
- 1Gradle 不能刷新问题解决方案_could not open init generic class cache for initia
- 2cadence23---PCB Editer 学习笔记
- 3win7 安装.net framework 4.5.2报错:“根据当前系统时钟或签名文件中的时间戳验证时要求的证书不在有效期内。”
- 4css伪类_#aa div{
- 5JDBC:Java数据库连接技术_jdbc技术
- 6TunesKit for Mac如何在Mac上将iTunes DRM M4V转换为MP4?_tuneskit acemovi(视频编辑软件) 输出音频是mp4
- 7前端下载文件获取返回状态以及删除文件总结_前端获取文件加载回调
- 8【Qt+opencv】基础的图像绘制
- 9go mod 添加私有库GOPRIVATE_go mod 私有仓库
- 10算法面试题目1
布隆过滤器(BloomFilter)的原理及应用_布隆过滤器原理 应用
赞
踩
介绍
本质上布隆过滤器(BloomFilter)是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在。
原理会在下面介绍。
使用场景
当你要判断一个东西是否存在的时候会使用到,比如:
- 网页爬虫对URL的去重,避免爬取相同的URL地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)
- Redis使用布隆过滤器去重
其他数据结构缺点
List
想判断某个个元素是否在在list种已经存在,需要O(n)的时间复杂度,并且需要把全部文件储存在List种,如果内存中存不下可能还有硬盘IO操作。
总结:
缺点 :
- O(n)
- IO操作
- 消耗内存
Tree
二叉树或者AVL树同样可以判断一个元素是否已经存在,比起List的优点是时间复杂度更低,为O(logn),同样有List的一些缺点。
- O(Logn)
- IO操作
- 消耗内存
HashTable
HashTable实际上是一个比较好的解决方法,时间复杂度为O(1),但是最大的问题同样是消耗内存。因为如果表内已经有了n个元素,就需要预留 n*4/3的空间用来存放hashTable并保证冲突的概率在一个比较低的水平线上。同时如果内存不足以存放这么多数据就需要调用硬盘IO,非常的费时。
缺点
- IO操作
- 消耗内存
布隆过滤器优点
最后降到了主角,布隆过滤器,实际上布隆过滤器最大的优点就是节约内存,不需要把所有元素的hash值保存。只需要用多个hash函数计算hash值,并把hash值映射到一个bitmap上。如果bitmap上有一个位置是0,这个元素肯定不存在,如果所有位置都是1,这个元素有可能存在。

复杂度:O(k)k是hash函数的个数
计算
计算最佳的hash函数的个数
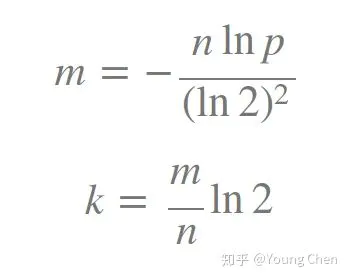
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
引用:
https://www.jianshu.com/p/2104d11ee0a2
https://hackernoon.com/probabilistic-data-structures-bloom-filter-5374112a7832

