
- 1给定两个数组,编写一个函数来计算它们的交集。_函数中两个数组能计算吗
- 2Host ‘localhost‘ is not allowed to connect to this MySQL server_host 'localhost' is not allowed to connect to this
- 3大数据 - Spark介绍和环境搭建_spark环境搭建
- 4添加、修改、删除及查看git的用户名及邮箱_linux删除git 用户
- 5万字长文!全网最详细的HarmonyOSNext星河版快速上手教程,小白看这个就够了!(下载安装DevEco Studio)_鸿蒙next开发教程
- 6<<潜伏在办公室>>_狠狠操经理
- 7探索开源世界:2024年值得关注的热门开源项目推荐_2024开源项目 csdn
- 8拍摄的vlog视频画质模糊怎么办?视频画质高清修复
- 9数据科学的文本挖掘:信息抽取与分析
- 10带头结点链栈的基本操作-C语言实现_本关要求按照完成链栈数据类型定义,并初始化一个空的链栈。编程要求链数结点
自动驾驶合集17_maplm: a large-scale vision-language dataset for m
赞
踩
# 首个基于大语言模型的自动驾驶语言控制模型
Arxiv论文链接:https://arxiv.org/abs/2312.03543
项目主页:https://github.com/Petrichor625/Talk2car_CAVG
近年来,工业界和学术界都争先恐后地研发全自动驾驶汽车(AVs)。尽管自动驾驶行业已经取得了显著进展,但公众仍然难以完全接受且信任自动驾驶汽车。公众对完全将控制权交给人工智能的接受度仍然相对谨慎,这主要受到了对人机交互可靠性的担忧以及对失去控制的恐惧的阻碍。这些挑战在复杂的驾驶情境中尤为凸显,车辆必须做出分秒必争的决定,这强调了加强人与机器之间沟通的紧迫需求。因此,开发一个能让乘客通过语言指令控制车辆的系统显得尤为重要。这要求系统允许乘客基于当前的交通环境给出相应指令,自动驾驶汽车需准确理解这些口头指令并做出符合发令者真实意图的操作。
得益于大型语言模型(LLMs)的快速发展,与自动驾驶汽车进行语言交流已经变得可行。澳门大学智慧城市物联网国家重点实验室须成忠教授、李振宁助理教授团队联合重庆大学,吉林大学科研团队提出了首个基于大语言模型的自动驾驶自然语言控制模型(CAVG)。该研究使用了大语言模型(GPT-4)作为乘客的语意情感分析,捕捉自然语言命令中的细腻情感内容,同时结合跨模态注意力机制,让自动驾驶车辆识别乘客的语意目的,进而定位到对应的交通道路区域,改变了传统乘客和自动驾驶汽车交互的方式。该研究还利用区域特定动态层注意力机制(RSD Layer Attention)作为解码器,帮助汽车精确识别和理解乘客的语言指令,定位到符合意图的关键区域,从而实现了一种高效的“与车对话”(Talk to Car)的交互方式。

自动驾驶汽车理解乘客语意,涉及到两个关键领域——计算机视觉和自然语言处理。如何利用跨模态的算法,在复杂的语言描述和实际场景之间建立有效的桥梁,使得驾驶系统能够全面理解乘客的意图,并在多样的目标中进行智能选择,是当前研究的一个关键问题。
