
热门标签
热门文章
- 1双人贪吃蛇@botzone数据格式_botzone数据怎么用
- 2将金融文件转化为ASP.NET Core C#中的智能且安全的表单
- 3【HarmonyOS】ArkUI - 自定义组件_arkui 自定义组件
- 4windows环境下ElasticSearch+kibana+ElasticSearch-Head安装搭建_windows es
- 5python上海房价数据分析统计服_(干货)数据分析案例--以上海二手房为例
- 6华为大佬的“百万级”MySQL笔记,基础+优化+架构一键搞定_百万级数据,需要用什么数据库
- 7Datahub安装教程
- 8Nginx 面试分享(十一):部署与集群_nginx tomcat 集群
- 9gitlab-runner k8s cicd小demo_gitlab-runner测试demo
- 10集成学习1——voting、bagging&stacking_voting集成学习
当前位置: article > 正文
Hadoop基础——HDFS知识点梳理_hdfs client
作者:Li_阴宅 | 2024-06-30 10:31:04
赞
踩
hdfs client
HDFS基础知识
1. 介绍一下HDFS组成架构?
组成部分:
- HDFS Client,
- NameNode,
- DataNode
- Secondary NameNode( HA模式下是 StandBy NameNode)
- Client: 客户端
- 文件切分,文件上传HDFS时,client将文件切分成一个一个的block,然后进行存储。
- 与NN交互,获取文件的位置信息。
- 与DN交互,读取或者写入数据。
- Client提供一些命令来管理HDFS, 比如启动或者关闭HDFS
- Client可以通过一些命令来访问HDFS
- NameNode: master,
- 管理hdfs的命名空间
- 管理数据块的映射信息
- 处理客户端的读写请求
- 配置副本策略
- DateNode: slave,NN下达命令,DN执行实际的操作
- 存储实际的数据块
- 执行数据块的读写操作
- Secondary NameNode:
- 辅助NN,分担其工作量。
- 定期合并fsimage和edits log,生成新的fsimage替换旧的fsimage。
- 在紧急情况下辅助恢复NN。
2. NameNode 和 SecondaryNameNode 的区别与联系
- 区别:
- namenode 负责管理整个文件系统的元数据,以及命名空间。
- secondary name node 负责定期合并fsimage和edit log。
- 联系:
- secondary name node 中保存了一份和namenode一致的fsimage(镜像文件)和edits log(编辑日志)。
- 在namenode 发生故障时, 可以从secondary namenode恢复数据。
3. NN和DN的区别和联系?
- 从角色来看:
- NN是master,承担管理者的角色,
- DN 是slave, 承担具体执行者的角色。
- 从工作内容:
