

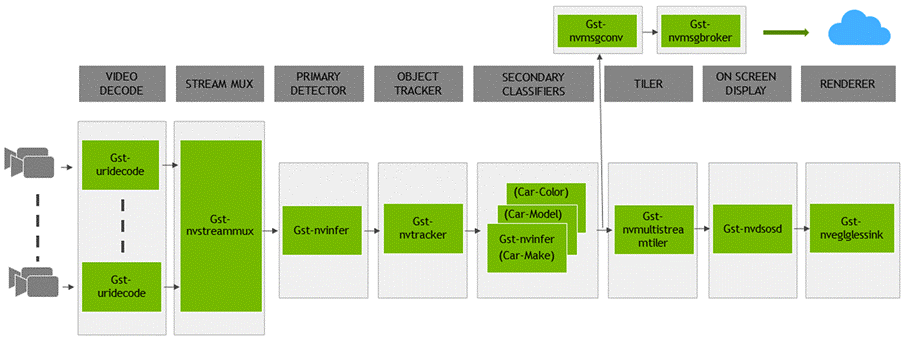

5.3.5 初级 GIE 和次级 GIE 组
DeepStream 应用程序支持多个辅助 GIE。对于每个辅助 GIE,secondary-gie%d必须将具有名称的单独组添加到配置文件中。例如:
[primary-gie]
key1=value1
key2=value2
...
[secondary-gie1]
key1=value1
key2=value2
...
主要和次要 GIE 配置如下。对于每个配置,Valid for 列指示配置属性是对主要还是次要 TensorRT 模型有效,还是对两个模型都有效。
小学和中学 GIE* 组 钥匙
意义
类型和值
例子
平台/ GIE*
使能够
指示是否必须启用主 GIE。
布尔值
启用=1
dGPU,Jetson 两个 GIE
唯一标识
要分配给 nvinfer 实例的唯一组件 ID。用于标识实例生成的元数据。
整数,>0
gie-unique-id = 2
两个都
gpu-id
在多个 GPU 的情况下,元素将使用 GPU。
整数,≥0
gpu-id=1
dGPU,两个 GIE
模型引擎文件
模式的预生成序列化引擎文件的绝对路径名。
细绳
模型引擎文件=../../models/Primary_Detector/resnet10. caffemodel_b4_int8.engine
两个 GIE
nvbuf 内存类型
CUDA 内存元素的类型是分配给输出缓冲区。
0 (nvbuf-mem-default):特定于平台的默认值
1 (nvbuf-mem-cuda-pinned): pinned/host CUDA 内存
2(nvbuf-mem-cuda-device):设备CUDA内存
3(nvbuf-mem-cuda-unified):统一CUDA内存
对于 dGPU:所有值均有效。
对于 Jetson:只有 0(零)有效。
整数、0、1、2 或 3
nvbuf-内存类型=3
dGPU,Jetson 初级 GIE
配置文件
指定 Gst-nvinfer 插件属性的配置文件的路径名。它可能包含此表中描述的任何属性,但配置文件本身除外。属性必须在名为 [property] 的组中定义。有关参数的更多详细信息,请参阅 DeepStream 4.0 插件手册中的“Gst-nvinfer 文件配置规范”。
细绳
config-file=¬/home/-ubuntu/-config_infer_resnet.txt 有关完整示例,请参阅示例文件 samples/¬configs/-deepstream-app/-config_infer_resnet.txt 或 deepstream-test2 示例应用程序。
dGPU,Jetson 两个 GIE
批量大小
批量推断的帧数(P.GIE)/对象(S.GIE)。
整数,>0 整数,>0
批量大小=2
dGPU,Jetson 两个 GIE
间隔
要跳过以进行推理的连续批次数。
整数,>0 整数,>0
间隔=2
dGPU,Jetson 初级 GIE
bbox边框颜色
特定类 ID 的对象的边框颜色,以 RGBA 格式指定。密钥的格式必须为 bbox-border-color<class-id>。可以为多个类 ID 多次标识此属性。如果未为类 ID 标识此属性,则不会为该类 ID 的对象绘制边框。
R:G:B:A 浮点数,0≤R,G,B,A≤1
bbox-border-color2= 1;0;0;1(红色表示类 ID 2)
dGPU,Jetson 两个 GIE
bbox-bg-颜色
在特定类 ID 的对象上绘制的框的颜色,采用 RGBA 格式。密钥的格式必须为 bbox-bg-color<class-id>。此属性可以多次用于多个类 ID。如果它不用于类 ID,则不会为该类 ID 的对象绘制框。
R:G:B:A 浮点数,0≤R,G,B,A≤1
bbox-bg-color3=-0;1;0;0.3(class-id 3 的半透明绿色)
dGPU,Jetson 两个 GIE
操作 gie-id
GIE 的唯一 ID,此 GIE 将在其元数据 (NvDsFrameMeta) 上运行。
整数,>0
操作 gie-id=1
dGPU,Jetson 二级 GIE
操作类 ID
此 GIE 必须在其上运行的父 GIE 的类 ID。使用 operation-on-gie-id 指定父 GIE。
分号分隔的整数数组
operation-on-class-ids=1;2(对父 GIE 生成的类 ID 为 1、2 的对象进行操作)
dGPU,Jetson 二级 GIE
推断原始输出目录
将原始推理缓冲区内容转储到文件中的现有目录的路径名。
细绳
infer-raw-output-dir=/home/ubuntu/infer_raw_out
dGPU,Jetson 两个 GIE
标签文件路径
标签文件的路径名。
细绳
labelfile-path=../../models/Primary_Detector/labels.txt
dGPU,Jetson 两个 GIE
插件类型
用于推理的插件。0:nvinfer(TensorRT) 1:nvinferserver(Triton 推理服务器)
整数,0 或 1
插件类型=1
dGPU,Jetson 两个 GIE

