
- 1Linux上运行MySQL出现“ERROR 2002 (HY000): Can't connect to
- 202、MongoDB -- MongoDB 的安全配置(创建用户、设置用户权限、启动安全控制、操作数据库命令演示、mongodb 的帮助系统介绍)_mongodb 创建用户
- 3华为OD机试2024年最新题库(Python、JAVA、C++合集)_华为od机试题库_od题库
- 4简述ECC加密算法
- 5MTK平台Android13实现三方launcher为默认_android13 系统默认launcher
- 6年终前端安全防护规范总结
- 7微信小程序slot插槽的使用
- 8Python解压7z压缩文件
- 9QT窗体间传值总结之Signal与Slot_qt 两个窗体 slot signal
- 10第三方库介绍——cJSON库_c语言json库
文献回顾 | 你还在这样使用工业企业数据库吗?_中国工业企业数据库
赞
踩
你还在这样使用工业企业数据库吗?
编者按:本文根据聂辉华、江艇、杨汝岱三位学者的《中国工业企业数据库的使用现状与潜在问题》(世界经济,2012)总结而成。
众所周知的是,中国工业企业数据库是国内外学者研究我国企业经营状况与问题的主要数据库,且是目前我国体量最大、指标最全面的可获得企业级数据库。基于该数据库,已有大量国内外经济学者进行了相关研究,主题涵盖了企业理论、产业组织理论、公司金融、国际贸易等诸多学科。
然而,正如《中国工业企业数据库的使用现状与潜在问题》一文中所说,该数据库的应用过程中总是伴随着样本匹配混乱、变量大小异常、测度误差明显和变量定义模糊等问题。
他山之石,可以攻玉。即便该文发表已过去六年,其中的“数据库使用现状”部分亟待更新,但“数据库潜在问题”部分内容翔实、观点深刻、引例广泛,仍旧可以为现下使用工业企业数据库进行实证研究的众多学者们提供经验建议与有益参考。
本推文将该文内容总结如下:
第一部分,中国工业企业数据库的优点
第二部分,数据库应用范围
第三部分,数据库潜在问题与部分解决方法
其中“第二部分”由于原文发表的年份较早,因此不再赘述当时“数据库的使用现状”,而只是总结得出“应用范围”。
数据库优点
1. 数据库样本量十分庞大
1999-2007年中国工业企业数据库包括了200多万个观测值,是除经济普查数据之外可获得的最大企业级数据库;
该数据库样本占据了中国工业企业的绝大部分比例,根据2004年全国第一次经济普查数据,数据库样本企业销售额占全国工业企业销售额的89.5%;
该数据库中国有、集体、民营、外资企业所占份额的变化可以从侧面反映中国市场经济结构的剧烈变动。
从统计学或计量经济学的角度来讲,大样本的优势在于降低估计的统计偏误,提高统计效率。

2.该数据库指标十分全面
该数据库所含指标约为130个,包括企业的两类信息:一类是企业的基本情况,另一类是企业的财务数据。
基本情况包括:法人代码、企业名称、法人代表、联系电话、所属行业、注册类型、职工人数、开业年份等;
财务数据包括:流动资产、应收帐款、长期投资、固定资产、累计折旧、无形资产、实收资本、主营业务成本、主营业务收入、管理费用、营业利润、利税总额、研究开发费、工资总额、增值税、工业总产值、出口交货值等。
如此多的指标可以让学者们进行各种主题的研究;若能将数据库和其他企业信息融合,那么学者们将会发现更为丰富的研究视角。而指标越多,在构建计量方程时解释变量和控制变量就越多,这样可以减少遗漏变量问题。
3.该数据库的时间序列较长
工业企业数据库早在1998年就已建立,至今仍在更新。这使得研究者采用动态面板方法具有可行性,从而有助于反映历史因素的作用,以及从动态角度研究企业和产业的演化过程。
数据库应用范围
该部分与原文有所不同的是,原文关注于研究人员们已经使用工业企业数据库“做了什么”“如何做的”,但由于距原文发表已有多年,工业企业数据库在各类经济学分支领域中已有了更多应用,因此,本文只概括工业企业数据库“可以做什么”。
1.生产率
企业生产率是相关文献中最受关注的主题之一。
