
- 1华为OD机试C卷-- 分月饼(Java & JS & Python & C)
- 2使用Docker Compose运行Elasticsearch
- 3pytest的快速使用_norecursedirs什么意思
- 4怎么写测试用例?_测试用例怎么写
- 5MySQL笔记: 16. 多版本并发控制_mysql 多版本并发控制
- 6Windows 使用Winmm库捕获麦克风音频数据(源码)_windows c winmm.lib 采集pcm
- 7数据库设计最佳实践:规范化与反规范化在MySQL中的应用
- 8链表经典题目:环形链表问题(LeetCode141.环形链表、LeetCode142.环形链表Ⅱ)
- 9ICLR2022录用的Transformer相关论文合集_transformer 2022论文
- 10在物联网设备安全中,如何有效进行固件更新管理?
一文详解几种常见本地大模型个人知识库工具部署、微调及对比选型(文末福利)_大模型知识库
赞
踩
近年来,大模型在AI领域崭露头角,成为技术创新的重要驱动力。从AlphaGo的胜利到GPT系列的推出,大模型展现出了强大的语言生成、理解和多任务处理能力,预示着智能化转型的新阶段。然而,要将大模型的潜力转化为实际生产力,需要克服理论到实践的鸿沟,实现从实验室到现实世界的落地应用。阿里云去年在云栖大会上发布了一系列基于通义大模型的创新应用,标志着大模型技术开始走向大规模商业化和产业化。这些应用展示了大模型在交通、电力、金融、政务、教育等多个行业的广阔应用前景,并揭示了构建具有行业特色的“行业大模型”这一趋势,大模型知识库概念随之诞生。
写在开头的话
这几年,各种新技术、新产品层出不穷,其中,大模型(Large Language Models) 作为AI领域的颠覆性创新,凭借其在语言生成、理解及多任务适应上的卓越表现,迅速点燃了科技界的热情。从阿尔法狗的胜利到GPT系列的横空出世,大模型不仅展现了人工智能前所未有的创造力与洞察力,也预示着智能化转型的新纪元。然而,大模型的潜力要真正转化为生产力,实现从实验室到现实世界的平稳着陆,还需跨越理论到实践的鸿沟。
自去年云栖大会上,阿里云发布了一系列基于通义大模型的创新应用,标志着大模型技术开始迈向大规模商业化和产业化的关键一步。这一系列动作不仅展示了大模型在交通、电力、金融、政务、教育等多个行业的广泛应用前景,也揭示了一个重要趋势:大模型的落地应用需要与行业知识深度整合,形成具有领域特色的“行业大模型” 。

而在这一过程中,一个概念应运而生——大模型知识库。这一概念的核心在于,它不仅仅是对现有企业私有知识库的技术性升级,更是一种革命性的知识管理与利用方式。大模型知识库旨在通过融合最新的大模型技术,对企业的海量内部数据、专业知识、最佳实践等进行高效组织、智能索引和深度学习,使之成为可被模型理解和运用的结构化知识资源。
这样的知识库不仅能够实现对企业内部知识的快速检索和精准匹配,还能够借助大模型的语境理解和生成能力,自动总结文档、生成报告、解答复杂问题,甚至在特定领域内进行创新性思考和策略建议。换句话说,大模型知识库可以成为企业智慧的“超级大脑”,极大提升知识的流动性和价值转化效率,让企业的每一份知识资产都成为推动业务发展和创新的源泉。
同理,既然企业可以用大模型知识库来管理企业级的知识,那么个人同样也可以构建起个人版的“智慧大脑” 。想象一下,将个人的学习笔记、工作经验、技能树、甚至是兴趣爱好等各类信息,全部整合进这样一个智能化的知识管理体系中。这不仅是一个简单的信息存储仓库,而是一个能够自我学习、自我优化,并根据个人需求动态调整的知识生态系统。
所以,这篇文章,我们就来好好聊一下最近一段时间常见的本地大模型个人知识库工具。至于为什么聊这个话题呢?有两个原因。
一是因为之前其实已经有过相关涉猎了,如之前有尝试过基于Ollama+AnythingLLM轻松打造本地大模型知识库,这篇文章放在整个互联网上同类型里面也算是比较早发表的,可惜事后尝试总觉得效果不如人意,缺乏自定义能力,因此想多研究几个开源工具,进行对比选型,找出更符合自己要求的。
二是因为最近同事也拜托我给她的新电脑搭建了一套本地大模型知识库环境,这次采用的是MaxKB来实现的,由于是纯windows环境部署,一路上也是遇到了不少坑,这里也正好想复盘一下。
常见本地大模型知识库工具
这里还是先盘点一下最近比较火爆的几个工具吧,下面分为知识库侧和大模型侧两个方面来说。
知识库侧
知识库侧主要是指更加偏向于能够直接读取文档并处理大量信息资源,包括文档上传、自动抓取在线文档,然后进行文本的自动分割、向量化处理,以及实现本地检索增强生成(RAG)等功能的工具,近期较为热门的主要包括:AnythingLLM、MaxKB、RAGFlow、FastGPT、Dify 、 Open WebUI 这六种。
AnythingLLM
这个也就是我之前使用过但是觉得效果不太理想的那位,稍微简单的介绍一下吧。
AnythingLLM 是 Mintplex Labs Inc. 开发的一款可以与任何内容聊天的私人 ChatGPT,是高效、可定制、开源的企业级文档聊天机器人解决方案。它能够将任何文档、资源或内容片段转化为大语言模型(LLM)在聊天中可以利用的相关上下文。
其采用MIT许可证的开源框架,支持快速在本地部署基于检索增强生成(RAG)的大模型应用。在不调用外部接口、不发送本地数据的情况下,确保用户数据的安全。点此下载
最近 AnythingLLM推出了桌面应用,可以在自己的笔记本电脑上下载使用,目前支持的操作系统包括MacOS,Windows和Linux。
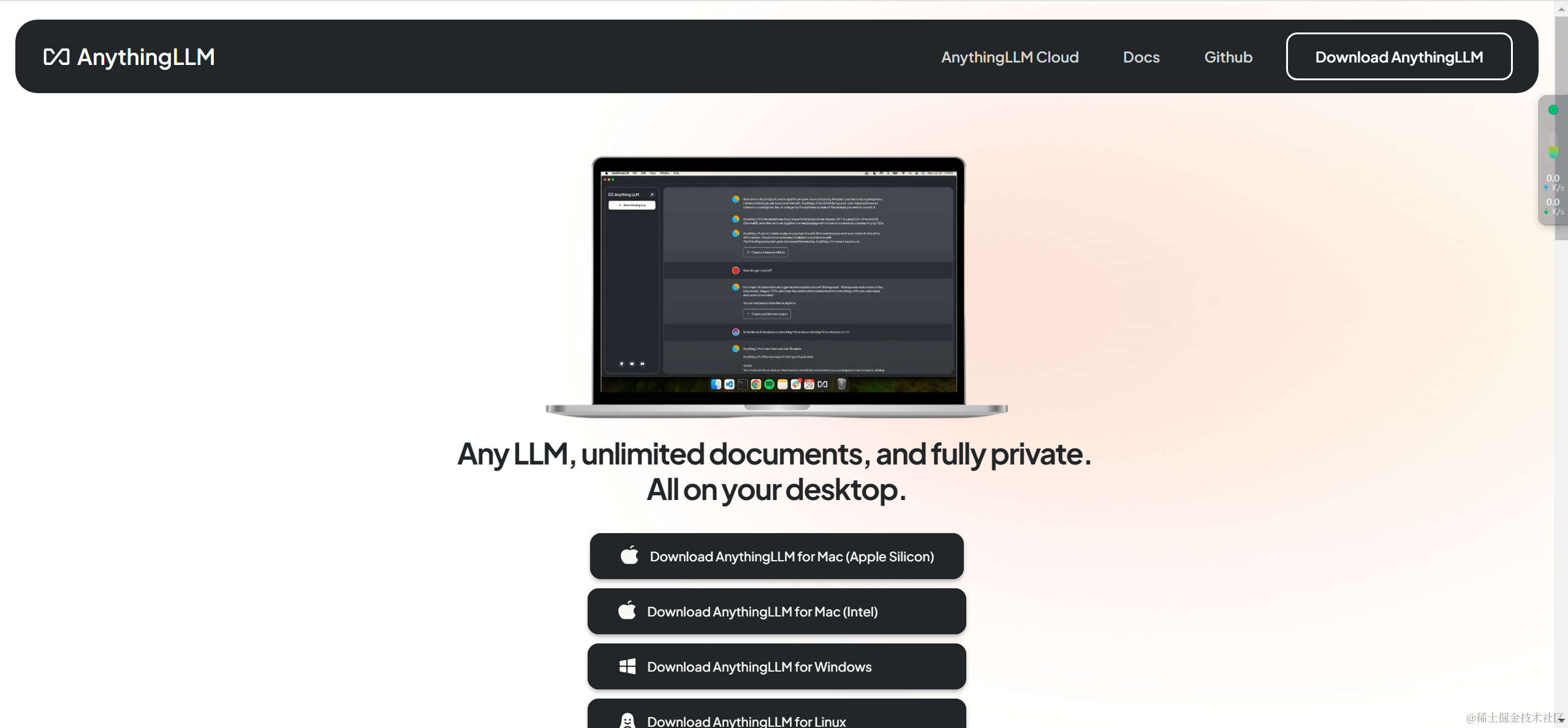
值得一提的是,AnythingLLM可以支持PDF,TXT,DOCX等文档,可以提取文档中的文本信息,经过嵌入模型(Embedding Models),保存在向量数据库中,并通过一个简单的UI界面管理这些文档。
为管理这些文档,AnythingLLM引入工作区(workspace) 的概念,作为文档的容器,可以在一个工作区内共享文档,但是工作区之间隔离。
同时,它独特的多用户模式,配合工作区使用起来效果更佳:
- 管理员(Admin)账号:拥有全部的管理权限。
- Manager账号:可管理所有工作区和文档,但是不能管理大模型、嵌入模型和向量数据库。
