
- 1UI自动化测试、接口测试等自动化测试策略
- 2布隆过滤器(BloomFilter)的原理及应用_布隆过滤器原理 应用
- 3人脸识别长篇研究_大数据 查找相似长相的人
- 4Hive Container 内存溢出问题解决_set hive.tez.container.size
- 5ubuntu 22.04 编译 ORBSLAM3_ubuntu 22 编译 orb slam3
- 6在CSDN创作了一年,我收获了什么?_我在csdn这一年
- 7利用Elasticsearch提升Java应用的搜索能力_java elasticsearch suggest智能辅助
- 8macOS Monterey 系统关闭SIP详细教程,超级简单!_macsip怎么关闭
- 9分布式架构下基于Redisson实现Redis分布式锁_redisson实现分布式锁
- 10(转)深度学习:感受野、卷积,反池化,反卷积,卷积可解释性,CAM ,G_CAM,为什么使用CNN替代RNN?_反卷积 可解释性
LSTM微博评论情绪识别二分类项目jieba分词遇到的问题
赞
踩
LSTM微博评论情绪识别二分类项目:
提示:这里简述项目相关背景:
LSTM微博评论情绪识别二分类项目是对.csv文件的数据集处理,首先要将评论进行清洗,分词,去掉停用词等处理。
无法正确分词----jieba分词库
提示:这里描述项目中遇到的问题:
问题1:对于“不开心”它分成了“开心”,无法识别出否定的“不”,经过处理后发现是停用表中含有“不”,所以我去掉了停用表里面的“不”,“不是”,“不要”等词,以及表示嘿嘿,哈哈等情绪的词汇。问题表现它可以识别【不】【开心】却无法对后续的情绪处理带来好处。
问题2:无法识别断句,比如:微信(微信号:XXXXXX),它将微【微信微】和 【信号】分在了一起,后来我发现是我提前将所有的标点符号再分词前给删掉了,现在分成了【微信】【微信】【号】但是现在的问题是:我将一些不必要的 【@小小】给删除后,再分的词,但是发现了槽点,【@小小】前后两个没有关系的句子中结合出了一个单词。我无语了。
问题现象:
原始句子://@刺客小A: 好好的不行吗嘛!一定要剧透,自己知道就算了,还转发!唉伊!//@璐璐小仙: 剧透了,剧透了。姚双喜再恶心点。人品再差一点,每次都要哭到鼻涕全都出来。看到他就想快近。还是三顺可爱,好好的不行嘛~[太开心]
分词后:好好 不行 一定 要剧 透 知道 转发 伊剧 透 剧透 姚 双喜 恶心 点 人品 差一点 每次 哭 鼻涕 全都 看到 想 快 近 三顺 可爱 好好 不行 太 开心
原始句子:回复@我要你做回自己:关注锦庭火锅道官方微信(微信号:zhongguohuoguodao),发送自己的美照到公共账号:麒麟锦庭火锅道,我们会专门为大家定制专属于您的电子VIP会员卡,享受全单8.8折的优惠哦。 //@我要你做回自己:怎么玩 //@麒麟锦庭火锅道:[亲亲][亲亲]谢谢大家
分词后:回复 关注 锦庭 火锅 道 官方 微信微 信号 发送 美照 公共 账号 麒麟 锦庭 火锅 道 会 专门 定制 专 属于 电子 会员卡 享受 全单 折 优惠 玩 亲亲 亲亲 谢谢
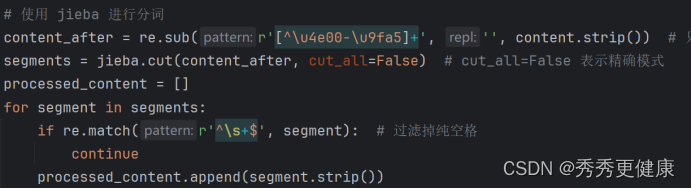
原因分析:
提示:这里填写问题的分析:
问题1:我在分词字典中加入了【不开心】,【嘿嘿】,【哈哈】等表示情绪的词语,因为我发现就算我可以得到分词结果【不】【开心】,模型还是无法识别出【开心】【不开心】是两个相对的意思,它把【开心】作为关键词,这样积极和消极那个特征中含有的【开心】多,模型就会把它分为那个情绪标签。所以我直接加入【不开心】。但是这不是长久的发展,因为【不难受】等这样的情况太多了。
问题2:我发现像我处理掉的 【@小小】【https://editor.csdn.net/md?not_checkout=1&spm=1015.2103.3001.8066&articleId=138742678】【XXXXXXXX.qq.com】等无用的信息和标点符号一样有停顿的作用。
解决方案:
提示:这里填写该问题的具体解决方案:
def ONE_comment_process(content): content = re.sub(r'(https?|ftp|file|www\.)[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]', '[URL]', content) content = re.sub(r'[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+[\.][a-zA-Z0-9_-]+', '[email]', content) content = re.sub(r'(\/\/){0,1}@.*?(:|:| |\n)', '[FORWARD]', content) content = re.sub(r'(\d+\.\d+)|(\d+)', '[number]', content) content = re.sub(r'[\.。…]{2,}', '。', content) content = re.sub(r'~{2,}', '~', content) content = re.sub(r'[!!]{2,}', '!', content) content = re.sub(r'[??]{2,}', '?', content) content = re.sub(r'//', ' ', content) content = re.sub(r'["“”\'‘’]', '', content) content = re.sub(r'@.*?(,| )', '[username]', content) content = re.sub(r'@\S+', '[username]', content) # 使用 jieba 进行分词 jieba.load_userdict("jieba.txt") #增加词典 segments = jieba.cut(content, cut_all=False) #cut_all=False 表示精确模式 processed_content = [] i = 1 for segment in segments: if re.match(r'^\s+$', segment): #过滤掉纯空格 continue processed_content.append(segment.strip()) # 引用停用表stop_words with open("cn_stopwords.txt", "r", encoding="utf-8") as lines: stop_words = [] for line in lines: stop_word = line.strip() # 使用strip()方法删除每行两端的空白字符(包括换行符) if stop_word: # 如果停用词不为空,则添加到列表中 stop_words.append(stop_word) #特色的停用词,用户自定义添加 ignore_chars = ["/", "~", "~", "-", "」", "「", "@", "【", "】", "#", ":", "[", "]", "\"", """, "*", "(", ")", "!", ".", ",", "`", "'", ','] words_list = [] for word in processed_content: if not word: continue if word in ignore_chars: continue if word not in stop_words: words_list.append(word) return words_list

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41