- NN管理HDFS的名称空间,数据块的映射信息,处理客户端读写请求。
- DN 存储实际的数据块, 执行数据块的读/写操作。
4. HDFS在HA模式下的工作流程?
相较于非HA模式,多了3部分:
- 负责负载均衡的ZK集群。
- Edits log文件管理系统Qjournal。
- ZKFailoverController负责监测NN是否健康。

5. ZKFailoverController的作用?(HA NameNode的工作模式)
- 健康监测: 周期性的向它监控的NN发送健康探测命令,从而确定某个NN是否处于健康状态,如果机器宕机,心跳失败,zkfc就会标记该NN处于一个不健康的状态。
- 会话管理: 如果NN是健康的,zkfc就会在zk 中保持一个打开的会话,如果NN同时还是Active状态,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉后,znode也将会被删掉,然后备用的NN,将会得到这把锁,升级为主NN,同时标记状态为Active。
- 当宕机的NN新启动时,会再次注册zk, 发现已有znode锁,会自动变为standby状态(防止脑裂,出现两个active node)
- master选举:通过在zk中维持一个短暂类型的znode, 来实现抢占式的锁机制,从而判断哪个NameNode为Active状态。
6. HDFS的存储机制
写数过程:
- 客户端通过 Distributed FileSystem模块向NN发其文件上传请求, NN检查目标文件是否已存在,父目录是否存在
- NN返回是客户端是否可以上传
- 客户端请求第一个block上传到哪几个dn服务器上
- NN返回3个dn节点,分别为dn1,dn2, dn3,表示采用这个三个节点存储数据。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3, 将这个通信管道建立完成。
- dn1, dn2, dn3逐级应答客户端
- 客户端开始往dn1上传第一个block, 以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3; dn1每传一个packet会放入一个应答队列等待应答。
- 当一个block传输完成后, 客户端再次请求NameNode上传第二个block的服务器。

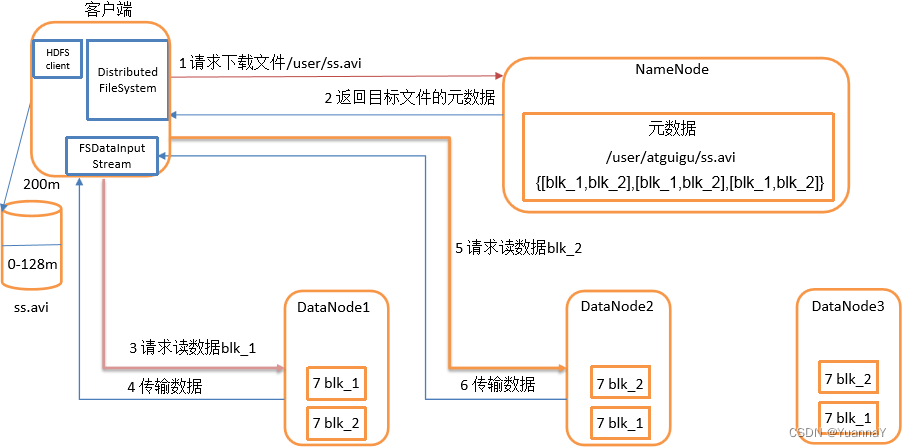
读数过程:
- 客户端通过 Distribued FileSystem 向NameNode请求文件,NameNode通过查询元数据,找到文件所在的DataNode地址。
- 挑选一台DataNode(就近原则)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里读取数据输入流,以packet为单位来做校验)
- 客户端以packet为单位接收,现在本地缓存,然后写入目标文件。
7. Secondary NN 和 HA模式下的StandbyNN的区别
- 首先强调,SecondaryNN 不是NN的备份,只能算是辅助,负责定期合并fsimage和edits log,形成新的fsimage 以替换旧的fsimage。简单理解:Secondry NN负责的是定期存档,方便那天NN异常退出,可以快速回复。
- HA下的Standby NN可以理解为是Active的备份,实时合并fsimage和edits log,将合并后的fsimage 替换旧的fsimage。一旦Active NN挂了,Standby NN 就可以转正,继续提供服务,无需等待,即高可用性的含义。
- 对比,secondary nn 架构简单,但是存在元数据丢失的问题;HA架构复杂,但是元数据不会丢失。
8. HDFS中负责存储的是哪一部分
DateNode,DN 负责具体的数据存储操作
9. HDFS中的Block默认大小是多少?为什么这么设计?
Block默认大小:
1.X版本是64MB,2.X和3.X是128MB。
Block的大小是不能太大,也不能太小,这样做的目的是尽量减少寻址时间在总时间中的占比。
这么理解:
- 文件块越大,寻址时间越短,但磁盘传输时间越长;
- 文件块越小,寻址时间越长,但磁盘传输时间越短。
至于为什么是128M,根据统计,HDFS中平均寻址时间大概为10ms,经过测试,寻址时间为传输时间的1%时,为最佳状态
那么按照公式计算:
最佳传输时间为10ms/0.01=1000ms=1s
目前磁盘的传输速率普遍为100MB/s:
最佳block大小:100MB/s x 1s = 100MB
处于对2进制的执着,block设计为128MB。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Li_阴宅/article/detail/772348
推荐阅读
相关标签