- 普通用户账号:基于已授权的工作区与大模型对话,不能对工作区和系统配置做任何更改。
MaxKB
MaxKB 是一款基于 LLM 大语言模型的知识库问答系统。MaxKB = Max Knowledge Base,旨在成为企业的最强大脑。

与同类基于LLM的知识库问答提供系统相比,MaxKB的核心优势包括:
■ 开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化,智能问答交互体验好;
■ 无缝嵌入:支持零编码快速嵌入到第三方业务系统;
■ 多模型支持:支持对接主流的大模型,包括本地私有大模型(如Llama 2)、OpenAI、Azure OpenAI和百度千帆大模型等。
使用界面是这个样子:
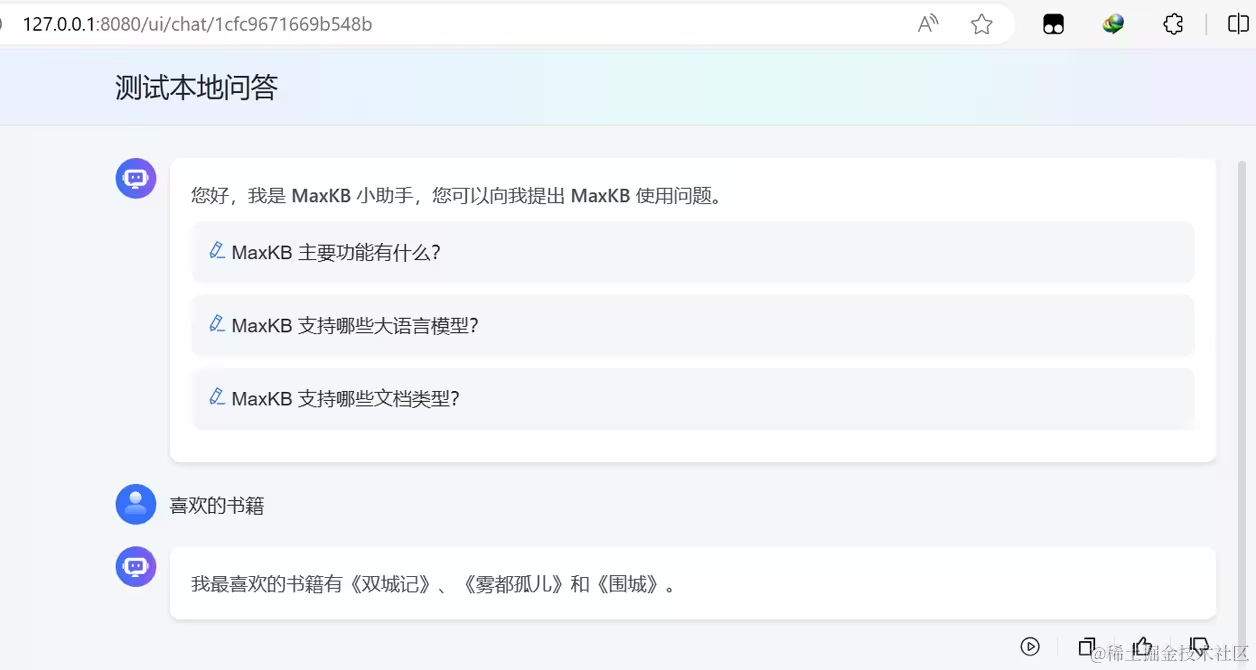
- 官方推荐采用docker进行快速部署,所以我个人建议还是起一台Linux虚拟机,方便又快捷;
- 如果稍微懂一点Linux,但是不太懂docker的,建议部署 1Panel 后再通过里面的应用商店来下载使用;
- 如果实在不会Linux的才建议安装Docker Desktop,但是安装的过程会麻烦很多,包括开启Hyper-v、CPU虚拟化、启用WSL、修改环境变量为非家庭版等(Docker Desktop不支持家庭版哦!),一套下来顺利的话也得至少半个小时以上。
上面这三种部署方式,后续也都会详细讲解到。
RAGFlow
RAGFlow 作为一款端到端的RAG解决方案,旨在通过深度文档理解技术,解决现有RAG技术在数据处理和生成答案方面的挑战。它不仅能够处理多种格式的文档,还能够智能地识别文档中的结构和内容,从而确保数据的高质量输入。RAGFlow 的设计哲学是“高质量输入,高质量输出”,它通过提供可解释性和可控性的生成结果,让用户能够信任并依赖于系统提供的答案。
2024年4月1日,RAGFlow宣布正式开源,这一消息在技术界引起了轰动。开源当天,RAGFlow 在 GitHub 上迅速获得了数千的关注,不到一周时间,已吸收2900颗星,这不仅体现了社区对 RAGFlow 的高度认可,也显示出大家对这一新技术的热情。
- 深度文档理解:“Quality in, quality out”,RAGFlow 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。真正在无限上下文(token)的场景下快速完成大海捞针测试。对于用户上传的文档,它需要自动识别文档的布局,包括标题、段落、换行等,还包含难度很大的图片和表格。对于表格来说,不仅仅要识别出文档中存在表格,还会针对表格的布局做进一步识别,包括内部每一个单元格,多行文字是否需要合并成一个单元格等。并且表格的内容还会结合表头信息处理,确保以合适的形式送到数据库,从而完成 RAG 针对这些细节数字的“大海捞针”。
- 可控可解释的文本切片:RAGFlow 提供多种文本模板,用户可以根据需求选择合适的模板,确保结果的可控性和可解释性。因此 RAGFlow 在处理文档时,给了不少的选择:Q&A,Resume,Paper,Manual,Table,Book,Law,通用… 。当然,这些分类还在不断继续扩展中,处理过程还有待完善。后续还会抽象出更多共通的东西,使各种定制化的处理更加容易。
- 降低幻觉:RAGFlow 是一个完整的 RAG 系统,而目前开源的 RAG,大都忽视了 RAG 本身的最大优势之一:可以让 LLM 以可控的方式回答问题,或者换种说法:有理有据、消除幻觉。我们都知道,随着模型能力的不同,LLM 多少都会有概率会出现幻觉,在这种情况下, 一款 RAG 产品应该随时随地给用户以参考,让用户随时查看 LLM 是基于哪些原文来生成答案的,这需要同时生成原文的引用链接,并允许用户的鼠标 hover 上去即可调出原文的内容,甚至包含图表。如果还不能确定,再点一下便能定位到原文。RAGFlow 的文本切片过程可视化,支持手动调整,答案提供关键引用的快照并支持追根溯源,从而降低幻觉的风险。
- 兼容各类异构数据源:RAGFlow 支持 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据, 网页等。对于无序文本数据,RAGFlow 可以自动提取其中的关键信息并转化为结构化表示;而对于结构化数据,它则能灵活切入,挖掘内在的语义联系。最终将这两种不同来源的数据统一进行索引和检索,为用户提供一站式的数据处理和问答体验。
- 自动化 RAG 工作流:RAGFlow 支持全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统;大语言模型 LLM 以及向量模型均支持配置,用户可以根据实际需求自主选择。;基于多路召回、融合重排序,能够权衡上下文语义和关键词匹配两个维度,实现高效的相关性计算;提供易用的 API,可以轻松集成到各类企业系统,无论是对个人用户还是企业开发者,都极大方便了二次开发和系统集成工作。
FastGPT
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
该项目主要提供了以下几个核心特点和功能:
- 开箱即用的数据处理与模型调用:FastGPT允许用户轻松地导入文档、文本文档、PDF文件、电子邮件等非结构化数据,并自动处理这些数据以便于模型理解和使用。它内置了对多种大型语言模型的支持,如GPT-2、GPT-3及其变体,用户可以快速调用这些模型进行问答或对话任务。
- 可视化工作流编排:FastGPT支持使用Flow可视化工具进行工作流的编排,使得构建复杂问答场景变得更加直观和简单,用户可以拖拽组件来设计数据处理流程、模型调用逻辑等,而不需要编写大量代码。
- 高效向量检索:项目利用PostgreSQL的PG Vector插件作为向量检索器,优化了对大规模数据的检索效率,这在处理复杂知识库查询时尤为关键。
- 易于部署与定制:FastGPT设计有较低的学习成本,便于用户快速上手和部署。同时,它支持模型的微调和扩展,用户可以根据特定需求调整模型,使其更好地服务于特定领域或业务场景。
Dify
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
你或许可以把 LangChain 这类的开发库(Library)想象为有着锤子、钉子的工具箱。与之相比,Dify 提供了更接近生产需要的完整方案,Dify 好比是一套脚手架,并且经过了精良的工程设计和软件测试。
