
- 1测试开发 | 词嵌入(Word Embeddings):赋予语言以向量的魔力_词嵌入是将词汇表中的每个词映射到
- 2OpenMV:21控制多个舵机(需要模块PCA9685)_openmv控制双舵机
- 3AIGC内容分享(五十五):AIGC周刊
- 4在NVIDIA Orin中编译Apollo 9_apollo 9.0 orin
- 5大数据项目在线实习_数据测试员实习项目
- 6Elasticsearch 未授权访问_elasticsearch未授权访问
- 7【推荐系统】DeepFM模型分析
- 8跟着我,在PS里成功装上SD插件(终极教程!附基本操作步骤)_ps sd插件
- 9stm32+cubemx+淘晶驰串口屏+收发通信并应用_stm32驱动陶晶驰x系列串口屏
- 10原生php开发学生信息管理系统源码_php学生信息管理系统源代码
基于langchain+千帆sdk的一个基于文档的QA问答Demo_千帆 文档生成问答对
赞
踩
微信公众号:淼学派对
CSDN:淼学派对
哔哩哔哩:淼学派对
各大博客社区:淼学派对
背景说明
百度智能云千帆大模型平台官方SDK正式对外发布:https://pypi.org/project/qianfan/。同步支持langchain接入千帆api。
本文重点介绍基于langchain+千帆sdk的一个基于文档的QA问答Demo。

Demo物料
可以直接下载Demo,只需修改step0的ak和sk,即可顺利跑完整个demo。
https://bce-doc-on.bj.bcebos.com/qianfanshequ/qianfan-langchain-QA-demo.zip
版本依赖说明
-
lanchain >= 0.0.292
-
qianfan >= 0.0.3
-
python >= 3.7
QA问答Demo
用例
此处展示了如何使用 Langchian + 千帆 SDK 完成对特定文档完成获取、切分、转为向量并存储,而后根据你的提问来从文中获取答案。
并且借助 Langsmith 将整个过程可视化展现。
概览
把一个非结构化的文档转成问答链涉及以下步骤:
-
Loading: 首先我们需要加载数据,非结构化的数据可以从多种渠道加载。LangChain integration hub 查看所有 Langchain 支持的 Loader。
每个 Loader 都会返回 Langchian 中的 Document 对象。 -
Splitting: 文本切分器 把 Documents 切分成特定的大小。
-
Storage: Storage (例如 vectorstore)会将切分的数据储存起来,通常还附带对文本做 embedding 。
-
Retrieval: 用于从 Storage 中获取切分的数据,用于后面生成答案。
-
Generation: 使用提示词和获取到的数据,搭配 LLM 来生成回答。
-
Conversation (扩展): 添加 Memory 模块来在你的问答链上实现多轮对话。
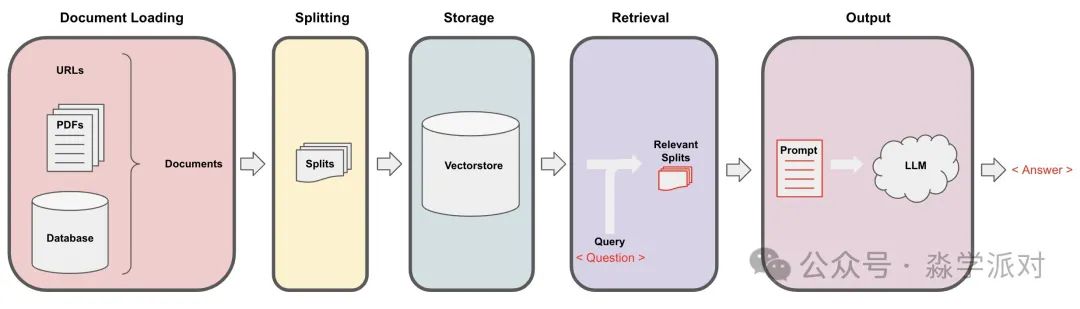
接下来我们会演示如何一步步构造我们自己的流水线,并且实现我们自己定制化的功能
Step 0. Prepare
为了能够运行我们的 Demo,首先我们需要下载依赖并且设置环境变量
- !pip list | grep langchain
- !pip list | grep qianfan
- !pip install langchain !pip install qianfan
实例代码:
- import os
- os.environ['QIANFAN_AK'] = "your_api_key"
- os.environ['QIANFAN_SK'] = "your_secret_key"
- # 此处为 Langsmith 相关功能开关。当且仅当你知道这是做什么用时,可删除注释并设置变量以使用 Langsmith 相关功能
- # os.environ['LANGCHAIN_TRACING_V2'] = "true"
- # os.environ['LANGCHAIN_ENDPOINT'] = "https://api.smith.langchain.com"
- # os.environ['LANGCHAIN_API_KEY'] = "your_langchian_api_key"
- # os.environ['LANGCHAIN_PROJECT'] = "your_project_name"
- is_chinese = True
- if is_chinese:
- WEB_URL = "https://zhuanlan.zhihu.com/p/85289282"
- CUSTOM_PROMPT_TEMPLATE = """
- 使用下面的语料来回答本模板最末尾的问题。如果你不知道问题的答案,直接回答 "我不知道",禁止随意编造答案。
- 为了保证答案尽可能简洁,你的回答必须不超过三句话。
- 请注意!在每次回答结束之后,你都必须接上 "感谢你的提问" 作为结束语
- 以下是一对问题和答案的样例:
- 请问:秦始皇的原名是什么
- 秦始皇原名嬴政。感谢你的提问。
- 以下是语料:
- {context}
- 请问:{question}
- """
- QUESTION1 = "明朝的开国皇帝是谁"
- QUESTION2 = "朱元璋是什么时候建立的明朝"
- else:
- WEB_URL = "https://lilianweng.github.io/posts/2023-06-23-agent/"
- CUSTOM_PROMPT_TEMPLATE = """
- Use the following pieces of context to answer the question at the end.