鉴于乘客的语言表达与实际场景之间存在较大的差异,传统方法通常难以准确地将乘客的语言描述转化为实际驾驶目标。现有的挑战在于:传统模型很难实现乘客的意图分析,模型往往无法在全局场景下进行综合信息分析,由于陷入局部分析而给出错误的定位结果。同时在面对多个符合语义的潜在目标时,模型如何判断筛选,从中选择最符合乘客期待的结果也是研究的一个关键难题。

现有的视觉定位的算法主要分为两大类,One-Stage Methods和Two-Stage Methods:
-
One-Stage Methods: One-Stage Methods本质上是一种端到端的算法,它只需要一个单一的网络就能够同时完成定位和分类两件事。在这种方法中的核心思想是将文本特征和图片特征进行编码,然后映射到特定的语意空间中,接着直接在整张图像上预测对象的类别和位置,没有单独的区域提取步骤。
-
Two-Stage Methods:在Two-Stage Methods中,视觉定位任务拆成先定位、后识别的两个阶段。其核心思想是利用一个视觉网络(如CenterNet),在图像中识别出潜在的感兴趣区域(Regions of Interest, ROI),将潜在的符合语意的位置和对应的特征向量保存下来。ROI区域将有用的前景信息尽可能多地保留下来,同时滤除掉对后续任务无用的背景信息,随后在第二个识别阶段,结合对应的语意信息在多个ROI区域中挑选出最符合语意的结果。
但不管是哪个任务,如何更好地理解不同模态信息之间的交互关系是图文视觉定位必须解决的核心问题。
算法和模型介绍
作者将视觉定位问题归纳为:“通过给出乘客的目标指令与自动驾驶汽车的前视图,模型能够处理一幅车辆的正面视图图像,以遵循给定的命令,在图像中准确指出车辆应导航至的目的地区域。”

图1.1 Region Proposal示意图
为了使这一目标具体化,模型将考虑为一个映射问题:将文本向量映射到候选子区域中最合适的子区域。具体而言,CAVG基于Two-Stage Methods的架构思想,利用CenterNet模型在图像I提取分割出多个候选区域(Region Proposal),提取出对应区域的区域特征向量和候选区域框(bounding boxes)。如下图所示, CAVG使用Encoder-Decoder架构:包含文本、情感、视觉、上下文编码器和跨模态编码器以及多模态解码器。该模型利用最先进的大语言模型(GPT-4V)来捕捉上下文语义和学习人类情感特征,并引入全新的多头跨模态注意力机制和用于注意力调制的特定区域动态(RSD)层进一步处理和解释一系列跨模态输入,在所有Region Proposals中选择最契合指令的区域。
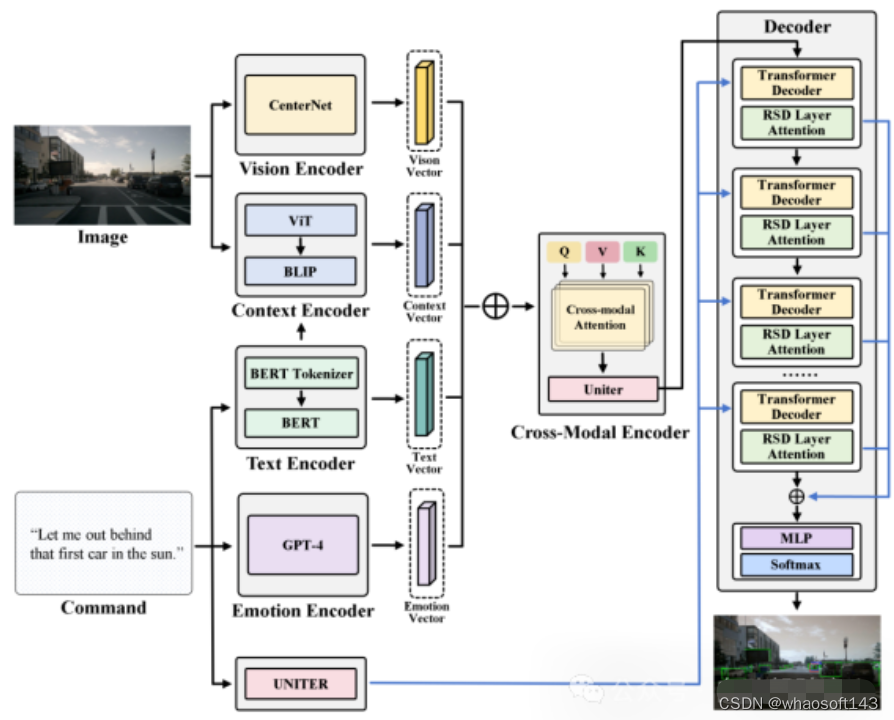
图1.2 CAVG模型架构图


图1.3 Context Encoder中不同层输出示意图


数据集介绍
本工作采用了Talk2Car数据集。下图详细比较了Talk2Car和其他Visual Grounding相关数据集(如ReferIt、RefCOCO、RefCOCO+、RefCOCOg、Cityscape Ref和CLEVR-Ref)的异同。Talk2Car数据集包含11959个自然语言命令和对应场景环境视图的数据集,用于自动驾驶汽车的研究。这些命令来自nuScenes训练集中的850个视频,其中55.94%的视频拍摄于波士顿,44.06%的视频拍摄于新加坡。数据集对每个视频平均给出了14.07个命令。每个命令平均由11.01个单词、2.32个名词、2.29个动词和0.62个形容词组成。在每幅图像中,平均有4.27个目标与描述目标属于相同类别,平均每幅图片有10.70个目标。下图解释了文章所统计数据集中的指令长度和场景中交通车辆种类的布局。
