
- 1【全开源】餐饮点餐小程序源码(ThinkPHP+FastAdmin+Uniapp)_开源外卖小程序
- 2【Android14 ShellTransitions】(六)SyncGroup完成_transition ontransactionready
- 3谷歌浏览器的源码分析(17)
- 4STM32单片机可变频率幅度DDS信号发生器正弦波三角波方波AD9833_ad9833输出正弦波时幅值最大
- 5在GitHub多个帐号上添加同一台机器的SSH公钥
- 6USB 设备常见问题_usb枚举失败
- 7ai扩图在哪个软件上?本文奉上六款表现亮眼的ai扩图工具_dxo photolab ai扩图
- 8第四篇:实体识别与关系抽取:知识图谱的心脏_实体识别,关系提取例子
- 9Mac虚拟机软件哪个好用 mac虚拟机parallels desktop有什么用 Mac装虚拟机的利与弊 mac装虚拟机对电脑有损害吗
- 10力扣1137. 第 N 个泰波那契数_c语言c++给你整数n,请返回第 n 个泰波那契数 t(n) 的值。
HDFS节点内数据平衡:DiskBalancer_hdfs balancer -threshold
赞
踩
转载地址:http://blog.csdn.net/androidlushangderen/article/details/51776103
前言
做集群运维的同学可能都会遇到这样一个问题:Hadoop集群使用久了,各个节点上的数据会变得不均衡,多的达到70,80%,少的就10,20%.面对这种场景,我们的办法一般就是用HDFS自带的Balancer工具对其进行数据平衡.但有的时候,你会发现尽管节点间数据平衡了,但是节点内各个磁盘块的数据出现了不平衡的现象.这可是Balancer工具所干不了的事情.通过这个场景,我们引入本文的一个话题点:HDFS节点内数据平衡.这个问题很早的时候其实就被提出了,详见issueHDFS-1312(Re-balance disks within a Datanode).我相信大家在使用Hadoop集群的时候或多或少都遇到过这个问题.本文就来好好聊聊这个话题,以及社区目前对此的解决方案.
磁盘间数据不均衡状况的出现
磁盘间数据不均衡的现象源自于长期写操作时数据大小不均衡.因为每次写操作你可以保证写磁盘的顺序性,但是你没法保证每次写入的数据量都是一个大小.比如A,B,C,D四块盘,你用默认的RoundRobin磁盘选择策略去写,最后四块盘都写过了,但是A,B可能写的block块就1M,而C,D可能就是128M.
磁盘间数据不均衡带来的问题
如果磁盘间数据不均衡现象确实出现了,它会给我们造成什么影响呢?有人可能会想,它不就是一个普通磁盘嘛,又不是系统盘,系统盘使用空间过高是会影响系统性能,但是普通盘应该问题不大吧.这个观点听上去是没问题,但是只能说它考虑的太浅了.我们从HDFS的读写层面来对这个现象做一个分析.这里归纳出了以下2点:
第一点,磁盘间数据不均衡间接引发了磁盘IO压力的不同.我们都知道,HDFS上的数据访问频率是很高的,这就会涉及到大量读写磁盘的操作,数据多的盘自然的就会有更高频率的访问操作.如果一块盘的IO操作非常密集的话,势必会对它的读写性能造成影响.
第二点,高使用率磁盘导致节点可选存储目录减少.HDFS在写Block数据的时候,会挑选剩余可用空间满足待写Block的大小的情况下时,才会进行挑选,如果高使用率磁盘目录过多,会导致这样的候选块变少.所以这方面其实偏向的是对HDFS的影响.
磁盘间数据不均衡的传统解决方案
磁盘间数据不均衡现象出现了,目前我们有什么办法解决呢?下面是2种现有解决方案:
方案一:节点下线再上线.将节点内数据不均衡的机器进行Decommision下线操作,下线之后再次上线.上线之后相当于是一个全新的节点了,数据也将会重新存储到各个盘上.这种做法给人感觉会比较暴力,当集群规模比较小的时候,代价太高,此时下线一个节点会对集群服务造成不小的影响.
方案二:人工移动部分数据block存储目录.此方案比方案一更加灵活一些,但是数据目录的移动要保证准确性,否则会造成移动完目录后数据找不到的现象.下面举一个实际的例子,比如我们想将磁盘1上的数据挪到磁盘2上.现有磁盘1的待移动存储目录如下:
/data/1/dfs/dn/ current/BP-1788246909-xx.xx.xx.xx-1412278461680/current/ finalized/subdir0/subdir1/
我移动到目标盘上的路径应该维持这样的路径格式不变,只变化磁盘所在的目录,目标路径如下:
/data/2/dfs/dn/current/BP-1788246909-xx.xx.xx.xx-1412278461680/current/finalized/subdir0/subdir1/
如果上述目录结构出现变化,就会造成HDFS找不到此数据块的情况.
