
MM-LLM:CogVLM解读
赞
踩
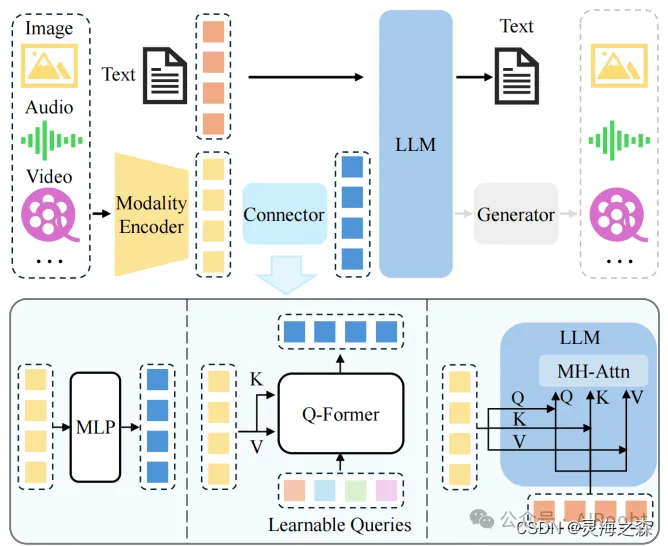
在图文多模态模型中,范式是图像的编码器、文本编码器、模态融合器。也就是不同模态特征抽取加模态对齐。
这部分可以看李沐的精讲
在大模型里的范式在也是如此,目前的工作大部分都专注于怎么拉齐不同模态。
该论文的动机(背景):
论文认为以 BLIP2代表的多模态模型在模态对齐时是shallow alignment,所谓浅对齐,是为了说明该论文的深度对齐。
shallow alignment:BLIP-2为代表的对齐方法,通过对比学习Loss训练Q-Former 或者线性层,来连接冻结的vision encoder和LLM,将图像特征对齐到text Embedding空间。这种办法收敛快,但是性能不如联合训练。同时还具有幻觉问题。
作者的灵感来自于p-tuning and LoRA ,认为p-tuning的添加prompt的方式和浅对齐的模态拼接相似,
(because in the shallow alignment methods, the image features act like the prefix embedding in p-tuning)
而Lora通过在权重矩阵外增加旁支通路,取得了比p-tuning更优秀的结果。
作者推测造成浅对齐的更具体的原因是:
-
冻结的LLM在面对text token的时候才会训练。视觉特征在输入文本空间,将不会有一个很好的对应。因为经过多层Transformer以后,visual feature将不会和weights的输入分布保持一致在深层。
-
在预训练阶段,图像描述任务的先验(例如,写作风格、字幕长度),只能用浅对齐方法编码到视觉特征中。这削弱了视觉特征和内容之间的一致性。
作者继续说如果采用图文联合训练可以增强模态的对齐性能,但是会带来模型在文本上的性能损失。也很自然地想到,原本的LLM在大规模文本数据集上训练,自己再在小规模数据集上微调本身就会出现灾难性遗忘。
总结: 以往工作的浅对齐方法在模态对齐上存在性能不足和幻觉问题。
1.冻结的LLM限制了视觉特征与文本空间的有效对齐。
2.预训练阶段的图像描述任务先验削弱了视觉特征与内容之间的一致性。
3.联合训练可以在一定程度克服浅对齐的弊端,增强对齐性能,但会带来文本性能损失和灾难性遗忘问题。
由此引出了作者借鉴Lora而做的visual expert
CogVLM instead adds a trainable visual expert to the language model.
是针对图像特征,在LLM的每一层解码器上,都copy一份形状相同、初始状态相同的Q、K、V和MLP。
因为针对图像输入训练了一份权重,所以保留了原始的语言处理能力,不损失在单独文本处理上的能力。
模型结构
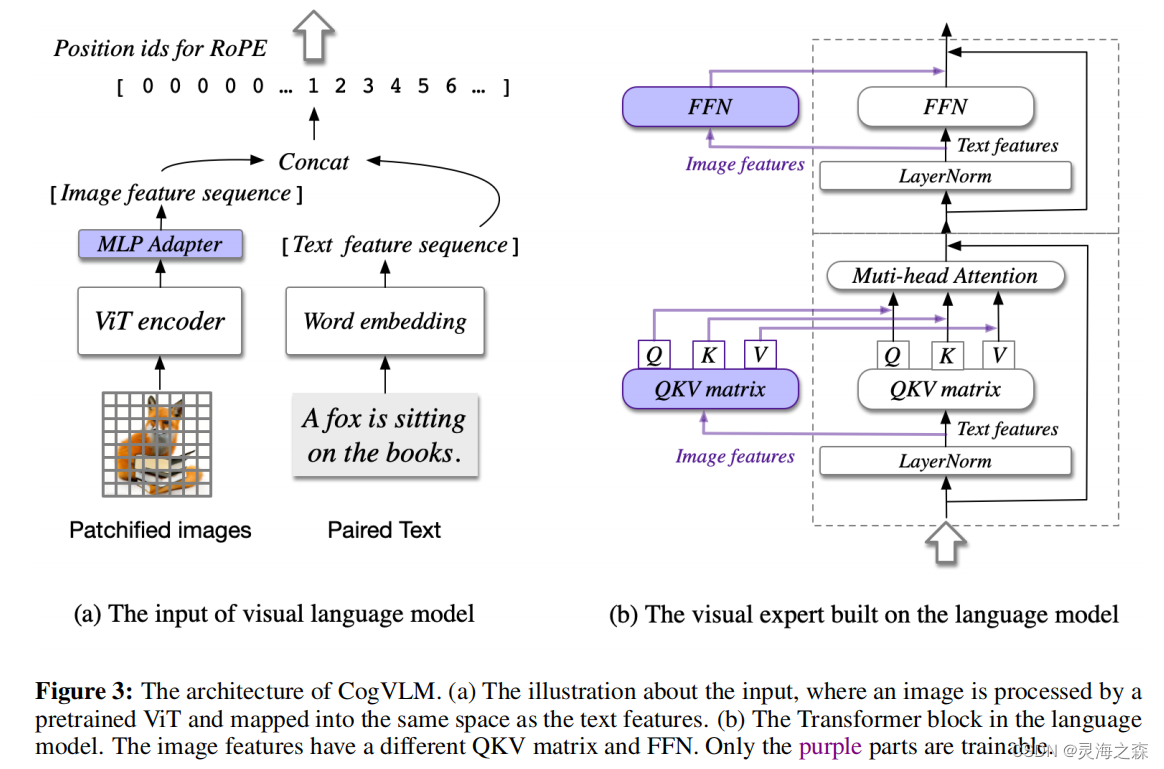 紫色部分是可以训练的,其它是冻结的。
紫色部分是可以训练的,其它是冻结的。
1.编码器
Vision Encoder:最后一层被移除的EVA2-CLIP-E
文本编码器
2.MLP Adapter
2层MLP,激活函数:SwiGLU(有必要开一篇专门的激活函数博客)
将图像特征映射到跟文本特征一样的向量空间。图像特征的position id都是一样的。
3.LLM
使用的基座模型是Vicuna-7Bv1.5。
4.Visual Expert Module(创新)
每一层,都包含QKV矩阵,和MLP。形状和LLM的相同,并且从其初始化。