- If you don't know the answer, just say that you don't know, don't try to make up an answer.
- Use three sentences maximum and keep the answer as concise as possible.
- Always say "thanks for asking!" at the end of the answer.
- {context}
- Question: {question}
- Helpful Answer:
- """
- QUESTION1 = "How do agents use Task decomposition?"
- QUESTION2 = "What are the various ways to implemet memory to support it?"

Step 1. Load
指定一个 DocumentLoader 来把你指定的非结构化数据加载成 Documents。一个 Document 是文字(即 page_content)和与之相关的元数据的结合体
- from langchain.document_loaders import WebBaseLoader
- loader = WebBaseLoader(WEB_URL)
- data = loader.load()
Step 2. Split
接下来把 Document 切分成块,为后续的 embedding 和存入向量数据库做准备。
- from langchain.text_splitter import RecursiveCharacterTextSplitter
-
- text_splitter = RecursiveCharacterTextSplitter(chunk_size = 384, chunk_overlap = 0, separators=["\n\n", "\n", " ", "", "。", ","])
- all_splits = text_splitter.split_documents(data)
Step 3. Store
为了能够查询文档的片段,我们首先需要把它们存储起来,一种比较常见的做法是对文档的内容做 embedding,然后再将 embedding 的向量连同文档一起存入向量数据库中,此处 embedding 用于索引文档。
- from langchain.embeddings import QianfanEmbeddingsEndpoint
- from langchain.vectorstores import Chroma
- vectorstore = Chroma.from_documents(documents=all_splits, embedding=QianfanEmbeddingsEndpoint())
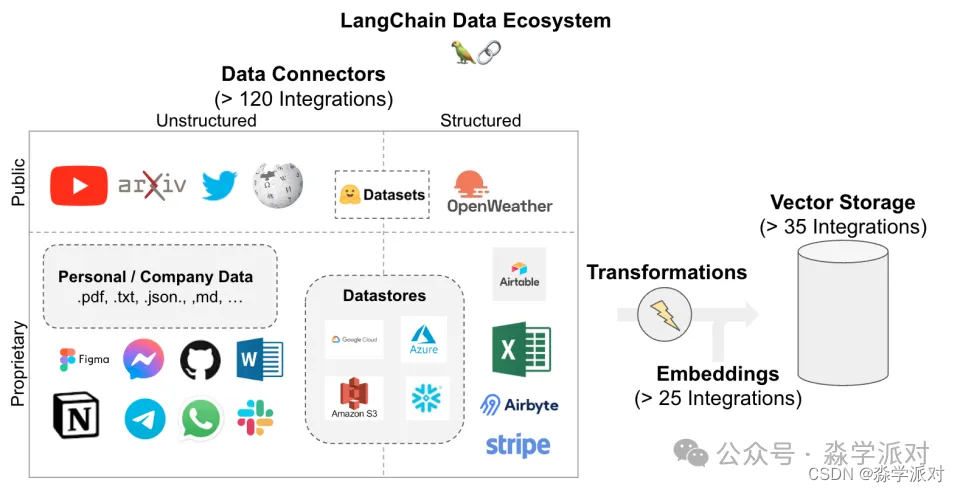
除了非结构化的文档以外,Langchain 还可以从多种数据源获取数据并将它们存储起来。
 Step 4. Retrieve
Step 4. Retrieve
我们可以使用 相似度搜索 来从切分的文档内获取数据,获取到的数据会作为最终提交给 LLM 的 prompt 的一部分。
- # 基于prompt问题查找相似文档
- print("prompt问题:"+QUESTION1)
- docs = vectorstore.similarity_search_with_relevance_scores(QUESTION1)
- [(document.page_content, score) for document, score in docs]
Step 5. Generate
接下来我们就可以使用我们的大模型(例如文心一言)和 Langchain 的 RetrievalQA 链,来针对这篇文档进行提问并获取我们想要的回答了。
- from langchain.chains import RetrievalQA
- from langchain.chat_models import QianfanChatEndpoint
- from langchain.prompts import PromptTemplate
-
- QA_CHAIN_PROMPT = PromptTemplate.from_template(CUSTOM_PROMPT_TEMPLATE)
-
- llm = QianfanChatEndpoint(streaming=True)
- retriever=vectorstore.as_retriever(search_type="similarity_score_threshold", search_kwargs={'score_threshold': 0.0})
-
- qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever, chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})
- qa_chain({"query": QUESTION1})
注意,此处不光可以传入 ChatModel ,也可以传入一个 LLM 对象到 RetrievalQA 中。并且通过代码我们可以看到,用户可以通过传入额外的命名参数字典来自定义我们所需使用的 prompt 模板
Step 5.1 返回源文档
用于 QA 的知识文档也可以通过指定 return_source_documents=True 被包含在返回的字典里
- from langchain.chains import RetrievalQA
-
- qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever, chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}, return_source_documents=True)
- result = qa_chain({"query": QUESTION1})
- len(result['source_documents'])
- result['source_documents']
Step 6. Chat
我们还可以加入 Memory 模块并替换使用 ConversationalRetrievalChain 来实现记忆化的对话式查询。
- from langchain.memory import ConversationSummaryMemory
- from langchain.chains import ConversationalRetrievalChain
-
- memory = ConversationSummaryMemory(llm=llm,memory_key="chat_history",return_messages=True)
- qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory, combine_docs_chain_kwargs={"prompt": QA_CHAIN_PROMPT})
- qa(QUESTION1)