重要的是,Dify 是开源的,它由一个专业的全职团队和社区共同打造。你可以基于任何模型自部署类似 Assistants API 和 GPTs 的能力,在灵活和安全的基础上,同时保持对数据的完全控制。
Open WebUI
Open WebUI(前身为Ollama WebUI)是一个可扩展的、功能丰富的、用户友好的自托管Web界面,设计用于完全离线运行。它支持各种LLM(大型语言模型)运行器,包括Ollama和兼容OpenAI的API。
特性包括:
- 直观界面:聊天界面灵感源自 ChatGPT,确保用户友好体验。
- 响应式设计:在桌面和移动设备上都能获得无缝体验。
- 本地RAG集成:通过开创性的检索增强生成(RAG)支持,深入聊天互动的未来。这项功能将文档交互无缝集成到你的聊天体验中。你可以直接将文档加载到聊天中,或者毫不费力地将文件添加到你的文档库中,使用提示中的#命令轻松访问它们。在其alpha阶段,可能会出现偶尔的问题,因为我们正在积极改进和增强这项功能,以确保最佳性能和可靠性。
- 无缝设置:使用 Docker 或 Kubernetes(kubectl、kustomize 或 helm)轻松安装,无烦恼体验。
- 主题定制、代码语法高亮、完整支持 Markdown 和 LaTeX、本地 RAG 整合、RAG 嵌入支持、网页浏览功能。
该项目还具有诸多功能,支持多模型和多语言设置,旨在提供全面的聊天体验,提高用户互动的灵活性和多样性。
小结
纵观上述知识库侧的六种工具,我们不难发现其共同点:都强调了对检索增强生成(RAG, Retrieval Enhanced Generation)的支持。RAG是一种结合了检索和生成两种策略的技术,旨在提升模型的性能,尤其是在处理需要精确信息检索和上下文理解的任务上。而RAG的准确性,则决定了本地知识库最终生成答案的质量与实用性,工具能否支持用户实现或者让用户能以更小的代价、更简单的方式实现RAG,是评判知识库侧工具能力的关键点。
其次需要考虑的点就是这些工具能否满足多样化的模型集成与高度的可定制性的要求。要既能对接外部模型比如:通义千问、OpenAI、Azure OpenAI等,也能对接本地大模型侧工具如Ollama,确保了广泛的应用覆盖和适应性。
再者,需要考虑的才是用户体验与界面等方面。综合以上几点,因此,方能挑选出最为合适的知识库侧工具。
大模型侧
大模型侧理论上是需要对模型本身进行测评的,但是本人确实无此资质,所以在此不做对于任何模型的评测。如有需求,可以直接查看CompassArena 司南大模型竞技场给出的排行榜,并根据实际情况挑选适合自己的模型。
这里主要讨论用来管理或者快捷部署本地大模型的工具,较为热门的主要包括:Ollama、LM Studio、Xinference等。
Ollama
最近被刷爆的唯一真神!
Ollama是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型,如Llama 2和最新开源的Llama 3。Ollama极大地简化了在Docker容器内部署和管理LLM的过程,使得用户能够快速地在本地运行大型语言模型。
在6月2日,Ollama也推出了他的 0.1.40 - 0.1.41 版本,新推出了三个模型:
- Codestral:这是 Mistral AI 首次推出的代码生成模型,专门为编码任务设计。
- IBM Granite Code:专门为编码任务设计,目前提供 3B 和 8B 两种模型大小。
- Deepseek V2:一款强大、经济又高效的混合专家语言模型。
目前为止,Ollama几乎可以说是大模型工具侧的神,极其推荐使用!
LM Studio
LM Studio,这款丝毫不逊色于Ollama!
LM Studio 是一款功能强大、易于使用的桌面应用程序,用于在本地机器上实验和评估大型语言模型(LLMs)。它允许用户轻松地比较不同的模型,并支持使用 NVIDIA/AMD GPU 加速计算。
使用LM Studio不需要深厚的技术背景或复杂的安装过程。它提供了一个简单的安装程序,用户只需几个简单的步骤就可以轻松安装和运行。
Xinference
相比于上面两位重量级的,这位最近在互联网上就稍显冷门了。
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于各种模型的推理。通过 Xinference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xinference 与最前沿的 AI 模型,发掘更多可能。
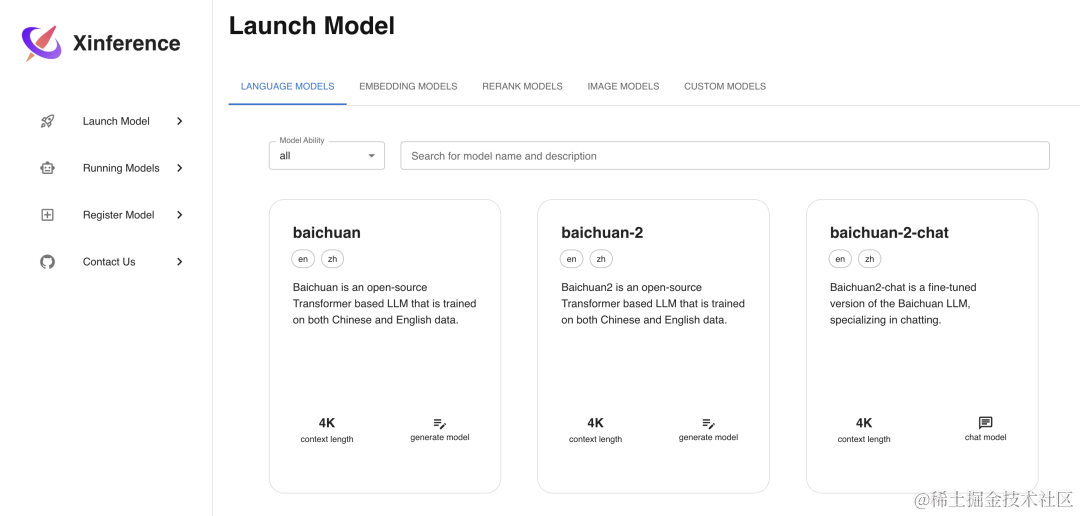
可能在界面上没有上面二位那么美观,但是基础功能还是比较齐全的,提供了简洁的API来集成模型到应用,还便于模型管理和高性能的基础设施,保证了在复杂模型运行的效率。
小结
纵观上述大模型侧的三种工具,我们也可以看出,能高效部署和快速使用是大模型侧工具选择的第一要义,其次是工具的定制与可扩展性,再其次是易用性、稳定性。这四个维度综合起来,为大模型工具选择奠定了坚实的基础,使得项目能够既高效推进,又能适应变化,稳定可靠,同时满足定制需求,操作友好。因此,评估时这四点缺一不可,方能挑选出最为合适的大模型侧工具。
大模型侧工具安装部署实践
这里首先介绍的是大模型侧的工具安装部署实践,至于为什么先提大模型侧后提知识库侧呢?这是因为大模型通常是知识库操作和应用的基础与核心,是提供智能决策的引擎。它们构建了理解和生成文本、图像、语音等多模态反应的基础能力,是整个智能应用的心脏,同时,由于这次主题是本地大模型个人知识库,所以大模型的安装、配置、优化和部署是首要步骤,也是确保知识库工具能够顺畅运行的基石。
随后才转到知识库侧,是因为知识库是大模型应用的扩展和优化层,它们是模型与业务场景的桥梁。知识库如RAG集成,使得模型能精准定位和检索增强生成,通过文档、上下文理解,提高交互式问答等。知识库通过索引申明确定模型的实用性,让模型能够更贴近业务需求,提升用户体验,如MaxKB、Open WebUI等工具提供了直接上传、管理文档、集成知识,使得模型与业务系统无缝对接。因此,知识库是大模型的补充,提升模型在具体应用中发挥价值的关键,所以放在模型之后介绍。
