
- 1机器周期、振荡周期、时钟周期、状态周期???_时钟周期等于几个震荡周期
- 2[数据结构 3] 十大经典排序算法_数据结构-十大经典排序算法
- 3STM32F103—有关陶晶驰串口屏的串口使用代码_淘晶驰串口屏和stm32
- 4推荐8款好用的Python库,助你成为编程大师!_好用的python库推荐
- 5AI 对IT行业的影响_近5年来最新ai技术发展对计算机领域有何影响
- 6零基础5分钟上手亚马逊云科技AWS核心云架构知识 - 为应用配置自动扩展
- 7用 Python 送“爱心”
- 8用Python给学弟准备追女神要用的多种流行的表白爱心代码【源码】_python爱心代码
- 9【LangChain系列教程】AI大模型应用开发——实战操作LangChain智能体Agents模块_如何通过langchain建立自己的ai agent
- 10Python中实现数据库和Excel的导入导出_python excel 导入 sqlite
IK分词器---Elasticsearch(standard、ik_smart、ik_max_word、拓展词典---ik_max_word)
赞
踩
IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。

1.4.1.安装IK分词器
方案一:在线安装
运行一个命令即可:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
- 1
然后重启es容器:
docker restart es
- 1
方案二:离线安装

如果网速较差,也可以选择离线安装。
首先,查看之前安装的Elasticsearch容器的plugins数据卷目录:
docker volume inspect es-plugins
- 1
结果如下:
[
{
"CreatedAt": "2024-11-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
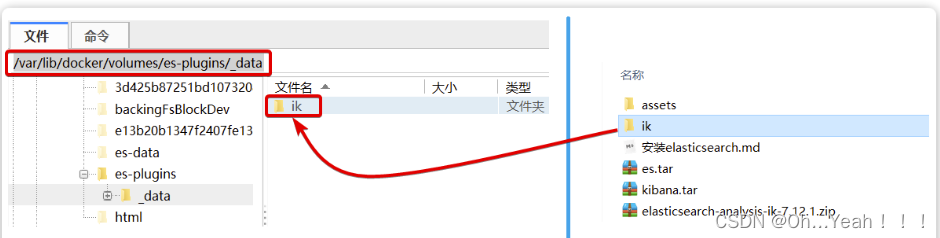
可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。我们需要把IK分词器上传至这个目录。
找到课前资料提供的ik分词器插件,课前资料提供了7.12.1版本的ik分词器压缩文件,你需要对其解压:
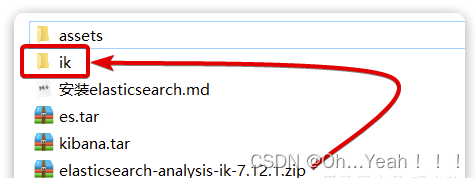
然后上传至虚拟机的/var/lib/docker/volumes/es-plugins/_data这个目录:
最后,重启es容器:
docker restart es
- 1
1.4.2.使用IK分词器(standard、ik_smart、ik_max_word)
IK分词器包含两种模式:
ik_smart:智能语义切分ik_max_word:最细粒度切分
我们在Kibana的DevTools上来测试分词器,首先测试Elasticsearch官方提供的标准分词器:
POST /_analyze
{
"analyzer": "standard",
"text": "真知程序员学习java太棒了"
}
- 1
- 2
- 3
- 4
- 5

结果如下:
{ "tokens" : [ { "token" : "真", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "知", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "程", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "序", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "员", "start_offset" : 4, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 4 }, { "token" : "学", "start_offset" : 5, "end_offset" : 6, "type" : "<IDEOGRAPHIC>", "position" : 5 }, { "token" : "习", "start_offset" : 6, "end_offset" : 7, "type" : "<IDEOGRAPHIC>", "position" : 6 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "太", "start_offset" : 11, "end_offset" : 12, "type" : "<IDEOGRAPHIC>", "position" : 8 }, { "token" : "棒", "start_offset" : 12, "end_offset" : 13, "type" : "<IDEOGRAPHIC>", "position" : 9 }, { "token" : "了", "start_offset" : 13, "end_offset" : 14, "type" : "<IDEOGRAPHIC>", "position" : 10 } ] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
可以看到,标准分词器智能1字1词条,无法正确对中文做分词。
我们再测试IK分词器:
POST /_analyze
{
"analyzer": "ik_smart",
"text": "真知程序员学习java太棒了"
}
- 1
- 2
- 3
- 4
- 5
执行结果如下:
{ "tokens" : [ { "token" : "真知", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "程序员", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 1 }, { "token" : "学习", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 2 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "ENGLISH", "position" : 3 }, { "token" : "太棒了", "start_offset" : 11, "end_offset" : 14, "type" : "CN_WORD", "position" : 4 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
我们再测试IK分词器:
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "真知程序员学习java太棒了"
}
- 1
- 2
- 3
- 4
- 5
执行结果如下:
{ "tokens" : [ { "token" : "真知", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "程序员", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 1 }, { "token" : "程序", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "员", "start_offset" : 4, "end_offset" : 5, "type" : "CN_CHAR", "position" : 3 }, { "token" : "学习", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 4 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "ENGLISH", "position" : 5 }, { "token" : "太棒了", "start_offset" : 11, "end_offset" : 14, "type" : "CN_WORD", "position" : 6 }, { "token" : "太棒", "start_offset" : 11, "end_offset" : 13, "type" : "CN_WORD", "position" : 7 }, { "token" : "了", "start_offset" : 13, "end_offset" : 14, "type" : "CN_CHAR", "position" : 8 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
1.4.3.拓展词典(ik_max_word)
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“泰裤辣”,“传智播客” 等。
IK分词器无法对这些词汇分词,测试一下:
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "真知博客开设大学,真的泰裤辣!"
}
- 1
- 2
- 3
- 4
- 5
结果:
{ "tokens" : [ { "token" : "真", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { "token" : "知", "start_offset" : 1, "end_offset" : 2, "type" : "CN_CHAR", "position" : 1 }, { "token" : "播", "start_offset" : 2, "end_offset" : 3, "type" : "CN_CHAR", "position" : 2 }, { "token" : "客", "start_offset" : 3, "end_offset" : 4, "type" : "CN_CHAR", "position" : 3 }, { "token" : "开设", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 4 }, { "token" : "大学", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 5 }, { "token" : "真的", "start_offset" : 9, "end_offset" : 11, "type" : "CN_WORD", "position" : 6 }, { "token" : "泰", "start_offset" : 11, "end_offset" : 12, "type" : "CN_CHAR", "position" : 7 }, { "token" : "裤", "start_offset" : 12, "end_offset" : 13, "type" : "CN_CHAR", "position" : 8 }, { "token" : "辣", "start_offset" : 13, "end_offset" : 14, "type" : "CN_CHAR", "position" : 9 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
可以看到,真知博客和泰裤辣都无法正确分词。
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
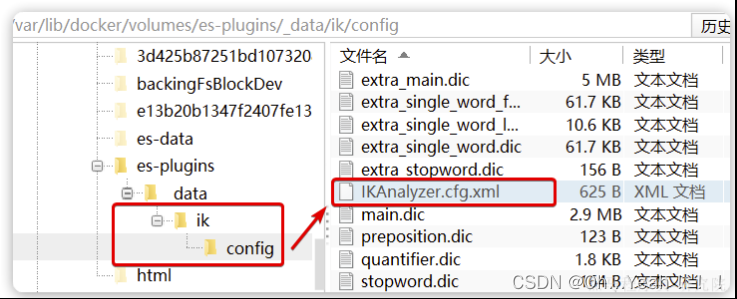
注意,如果采用在线安装的通过,默认是没有config目录的,需要把课前资料提供的ik下的config上传至对应目录。
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3)在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
真知博客
泰裤辣
Oh...Yeah!!!