符合C4AV挑战赛的要求,我们将预测区域利用bounding boxes在图中标出表示,同时采用左上坐标和右下坐标(x1,y1,x2,y2)的格式来提交对应的数据结果。t同时我们使用scores作为评估指标,定义为预测的bounding boxes中交并区域与实际边界框相交的比中超过0.5阈值的占比(IoU0.5)。这一评估指标在PASCAL(Everingham和Winn,2012年)、VOC(Everingham等人,2010年)和COCO(Lin等人,2014年)数据集等挑战和基准测试中广泛使用,为我们的预测准确性提供了严格的量化,并与计算机视觉和对象识别任务中的既定实践相一致。以下方程详细说明了预测边界框和实际边界框之间的IoU的计算方法:
实验结果

在对应文章中未公开相关的星系。这种分类阐明了影响每个模型性能的基本组件和策略。下图中的粗体值和下划线值分别代表最佳的模型和第二好的模型。
为了严格评估CAVG的模型在现实场景中的有效性,文章根据语言命令的复杂性和视觉环境的挑战,文章精心地划分了测试集。一方面,由于较长的命令可能会引入不相关的细节,或者对自动驾驶汽车来说更难理解。对于长文本测试集,我们采用了一种数据增强策略,在不偏离原始语义意图的情况下,增加了数据集的丰富性。我们使用GPT扩展了命令长度,得到的命令范围从23到50个单词。进一步评估模型处理扩展的语言输入的能力,对模型的适应性和鲁棒性进行全面的评估。
另一方面,为了进一步衡量模型的泛用性,本文还额外选取构造了特定的测试场景场景:如低光的夜晚场景、复杂物体交互的拥挤城市环境、模糊的命令提示以及能见度下降的场景,使预测更具困难。将而外构造的两个测试集合分别称为为Long-text Test和Corner-case Test。
除此之外,仅使用一半的数据集CAVG(50%)和CAVG(75%)迭代显示出令人印象深刻的性能。提供足够的训练数据时,我们的模型CAVG和CAVG(75%)在部分特殊场景中表现出色。
whaosoft aiot http://143ai.com
# 中低算力平台友好的环视特征融合方案
车端感知算法变迁
FastBEV的目标是面向于实时的车端的一个BEV环视的感知芯片。它的一个特点是一个中低算力友好的实现方案。如图1所示自动驾驶感知算法的变迁,它可能不同阶段不同方案是受到不同的数据积累不同的算法优化的一个成熟度,还有一个车端算力的芯片提升以及说我们对不同的功能需求的多样性之类的都是相关的,那他可能目前可能这段时间内的一些优化方向的话,一方面可能会考虑到说跨平台,以及部署的问题,要兼容到一些不同的算力平台。
这两年自动驾驶感知发展比较快的几年,技术的变迁目标都是为了解决上一代方案痛点,2D方案的缺点在于深度不准,单目3D方案的缺点在于后融合繁琐易错且耗时。单帧环视3D的方案的缺点在于局部感知的能力,受限于单帧输入。时序环视3D的方案的优点在于长时序融合,提高稳定性,可以理解为“检测+跟踪的端到端”。多传感器融合环视3D方案:对齐特征融合了多传感器的特征,感知能力更强。而大家所期待的端到端的放哪:下一代规控,更好地接入感知特征,管线更加简化,或者换句话说更加丝滑了。