简而言,先模型侧,后知识库,是按照技术实施的逻辑顺序,从基础架构到应用优化,确保理解模型部署到业务场景的深入,逐步构建出高效、用户友好的智能系统。
Ollama部署
Windows部署Ollama
首先,访问Ollama官网(点此到达)。
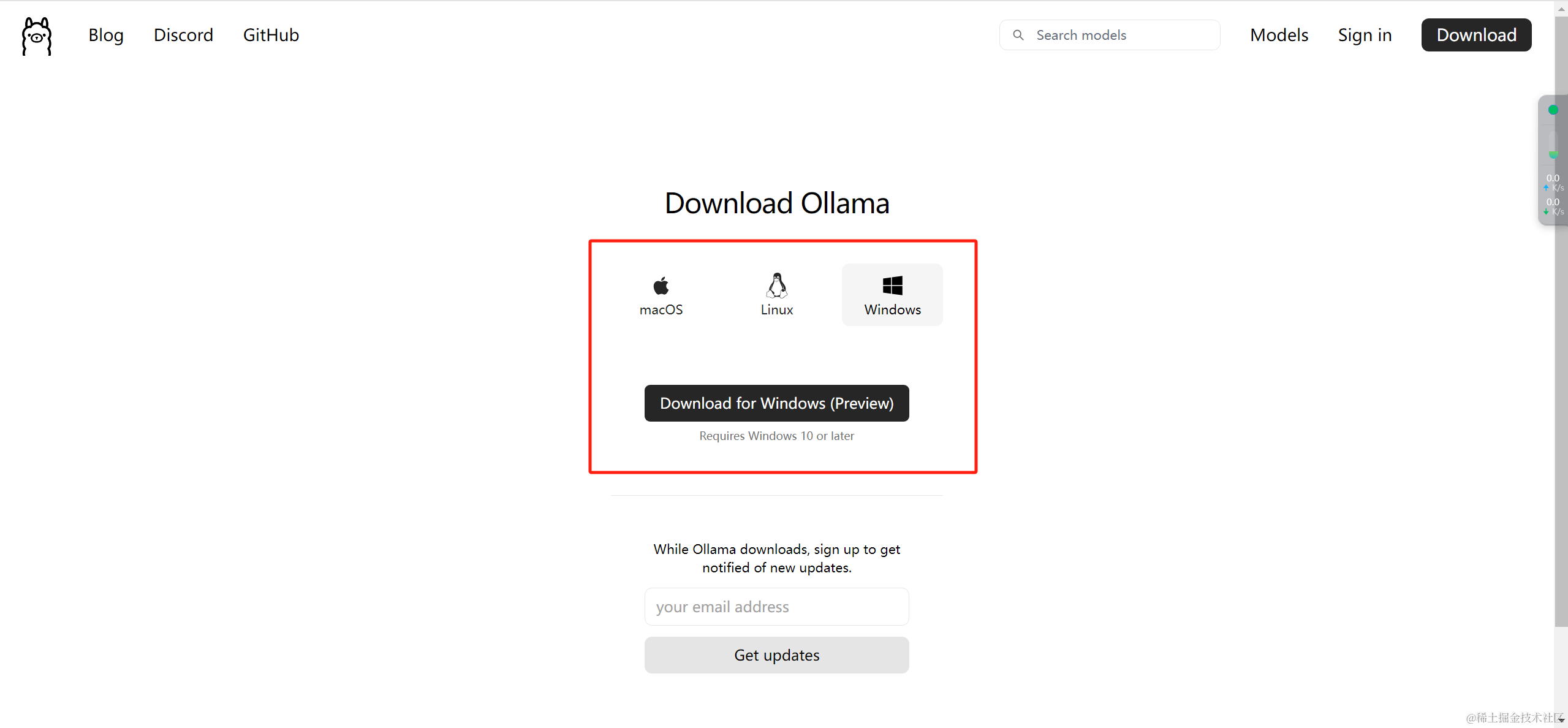
点击下载,选择适配自己电脑的版本。
Windows下载完之后电脑也没弹出快捷启动方式啥的,不知道是不是bug,我这里一般是点击缩略符进到日志目录下,再右键打开终端。
再回到Ollama官网,点击右上角的Models。
可以看到诸多模型如下:
我们点击llama3,可以看到如下界面:
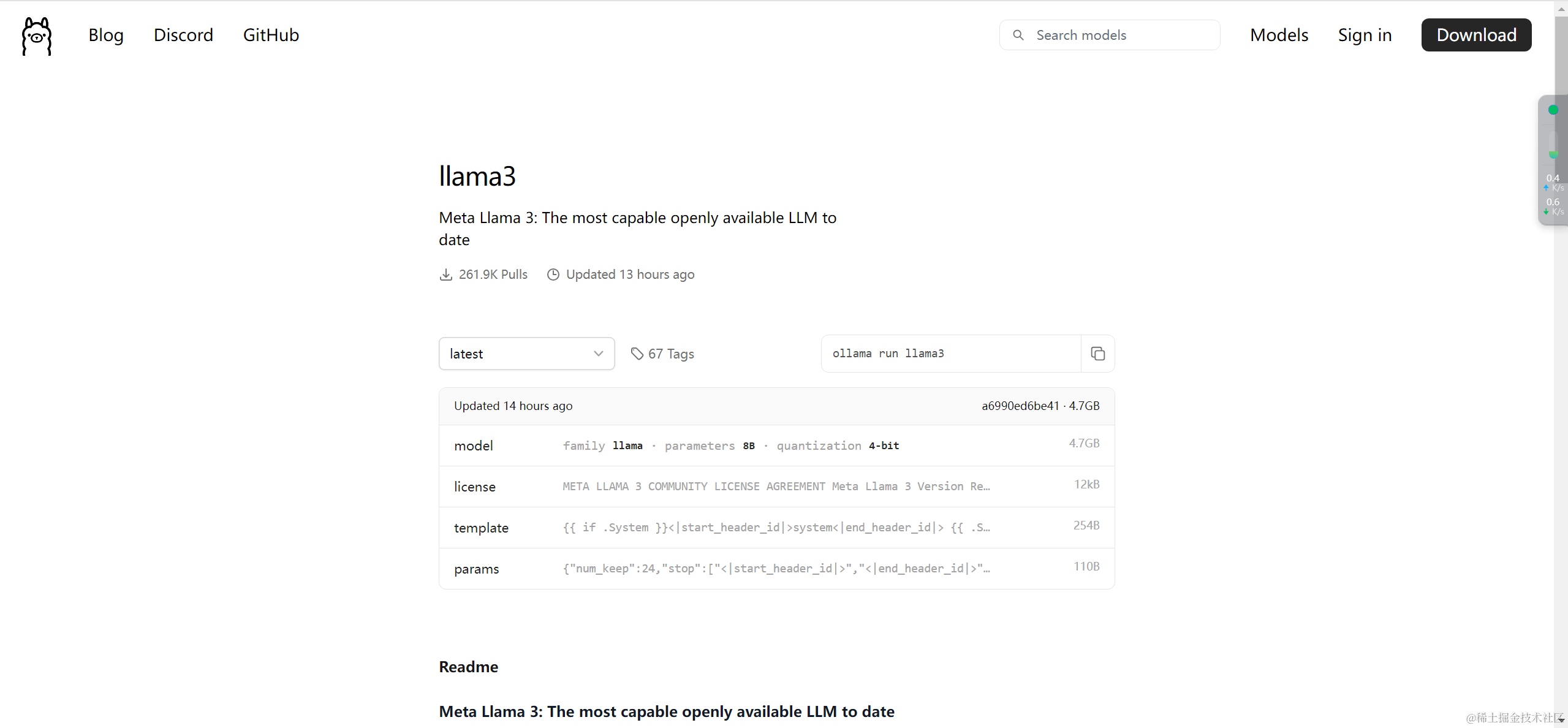
点击latest,可以选择模型的类型,笔记本运行建议8b,服务器可以选择70b(作者笔记本显卡为RTX4070)。
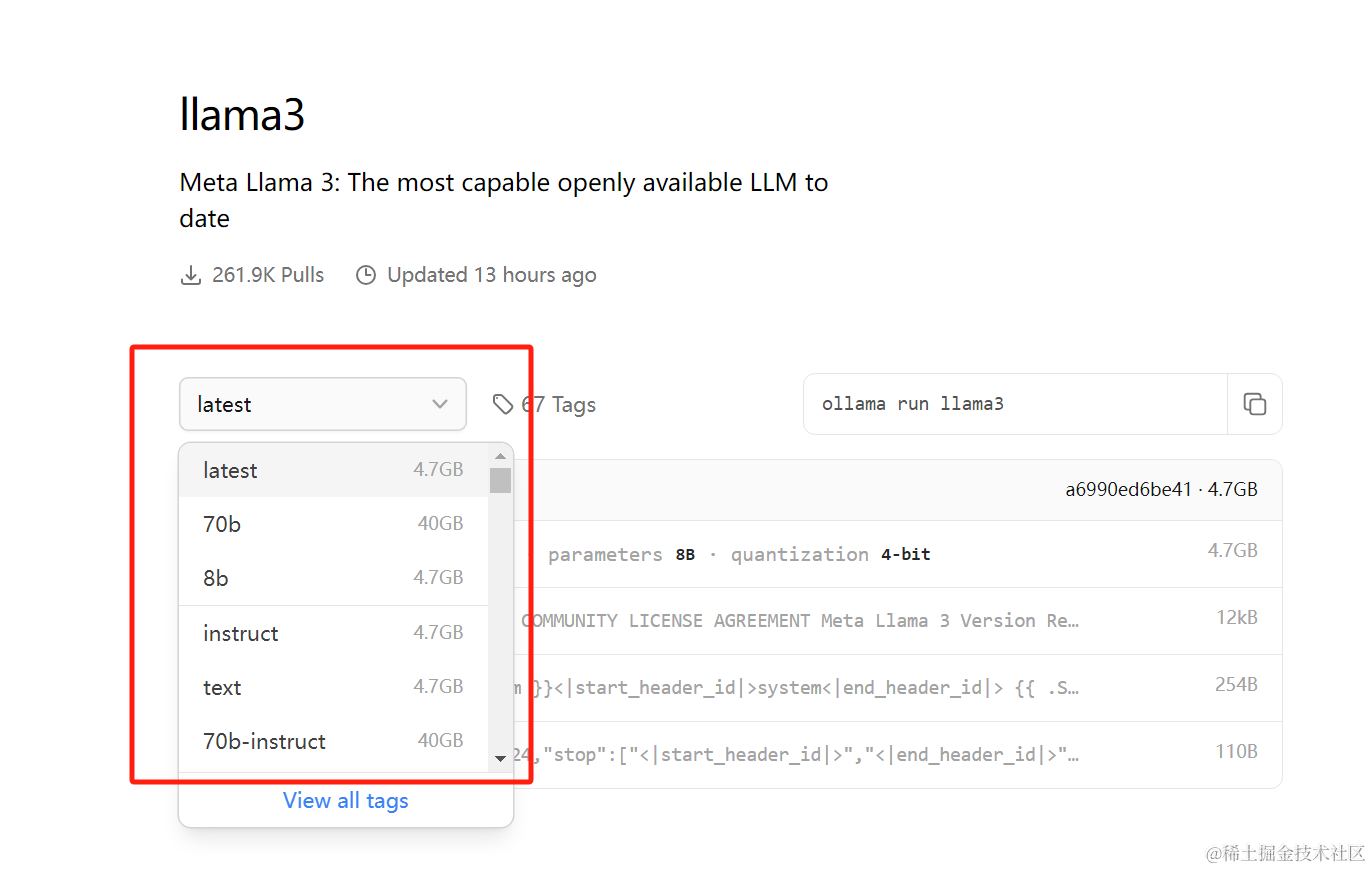
点击复制按钮,粘贴命令行到终端框,执行即可。
ollama run llama3:8b
- 1
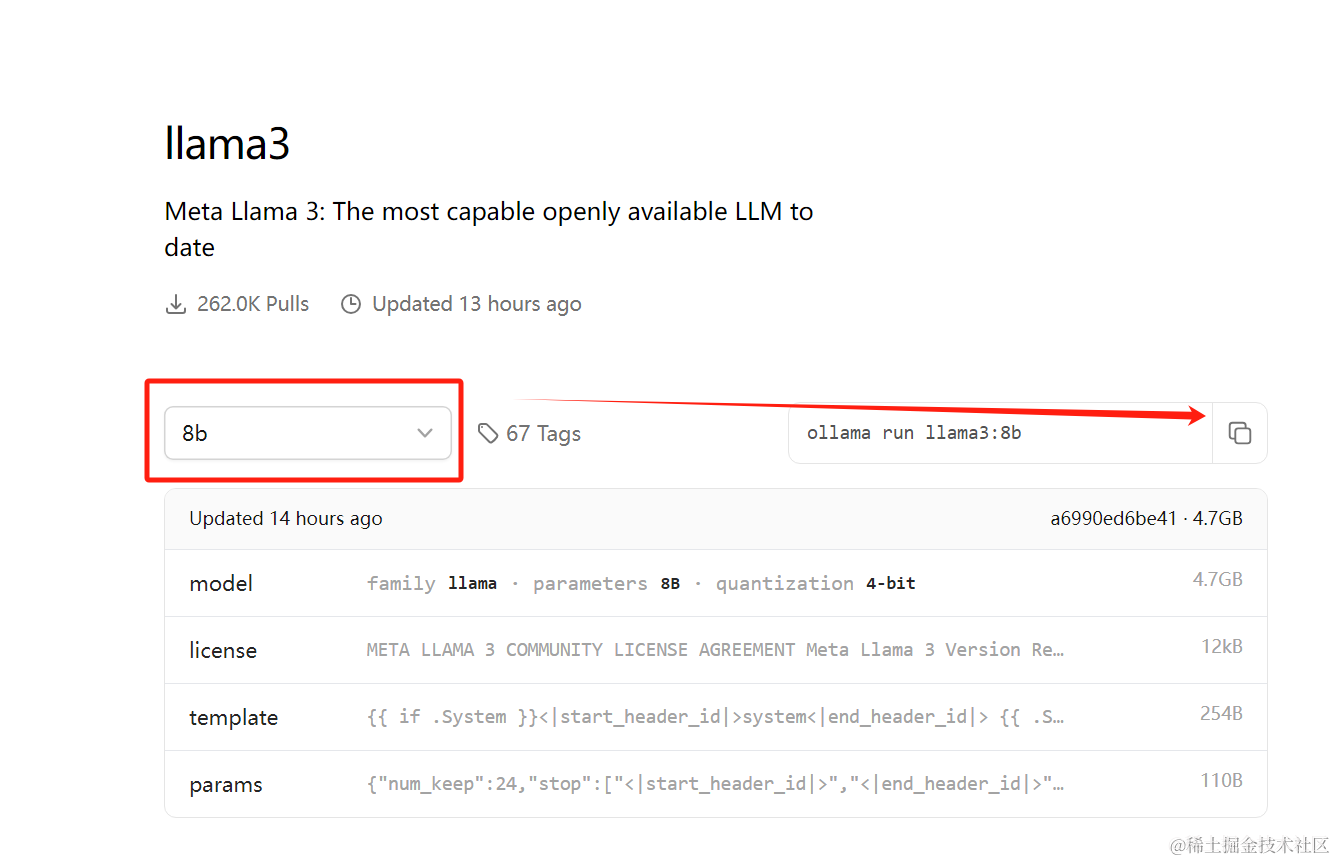
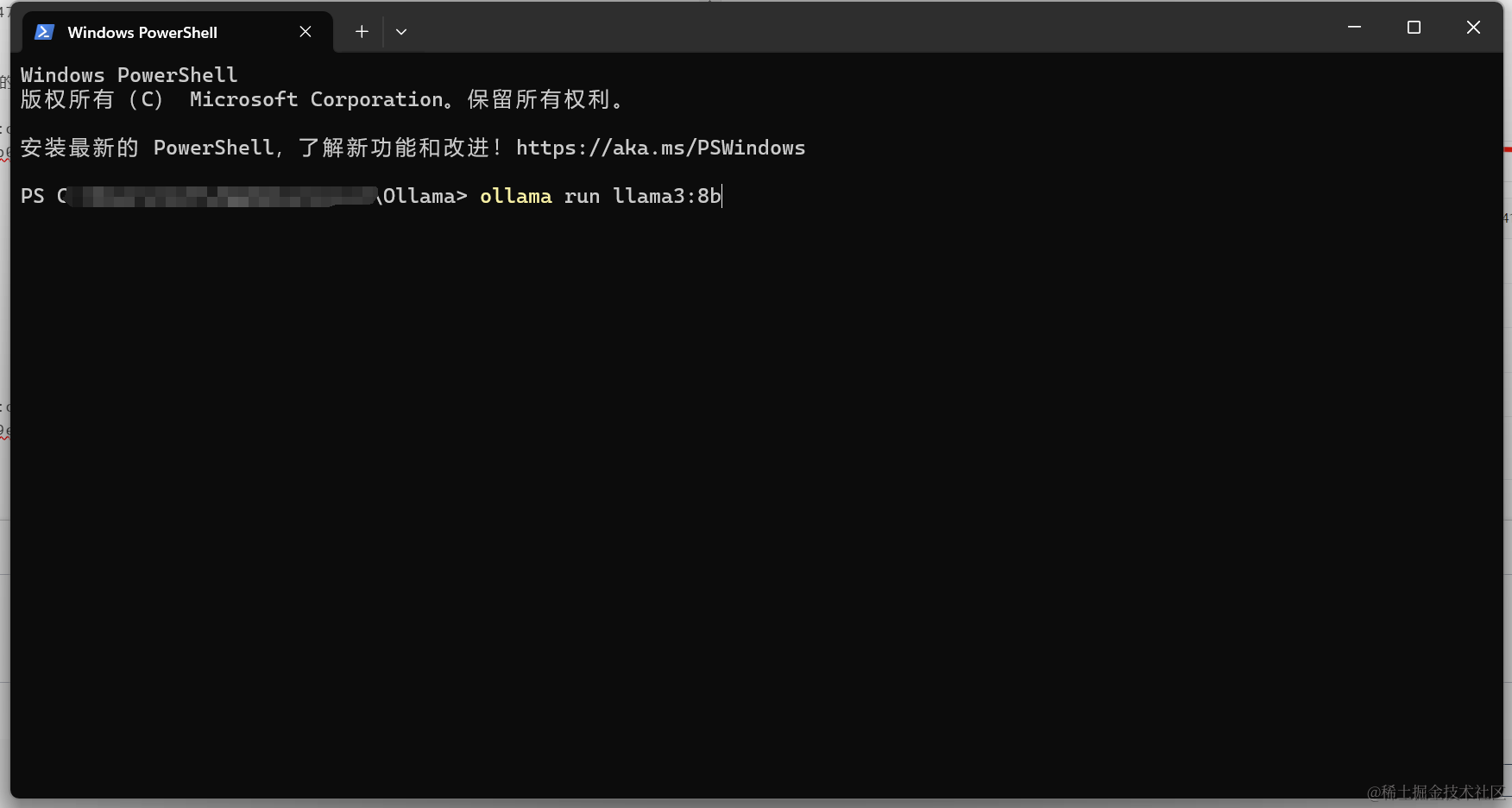
安装好后如下所示:


当然,在Windows环境下其实也可以采用docker来部署Ollama,但是我这里并未提及,一点是因为配置过程稍微麻烦,第二是因为在windows中部署docker会对电脑性能有一定的折损,有Linux操作基础的小伙伴没有必要进行该尝试,直接看下面的Linux部署部分内容就可以了。
Linux部署Ollama
在Linux环境下,部署Ollama也仅仅只需一条命令。前期基础虚拟机搭建可以参看我以前的文章,Linux虚拟机安装操作。
进入虚拟机后,打开命令行,输入
curl -fsSL https://ollama.com/install.sh | sh
- 1
此时会提示需要更新包。

执行如下命令更新包:
sudo apt install curl
- 1
更新完毕后再次执行,开始部署并启动Ollama:
在这个过程中,极有可能出现超时的情况,需要修改hosts文件,直接将 http://github.com 做个ip指向,进入如下编辑页面:
sudo vim /etc/hosts
- 1
进入后,增加如下配置:
# github 注意下面的IP地址和域名之间有一个空格
140.82.114.3 github.com
199.232.69.194 github.global.ssl.fastly.net
185.199.108.153 assets-cdn.github.com
185.199.109.153 assets-cdn.github.com
185.199.110.153 assets-cdn.github.com
185.199.111.153 assets-cdn.github.com
- 1
- 2
- 3
- 4
- 5
- 6
- 7
再次尝试,就不会直接出现超时的情况了,但是由于是国内环境,速度依然不是很理想。
在Ollama安装完成后, 一般会自动启动 Ollama 服务,而且会自动设置为开机自启动,然后这里我直接运行一个千问模型,可以看到运行成功。
除了直接部署之外,也支持采用docker的方式来部署,作者这里也推荐使用这种方式。
首先是安装 docker 和 docker-compose
sudo apt install docker.io
sudo apt-get install docker-compose
sudo usermod -aG docker $USER
sudo systemctl daemon-reload
sudo systemctl restart docker
- 1
- 2
- 3
- 4
- 5
然后配置国内 docker 镜像源,修改/etc/docker/daemon.json,增加以下配置:
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com"
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
配置好以后重启docker。
sudo systemctl daemon-reload
sudo systemctl restart docker
- 1
- 2
拉取镜像
docker pull ollama/ollama
- 1
在docker下,也有几种不同的启动模式(对应路径请按照实际情况更改):
CPU模式
docker run -d -v /opt/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
- 1
GPU模式(需要有NVIDIA显卡支持)
docker run --gpus all -d -v /data/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
- 1
docker部署ollama web ui
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:main
- 1
比如我采用CPU模式启动:

在浏览器中可以通过 服务器IP:11434 来进行访问查看 , 如下所示则是正常启动 。
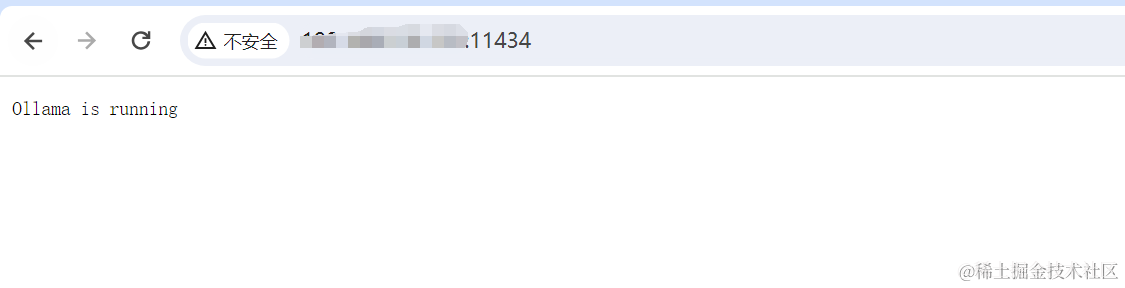
然后运行模型:
docker exec -it ollama ollama run llama3
- 1

安装完成后正常体验即可,如果觉得命令行不好看,也可以尝试上面的Web-UI部署。
Ollama使用技巧
模型更换存储路径
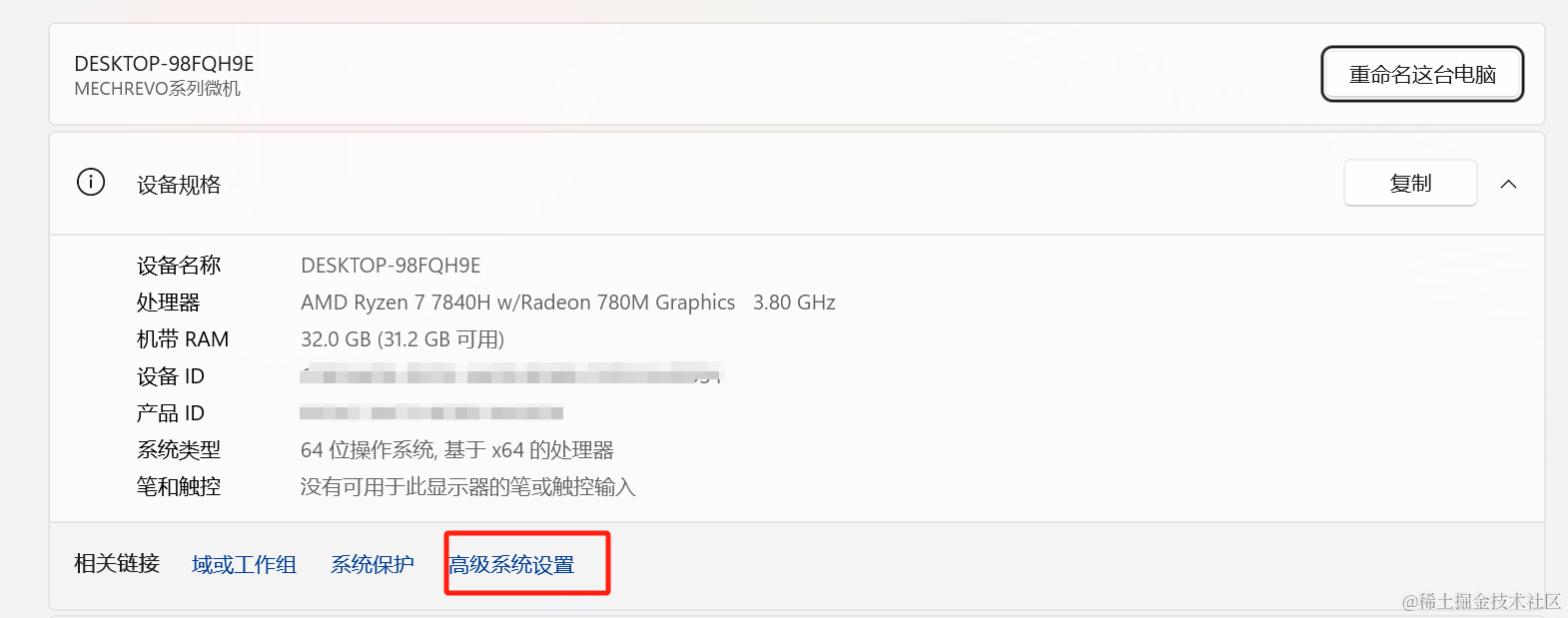
在windows系统中下载时,很不科学的一点就是默认使用C盘来存放模型文件,本来C盘就不够用,这一下载模型少说七八个GB就没了。但是莫慌,我们可以通过修改环境变量来设置指定模型的目录位置。
【电脑】——>右键【属性】——>【高级系统设置】——>【高级】——>【环境变量】
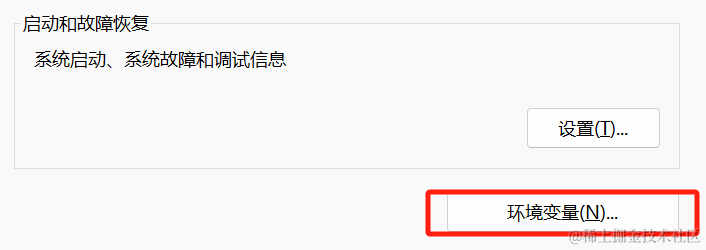
