
- 1关于cannot import name ‘nms_rotated_ext‘ from partially initialized module ‘utils.nms_rotated‘问题解决
- 2【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 卢小姐的生日礼物(200分) - 三语言AC题解(Python/Java/Cpp)
- 3Java的并发编程与虚拟线程Java 17中的Record类Java 16中的Switch表达式Java 11中的局部变量类型推断 [包含示咧]
- 4计算机网络联考复习题_如果源节点知道目的地的ip和 mac 地址的话,信号是直接送往目的地
- 5sourcetree安装过程中的注意事项:_sourcetree安装报错
- 6Java二十三种设计模式-抽象工厂模式(3/23)_java设计原则
- 7Git | git的简单使用教程_downgit
- 8VPN和NAT服务搭建_搭建nat服务器
- 9ComfyUI 基础教程(十四):ComfyUI中4种实现局部重绘方法_comfyui局部重绘工作流
- 10语义分割的几种网络模型_语义分割最新模型
SlowFast视频识别分类算法_slowfast网络结构
赞
踩
前言
Facebook FAIR 何恺明团队提出了用于视频识别的 SlowFast 网络。该网络通过两条路径以不同的时间率(快和慢)进行视频识别。在没有预训练的情况下,在 Kinetics 数据集上的准确率达到了 79.0%,在 AVA 动作检测数据集上实现了 28.3mAP,实现了当前最佳水平。
摘要
本文提出了用于视频识别的 SlowFast 网络。该模型包含:
1)Slow 路径,以低帧率运行,用于捕捉空间语义信息;
2)Fast 路径,以高帧率运行,以较好的时间分辨率捕捉运动。可以通过减少 Fast 路径的通道容量,使其变得非常轻,同时学习有用的时间信息用于视频识别。