BEV versus Occupancy
如图2所示,对于环视前融合这样方案,初步阶段是一个基于BEV future的融合,只有一层BEV的特征,换一个思维理解,就是在纯鸟瞰图下的一个2D BEV特征。它可能同时有传统维和深度维,跟着这个一个思路,比如说把BEV给它拉伸到一个三维的空间去做。基于三维的空间去预测相关的占据,那这就是占据网络相关的思路,最大的一个问题是这个东西会非常的重。如图2中的所表示的 Surround-OCC 网络结构所示。那么是否有轻量化的Occ 表示呢,Flash-OCC 网络就是这样设计,核心点是2D 转3D,会发现是一个比较慢的东西,因为刚刚提到这个特征,又要有深度,又要有一个特征为本身的维度,还涉及到要有六个camera的话,那可能六个camera先各自要做一份。图2中这几篇工作,都是先会把它放到一个好的BEV特征上,然后再去做后续任务,基于这个也能看到一个点,BEV特征融合后的特征,对于各个任务首先都是一个比较好的初始。融合一个统一特征本身,它的任务本身还是比较能够泛化的。
Dense 2D to 3D project
图3 所示主要是说明了显示和隐式的2D转3D,隐式就没有显示的去构建这样一个2D转3D(它的一个类似于索引和融合这样一个过程),隐的方式是从原始的构建2D特征,同时构建出一系列初始的3D点的一些散点。把它作为一个3D的坐标点序列,作为一个位置编码去编码2D特征里面,然后再去接一些position,Encoder和一些结构直接去3D结构,核心用的还是那样一些对应关系,但是它可能就不用显示的先构建出一个BEV特征。
BEVPool V2 versus FastBEV
如图4所示,首选Fast BEV 设计的本身吸收了很多新的Trick 比如时序的融合,2D,3D的引入,深度上不去做过进一步的深度预测,这样的一个隐式深度假设我们就直接均匀的给它铺开。基于这个思想核心的实现,就它是这个东西是可以做的非常快的点是什么?如图4中比如说如果这是一个车子,自车是红色的,可能每个camera只拍到了各自的一部分特征。原来M2BEV 的实现,是每一部分特征各自放一份,然后第二个也各自放一份,完了之后再把六份这样的结果,但是核心点会发现说,因为放就是每个camera之间它的重叠区域会非常小。也就是说,只有涉及到一些重叠区域的时候,它可能才涉及到说这部分的特征是来自不同camera的。然后在每个camera各自拍到的那部分特征之下,它各自特征基本上都是沿着射线等价的。
我们觉得说我两个设计都相机都拍到了,那我也不用考虑那么多了,我就只留一份,这个会造成一个什么样的结果?那这样的就变成了说我们每一个voxels 这个格子应该填每一个camera下的哪个位置的特。它就是一个固定的东西了。那这样的话,只需要通过最终的一个voxels的大小的volume的每一个索引值,就去只需要建立一遍索引。比如说零零这个位置的特征。只需要拿,比如说第一个camera的,比如说第33某个位置的特征,我只要通过建立这样的索引关系,我就直接这样循环做一遍去填充,然后这样就填完了,这样可以做的非常快,其实整个过程是一个静态的参数对应的一个东西,它本身就可以建立一个叉表,其次还完全省去了六个camera各自要构建一遍再同步去做融合这个事.
