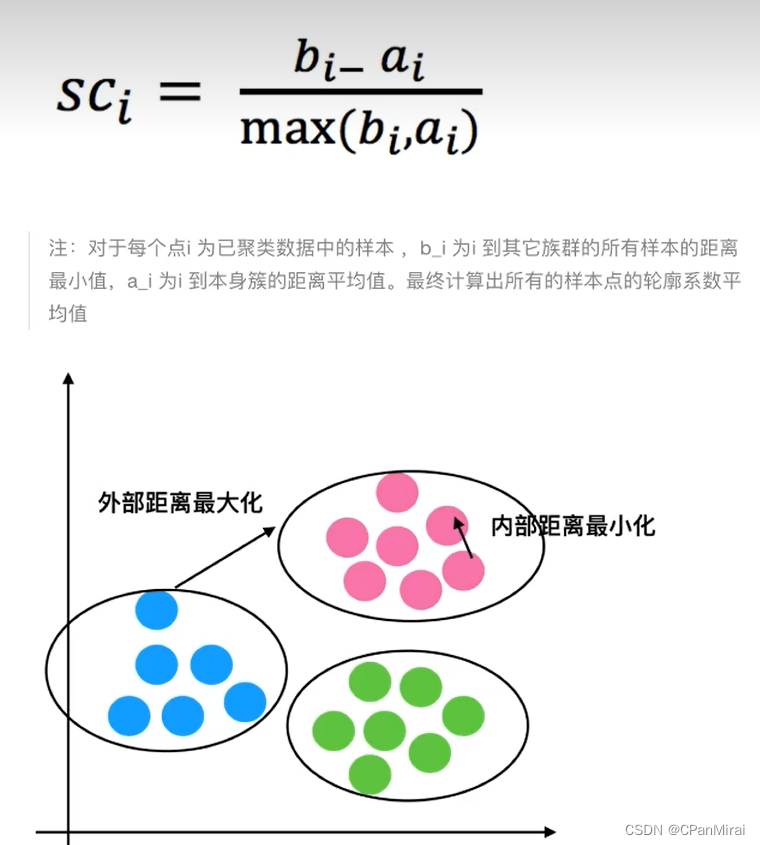
结论:如果b_i >> a_i趋近于1效果越好,b_i << a_i 趋近于 -1,效果不好。轮廓系数的值是介于[-1,1],越接近于1代表内聚度和分离度都相对较优。
-
轮廓系数API
sklearn.metrics.silhouette_score(X,labels) # 计算所有样本的平均值轮廓系数 # x : 特征值 # labels : 被聚类标记的目标值- 1
- 2
- 3
-
K-means总结
- 特点:采用迭代式算法,直观易懂并且实用
- 缺点:容易收敛到局部最优解(可以用多次聚类解决)