该模型在视频动作分类和检测方面性能强大,而且 SlowFast 概念带来的重大改进是本文的重要贡献。在没有任何预训练的情况下,我们在 Kinetics 数据集上的准确率达到了 79.0%,远远超过之前的最佳水平。在 AVA 动作检测数据集上,我们也达到了 28.3 Map,是当前最佳水平。
介绍
在图像识别领域,对称地处理图像 I(x,y)中的两个空间维度 x 和 y 是常见的做法。这是由于自然图像具有第一近似各向同性(所有方向具有相同的可能性)和平移不变性。但是对于视频信号 I(x,y,t)来说,并非所有的时空方向都有相同的可能性。所以我们就不应该像时空卷积那样对称地处理时间和空间。相反,我们应该“分解”该架构,分别处理空间结构和时间事件。
视觉内容的类别空间语义变化通常十分缓慢,例如,挥手不会在这个动作进行期间改变“手”的识别结果,并且人也总是在“人”类别下,即使他/她从走路变成跑步。因此,类别语义(及其颜色、纹理、光照等)的识别可以相对缓慢地刷新。另一方面,正在执行的动作比其主体识别变化速度快得多,例如拍手、挥手、摇晃、走路或跳跃。应该用快速刷新帧(高时间分辨率)来有效建模可能快速变化的动作。
基于这种想法,本文提出了一种用于视频识别的双路径 Slow-Fast 模型(如图 1)。其中一个路径旨在捕获由图像或稀疏帧提供的语义信息,它以低帧率运行,刷新速度慢。而另一个路径用于捕获快速变化的动作,它的刷新速度快、时间分辨率高。尽管如此,该路径的却是轻量级的,只占总计算开销的 20%左右。这是因为第二个路径通道较少,处理空间信息的能力较差,但这些信息可以由第一个路径用较为简洁的方式来提供。根据二者不同的时间速度,作者将其分别命名为 Slow 路径和 Fast 路径。二者通过横向连接(lateral connection)进行融合。
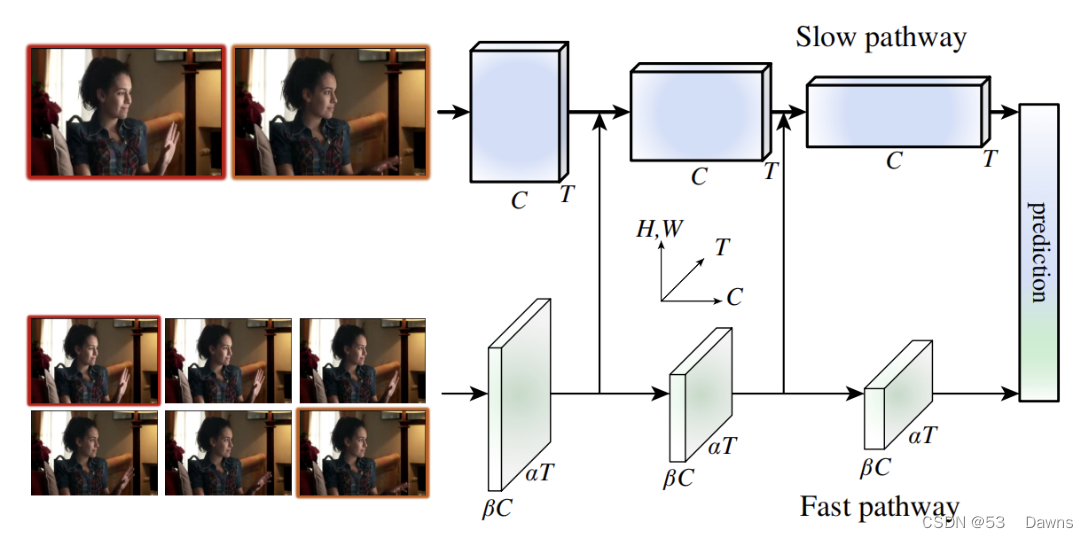