利用工业企业数据库中提供的销售额或经济增加值、固定资产和职工人数,采取相应的价格指数进行平减,可以计算出每个企业的劳动生产率和全要素生产率(TFP)。
TFP的计算方法包括索洛残差法、OP方法、LP方法、SFA随机边界法等,值得关注的是,聂辉华和贾瑞雪(2011)比较了几种TFP算法的优劣。
2.国际贸易
与生产率研究密切相关的是国际贸易,更具体地说是考察企业出口与生产率的关系。
利用工业企业数据库,一些学者验证了企业异质性假说(生产率与企业出口呈正相关关系)对于中国企业是否成立。
3.外商直接投资
主要研究FDI在中国经济发展中的作用,并以行业间、地区间、内外资企业间的溢出效应存在形式为主要关注的方向。
4.研发
关于R&D的文献主要分为两类:
研究R&D或企业创新的决定因素,即验证“熊彼特假说”;
研究企业R&D对企业绩效的影响
5.民营化
关于民营化的研究主要分为两个方向:
民营化的动因:市场竞争加剧、FDI集中度上升和预算约束的硬化;
民营化的影响:民营化对于企业销售额、劳动生产率、销售成本与管理费用等的影响
6.公司金融
主要研究企业的投资、融资和避税行为
7.产业集聚
主要考察影响产业集聚的因素和产业集聚对企业的影响
8.宏观政策的微观效应
主要研究宏观政策对企业微观行为和绩效的影响
9.其他
主要聚焦于就业问题等劳动经济学范畴问题
数据库潜在问题与部分解决办法
1.样本匹配问题
(1) 企业匹配存在障碍
企业匹配问题:数据库中没有一个可以识别每个样本企业的统一编码
这是因为企业基本信息申报时没有统一格式,无法精确匹配。如果使用以企业代码和名称为依据的序贯识别法,则无法判断在各样本点不同的企业代码,也无法辨别“同一企业更改企业代码或不同企业共享企业代码”的情况。这导致构建一个以企业ID和年份为两维的面板数据变成一个十分棘手的问题。
企业匹配问题解决方法:分组、交叉匹配、人工识别
首先对企业代码和企业名称分别进行两次分组,然后考察同一名称组下的企业是否分属不同代码组。
若是,将这些不同代码组内的所有企业归为一组(不断重复):若新组内没有年份重复的观测值,则将这一组样本点识别为同一家企业;若新组内存在年份重复的观测值,则进入人工识别。
人工识别阶段可能存在多种情况:样本的某些年份有两个观测值,只需保留一个;还可能存在样本代码登记错误的情况,需要参照其他信息进行分类。
使用交叉匹配方法后,发现大约有10%的观测值属于名称相同但法人代码不同的情况。因此若忽视匹配问题将会严重影响样本真实性与准确性。
(2)产业匹配也存在问题
产业匹配问题:2002年前后统计局使用了两种产业分类标准
两种分类标准在二位数行业上无差异,但在三位数和四位数行业上有明显差异。
产业匹配问题解决方法:
将1994GB四位数行业分类对应到2002GB三位数行业分类。
2.指标缺失问题
(1)由于每年的统计对象与口径有所不同,导致重要指标在若干年份缺失
这是因为国家统计局在编纂数据库时,直接将2004年经济普查数据与其他年份混编,没有与其进行匹配。而2004年数据缺少工业总产值、工业增加值、出口交货值、研究开发费等重要指标,其他年份又缺少关于工会、男女职工学历和技术职称等指标。
其次,2003年前后的指标也有一些不同:2001年前数据不包括研发费用;1999-2003年工业企业数据没有工业增加值和应收账款。
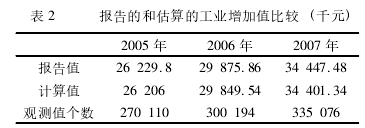
(2)工业企业数据库提供的出口交货值无法区分出口类型
原文认为工业企业数据库不适用于检验企业异质性假说,Dai(2011)将工业企业数据与海关数据匹配,发现生产率悖论不存在。
3、指标异常问题
数据库中有相当多的指标存在异常值异常值的存在使很多观测值无效,因此必须予以剔除。
Cai和Liu(2009)使用了比较全面的剔除方式:
第一步,剔除关键指标缺失的观测值
第二步,剔除了不满足“规模以上”标准的观测值
第三步,剔除明显不符合会计原则的观测值
第四步,剔除了关键指标的极端值