Fast BEV 的主要贡献
如图5 所示 Fast BEV 的主要贡献
1) FastBEV 论证了在对齐训练Trick 的情况下, 基于深度均匀假设的环视特征融合方案相比于其他dense 方案进度损失很小
2) 支持了查找表优化和多合一voxel 加速,可实现优异的跨平台&不同算力高效部署性能,使得在低算力平台快速部署环视BEV 模型成为可能
3) 2D 转3D 算子作为环视感知方案的核心组建,其优化可赋能任何基于Dense BEV feature的下游任务
最后的彩蛋
如图6 所示为Fast BEV 经典的pipeline, 在此致敬一下这种查找表的创新之作,最后关于完整的视频分享,后续会整理出更加详细的内容和视频
# 相机与激光雷达~主流的标定工具
相机与激光雷达的标定是很多任务的基础工作,标定精度决定了下游方案融合的上限,因为许多自动驾驶与机器人公司投入了较大的人力物力不断提升,今天也为大家盘点下常见的Camera-Lidar标定工具箱,建议收藏!
(1)Libcbdetect
一次拍摄多棋盘格检测:https://www.cvlibs.net/software/libcbdetect/
MATLAB代码实现,该算法自动提取角到亚像素精度,并将它们组合成(矩形)棋盘状图案。它可以处理各种图像(针孔相机、鱼眼相机、全向相机)。
(2)Autoware 标定包
Autoware 框架的激光雷达-相机标定工具包。
链接:https://github.com/autowarefoundation/autoware_ai_utilities/tree/master/autoware_camera_lidar_calibrator
(3)基于3D-3D匹配的靶标标定
基于3D-3D点对应关系的激光雷达相机标定,ROS包,出自论文《LiDAR-Camera Calibration using 3D-3D Point correspondences》!
链接:https://github.com/ankitdhall/lidar_camera_calibration
(4)上海 AI Lab OpenCalib
上海人工智能实验室出品,OpenCalib提供了一个传感器标定工具箱。工具箱可用于标定IMU、激光雷达、相机和Radar等传感器。
链接:https://github.com/PJLab-ADG/SensorsCalibration
(5)Apollo 标定工具
Apollo标定工具箱,链接:https://github.com/ApolloAuto/apollo/tree/master/modules/calibration
(6)Livox-camera标定工具
本方案提供了一个手动校准Livox雷达和相机之间外参的方法,已经在Mid-40,Horizon和Tele-15上进行了验证。其中包含了计算相机内参,获得标定数据,优化计算外参和雷达相机融合应用相关的代码。本方案中使用了标定板角点作为标定目标物,由于Livox雷达非重复性扫描的特点,点云的密度较大,比较易于找到雷达点云中角点的准确位置。相机雷达的标定和融合也可以得到不错的结果。
链接:https://github.com/Livox-SDK/livox_camera_lidar_calibration
中文文档:https://github.com/Livox-SDK/livox_camera_lidar_calibration/blob/master/doc_resources/README_cn.md
(7)CalibrationTools
CalibrationTools为激光雷达-激光雷达、激光雷达相机等传感器对提供标定工具。除此之外,还提供了:
1)定位-偏差估计工具估计用于航位推算(IMU和里程计)的传感器的参数,以获得更好的定位性能!