其动机在于,语言模型中的每个注意力头捕捉某一方面的语义信息,而可训练的视觉专家能够转换图像特征以对齐不同的注意力头,从而实现深度融合。
重点——每层解码器的计算:


代码:https://github.com/THUDM/CogVLM/tree/main/models
图像tokens与文本tokens的Q,K,V分别计算后拼接为一体。在Q,K,V的计算过程中,图像与文本互不干扰。图像信息与文本信息的交互在计算attention score与attention output的过程中发生。
训练阶段
1 预训练
1 所用数据
包含通用图文对数据和视觉定位数据。
通用图文对数据集:LAION-2B 和 COYO-700M。
数据过滤条件:移除损坏的URL;移除NSFW(不适合工作场所)的图像;移除带有噪声标题的图像;移除具有政治偏见的图像;移除长宽比大于6或小于1/6的图像。
视觉定位数据集: 从LAION-115M中抽样而来,再使用spaCy提取名词,并使用GLIPv2预测边界框。共计4000万张图像。
2 预训练的第一阶段
是图像描述损失(image captioning loss),即文本部分的下一个标记预测。
迭代次数:120k
Batch size:8192
3 预训练的第二阶段
图像描述和指代表达理解(REC)的混合训练。
REC任务是根据对象的文本描述预测图像中的边界框,以VQA(视觉问答)的形式进行训练,即“问题:物体在哪里?”和“答案:[[x0, y0, x1, y1]]”。x和y坐标的范围是000到999,表示图像中的归一化位置。在“答案”部分,我们只考虑下一个标记预测的损失。
迭代次数:60k
Batch size:1024
其中在最后30,000步中图像的分辨率从常见的224x224调整为了490x490。
得到CogVLM Grounding Model。base模型。
2 SFT
数据集:LLaVA-Instruct、LRV-Instruction、LLaVAR和一个内部数据集,总共约有50万对VQA(视觉问答)数据对。
对于监督微调,我们进行8,000次迭代训练,每批次大小为640,学习率为10^-5,并且进行了50次预热迭代。
为了防止数据集中文本答案的过拟合,我们采用了较小的学习率(其他参数学习率的10%)来更新预训练的语言模型。除了ViT编码器外,所有参数在SFT期间都是可训练的。
得到 Chat model。
个人总结:
作者在浅对齐的基础上增加了视觉专家模型,实现了不同模态的深度融合,效果也是很强的。但是模型参数量也是上涨了一倍多。也许是可以改进的点。
参考:
1.https://arxiv.org/abs/2311.03079
2.https://zhuanlan.zhihu.com/p/672491823
3.https://zhuanlan.zhihu.com/p/662764235
4.https://zhuanlan.zhihu.com/p/668806245
5.https://blog.csdn.net/weixin_38252409/article/details/134678294
6.【COGVLM: VISUAL EXPERT FOR LARGE LANGUAGEMODELS】 https://www.bilibili.com/video/BV1Fc41167rN/?share_source=copy_web&vd_source=29af710704ae24d166ca951b4c167d53