我们通过设置环境变量(OLLAMA_MODELS)来指定模型目录,可以通过系统设置里来配置环境变量(系统变量或者用户变量)
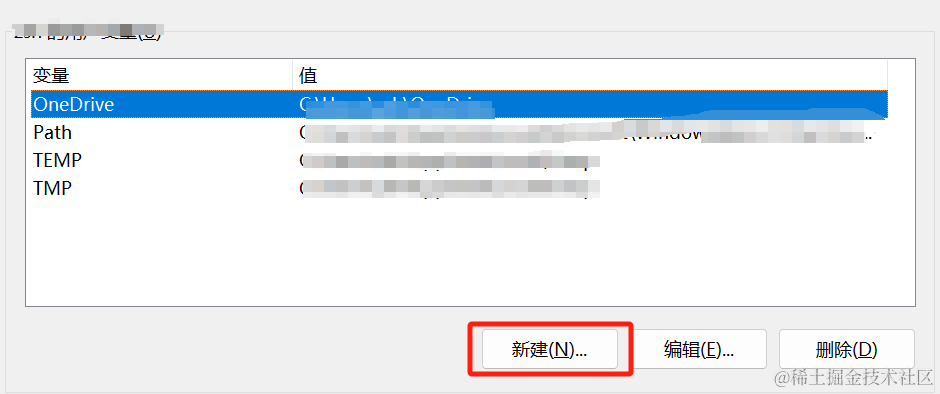
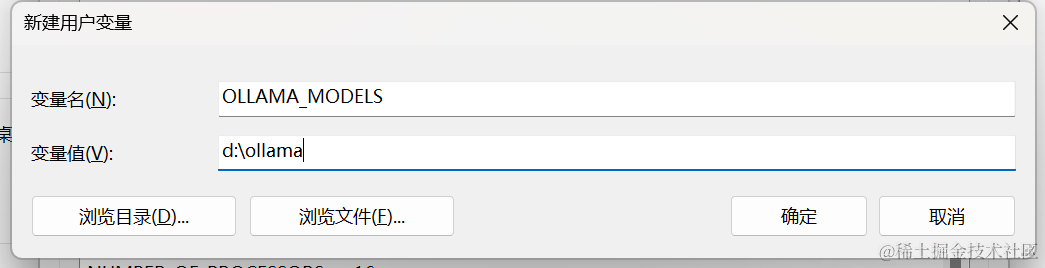
而在Linux系统中,默认地址是~/.ollama/models, 如果想移到别的目录,同样也是设置环境变量OLLAMA_MODELS:
export OLLAMA_MODELS=/data/ollama
- 1
导出某个模型
这里以 llama3:8b为例,先查看模型信息:
ollama show --modelfile llama3:8b
- 1
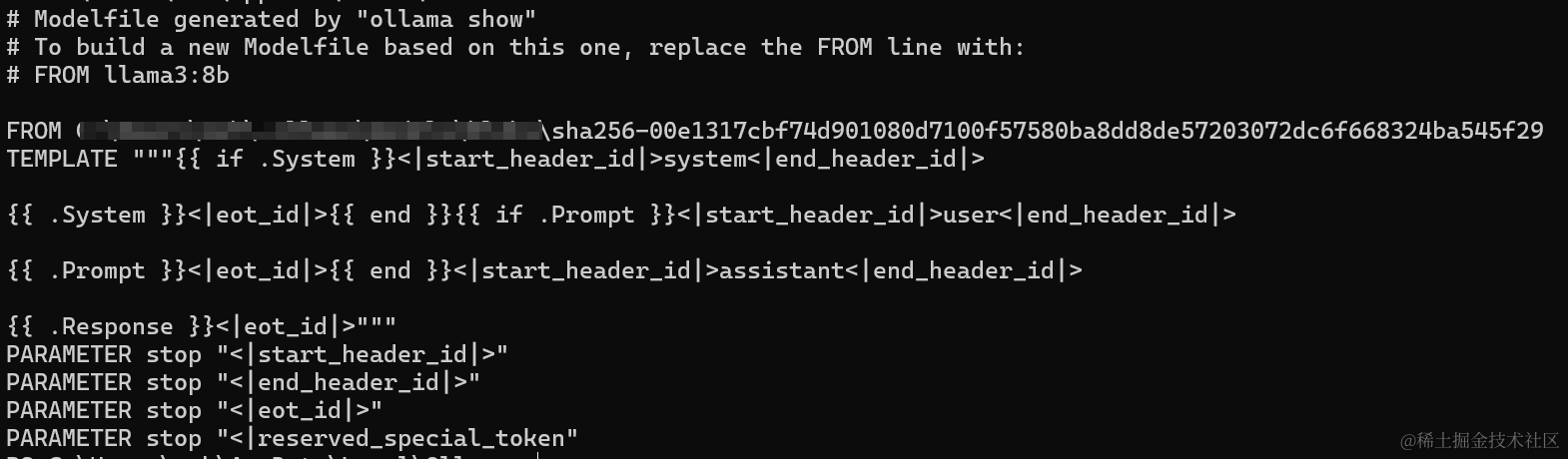
从模型文件信息里得知 /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29 即为我们想要的llama3:8b (格式为gguf),导出代码如下:
Linux系统中
cp /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29
- 1
Windows系统中
copy /xxx/xxx/xxx/xxx/xxx/sha256-00e1317cbf74d901080d7100f57580ba8dd8de57203072dc6f668324ba545f29
- 1
导入某个模型
比如我们选择个链接 https://hf-mirror.com/brittlewis12/Octopus-v2-GGUF/tree/main 下载octopus-v2.Q8_0.gguf
准备Modelfile文件
From /path/to/qwen_7b.gguf
- 1
是最简单的办法 当然可以从上面模型信息生成完成版本的Modelfile
# Modelfile generated by "ollama show" # To build a new Modelfile based on this one, replace the FROM line with: # FROM qwen:7b FROM /path/to/qwen_7b.gguf TEMPLATE """{ { if .System }}<|im_start|>system { { .System }}<|im_end|>{ { end }}<|im_start|>user { { .Prompt }}<|im_end|> <|im_start|>assistant """ PARAMETER stop "<|im_start|>" PARAMETER stop ""<|im_end|>""

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
记得替换你的模型的完整路径 另外不同模型的template 和 stop parameter不同,这个不知道就不写,或者网上搜索 然后执行:
ollama create qwen:7b -f Modelfile
- 1
导入模型的时候,至少确保硬盘可用空间在模型大小的2倍以上。
小结
通过以上实际部署及使用操作体验情况来看,我只能说无怪Ollama最近爆火,它是真正击中了众多开发者的心(包括我),轻松点击几下鼠标就可以完成本地模型的部署,这种“即插即用”的模式,彻底改变了以往需要深厚技术背景才能涉足的大型语言模型应用领域,让更多创意和项目得以孵化。除此之外,它也提供了丰富的模型选择,Ollama里支持的模型库达到了92种,涵盖了从基础研究到行业应用的广泛需求,甚至最新的qwen2也在其中。
而在使用上,Ollama虽然没有直接提供可视化一键拉取模型的方式,但是由于其命令简明,手册清晰,所以我觉得这点也是可以接受的。
总的来概括一下,Ollama确确实实是一个部署模型便捷、模型资源丰富、可扩展性强的大模型侧的工具,截止至2024年6月8日,我仍然认为它是部署本地大模型的不二之选。
LM Studio部署
Windows部署LM Studio
进入LM Studio官网,需要加载一分钟左右,点击【Download LM Studio for Windows】:
这个下载速度属实给我干沉默了:
好不容易下载完了,这边我也给出百度云的资源,避免小伙伴们走弯路:
链接:https://pan.baidu.com/s/1UZvxkmHuCSWBpnQ2EYje0A
提取码:nigo

点击可以直接启动,界面如下:
- Home:主屏幕区,后面推荐各类大模型
- Search:搜索下载各类大模型。
- AI Chat:模型对话区
- Multi Model:多模型对话,显存要大24G+。
- Local Server:创建web服务
- My Models:已下载模型和文档设置
先来到文件夹这里,把模型的下载路径换到D盘下面:
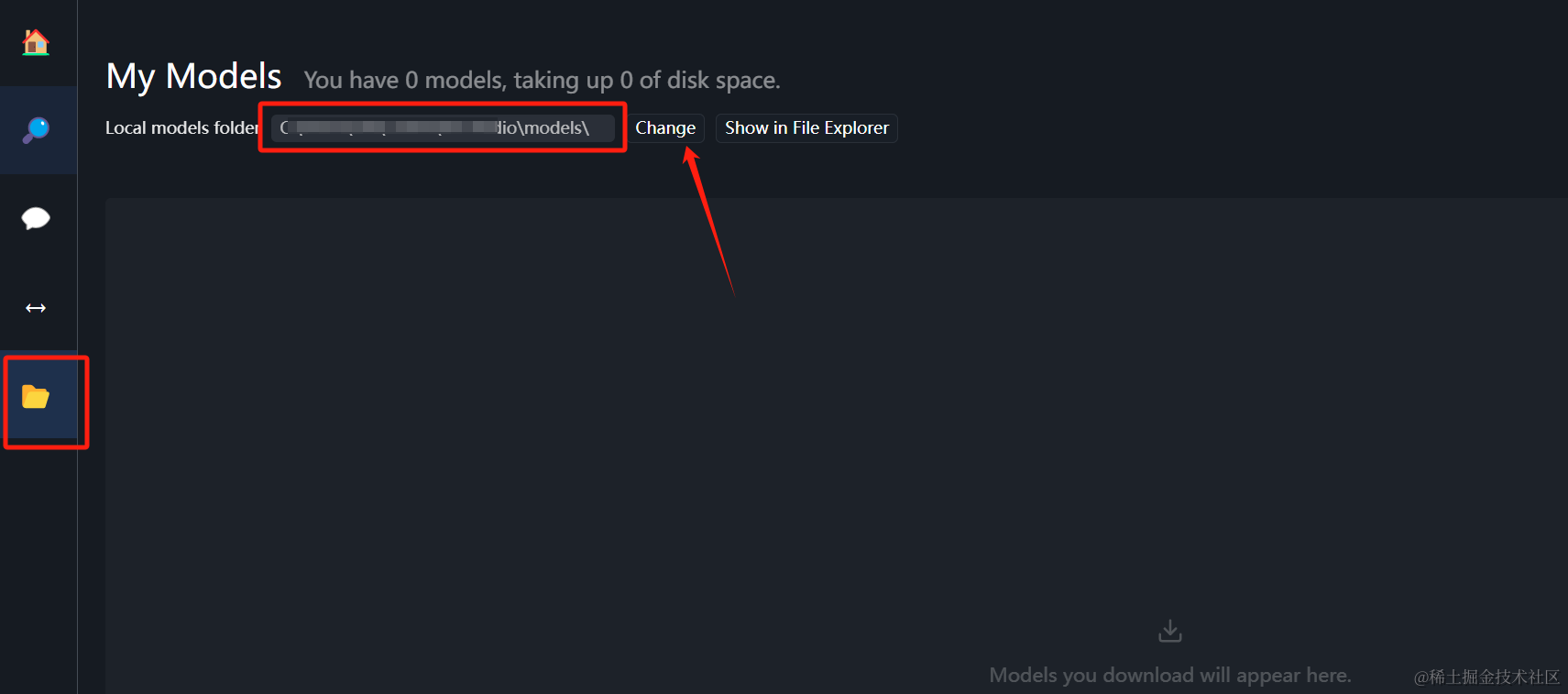
这里必须在D盘下创建该目录结构:
D:\models\Publisher\Repository
- 1
但在点击 Change 时,自定义路径选择到 /models 层即可。

在主界面中直接下拉,可浏览各种大语言模型,选择download 按钮可直接下载,但是部分模型可能需要科学上网才能下载:
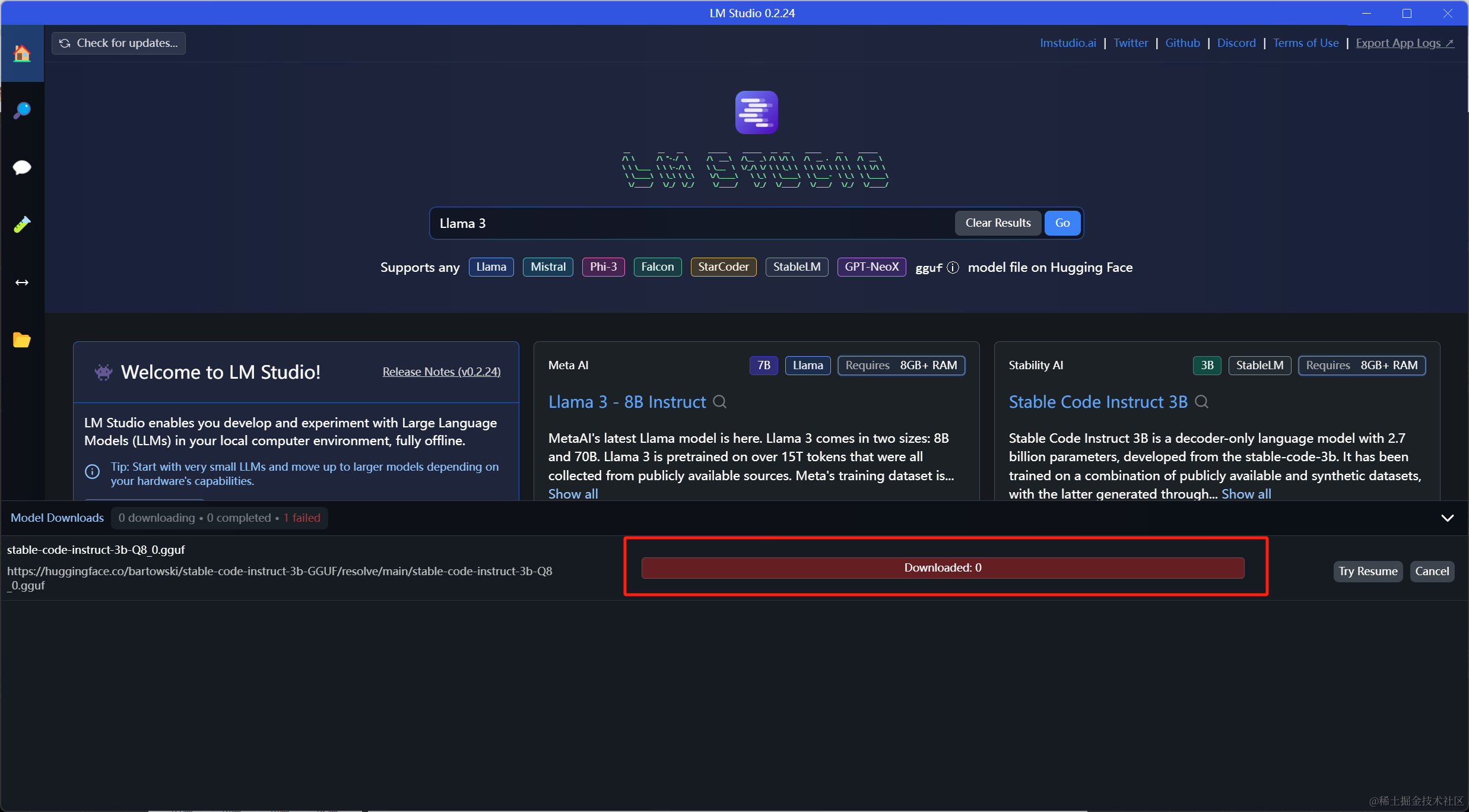
同时,在搜索栏中也可以直接搜索想要下载的模型:
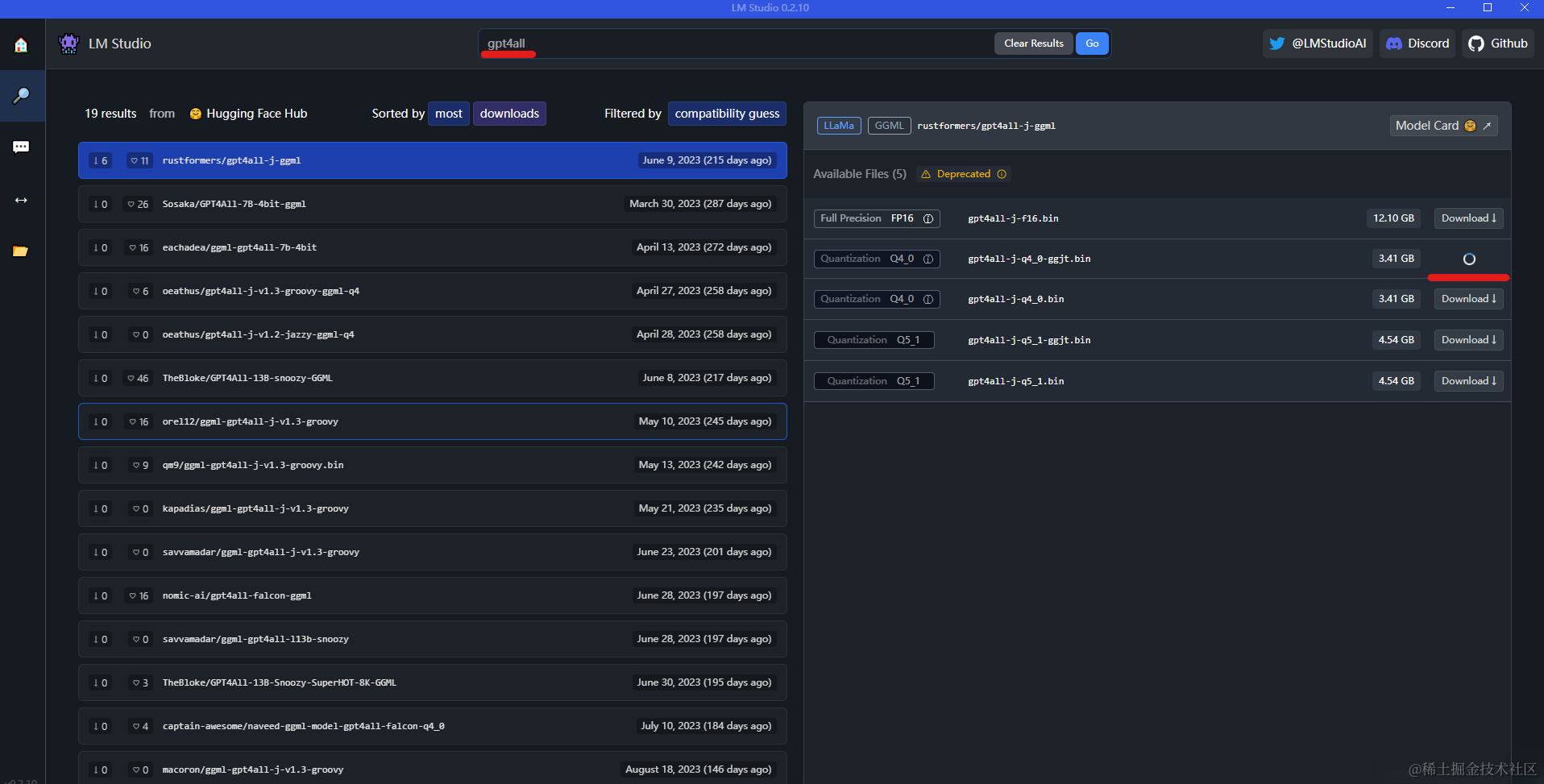
当模型下载完后,可以在左边菜单栏选择chat图标,然后选择模型(下载之后的模型会在下拉列表中),如下图:
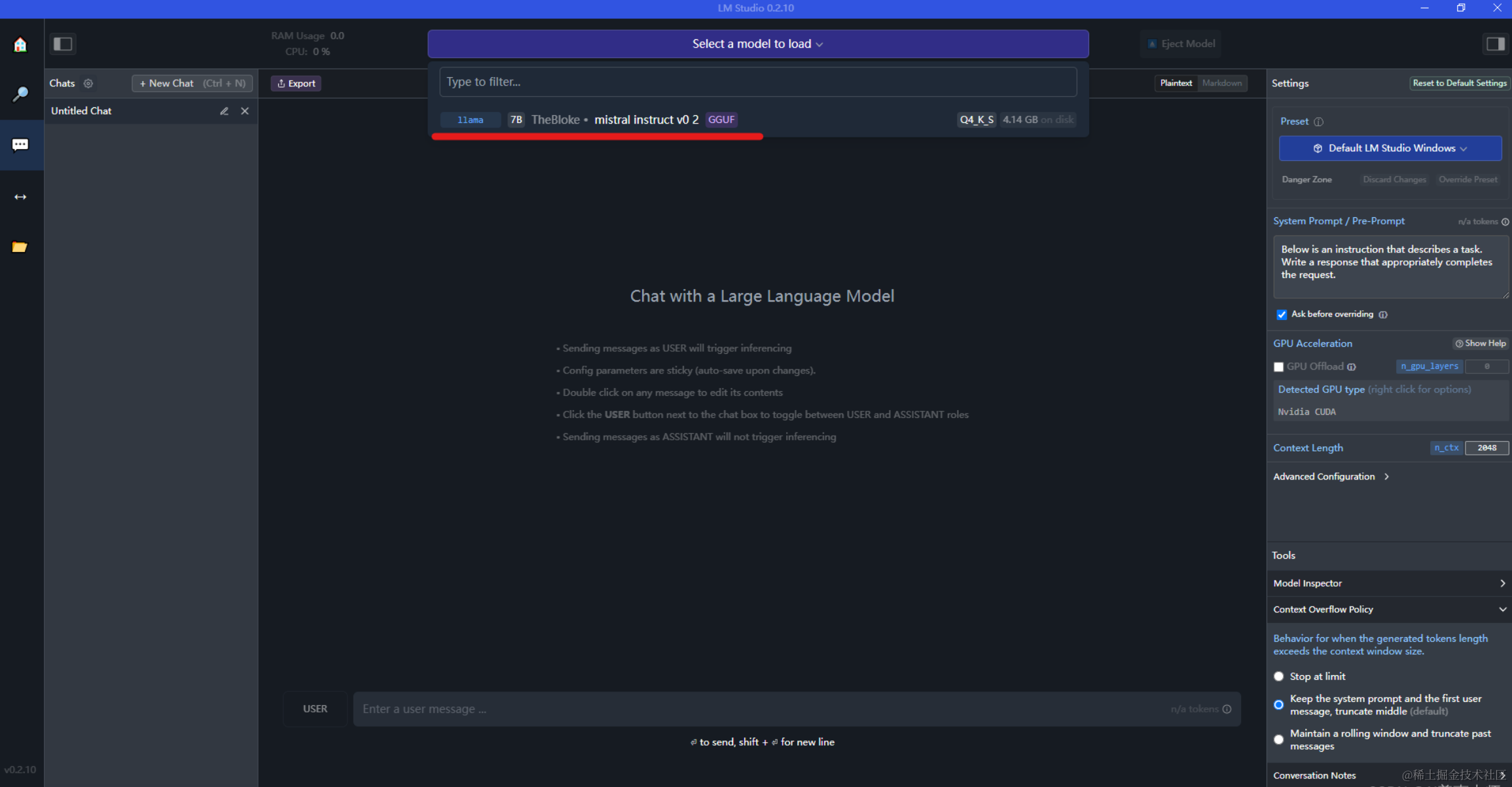
直接输入你想要提问的问题,和模型进行对话
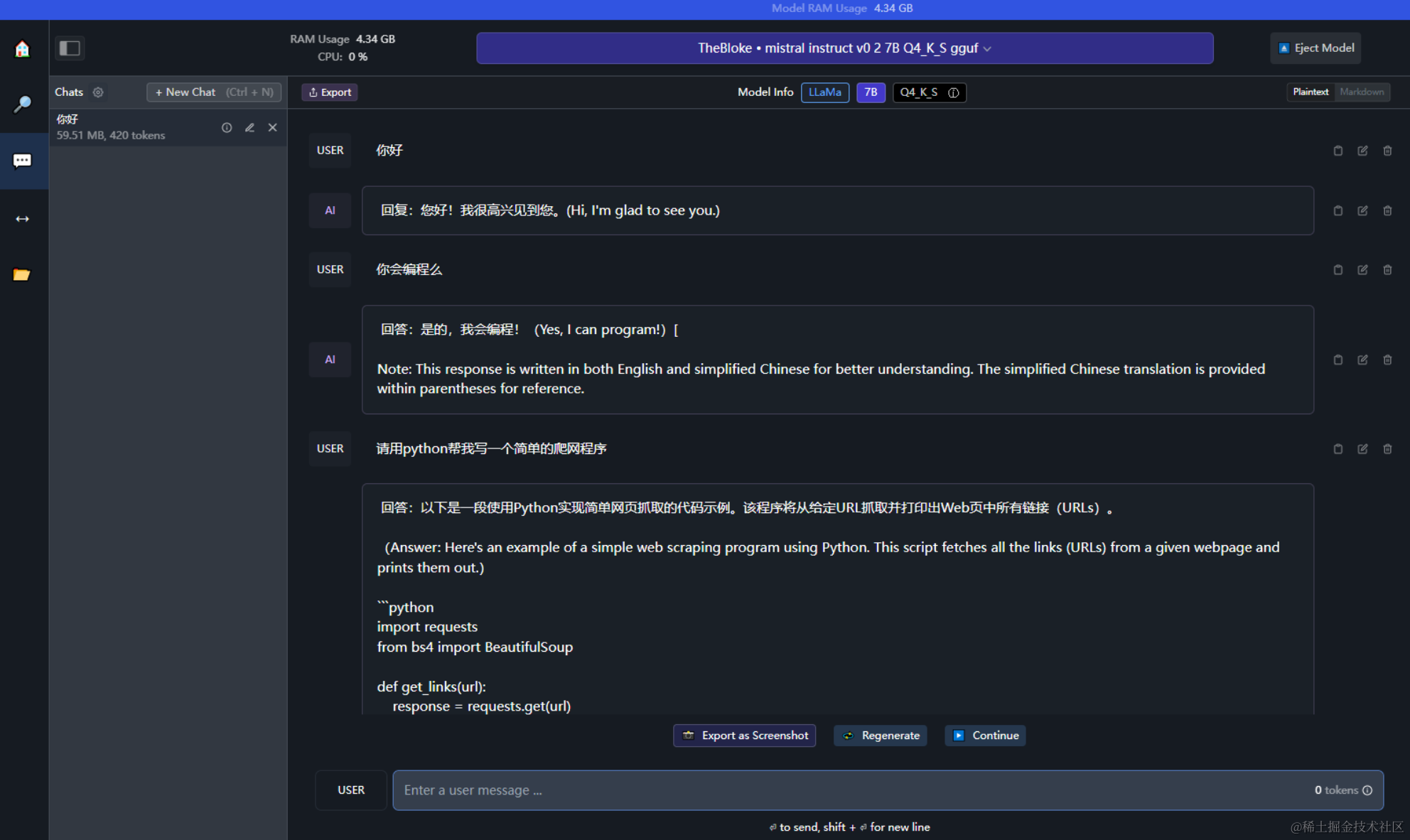
当然,LM 同样也支持在本地以Server的形式提供API接口服务,这意味着可以把大语言模型做为一个后端服务来进行调用,前端可以包装任意面向业务的功能。
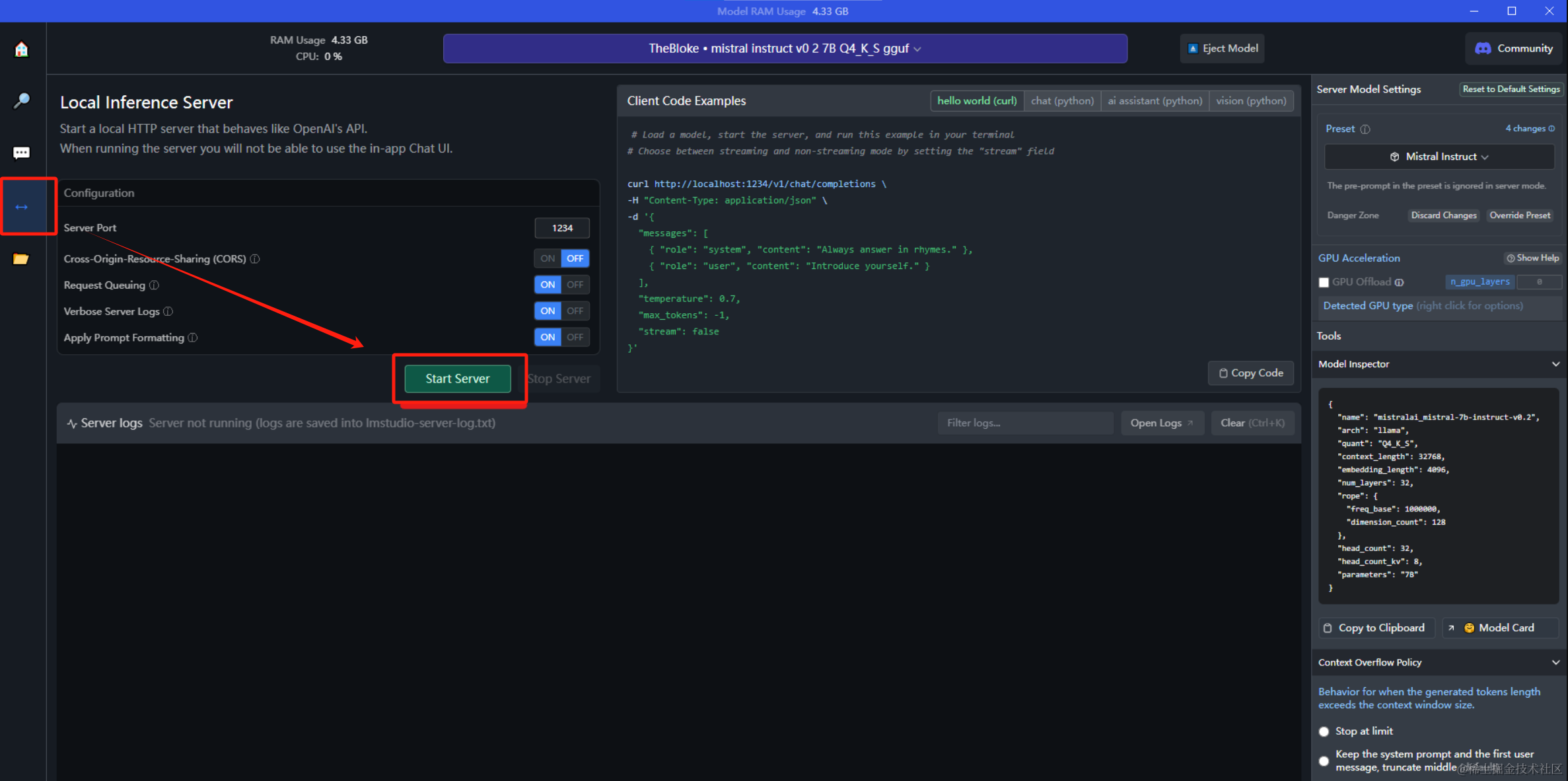
Linux部署LM Studio