2)Autoware控制输出的可视化和分析工具;
3)用于修复车辆指令延迟的校准工具;
链接:https://github.com/tier4/CalibrationTools
(8)Matlab
Matlab自带的工具箱,支持激光雷达和相机的标定,链接:https://ww2.mathworks.cn/help/lidar/ug/lidar-and-camera-calibration.html
(9)ROS 标定工具
ROS Camera LIDAR Calibration Package,链接:https://github.com/heethesh/lidar_camera_calibration
(10)Direct visual lidar calibration
该软件包提供了一个用于激光雷达相机标定的工具箱:可通用:它可以处理各种激光雷达和相机投影模型,包括旋转和非重复扫描激光雷达,以及针孔、鱼眼和全向投影相机。无目标:它不需要标定目标,而是使用环境结构和纹理进行标定。单次拍摄:标定至少只需要一对激光雷达点云和相机图像。可选地,可以使用多个激光雷达相机数据对来提高精度。自动:标定过程是自动的,不需要初始猜测。准确和稳健:它采用了像素级直接激光雷达相机配准算法,与基于边缘的间接激光雷达相机配准相比,该算法更稳健和准确。
链接:https://github.com/koide3/direct_visual_lidar_calibration
(11)2D lidar-camera工具箱

链接:https://github.com/MegviiRobot/CamLaserCalibraTool
# 2024自动驾驶热点方向
最新的热点方向涉及端到端自动驾驶、大语言模型、Occupancy、SLAM、车道线检测、3D检测、协同感知、点云处理、MOT、毫米波雷达、Nerf、Gaussian Splatting等方向;
CVPR2024仓库链接:https://github.com/autodriving-heart/CVPR-2024-Papers-Autonomous-Driving
1) End to End | 端到端自动驾驶
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
-
Paper: https://arxiv.org/pdf/2312.03031.pdf
-
Code: https://github.com/NVlabs/BEV-Planner
Visual Point Cloud Forecasting enables Scalable Autonomous Driving
-
Paper: https://arxiv.org/pdf/2312.17655.pdf
-
Code: https://github.com/OpenDriveLab/ViDAR
PlanKD: Compressing End-to-End Motion Planner for Autonomous Driving
-
Paper: https://arxiv.org/pdf/2403.01238.pdf
-
Code: https://github.com/tulerfeng/PlanKD
VLP: Vision Language Planning for Autonomous Driving
-
Paper:https://arxiv.org/abs/2401.05577
2)LLM Agent | 大语言模型智能体
ChatSim: Editable Scene Simulation for Autonomous Driving via LLM-Agent Collaboration
-
Paper: https://arxiv.org/pdf/2402.05746.pdf
-
Code: https://github.com/yifanlu0227/ChatSim
LMDrive: Closed-Loop End-to-End Driving with Large Language Models
-
Paper: https://arxiv.org/pdf/2312.07488.pdf
-
Code: https://github.com/opendilab/LMDrive
MAPLM: A Real-World Large-Scale Vision-Language Dataset for Map and Traffic Scene Understanding
-
Code: https://github.com/LLVM-AD/MAPLM
One Prompt Word is Enough to Boost Adversarial Robustness for Pre-trained Vision-Language Models
-
Paper:https://arxiv.org/pdf/2403.01849.pdf
-
Code:https://github.com/TreeLLi/APT
PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
-
Paper:https://arxiv.org/pdf/2403.02781
RegionGPT: Towards Region Understanding Vision Language Model
-
Paper:https://arxiv.org/pdf/2403.02330
3)SSC: Semantic Scene Completion | 语义场景补全
Symphonize 3D Semantic Scene Completion with Contextual Instance Queries
-
Paper: https://arxiv.org/pdf/2306.15670.pdf
-
Code: https://github.com/hustvl/Symphonies
PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
-
Paper: https://arxiv.org/pdf/2312.02158.pdf
-
Code: https://github.com/astra-vision/PaSCo
4)OCC: Occupancy Prediction | 占用感知
SelfOcc: Self-Supervised Vision-Based 3D Occupancy Prediction
-
Paper: https://arxiv.org/pdf/2311.12754.pdf
-
Code: https://github.com/huang-yh/SelfOcc
Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications
-
Paper: https://arxiv.org/pdf/2311.17663.pdf
-
Code: https://github.com/haomo-ai/Cam4DOcc
PanoOcc: Unified Occupancy Representation for Camera-based 3D Panoptic Segmentation
-
Paper: https://arxiv.org/pdf/2306.10013.pdf
-
Code: https://github.com/Robertwyq/PanoOcc
5)车道线检测
Lane2Seq: Towards Unified Lane Detection via Sequence Generation
-
Paper:https://arxiv.org/abs/2402.17172
6)Pre-training | 预训练
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
-
Paper: https://arxiv.org/pdf/2310.08370.pdf
-
Code: https://github.com/Nightmare-n/UniPAD
7)AIGC | 人工智能内容生成
Panacea: Panoramic and Controllable Video Generation for Autonomous Driving
-
Paper: https://arxiv.org/pdf/2311.16813.pdf
-
Code: https://github.com/wenyuqing/panacea
