
- 1人脸识别--SeetaFace2介绍
- 2Android 判断网络是否可用
- 3cfar(Constant False-Alarm Rate)_cfar算子
- 4Apollo与百度文心一言联手:智能驾驶领域的协同创新_百度 文心一言和apllo
- 5基于WEB的开放式实验室管理系统的设计与实现(论文+源码)_kaic_asp源码 学生成绩智能管理系统
- 6ORA-00257:archiver error.Connect internal only,until freed._ora-00257: archiver error. connect internal only,
- 7Git可视化工具 - 推荐_gitlens
- 8基于信号分解的几种一维时间序列降噪方法(MATLAB R2021B)
- 9Maven解决找不到依赖项_maven找不到依赖项怎么办
- 10Java泛型,数据结构,List,Set详细介绍
【论文笔记】命名实体识别论文
赞
踩
其实实体识别这块看了挺久了的,今天就来好好聊一聊它。实体识别(Name Entity Recognition)是属于NLP任务中的序列标注问题:给定一个输入句子,要求为句子中的每一个token做实体标注(如人名、组织/机构、地名、日期等等)。
NER算法回顾
明白了NER任务的目的,那我们就来看看具体是怎么实现的。到目前为止,可以大致分为基于规则、基于传统机器学习方法和基于深度学习方法这三大类(其实很多任务的算法都可以从这三个方面去入手)。基于规则的方法效果可能很高,但是实在是太硬核了,很大程度上取决于个人对规则的定义,而且费时费力,基本不可取。
传统机器学习
不是今天的重点。简单介绍一下标准流程:
Training
- 获取训练数据(文本+标注)
- 设计适合该文本和类别的特征提取方法
- 训练一个类别分类器来预测每个token的label
Predicting
- 获取测试数据
- 运行训练好的模型给每个token做标注
- 输出实体
深度学习方法
也不是今天的重点。最经典最sate-of-the-art的模型就是LSTM+CRF(当然得除去bert这种)

paper list:
- Fast and Accurate Entity Recognition with Iterated Dilated Convolutions(2017) [paper]
- Chinese NER Using Lattice LSTM(2018)[paper]
- Adversarial Transfer Learning for Chinese Named Entity Recognition
with Self-Attention Mechanism(2018)[paper] - Adversarial Learning for Chinese NER from Crowd Annotations(2018)[paper]
- Adaptive Co-Attention Network for Named Entity Recognition in Tweets(2018)[paper]
Paper: IDCNN for NER
前面废话了那么多,赶紧开始吧。
众所周知,目前在NLP领域用的最多的还是要数RNN这一个大类,因为RNN简直就是为文本这类序列数据而生的。但是在实现中也会有很多问题,所以这时候就可能试试CNN。相对于RNN, CNN由于可以并行训练,使得其训练速度远远高与RNN,可以使得在精度不变或损失一点的情况下打打提高效率。这一点也在前面文本分类任务中有提及。 【论文复现】使用CNN进行文本分类
Fast and Accurate Entity Recognition with Iterated Dilated Convolutions(2017)这篇论文就是基于CNN类来做命名实体识别的。
传统CNN的缺陷
CNN运用于文本处理,有一个劣势,就是经过卷积之后,末层神经元可能只是得到了原始输入数据中一小部分的信息。所以为了获取上下文信息,可能就需要加入更多的卷积层,导致网络原来越深,参数越来越多,而模型越大越容易导致过拟合问题,所以就需要引入Dropout之类的正则化,带来更多的超参数,整个网络变得庞大冗杂难以训练。