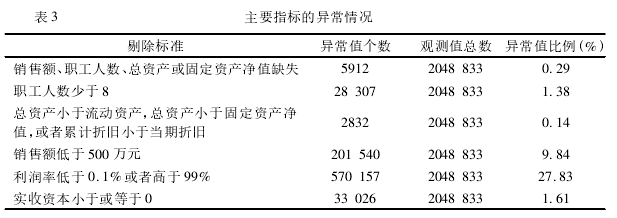
以1999-2007为例,本文分析了指标异常问题。首先,在总共2048833个观测值中,剔除销售额、总资产等缺失的观测值5900个(0.3%);其次,剔除职工人数小于8人的观测值28000个(1%);再次,剔除资产指标不符条件的观测值200多个;最后,剔除销售额低于500万的观测值176500个(9%);即便进行了以上剔除,还是有不少异常值。根据Bai(2009)的标准,异常值大约还有43万个(23%)。
4、测度误差问题
(1)存在测度误差问题
这是因为数据申报过程中企业需要上报四套报表,由于统计时间和口径不同,可能同一指标,企业上报的数值也不一样;并且很多规模不大的企业缺乏可靠的会计系统,或为了避税而瞒报、错报相关指标。
以研发费为例,研发费为0的观测值有120多万个(89%)。对于这种情况有三种解释:企业没有研发支出;企业不清楚,任意填报0;企业未填写,赋值为0。由于无研发支出和不清楚的情况更可能发生在中小企业中,但去除中小企业和出口企业后仍有20000多个研发费为0的企业。
因此应注意两点:
第一,分析企业研发支出决定因素时,应使用Tobit截断模型
第二,若无法区分2、3种情况,那么利用工业企业数据库来分析研发的决定因素是不恰当的
当然,同样存在问题的还有利润和增加值,企业在监管不力情况下为减轻税负会低报、误报这两个指标
(2)虚假指标问题
1999-2007年间,大约有1/5的观测值属于外资企业,但原文分析发现,其中存在严重的不实现象。存在该现象的原因可能有以下两种:
一是可能这些企业以前是外资企业,但变更了实收资本后没有及时变更注册类型
二是这些企业错误地填报了注册类型
但剔除了这些企业后,我们对94%的外资企业仍旧无法辨认其真实身份
5.样本选择问题
(1) 只包括了规模以上的非国有工业企业
因此需要注意两点:
对比国有企业与非国有企业时,应剔除规模以下的国有企业样本
研究产业集聚问题时,可能会低估非国有企业的集聚程度
(2)规模以上的样本并非是随机的
200多万个观测值中,有些样本并不常年存在,因此难以严格界定企业进入和退出情况,研究者在研究企业动态时必须力争解决这个问题。
(3)统计口径不是企业或工厂,导致同属一个集团的企业被定义为不同企业
6.变量定义问题
(1)所有制类型的定义问题
现有文献识别企业所有制时通常采取两种方式:注册类型或实收资本,若根据注册类型来定义,会发现至少有15%的注册国有企业已经不是真正的国企了,因此原文建议使用实收资本比例来定义企业所有制。外资企业的识别存在类似问题(路江涌,2008)。
(2)资本的定义问题
多数文献采取永续盘存法来计算投资,但这意味着第一期的投资变量会缺失,折旧率的不同选取也会造成结果的差异。因此还应该采取不同的价格指数对产值等变量进行平减(Brandt,2012)。
参考文献
聂辉华, 江艇, 杨汝岱. 中国工业企业数据库的使用现状和潜在问题[J]. 世界经济, 2012(5):142-158.
聂辉华, 贾瑞雪. 中国制造业企业生产率与资源误置[J]. 世界经济, 2011(7):27-42.
路江涌. 外商直接投资对内资企业效率的影响和渠道[J]. 经济研究, 2008(6):95-106.
Dai M, Maitra M, Yu M. Unexceptional exporter performance in China? The role of processing trade[J]. Journal of Development Economics, 2016, 121:177-189.
Cai H, Liu Q. Competition and Corporate Tax Avoidance: Evidence from Chinese Industrial Firms[J]. Economic Journal, 2009, 119(537):764–795.
数据Seminar
这里是经济学与大数据的交叉路口
作者/谈佳辉
审阅/杨奇明
编辑/谈佳辉