SemCity: Semantic Scene Generation with Triplane Diffusion
-
Paper:
-
Code: https://github.com/zoomin-lee/SemCity
BerfScene: Bev-conditioned Equivariant Radiance Fields for Infinite 3D Scene Generation
-
Paper: https://arxiv.org/pdf/2312.02136.pdf
-
Code: https://github.com/zqh0253/BerfScene
8)3D Object Detection | 三维目标检测
PTT: Point-Trajectory Transformer for Efficient Temporal 3D Object Detection
-
Paper: https://arxiv.org/pdf/2312.08371.pdf
-
Code: https://github.com/KuanchihHuang/PTT
VSRD: Instance-Aware Volumetric Silhouette Rendering for Weakly Supervised 3D Object Detection
-
Code: https://github.com/skmhrk1209/VSRD
CaKDP: Category-aware Knowledge Distillation and Pruning Framework for Lightweight 3D Object Detection
-
Code: https://github.com/zhnxjtu/CaKDP
CN-RMA: Combined Network with Ray Marching Aggregation for 3D Indoors Object Detection from Multi-view Images
-
Paper:https://arxiv.org/abs/2403.04198
-
Code:https://github.com/SerCharles/CN-RMA
UniMODE: Unified Monocular 3D Object Detection
-
Paper:https://arxiv.org/abs/2402.18573
Enhancing 3D Object Detection with 2D Detection-Guided Query Anchors
-
Paper:https://arxiv.org/abs/2403.06093
-
Code:https://github.com/nullmax-vision/QAF2D
SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection
-
Paper:https://arxiv.org/abs/2403.05817
-
Code:https://github.com/zhanggang001/HEDNet
RadarDistill: Boosting Radar-based Object Detection Performance via Knowledge Distillation from LiDAR Features
-
Paper:https://arxiv.org/pdf/2403.05061
9)Stereo Matching | 双目立体匹配
MoCha-Stereo: Motif Channel Attention Network for Stereo Matching
-
Code: https://github.com/ZYangChen/MoCha-Stereo
Learning Intra-view and Cross-view Geometric Knowledge for Stereo Matching
-
Paper:https://arxiv.org/abs/2402.19270
-
Code:https://github.com/DFSDDDDD1199/ICGNet
Selective-Stereo: Adaptive Frequency Information Selection for Stereo Matching
-
Paper:https://arxiv.org/abs/2403.00486
-
Code:https://github.com/Windsrain/Selective-Stereo
10)Cooperative Perception | 协同感知
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
-
Code: https://github.com/ryhnhao/RCooper
11)SLAM
SNI-SLAM: SemanticNeurallmplicit SLAM
-
Paper: https://arxiv.org/pdf/2311.11016.pdf
CricaVPR: Cross-image Correlation-aware Representation Learning for Visual Place Recognition
-
Paper:https://arxiv.org/abs/2402.19231
-
Code:https://github.com/Lu-Feng/CricaVPR
12)Scene Flow Estimation | 场景流估计
DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement
-
Paper: https://arxiv.org/pdf/2311.17456.pdf
-
Code: https://github.com/IRMVLab/DifFlow3D
3DSFLabeling: Boosting 3D Scene Flow Estimation by Pseudo Auto Labeling
-
Paper: https://arxiv.org/pdf/2402.18146.pdf
-
Code: https://github.com/jiangchaokang/3DSFLabelling
Regularizing Self-supervised 3D Scene Flows with Surface Awareness and Cyclic Consistency
-
Paper: https://arxiv.org/pdf/2312.08879.pdf
-
Code: https://github.com/vacany/sac-flow
13)Point Cloud | 点云
Point Transformer V3: Simpler, Faster, Stronger
-
Paper: https://arxiv.org/pdf/2312.10035.pdf
-
Code: https://github.com/Pointcept/PointTransformerV3
Rethinking Few-shot 3D Point Cloud Semantic Segmentation
-
Paper: https://arxiv.org/pdf/2403.00592.pdf
-
Code: https://github.com/ZhaochongAn/COSeg
PDF: A Probability-Driven Framework for Open World 3D Point Cloud Semantic Segmentation
-
Code: https://github.com/JinfengX/PointCloudPDF
14) Efficient Network
Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications
-
Paper: https://arxiv.org/pdf/2401.06197.pdf
RepViT: Revisiting Mobile CNN From ViT Perspective
-
Paper: https://arxiv.org/pdf/2307.09283.pdf
-
Code: https://github.com/THU-MIG/RepViT
15) Segmentation
OMG-Seg: Is One Model Good Enough For All Segmentation?