SlowFast 网络包括低帧率、低时间分辨率的 Slow 路径和高帧率、高时间分辨率(Slow 路径时间分辨率的 α 倍)的 Fast 路径。Fast 路径使用通道数的一部分(β,如 β = 1/8)来轻量化。Slow 路径和 Fast 路径通过横向连接融合。
这一想法为视频模型带来了灵活、高效的设计。由于自身较轻,Fast 路径不需要执行任何时间池化——它能以高帧率在所有中间层运行,并保持时间保真度。同时,由于时间速率较低,Slow 路径可以更加关注空间域和语义。通过以不同的时间速率处理原始视频,两种路径可以通过其特有的方式对视频建模。
总结来说就是:
Slow分支:较少的帧数以及较大的通道数学习空间语义信息。
Fast分支:较大的帧数以及较少的通道数学习运动信息。
该方法部分受到灵长类视觉系统中视网膜神经节细胞的生物学研究启发。研究发现,在这些细胞中,约 80% 是 P 细胞,约 15-20% 是 M 细胞。M 细胞以较高的时间频率工作,对时间变化更加敏感,但对空间细节和颜色不敏感。P 细胞提供良好的空间细节和颜色,但时间分辨率较低。SlowFast 框架与此类似:i)该模型有两条路径,分别以低时间分辨率和高时间分辨率工作;ii)Fast 路径用来捕捉快速变化的运动,但空间细节较少,类似于 M 细胞;iii)Fast 路径很轻,类似于较小比例的 M 细胞。
网络实现
我们提出的 SlowFast 是一个通用思想,但是网络可以通过不同的主干结构有不同的实现。表 1 给出了一个 SlowFast 模型的实例化示例。
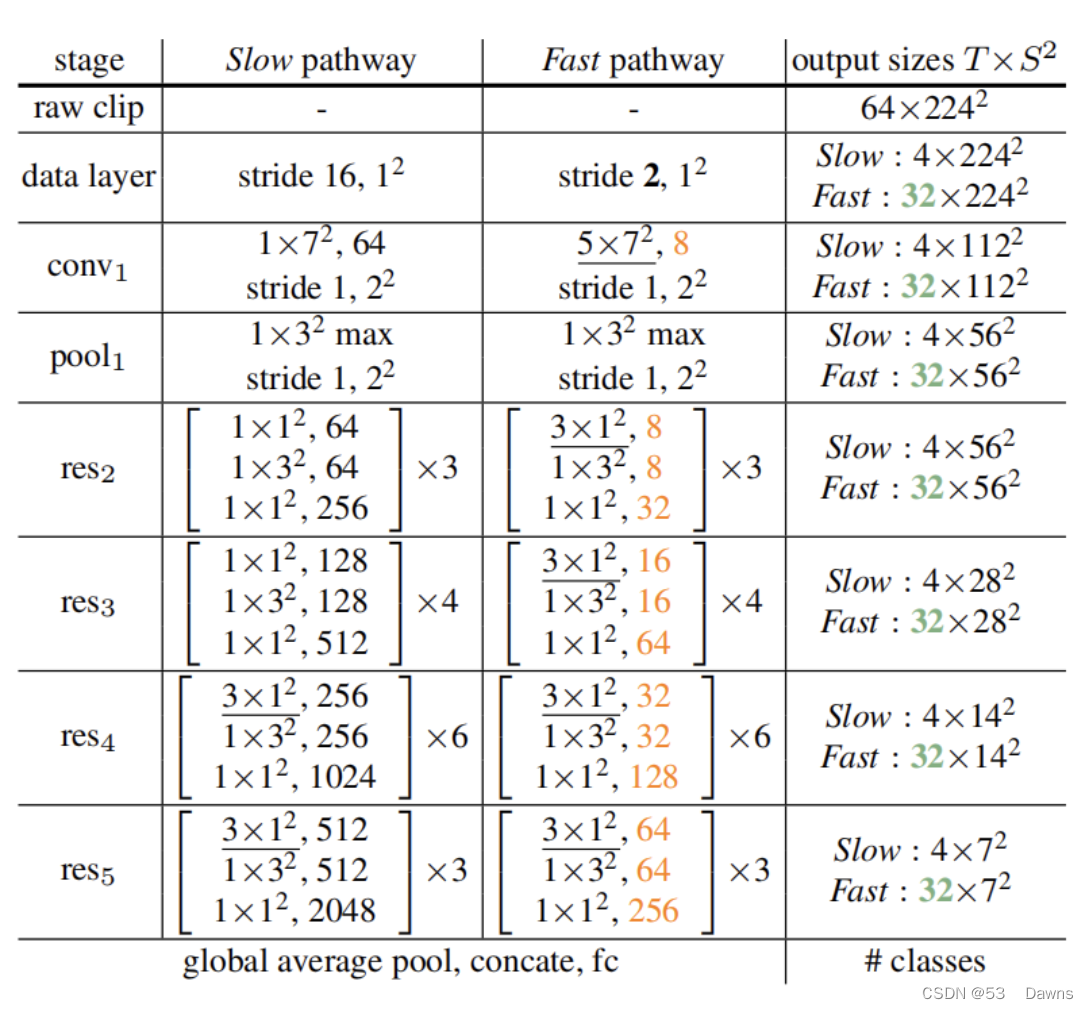
内核的维度由 {T×S^2 , C} 表示,T 表示时间分辨率、S 表示空间语义、C 表示通道数。步长由 {时间步长, 空间步长^2} 表示。此处 速度比例是α = 8,通道比例是 β = 1/8。τ = 16。绿色表示 Fast 路径较高的时间分辨率,橙色表示 Fast 路径较少的通道数。下划线为非退化时间滤波器(non-degenerate temporal filter)。方括号内是残差块。骨干网络是 ResNet-50。
