
- 1【UE5.1】* 动画重定向 (让你的角色可以使用小白人全部动画)_ue5创建小白人
- 2Python 学习路线_数据开发学习路线
- 3Android编程:底部弹出输入框_android底部弹出输入框
- 4Zookeeper:Zookeeper JavaAPI操作与分布式锁
- 51024程序员日:有奖答题,全“猿”狂欢!(无套路,100%中奖)_1024问答趣味题吗
- 6AI绘画汇总14000关键词+35个国内AI绘画工具头像壁纸不愁_ai头像关键词素材
- 7windows 系统 上启动kafka_windows启动kafka
- 8SVM详解(包含它的参数C为什么影响着分类器行为)-scikit-learn拟合线性和非线性的SVM_parameter c in svm
- 9关于小程序session_key漏洞问题的解决2022-12-01_小程序存在 sessionkey 泄露
- 10【算法详解】SlowFast——用于视频识别任务的双通道模型
transformer结构笔记_softmax scale
赞
踩
整体结构:encoder - decoder
创新点:self-attention、multihead-attention等
细节:
1. encoder的每层结构
encoder包含了若干个层,每层都有类似的结构,即一个self-attention层加上一个postion-wise的前馈网络:

首先看下自注意力模型。自注意力模型的输入x和输出z是怎样的关系? 为了计算出自注意力的3个要素query、key、value,x要分别乘以三个矩阵:W_q, W_k, W_v(为了计算方便,我们对于多个词汇的attention会以矩阵乘法的形式计算,Q=x*W_q,其它类似);有了q,k和v那么attention的计算和普通attention的计算便没什么两样(q和k乘积作为权重与v相乘)。这里需要注意的是,区别与普通的attention在self-attention中,qkv这三者全部来自于上一层。
对于第一层encoder,输入即词嵌入向量要加上一个position encoding 来注入位置信息(self - attention模型本身不具备抽象出位置信息的能力) 才能作为本层的输入;position encoding 的算法不唯一,关键是要可以表示位置的信息,一种方法是
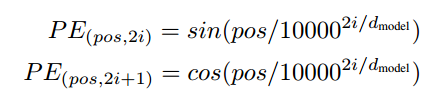
pos单词在句子中的是位置,2i 和 2i + 1 表示词向量的第几个维度,d_model表示词向量的维度的多少,图片就不放了,但确实可以看出有能表示位置信息的能力。
multi-head attention, 这部分的做法是分配多个W_q, W_k, W_v(初始参数均不同)来计算self-attention,最后拼接,这种做法是为了使得attention可以关注到句子的"不同方面"(有争议)。
最后self-attention模块和前馈网络模块的输出都要配上残差块,并且要有layer-normalization :

2. decoder的结构
decoder的结构与encoder结构有几处不同。
decoder的attention有两种:
第一种是来自于encoder最顶层的输出也就是encoder-decoder attention,它输出到decoder中的每一层,它的key和value由encoder顶层提供,而query来自于上一层decoder(这点和传统rnn的seqToSeq模型就很像了)。
第二种是和encoder结构类似的self-attention,不同的是,在该层中后面的单词只能被前面(注意这里说的是decoder层中其他的单词带来的影响,而非encoder层中单词的影响)输出的单词影响(这是transformer的统计模型决定的,与之对应的bert和gpt就是双向的统计建模),所以在计算某个单词的attention时我们需要mask掉后面的词汇(为方便计算,实现的方法为将 K mask 为一个上三角阵)
decoder的其它结构类似于encoder,这里就不再介绍。
Transformer的意义:
并行化计算(position-wise 前馈神经网)
self-attention (长期依赖)
3. 为什么transformer中self-attention的softmax需要scale
按照论文的描述,维度(d_k,也就是dimention of key)增大之后,k*q(k和q都是向量,维度就是d_k)的值通常都会比较大。但如果考虑softmax的梯度在分量数量级比较大的情况下会消失[3],所以我们要对k*q做下scale。分类层的softmax是不需要scale的,它只是网络的最后一层,作用在于分类,梯度消失并不会影响整体网络的优化。
transformer的缺点:
虽然transformer中句子的元素可以不受空间限制和其它位置的元素发生联系,但计算复杂度是O(n^2),当然transformer计算是可以并行的,姑且忽略掉这个缺点。
参考文献:
[1] BERT大火却不懂Transformer?读这一篇就够了
[3] 浅谈Softmax函数

