
- 1Postman自动化测试:应用场景与实践指南_postman应用场景
- 2docker-compose搭建部署 Skywalking_docker-compose部署skywalking
- 3Ubuntu1804安装pdf阅读软件_ubutnu安装pdf软件
- 4Qwen2大模型微调入门实战(附完整代码)_qwen大模型源码
- 5关于uniapp打包后ios端高德地图的chooseLocation无法搜索地址问题_ios uni.chooselocation 选择地址错误
- 6Vue常用静态模板_vue模板
- 7面试算法 柠檬水找零_柠檬水找零c语言代码
- 8IO 流超级详细讲解_io流
- 9不想root,但想远程控制vivo手机?这个方法不用root也能做到_android 远程控制 非root方案
- 10一种简化决策树ROC的方法_决策树 计算roc
Parameter-Efficient Fine-tuning 相关工作梳理
赞
踩

©PaperWeekly 原创 · 作者 | 避暑山庄梁朝伟
研究方向 | 自然语言处理

背景
随着计算算力的不断增加,以 transformer 为主要架构的预训练模型进入了百花齐放的时代。看到了大规模预训练的潜力,尝试了不同的预训练任务、模型架构、训练策略等等,在做这些探索之外,一个更加直接也通常更加有效的方向就是继续增大数据量和模型容量来向上探测这一模式的上界。首先这些经过海量数据训练的模型相比于一般的深度模型而言,包含更多的参数,动辄数十亿。在针对不同下游任务做微调时,存储(每个任务对应一个完成的预训练模型)和训练这种大模型是十分昂贵且耗时的。

方法归类
2.1 Adapter
通过过在原始的预训练模型中的每个 transformer block 中加入一些参数可训练的模块实现的。假设原始的预训练模型的参数为 ω,加入的 adapter 参数为 υ,在针对不同下游任务进行调整时,只需要将预训练参数固定住,只针对 adapter 参数 υ 进行训练。常情况下,参数量 υ<<ω, 因此在对多个下游任务调整时,只需要调整极小数量的参数,大大的提高了预训练模型的扩展性和实用性。
代表论文:

论文标题:
Parameter-Efficient Transfer Learning for NLP
论文链接:
https://arxiv.org/abs/1902.00751
代码链接:
https://github.com/google-research/adapter-bert
在 Multi-head attention 层后和 FFN 层后都加了一个 adapter,通过残差连接和 down-project & up-project(减少 adapter 的参数量)实现。
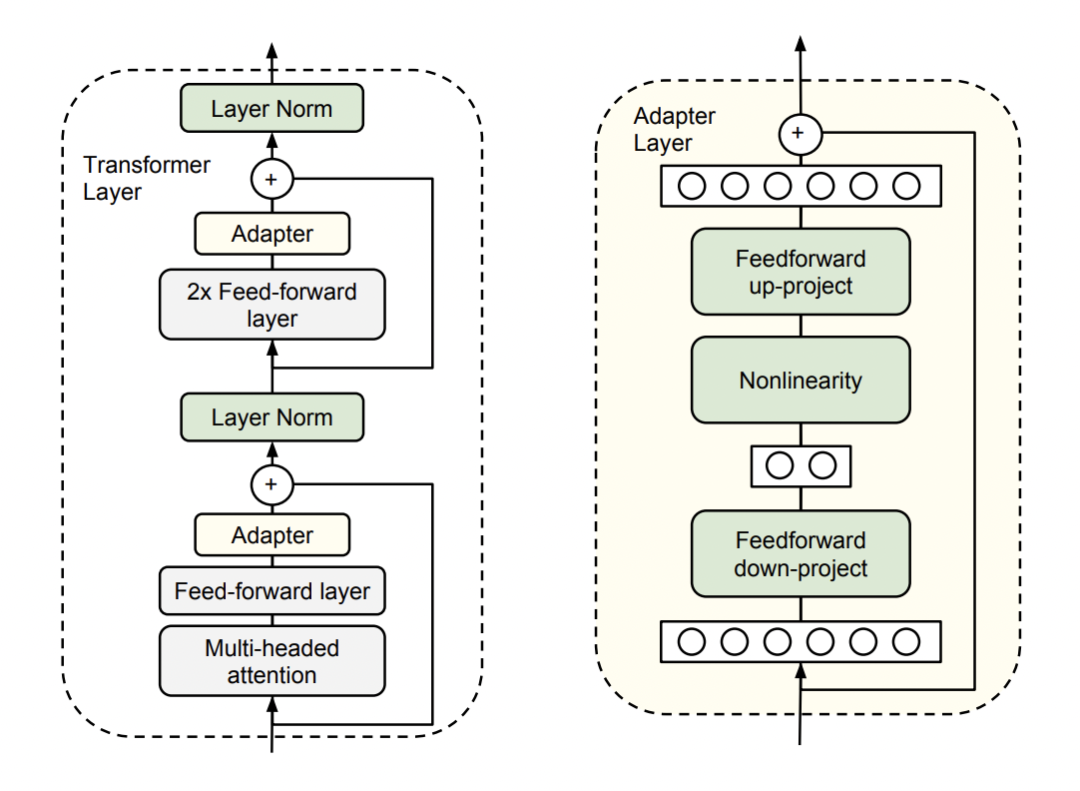

论文标题:
LoRA: Low-Rank Adaptation of Large Language Models
论文链接:
https://arxiv.org/abs/2106.09685
代码链接:
https://github.com/microsoft/LoRA
将原有预训练参数进行矩阵分解(减少参数量),然后和原有