Dilated CNN
基于上述问题,Multi-Scale Context Aggregation by Dilated Convolutions一文中提出了dilated convolutions,中文意思大概是“空洞卷积”。正常CNN的filter,都是作用在输入矩阵一片连续的位置上,不断sliding做卷积,接着通过pooling来整合多尺度的上下文信息,这种方式会损失分辨率。既然网络中加入pooling层会损失信息,降低精度。那么不加pooling层会使感受野变小,学不到全局的特征。如果我们单纯的去掉pooling层、扩大卷积核的话,这样纯粹的扩大卷积核势必导致计算量的增大,此时最好的办法就是Dilated Convolutions(扩张卷积或叫空洞卷积)。
具体使用时,dilated width会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而receptive field却是指数增加的,可以很快覆盖到全部的输入数据。
对应到文本上,输入是一维向量:
Iterated Dilated CNN
论文中提出的IDCNN模型是4个结构相同的Dilated CNN block拼接在一起,每个block里面是dilation width为1,1,2的三层DCNN。
IDCNN对输入句子的每一个字生成一个logits,这里就和biLSTM模型输出logits之后完全一样,放入CRF Layer,用Viterbi算法解码出标注结果。
在biLSTM或者IDCNN这样的深度网络模型后面接上CRF层是一个序列标注很常见的方法。biLSTM或者IDCNN计算出的是每个词分类的概率,而CRF层引入序列的转移概率,最终计算出loss反馈回网络。
关于IDCNN在NER任务的实现:
官方开源代码
超1k satr github代码
Paper: Chinese NER Using Lattice LSTM
作者首先综述了目前NER算法的主要思路,然后集中于LSTM-CRF模型分析了集中变种模型的优缺点:
- 基于词的LSTM-CRF:一般的pipeline是对文本进行分词之后embedding后输入深度网络预测序列中单词的类别标记。但是这样的话会受限于分词那一步的表现,也就是说如果分词过程效果不好的话,会进一步影响整个NER模型的误差。而对于NER任务中,许多词都是OOV;
- 基于字的LSTM-CRF:那么把词输入改为字输入是不是会有所改进呢?答案是肯定的。因为字向量可以完美克服上述分词过程引入的误差。但是如果单纯采用字向量的话会丢失句子中词语之间的内在信息。(当然基于该问题,学者们也提出了很多解决方案:例如利用segmentation information作为NER模型的soft features;使用multi-task learning等等)
Lattice LSTM 模型
基于上述问题,作者们提出了一种新型的Lattice LSTM:将潜在的词语信息融合到基于字模型的传统LSTM-CRF中去,而其中潜在的词语信息是通过外部词典获得的。如下所示,lattice lstm模型会在字向量的基础上额外获取词特征的信息。

但是上述模型中每个词语路径都考虑的话,会导致模型复杂度的指数增长,于是作者利用门结构来控制信息流动。例如,以最后一个“桥”字为例,除了需要考虑该字本身的向量特征,还需要考虑“长江大桥”和“大桥”这些词语信息的贡献量,而这个就是由图中红色圈圈代表的门结构来控制信息流入的。

在论文中,作者们还提出了自己改进过的基于字和词语的NER模型,但是这些应该都是为了最后的Lattice LSTM做铺垫的,所以这里就不做详细介绍。关于Lattice的整体模型如下:

- 模型的输入为字向量: c 1 , c 2 , . . . , c m c_1,c_2,...,c_m c1,c2,...,cm与所有与外部分词词典对应的字序列: w b , e d w_{b, e}^{d} wb,ed(表示该词语起始于句子下标b,结束于句子下标e,例如 w 7 , 8 d w_{7,8}^{d} w7,8d代表“大桥”)
- 经过Embedding层映射,其中每一个字和词被表示为:
x j c = e c ( c j ) x^c_j=e^c(c_j) xjc=ec(cj) x b , e w = e w ( w b , e d ) \mathbf{x}_{b, e}^{w}=\mathbf{e}^{w}\left(w_{b, e}^{d}\right) xb,ew=ew(wb,ed) - 然后将字表示部分送入LSTM网络训练,就是经典的那个结构
[ i j c o j c f j c c ~ j c ] = [ σ σ σ tanh ] ( W c ⊤ [ x j c h j − 1 c ] + b c ) \left[\right]=\left[icjocjfcjc~cj \right]\left(\mathbf{W}^{c \top} \left[σσσtanh \right]+\mathbf{b}^{c}\right) ⎣⎢⎢⎡ijcojcfjcc~jc⎦⎥⎥⎤=⎣⎢⎢⎡σσσtanh⎦⎥⎥⎤(Wc⊤[xjchj−1c]+bc) c j c = f j c ⊙ c j − 1 c + i j c ⊙ c ~ j c h j c = o j c ⊙ tanh ( c j c )xcjhcj−1 cjchjc=fjc⊙cj−1c+ijc⊙c jc=ojc⊙tanh(cjc)ccjhcj=fcj⊙ccj−1+icj⊙c˜cj=ocj⊙tanh(ccj) - 如果只有以上部分就仅仅与基于字向量的LSTM相同了,本文继续计算了词向量的表示:
[ i b , e w f b , e w c ~ b , e ψ ] = [ σ σ tanh ] ( W w ⊤ [ x b , e w h b c ] + b w ) \left[\right]=\left[iwb,efwb,ec˜ψb,e \right]\left(\mathbf{W}^{w \top} \left[σσtanh \right]+\mathbf{b}^{w}\right) ⎣⎡ib,ewfb,ewc b,eψ⎦⎤=⎣⎡σσtanh⎦⎤(Ww⊤[xb,ewhbc]+bw) c b , e w = f b , e w ⊙ c b c + i b , e w ⊙ c ~ b , e w \mathbf{c}_{b, e}^{w}=\mathbf{f}_{b, e}^{w} \odot \mathbf{c}_{b}^{c}+\mathbf{i}_{b, e}^{w} \odot \widetilde{\boldsymbol{c}}_{b, e}^{w} cb,ew=fb,ew⊙cbc+ib,ew⊙c b,ewxwb,ehcb
注意这里并没有输出门,因为我们的词向量只是作为一种额外特征,最终的类别标记还是从字向量那一套LSTM中获取。 - 那么我们怎么把词语信息特征加入到最终需要输出的字向量的那一套LSTM中去呢?使用了一个额外的门控制每一个词语信息对与其对应的字的贡献:
i b , e c = σ ( W l ⊤ [ x e c c b , e w ] + b l ) \mathbf{i}_{b, e}^{c}=\sigma\left(\mathbf{W}^{l \top} \left[\right]+\mathbf{b}^{l}\right) ib,ec=σ(Wl⊤[xeccb,ew]+bl)xcecwb,e - 更新我们的字向量LSTM中的状态向量:
c j c = ∑ b ∈ { b ′ ∣ w b ′ , j d ∈ D } α b , j c ⊙ c b , j w + α j c ⊙ c ~ j c \mathbf{c}_{j}^{c}=\sum_{b \in\left\{b^{\prime} | w_{b^{\prime}, j}^{d} \in \mathbb{D}\right\}} \boldsymbol{\alpha}_{b, j}^{c} \odot c_{b, j}^{w}+\boldsymbol{\alpha}_{j}^{c} \odot \tilde{c}_{j}^{c} cjc=b∈{b′∣wb′,jd∈D}∑αb,jc⊙cb,jw+αjc⊙c~jc