进入LM Studio官网,点击【Download LM Studio for Linux】,不过这里似乎只支持Beta版本的,查了一下文档,只适配Linux (x86, Ubuntu 22.04, AVX2) ,其他Linux系统可能会出现兼容性问题:
又是漫长的等待。。。结果下了一多个小时还是没有下完。。。中途还提示一次Failed,晕。。
本来还是想秉持着探索精神去尝试的,但是无奈真的被科学上网劝退了,至于Linux下的安装和启动方式,在Ubuntu里也是可以通过可视化的方式去操作的,所以与上述Windows差别不大,这里暂且略过吧,如有兴趣的小伙伴可以挂梯子去尝试下载安装部署。
LM Studio本地大模型下载设置
通过上述实践我们也可以看到,不管是LM Studio工具本身的下载还是内置大模型的下载,其实都是需要翻墙的,没有办法在日常网络环境中直接快速使用,但是,我们仍然可以通过其他的方式来下载大模型并导入到LM Studio中使用。
下面提供两种方案:
- 从国内的模型站下载,魔塔社区:ModelScope魔搭社区 。
- 使用VScode修改 huggingface.co链接替换为国内镜像 hf-mirror.com就可以查找下载大模型镜像。
从魔塔社区下载
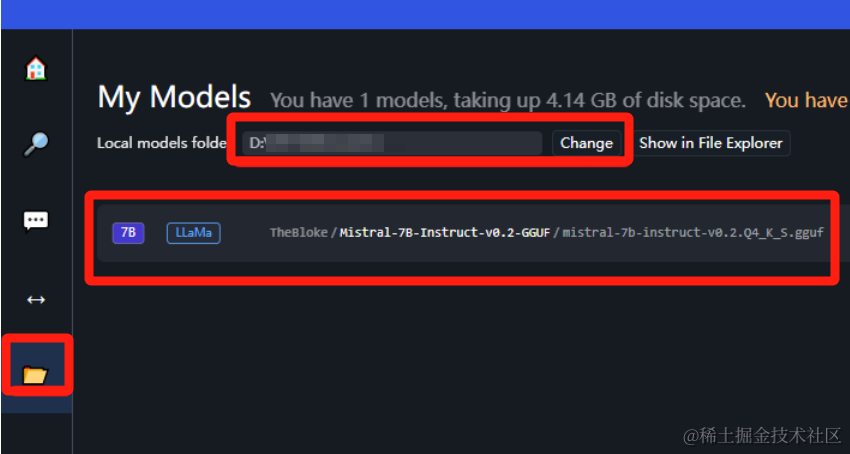
进入魔塔社区:ModelScope魔搭社区。
模型下载好之后,复制到目录所在位置即可在下方识别出来:
修改js文件中的默认下载路径
进入目录,如下所示:
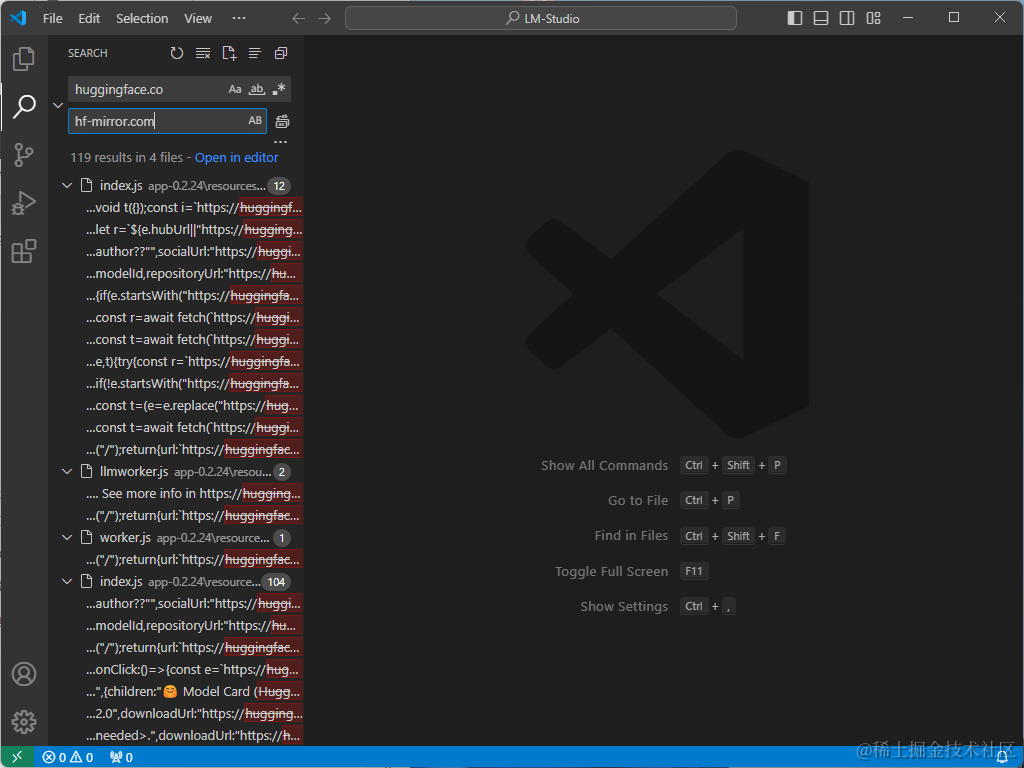
右键app-0.2.23,使用VS Code打开,然后把里面的huggingface.co链接替换为hf-mirror.com:
再次重启LM Studio,就可以搜索下载LLM大模型了。

小结
如果从工具本身的能力出发,我认为这款工具是强于Ollama的。首先说一下模型数量,LM Studio内部模型下载的主要来源是Hugging Face Hub,模型数量非常多,即便是对比Ollama的话整体数量也是偏多的。
第二点就是我个人非常喜欢的可视化界面以及模型对话时的负载设置。
相比于Ollama,LM Studio提供了更直观易用的界面,点击下载按钮即可一键进行模型的安装部署。
同时在模型负载设置这一块,LM Studio也做的更好,比如:正常来说默认是计算机的CPU完成所有工作,但如果安装了GPU,将在这里看到它。如果GPU显存不够,就可以将GPU想要处理多少层(从10-20开始)进行设置,然后这一部分层就会使用GPU处理了,这与llama.cpp的参数是一样的。还可以选择增加LLM使用的CPU线程数。默认值是4。这个也是需要根据本地计算机进行设置。
唯一美中不足的,就是需要科学上网才能下载该工具和工具内模型,不过通过上述换源的方式,这一问题也算得以解决。
整体对比,LM Studio和Ollama是各有千秋:
- 从功能丰富度和性能优化的角度综合评估,LM Studio明显更胜一筹。
- 从工具本身使用及模型部署效率来看,Ollama的上手速度会更快,使用会更便捷,效率也会更高。
所以我这里也斗胆得出如下结论:
- LM Studio更适合那些寻求快速原型设计、多样化实验以及需要高效模型管理的开发者和研究人员。
- Ollama更适合那些偏好轻量级解决方案、重视快速启动和执行效率的用户,适合小型项目或对环境要求不复杂的应用场景。
Xinference
Xinference 支持两种方式的安装,一种是使用 Docker 镜像安装,另外一种是直接本地源码进行安装。个人建议,如果在windows环境中最好采用源码安装,Linux环境中可以采用Docker来安装。
Windows 安装 Xinference
首先我们需要准备一个 3.9 以上的 Python 环境运行来 Xinference,建议先根据 conda 官网文档安装 conda。 然后使用以下命令来创建 3.11 的 Python 环境:
conda create --name xinference python=3.10
conda activate xinference
- 1
- 2
安装 pytorch
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
- 1
安装 llama_cpp_python
pip install https://github.com/abetlen/llama-cpp-python/releases/download/v0.2.55/llama_cpp_python-0.2.55-cp310-cp310-win_amd64.whl
- 1
安装 chatglm-cpp
pip install https://github.com/li-plus/chatglm.cpp/releases/download/v0.3.1/chatglm_cpp-0.3.1-cp310-cp310-win_amd64.whl
- 1
安装 Xinference
pip install "xinference[all]"
- 1
如有需要,也可以安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端(可选):
pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[transformers,vllm]" # 同时安装
#或者一次安装所有的推理后端引擎
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
- 2
- 3
- 4
- 5
设置 model 路径
在电脑上设置环境变量,路径请根据各自环境修改。
XINFERENCE_HOME=D:\XinferenceCache
- 1
不过同样,这里也面临着科学上网的问题,Xinference 模型下载缺省是从Huggingface官方网站下载 https://huggingface.co/models 。在国内因为网络原因,可以通过下面的环境变量设计为其它镜像网站:
HF_ENDPOINT=https://hf-mirror.com.
- 1
或者直接设置为:ModelScope:
通过环境变量"XINFERENCE_MODEL_SRC"设置。
XINFERENCE_MODEL_SRC=modelscope.