SlowFast 融合
Slow与Fast分支提取的特征需要进行融合,如上图,SlowFast采用的是将Fast分支的特征通过侧向连接(Lateral connections)送入Slow分支进行混合。但是两个分支的特征维度是不一致的(Fast分支是{αT, S², βC} 而Slow分支是 {T, S², αβC}),因此SlowFast需要对Fast分支的结果进行数据变换。
论文给出了三种进行数据变换的技术思路,如下所示,其中第3个方法在实践中最有效。
- Time-to-channel:将{αT, S², βC} 的特征变形为 {T , S², αβC}之后就行融合,就是说把α帧压入一帧。
- Time-strided采样:简单地每隔α帧进行采样,{αT , S², βC} 就变换为 {T , S², βC}。
- Time-strided卷积: 用一个5×1×1的3d卷积, 输出通道为2βC,步长为 α。
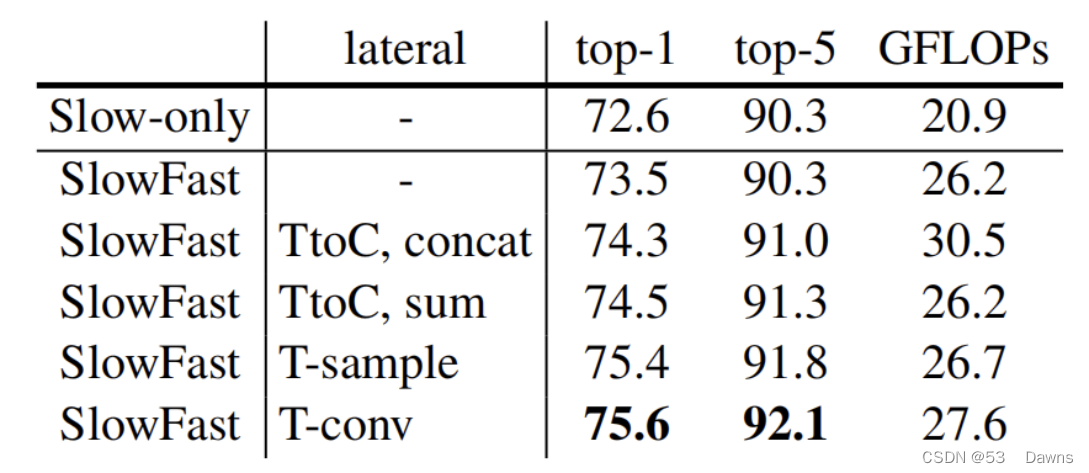
我们给出了没有横向连接的模型变体结果SlowFast,该变体的准确率为 73.5%,略优于 Slow-only 的模型。通过横向连接 T-conv 将 Slow 路径和 Fast 路径融合的准确率比仅有 Slow 路径的基线结果提高了大约3.0%,这是最优的训练结果(即方法3)。
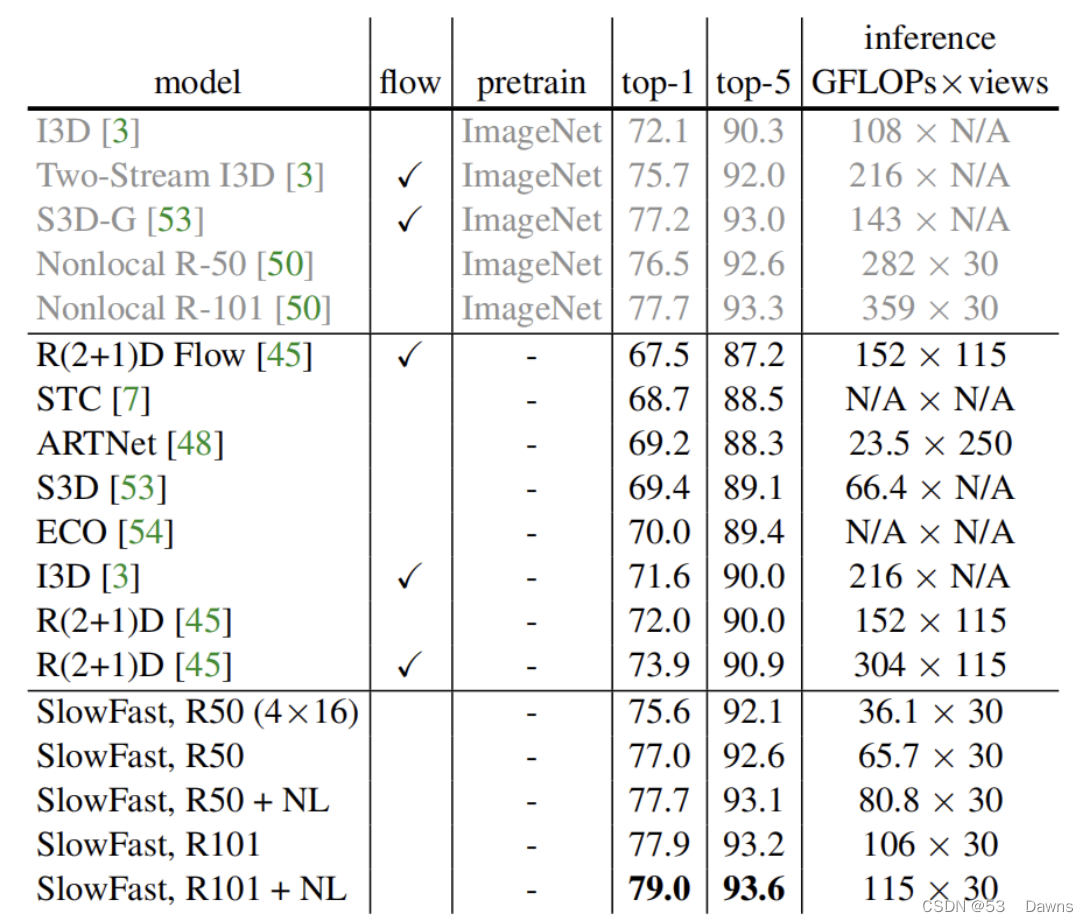
与其他方法进行对比,结果如所示。
总结
时间轴是一个特殊的维度。本文研究了一种沿该轴的处理速度不同的网络架构设计。它达到了目前视频动作分类和检测的最高精度。我们希望这个 SlowFast 概念将促进视频识别的进一步研究。
本篇博客只是简单叙述了一下slowfast,目前还没有深入研究,如有不当请指正!