这里两个alpha系数是门控制输出值 i b , j c \mathbf{i}_{b, j}^{c} ib,jc和 i j c \mathbf{i}_{j}^{c} ijc的归一值。计算公式为: α b , j c = exp ( i b , j c ) exp ( i j c ) + ∑ b ′ ∈ { b ′ ′ ∣ w b ′ ′ , j d ∈ D } exp ( i b ′ , j c ) α j c = exp ( i j c ) exp ( i j c ) + ∑ b ′ ∈ { b ′ ′ ∣ w b ′ ′ , j d ∈ D } exp ( i b ′ , j c )αb,jc=exp(ijc)+∑b′∈{b′′∣wb′′,jd∈D}exp(ib,jc)exp(ib′,jc)αjc=exp(ijc)+∑b′∈{b′′∣wb′′,jd∈D}exp(ijc)exp(ib′,jc)αcb,j=exp(icb,j)exp(icj)+∑b′∈{b′′|wdb′′,j∈D}exp(icb′,j)αcj=exp(icj)exp(icj)+∑b′∈{b′′|wdb′′,j∈D}exp(icb′,j)
至此LSTM模型部分已经搭建完成了,总结一下:就是由两套LSTM子结构分别是基于字的和基于词的,然后得到基于词的状态输出之后将其加入到基于字的结构中输出预测。
之后就是跟其他模型一样套上一层CRF层。
打完收工。不知道有没有讲清楚,欢迎留言讨论~
代码实现
官方开源代码
看了一下好像没有TF实现的star比较高的代码,暂时就先不贴了。
Paper: ATL for NER
来自论文Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism。
主要抓住三个关键词,也是构建本文模型的关键点:
- Adversarial Transfer Learning:对抗迁移学习
- task-share:本文中是将NER与CWS(Chinese Word Segment)两个类似的任务综合训练
- self-attention:为了解决长程依赖问题

整个框架看图也比较好理解,左半部分是NER任务学习网络, 右半部分是CWS任务学习网络,中间则是对抗学习网络。
Adversarial training 用来预测当前输入是哪一个task, NER 或者 CWS,希望shared bilstm学到的信息跟具体任务无关,而跟ner 和 cws task 都有关。Transfer learning to learn task-shared information, adversarial training to remove task-specific information.
Paper:Adversarial Learning for Chinese NER from Crowd Annotations
在训练命名实体识别系统时,往往需要大量的人工标注语料。为了保证质量,通常需要雇佣专家来进行标注,但这样会造成代价成本高且规模难于扩大。另一种方式是采用众包标注方法,雇佣普通人员来快速低成本完成标注任务,但这样获取的数据含有很多噪音。
作者提出了一种利用众包标注数据学习对抗网络模型的方法,来构建中文实体识别系统。受对抗网络学习的启发,他们在模型中使用了两个双向 LSTM 模块,来分别学习标注员的公有信息和属于不同标注员的私有信息。对抗学习的思想体现在公有块的学习过程中,以不同标注员作为分类目标进行对抗学习。从而达到优化公有模块的学习质量,使之收敛于真实数据 (专家标注数据)。算法框架如下:

Baseline: LSTM-CRF
右边模块属于传统的NER网络:BiLSTM+CRF ,在文章中也被叫做 private LSTM,用于拟合不同标注员的独立标注。
Worker Adversarial
对抗学习部分,首先第一块是一个common LSTM, 输入与private LSTM一样为中文句子的字向量,目的是学习不同标注员之间共同的部分。第二块是一个label LSTM,输入为对应标注员的标签数据。要注意的是,我们希望标注员分类器最终失去判断能力,所以它在优化时要反向更新
R
(
Θ
,
Θ
′
,
X
,
y
‾
,
z
‾
)
=
loss
(
Θ
,
X
,
y
‾
)
−
loss
(
Θ
,
Θ
′
,
X
)
=
−
log
p
(
y
‾
∣
X
)
+
log
p
(
z
‾
∣
X
,
y
‾
)