- 1
另外,可以通过环境变量XINFERENCE_HOME设置运行时缓存文件主目录。
export HF_ENDPOINT=https://hf-mirror.com
export XINFERENCE_MODEL_SRC=modelscope
export XINFERENCE_HOME=/jppeng/app/xinference
可以设置环境变量,临时启作用,或者设置在用户环境变量中,登陆即自动生效。
- 1
- 2
- 3
- 4
启动 Xinference
xinference-local -H 0.0.0.0或<your_ip>
- 1
Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。
启动成功后,我们可以通过地址 http://localhost:9777 来访问 Xinference 的 WebGUI 界面了。
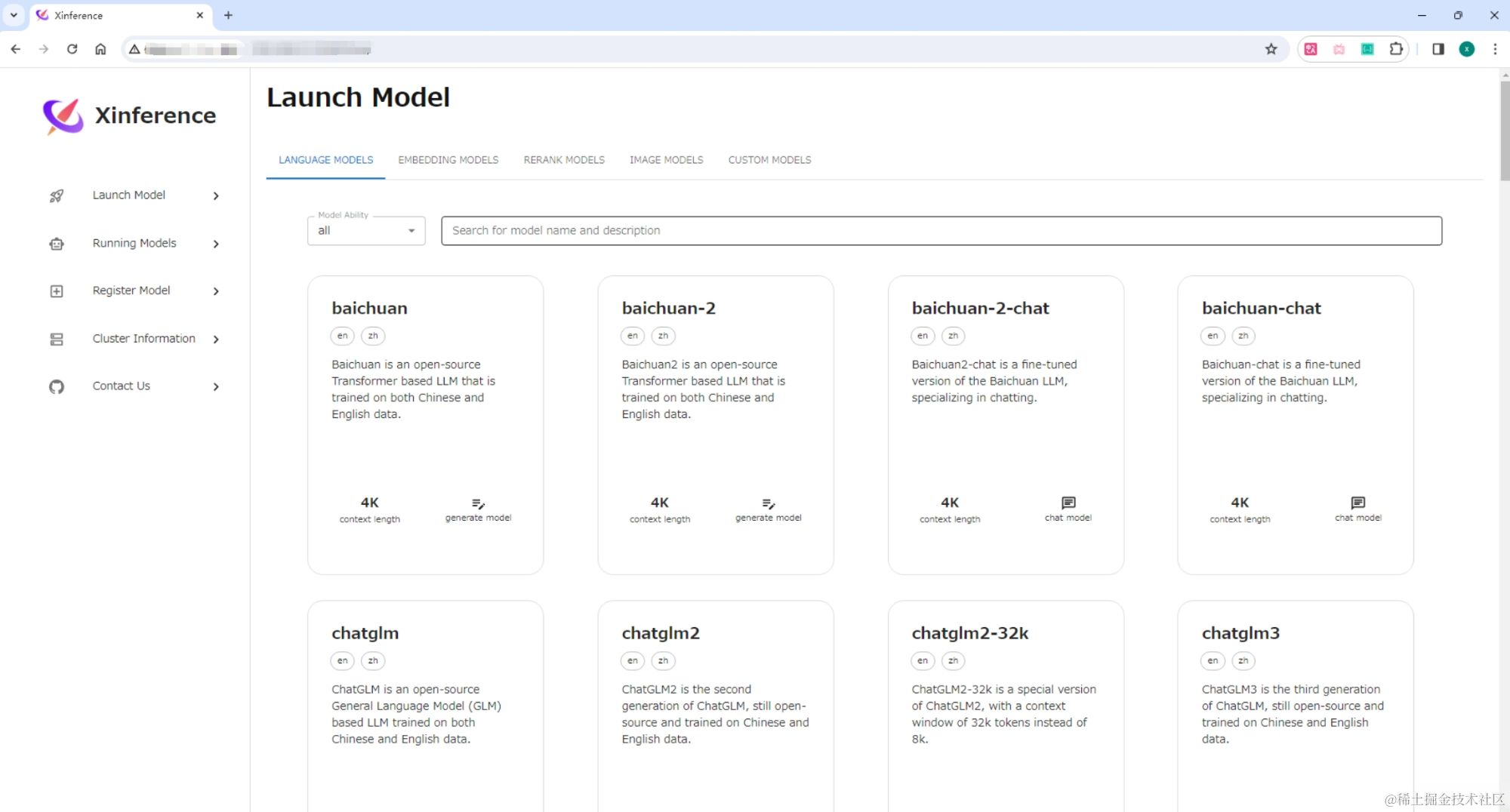
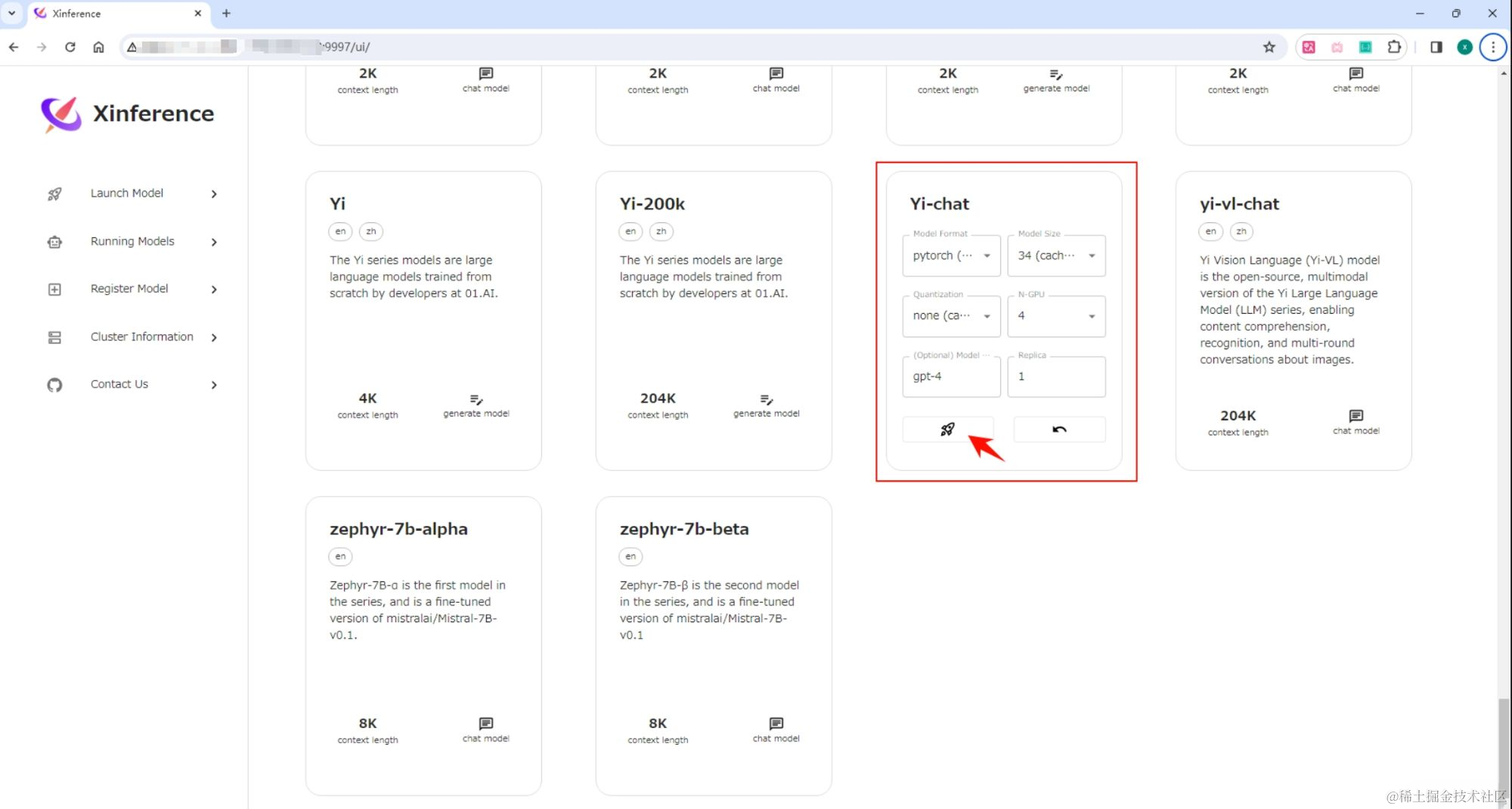
打开“Launch Model”标签,搜索到 Yi-chat,选择模型启动的相关参数,然后点击模型卡片左下方的小火箭 按钮,就可以部署该模型到 Xinference。 默认 Model UID 是 Yi-chat(后续通过将通过这个 ID 来访问模型)。

当第一次启动 Yi-chat 模型时,Xinference 会从 HuggingFace 下载模型参数,大概需要几分钟的时间。Xinference 将模型文件缓存在本地,这样之后启动时就不需要重新下载了。

点击该下载好的模型。
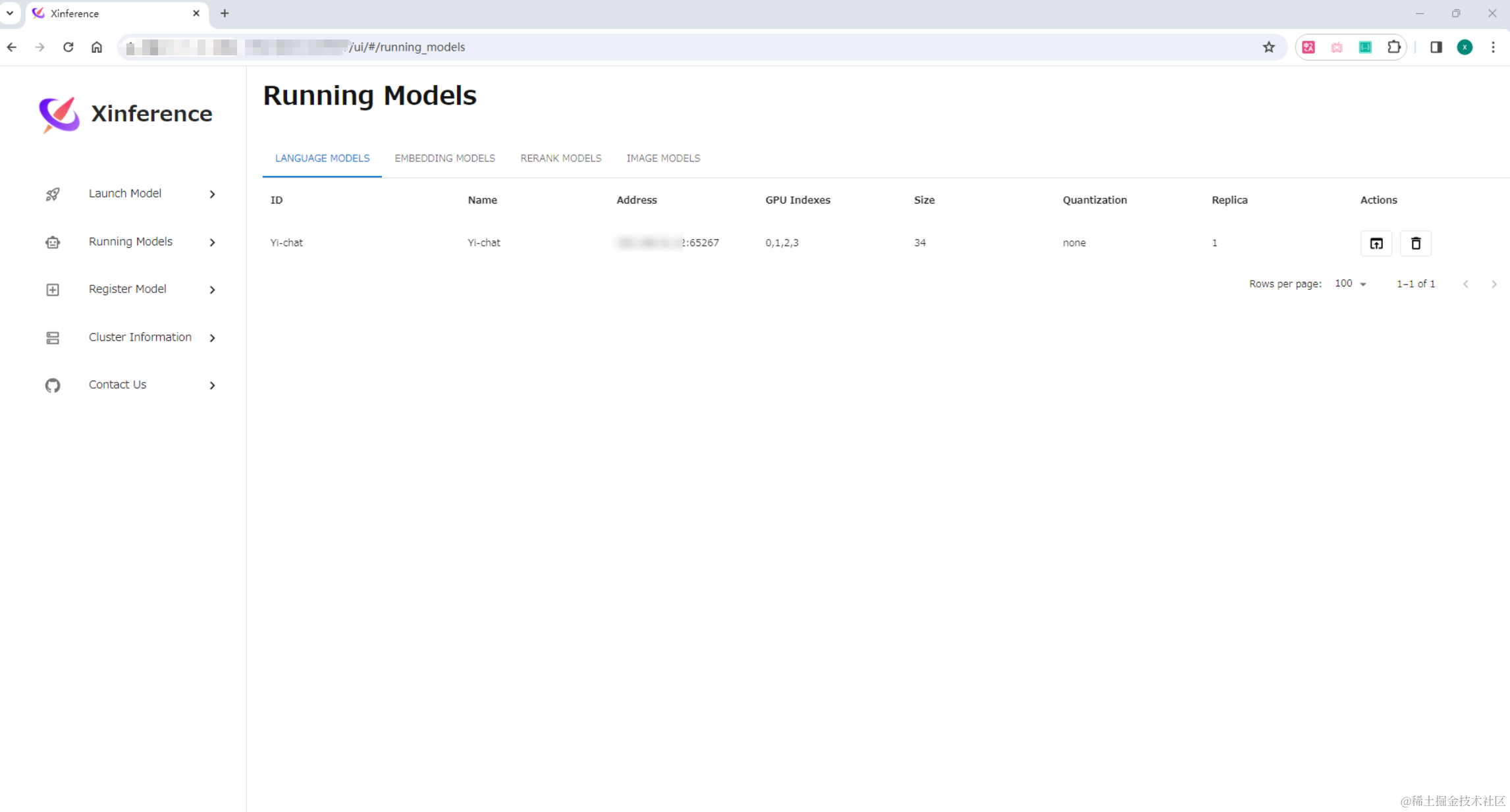
运行成功后,在 “Running Models” 页面可以查看。
Linux 安装 Xinference
在Linux下个人更推荐docker安装,这里需要准备两个前提,确保机器上已经安装了 Docker 和 CUDA。
docker一键安装 Xinference 服务。
docker pull xprobe/xinference:latest
- 1

docker启动 Xinference 服务
docker run -it --name xinference -d -p 9997:9997 -e XINFERENCE_MODEL_SRC=modelscope -e XINFERENCE_HOME=/workspace -v /yourworkspace/Xinference:/workspace --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
- 1
- -e XINFERENCE_MODEL_SRC=modelscope:指定模型源为modelscope,默认为hf
- -e XINFERENCE_HOME=/workspace:指定docker容器内部xinference的根目录
- -v /yourworkspace/Xinference:/workspace:指定本地目录与docker容器内xinference根目录进行映射
- –gpus all:开放宿主机全部GPU给container使用
- xprobe/xinference:latest:拉取dockerhub内xprobe发行商xinference项目的最新版本
- xinference-local -H 0.0.0.0:container部署完成后执行该命令
部署完成后访问IP:9997即可。
Xinference使用
Xinference接口
在 Xinference 服务部署好的时候,WebGUI 界面和 API 接口已经同时准备好了,在浏览器中访问http://localhost:9997/docs/就可以看到 API 接口列表。
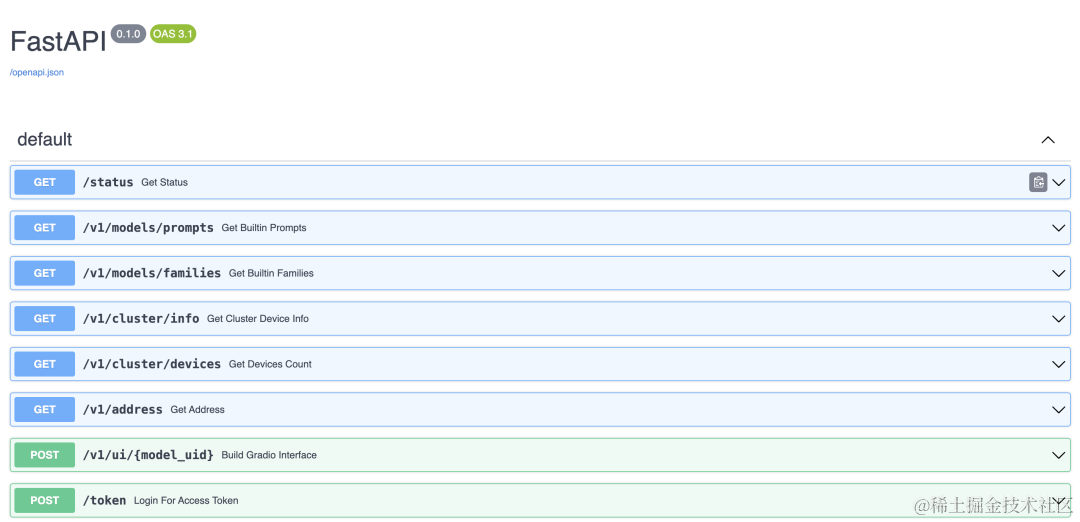
接口列表中包含了大量的接口,不仅有 LLM 模型的接口,还有其他模型(比如 Embedding 或 Rerank )的接口,而且这些都是兼容 OpenAI API 的接口。以 LLM 的聊天功能为例,我们使用 Curl 工具来调用其接口,示例如下:
curl -X 'POST' \ 'http://localhost:9997/v1/chat/completions' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "chatglm3", "messages": [ { "role": "user", "content": "hello" } ] }' # 返回结果 { "model": "chatglm3", "object": "chat.completion", "choices": [ { "index": 0, "message": { "role": "assistant", "content": "Hello! How can I help you today?", }, "finish_reason": "stop" } ], "usage": { "prompt_tokens": 8, "total_tokens": 29, "completion_tokens": 37 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
Xinference多模态模型
多模态模型是指可以识别图片的 LLM 模型,部署方式与 LLM 模型类似。
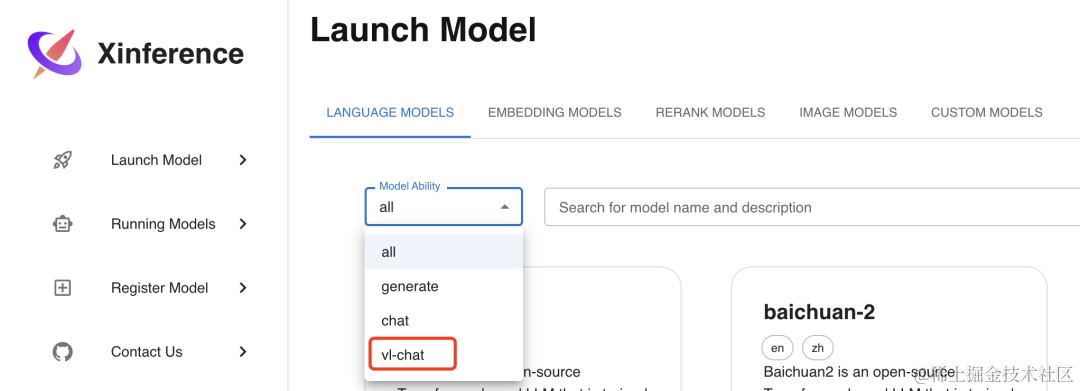
首先选择Launch Model菜单,在LANGUAGE MODELS标签下的模型过滤器Model Ability中选择vl-chat,可以看到目前支持的 2 个多模态模型:
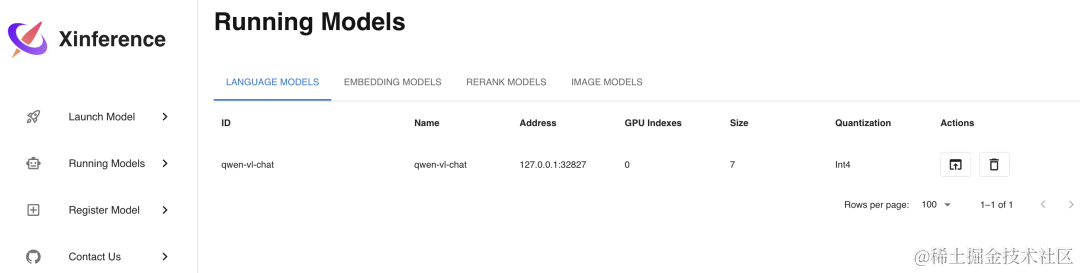
选择qwen-vl-chat这个模型进行部署,部署参数的选择和之前的 LLM 模型类似,选择好参数后,同样点击左边的火箭图标按钮进行部署,部署完成后会自动进入Running Models菜单,显示如下:
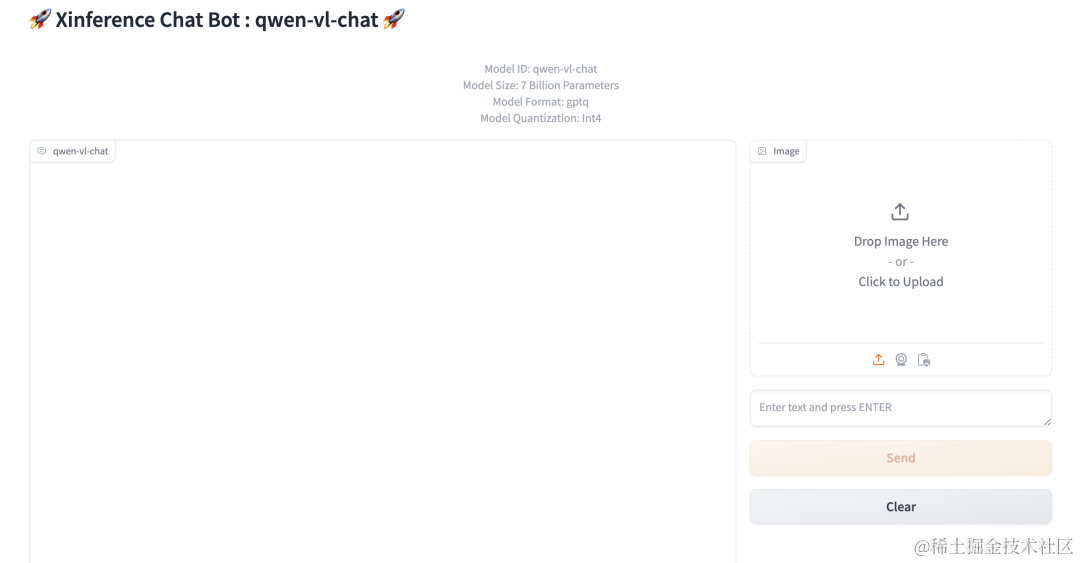
点击图中Launch Web UI的按钮,浏览器会弹出多模态模型的 Web 界面,在这个界面中,你可以使用图片和文字与多模态模型进行对话,界面如下:
XinferenceEmbedding 模型
Embedding 模型是用来将文本转换为向量的模型,使用 Xinference 部署的话更加简单,只需要在Launch Model菜单中选择Embedding标签,然后选择相应模型,不像 LLM 模型一样需要选择参数,只需直接部署模型即可,这里我们选择部署bge-base-en-v1.5这个 Embedding 模型。
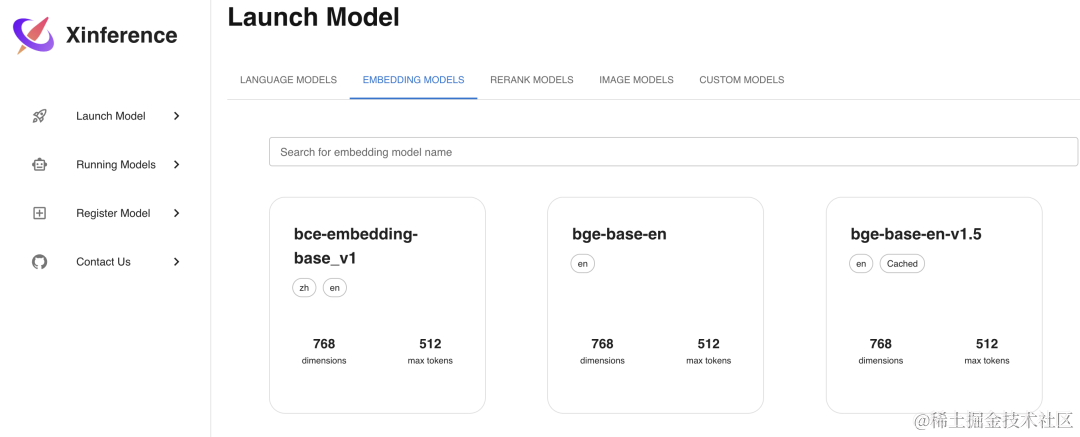
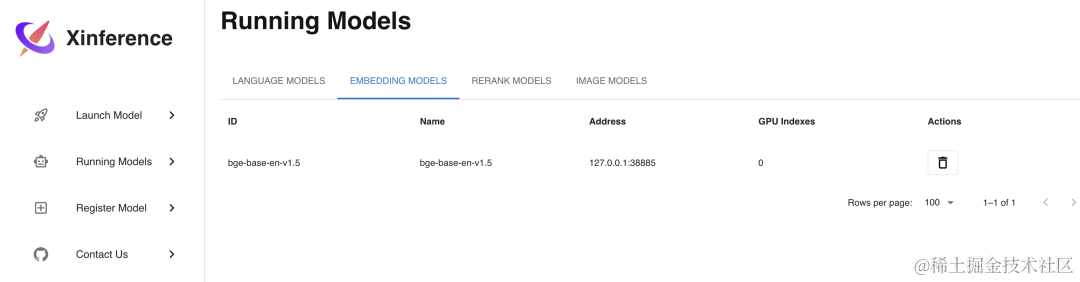
我们通过 Curl 命令调用 API 接口来验证部署好的 Embedding 模型:
curl -X 'POST' \ 'http://localhost:9997/v1/embeddings' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "bge-base-en-v1.5", "input": "hello" }' # 显示结果 { "object": "list", "model": "bge-base-en-v1.5-1-0", "data": [ { "index": 0, "object": "embedding", "embedding": [0.0007792398682795465, …] } ], "usage": { "prompt_tokens": 37, "total_tokens": 37 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Xinference Rerank 模型
Rerank 模型是用来对文本进行排序的模型,使用 Xinference 部署的话也很简单,方法和 Embedding 模型类似,部署步骤如下图所示,这里我们选择部署bge-reranker-base这个 Rerank 模型:
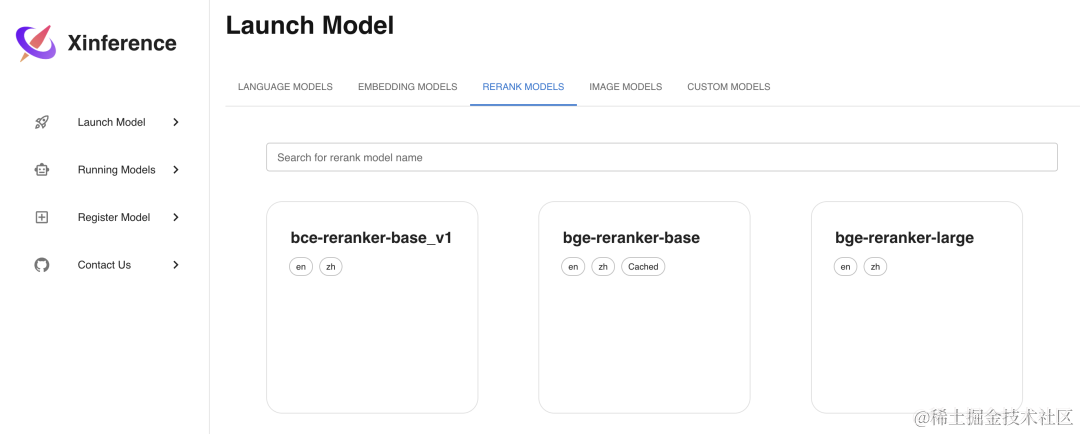
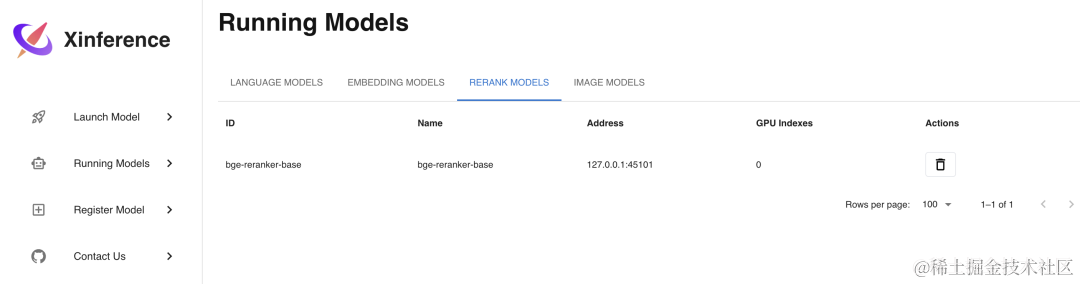
curl -X 'POST' \ 'http://localhost:9997/v1/rerank' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "bge-reranker-base", "query": "What is Deep Learning?", "documents": [ "Deep Learning is ...", "hello" ] }' # 显示结果 { "id": "88177e80-cbeb-11ee-bfe5-0242ac110007", "results": [ { "index": 0, "relevance_score": 0.9165927171707153, "document": null }, { "index": 1, "relevance_score": 0.00003880404983647168, "document": null } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
Xinference 注意事项
Xinference 默认是从 HuggingFace 上下载模型,如果需要使用其他网站下载模型,可以通过设置环境变量XINFERENCE_MODEL_SRC来实现,使用以下代码启动 Xinference 服务后,部署模型时会从Modelscope上下载模型:
XINFERENCE_MODEL_SRC=modelscope xinference-local
- 1
在 Xinference 部署模型的过程中,如果你的服务器只有一个 GPU,那么你只能部署一个 LLM 模型或多模态模型或图像模型或语音模型,因为目前 Xinference 在部署这几种模型时只实现了一个模型独占一个 GPU 的方式,如果你想在一个 GPU 上同时部署多个以上模型,就会遇到这个错误:No available slot found for the model。
但如果是 Embedding 或者 Rerank 模型的话则没有这个限制,可以在同一个 GPU 上部署多个模型。
小结
Xinference在基础配置功能上也是毫不含糊,相比于LM studio的界面更加简洁清爽,在模型库方面同样也是下载自Hugging Face Hub,同样也是需要科学上网或者修改下载源。
但有两个比较大的优势就是:Xinference的显存管理能力还比较好,服务挂掉可以自动重启,具有较高的稳定性。其次是支持集群模式部署,可以保证大模型的高可用。
大模型侧工具安装部署总结
由于作者的眼界、精力和能力也有限,并且确实也不是专业的AI研究员,仅仅是一位兴趣使然的爱好者,这里列出的几款也单纯只是作者平常关注到的,所以可能也不全,请各位见谅!
文章从起笔写到这里已经过了三天了,这三天也基本把上文提到的大模型侧工具全部体验了一遍,下面说一下主要结论吧。
就这三个工具而言,确实也是各有千秋:
- 从功能丰富度和性能优化的角度综合评估,LM Studio明显更胜一筹。
- 从工具本身使用及模型部署效率来看,Ollama的上手速度会更快,使用会更便捷,效率也会更高。
- 从企业级稳定性和高可用来看,Xinference支持分布式部署,并且可以故障自动拉起。
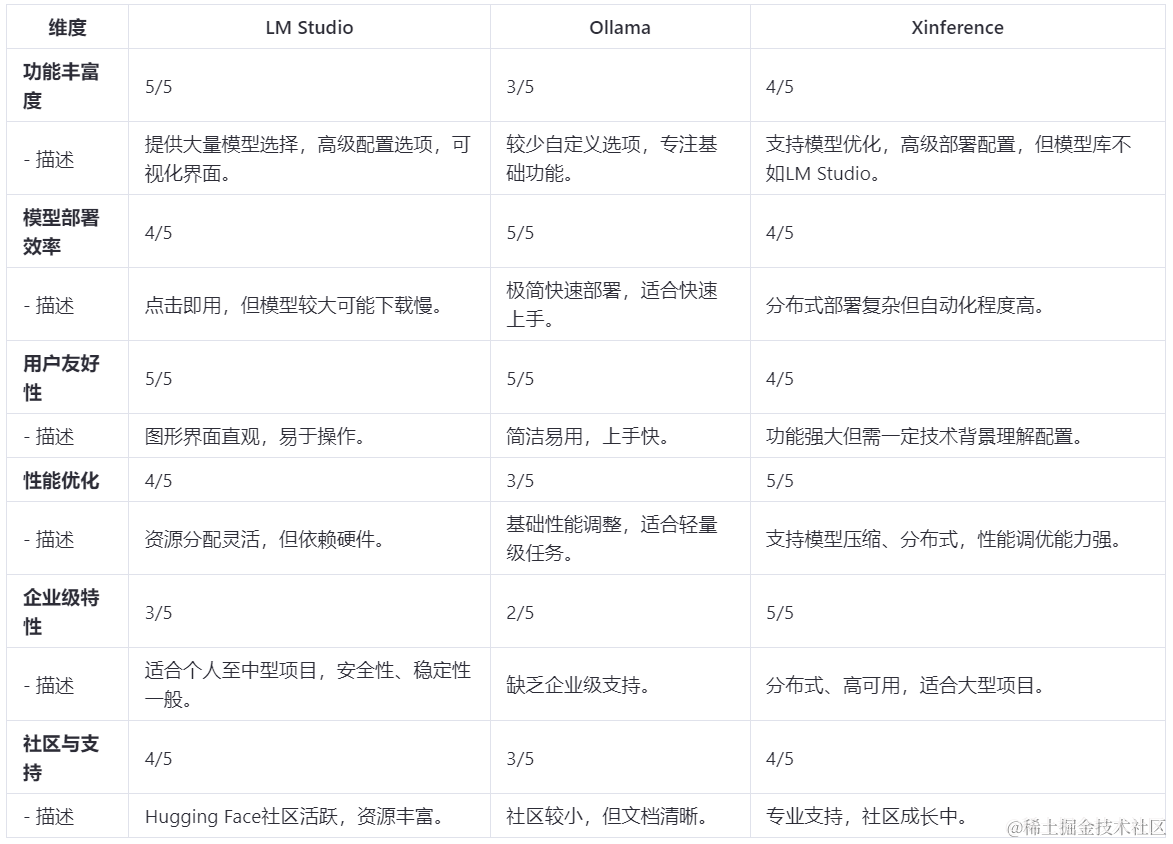
【注】:评分标准为1-5分,5分为最高。
对于AI小白来说(完全不懂AI,不知道大模型是什么具体含义,完全不知道怎么下载模型),选择Ollama来管理和下载模型是保证没有问题的,体验感确实拉满了。
对于一些开发者和研究员而言,我觉得可以在LM Studio和Xinference中任选其一,如果是个人实验的话,我倾向于推荐LM Studio;如果是企业级内部或者中大型项目需要的话,我建议还是采用Xinference。
除了上述提到的之外可能也还有一些比较好用的大模型管理工具是周周没有接触过的,也请小伙伴们积极指出~
随着AI技术的飞速发展,新的工具和服务也会不断涌现,本文截止至2024年6月9日,请各位选择最适合自己需求的工具,这将有助于提升工作效率,推动项目的成功。
记住,没有绝对最好,只有最适合当前情境的工具。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

