
- 1git分支选择错误进行操作后如何调整?
- 2模拟cmos集成电路设计_EE618CMOS模拟集成电路设计18
- 3bug5-tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm_ds-math-sub-underflow
- 4利用QLearning实现智能配送路径优化_基于q-learning的物流配送路径规划研究(提供python代码) github
- 58款最佳免费开源PLM解决方案对比_open plm 源码
- 6Mysql对已有数据表进行分区_mysql 现存的表可以再用range分区吗
- 7opencv导入头文件时报错#include
_opencv头文件报错 - 8如何在printf中换行_printf怎么换行
- 9113个创新创意的计算机毕业设计项目,应有尽有,被朋友羡慕了_大三计算机创新项目课
- 10springboot整合springsecurity+oauth2.0密码授权模式_springboot oauth2.0
python利用Excel读取和存储测试数据完成接口自动化_python读写excel表格完成接口自动化
赞
踩
http_request2.py用于发起http请求
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
|
do_excel2.py完成对excel中用例的读、写、统计
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
test_case2.xlsx存储测试用例
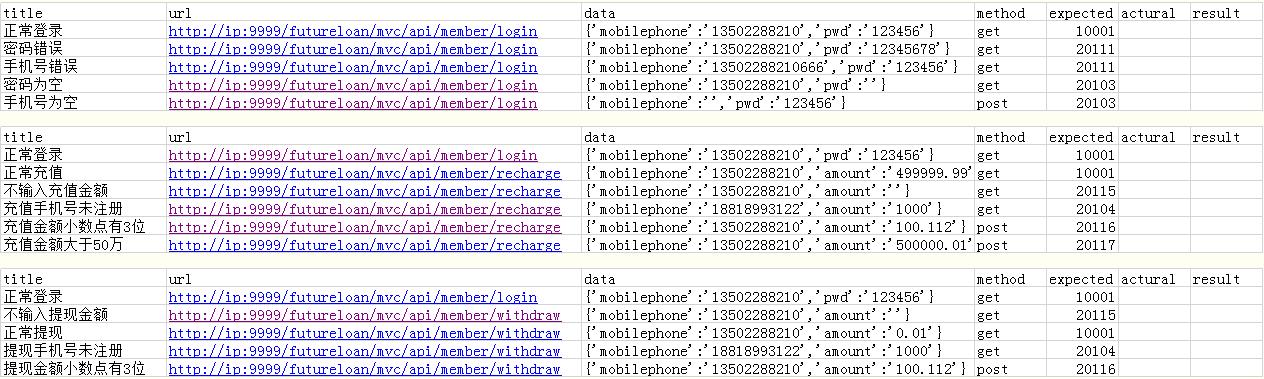

补充知识:python用unittest+HTMLTestRunner+csv的框架测试并生成测试报告
直接贴代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
|
csv文件格式:

备注:
使用python处理中文csv文件,并让execl正确显示中文(避免乱码)设施编码格式为:utf_8_sig,示例:
| 1 2 3 4 5 |
|
- 现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
- 如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
- qq群号:485187702【暗号:csdn11】
- 可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
- 分享他们的经验,还会分享很多直播讲座和技术沙龙
- 可以免费学习!划重点!开源的!!!
- 视频+文档+PDF+面试题可以关注公众号:【软件测试小dao】
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】

- b站视频下载 ...
赞
踩