Paper:Adaptive Co-Attention Network for Named Entity Recognition in Tweets
文章提出之前关于NER的研究仅仅关注文本信息是不够的,因为在社交网络(如推特等)上很多内容都是包含图片的,而且如下图所示仅仅考虑文本信息我们可能会认为"Rocky"是一个人名,但是综合考虑图片信息之后就可以判定其为一条狗。基于以上,文章提出一种综合考虑文本和图像信息的NER网络。
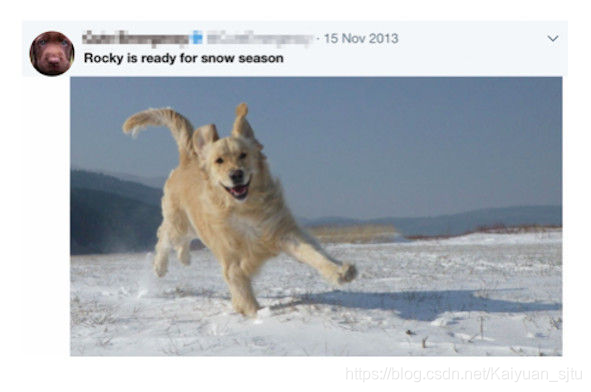

对于文本信息: 使用CNN提取字符向量表示,并从lookup table中提出word embedding。输入为两者的拼接,送入Bi-LSTM抽取更高层特征表示。
对于图像信息: 利用16层的VGG-net,注意本文抽取的特征是last pooling layer。并用一个全联接层转化为和文本信息相同维度的向量。
Adaptive Co-attention Network
如上图右半部分所示,包含了两个attention和两个gate mechanism。
Word-Guided Visual Attention
用于表征对于输入中的特定的词,对应整个图像中的哪个部分。输入为第t时间步的单词表示 h t h_{t} ht和图像特征矩阵 v I v_{I} vI,然后做attention操作 z t = tanh ( W v I v I ⊕ ( W h t h t + b h t ) ) z_{t}=\tanh \left(W_{v_{I}} v_{I} \oplus\left(W_{h_{t}} h_{t}+b_{h_{t}}\right)\right) zt=tanh(WvIvI⊕(Whtht+bht)) α t = softmax ( W α t z t + b α t ) \alpha_{t}=\operatorname{softmax}\left(W_{\alpha_{t}} z_{t}+b_{\alpha_{t}}\right) αt=softmax(Wαtzt+bαt) v ^ t = ∑ i α t , i v i \hat{v}_{t}=\sum_{i} \alpha_{t, i} v_{i} v^t=i∑αt,ivi
Image-Guided Textual Attention
同上,通过结合图片信息,来综合考虑句子中每一个词对整体的贡献。输入为句子经过LSTM后的所有隐层表示
x
=
(
h
1
,
h
2
,
⋯
,
h
n
)
x=\left(h_{1}, h_{2}, \cdots, h_{n}\right)
x=(h1,h2,⋯,hn)和上一步得到的图像权重
v
^
t
\hat{v}_{t}
v^t
z
t
′
=
tanh
(
W
x
x
⊕
(
W
x
,
v
^
t
v
^
t
+
b
x
,
v
^
t
)
)
β
t
=
softmax
(
W
β
t
z
t
′
+
b
β
t
)
h
^
t
=
∑
j
β
t
,
j
h
j
Gated Multimodal Fusion
用于自适应地从文本和图像中学习有用的特征。
h
v
^
t
=
tanh
(
W
v
^
t
v
^
t
+
b
v
^
t
)
h
h
^
t
=
tanh
(
W
h
^
t
h
^
t
+
b
h
^
t
)
g
t
=
σ
(
W
g
t
(
h
t
t
⊕
h
h
^
t
)
)
m
t
=
g
t
h
v
^
t
+
(
1
−
g
t
)
h
h
^
t
Filtration Gate
上面的多模态的信息用门控的方式进行融合,由于文本信息还是占主要部分,再通过一个过滤门控,因为,在预测动词或副词的标签时,图像特征是不必要的。由于多模态融合特征或多或少地包含图像特征并且可能引入一些噪声,使用过滤门来组合来自不同信号的特征,这些特征更好地代表解决特定问题所需的信息。
s
t
=
σ
(
W
s
t
,
h
t
h
t
⊕
(
W
m
t
,
s
t
m
t
+
b
m
t
,
s
t
)
)
u
t
=
s
t
(
tanh
(
W
m
t
m
t
+
b
m
t
)
)
m
^
t
=
W
m
^
t
(
h
t
⊕
u
t
)
最后是一个标准的CRF tagging层。
以上
2019.04.10