-
Paper: https://arxiv.org/pdf/2401.10229.pdf
-
Code: https://github.com/lxtGH/OMG-Seg
Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
-
Paper: https://arxiv.org/pdf/2312.04265.pdf
-
Code: https://github.com/w1oves/Rein
SAM-6D: Segment Anything Model Meets Zero-Shot 6D Object Pose Estimation
-
Paper:https://arxiv.org/abs/2311.15707
SED: A Simple Encoder-Decoder for Open-Vocabulary Semantic Segmentation
-
Paper:https://arxiv.org/abs/2311.15537
Style Blind Domain Generalized Semantic Segmentation via Covariance Alignment and Semantic Consistence Contrastive Learning
-
Paper:https://arxiv.org/abs/2403.06122
16)Radar | 毫米波雷达
DART: Doppler-Aided Radar Tomography
-
Code: https://github.com/thetianshuhuang/dart
17)Nerf与Gaussian Splatting
Dynamic LiDAR Re-simulation using Compositional Neural Fields
-
Paper: https://arxiv.org/pdf/2312.05247.pdf
-
Code: https://github.com/prs-eth/Dynamic-LiDAR-Resimulation
GSNeRF: Generalizable Semantic Neural Radiance Fields with Enhanced 3D Scene Understanding
-
Paper:https://arxiv.org/abs/2403.03608
NARUTO: Neural Active Reconstruction from Uncertain Target Observations
-
Paper:https://arxiv.org/abs/2402.18771
DNGaussian: Optimizing Sparse-View 3D Gaussian Radiance Fields with Global-Local Depth Normalization
-
Paper:https://arxiv.org/abs/2403.06912
S-DyRF: Reference-Based Stylized Radiance Fields for Dynamic Scenes
-
Paper:https://arxiv.org/pdf/2403.06205
SplattingAvatar: Realistic Real-Time Human Avatars with Mesh-Embedded Gaussian Splatting
-
Paper:https://arxiv.org/pdf/2403.05087
DaReNeRF: Direction-aware Representation for Dynamic Scenes
-
Paper:https://arxiv.org/pdf/2403.02265
18)MOT: Muti-object Tracking | 多物体跟踪
Delving into the Trajectory Long-tail Distribution for Muti-object Tracking
-
Code: https://github.com/chen-si-jia/Trajectory-Long-tail-Distribution-for-MOT
DeconfuseTrack:Dealing with Confusion for Multi-Object Tracking
-
Paper:https://arxiv.org/abs/2403.02767
19)Multi-label Atomic Activity Recognition
Action-slot: Visual Action-centric Representations for Multi-label Atomic Activity Recognition in Traffic Scenes
-
Paper: https://arxiv.org/pdf/2311.17948.pdf
-
Code: https://github.com/HCIS-Lab/Action-slot
20) Motion Prediction | 运动预测
SmartRefine: An Scenario-Adaptive Refinement Framework for Efficient Motion Prediction
-
Code: https://github.com/opendilab/SmartRefine
21)卷积网络相关
CAM Back Again: Large Kernel CNNs from a Weakly Supervised Object Localization Perspective
-
Paper:https://arxiv.org/abs/2403.06676
-
Code:https://github.com/snskysk/CAM-Back-Again