- 1
- 2
- 3
然后修改stopword.dic文件
a an and are as at be but by for if in into is it no not of on or such that the their then there these they this to was will with 啦 啊 哦 呀 的 了
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
最后将修改后的文件覆盖之前的文件即可
4)重启elasticsearch
docker restart es
# 查看 日志
docker logs -f elasticsearch
- 1
- 2
- 3
- 4
再次测试,可以发现真知博客和泰裤辣都正确分词了:
{ "tokens" : [ { "token" : "真知播客", "start_offset" : 0, "end_offset" : 4, "type" : "CN_WORD", "position" : 0 }, { "token" : "开设", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 1 }, { "token" : "大学", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 2 }, { "token" : "真的", "start_offset" : 9, "end_offset" : 11, "type" : "CN_WORD", "position" : 3 }, { "token" : "泰裤辣", "start_offset" : 11, "end_offset" : 14, "type" : "CN_WORD", "position" : 4 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
其他测试
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "真知程序员来自于真知播客,网上课程学习java太棒了,真是泰裤辣,Oh...Yeah!!!"
}
- 1
- 2
- 3
- 4
- 5
返回结果也比较Ok
{ "tokens" : [ { "token" : "真知", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "程序员", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 1 }, { "token" : "程序", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "员", "start_offset" : 4, "end_offset" : 5, "type" : "CN_CHAR", "position" : 3 }, { "token" : "来自于", "start_offset" : 5, "end_offset" : 8, "type" : "CN_WORD", "position" : 4 }, { "token" : "来自", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 5 }, { "token" : "于", "start_offset" : 7, "end_offset" : 8, "type" : "CN_CHAR", "position" : 6 }, { "token" : "真知播客", "start_offset" : 8, "end_offset" : 12, "type" : "CN_WORD", "position" : 7 }, { "token" : "网上", "start_offset" : 13, "end_offset" : 15, "type" : "CN_WORD", "position" : 8 }, { "token" : "上课", "start_offset" : 14, "end_offset" : 16, "type" : "CN_WORD", "position" : 9 }, { "token" : "课程", "start_offset" : 15, "end_offset" : 17, "type" : "CN_WORD", "position" : 10 }, { "token" : "学习", "start_offset" : 17, "end_offset" : 19, "type" : "CN_WORD", "position" : 11 }, { "token" : "java", "start_offset" : 19, "end_offset" : 23, "type" : "ENGLISH", "position" : 12 }, { "token" : "太棒了", "start_offset" : 23, "end_offset" : 26, "type" : "CN_WORD", "position" : 13 }, { "token" : "太棒", "start_offset" : 23, "end_offset" : 25, "type" : "CN_WORD", "position" : 14 }, { "token" : "了", "start_offset" : 25, "end_offset" : 26, "type" : "CN_CHAR", "position" : 15 }, { "token" : "真是", "start_offset" : 27, "end_offset" : 29, "type" : "CN_WORD", "position" : 16 }, { "token" : "泰裤辣", "start_offset" : 29, "end_offset" : 32, "type" : "CN_WORD", "position" : 17 }, { "token" : "oh...yeah", "start_offset" : 33, "end_offset" : 42, "type" : "LETTER", "position" : 18 }, { "token" : "oh", "start_offset" : 33, "end_offset" : 35, "type" : "ENGLISH", "position" : 19 }, { "token" : "yeah", "start_offset" : 38, "end_offset" : 42, "type" : "ENGLISH", "position" : 20 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
1.4.4.总结
分词器的作用是什么?
- 创建倒排索引时,对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
ik_smart:智能切分,粗粒度ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的
IkAnalyzer.cfg.xml文件添加拓展词典和停用词典 - 在词典中添加拓展词条或者停用词条