社区解决方案:DiskBalancer
前面铺垫了这么多的内容,就是为了引出本节要重点阐述的内容:DiskBalancer.DiskBalancer从名字上,我们可以看出,它是一个类似于Balancer的数据平衡工具.但是它的作用范围是被限制在了Disk上.首先这里要说明一点,DiskBalancer目前是未发布的功能特性,所以你们在现有发布版中是找不到此工具的.下面我将会全方面的介绍DiskBalancer,让大家认识,了解这个强大的工具.
DiskBalancer的设计核心
首先我们先来了解DiskBalancer的设计核心,这里与Balancer有一点点的区别.Balancer的核心点在于数据的平衡,数据平衡好就OK了.而DiskBalancer在设计的时候提出了2点目标:
第一.Data Spread Report.数据分布式的汇报.这是一个report汇报的功能.也就是说,DiskBalancer工具能支持各个节点汇报磁盘块使用情况的功能,通过这个功能我可以了解到目前集群内使用率TopN的节点磁盘.
第二.Disk Balancing.第二点才是磁盘数据的平衡.但是在磁盘内数据平衡的时候,要考虑到各个磁盘storageType的不同,因为之前提到过HDFS的异构存储,不同盘可能存储介质会不同,目前DiskBalancer不支持跨存储介质的数据转移,所以目前都是要求在一个storageType下的.
以上2点取自于DiskBalancer的设计文档(DiskBalancer相关设计文档可见文章末尾的参考链接).
DiskBalancer的架构设计
此部分来讨论讨论DiskBalancer的架构设计.通过架构设计,我们能更好的了解它的一个整体情况.DiskBalancer的核心架构思想如下图所示:
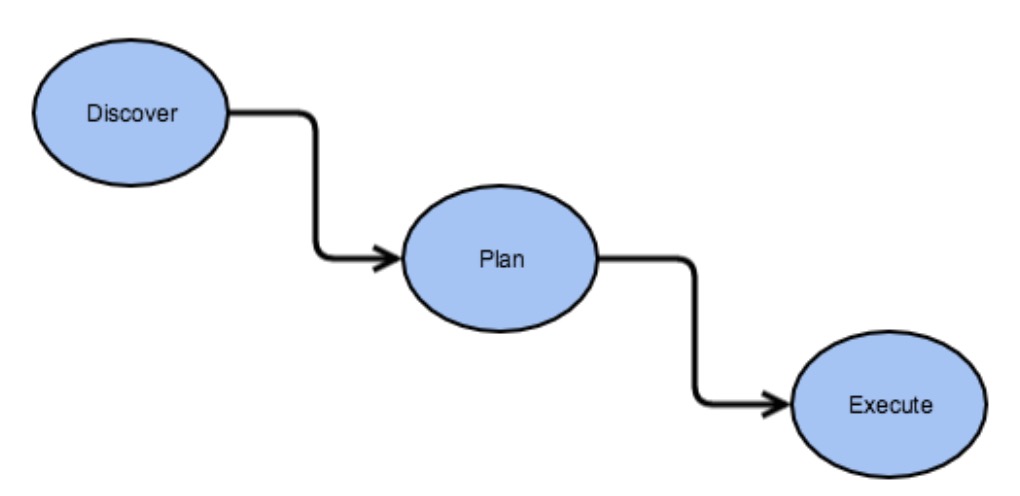
上面过程经过了3个阶段,Discover(发现)到Plan(计划),再从Plan(计划)到Execute(执行).下面来详细解释这3个阶段:
Discover
发现阶段做的事情实际上就是通过计算各个节点内的磁盘使用情况,然后得出需要数据平衡的磁盘列表.这里会通过Volume Data Density磁盘使用密度的概念作为一个评判的标准,这个标准值将会以节点总使用率作为比较值.举个例子,如果一个节点,总使用率为75%,就是0.75,其中A盘使用率0.5(50%),那么A盘的volumeDataDensity密度值就等于0.75-0.5=0.25.同理,如果超出的话,则密度值将会为负数.于是我们可以用节点内各个盘的volumeDataDensity的绝对值来判断此节点内磁盘间数据的平衡情况,如果总的绝对值的和越大,说明数据越不平衡,这有点类似于方差的概念.Discover阶段将会用到如下的连接器对象:
1.DBNameNodeConnector
2.JsonConnector
3.NullConnector
其中第一个对象会调用到Balancer包下NameNodeConnector对象,以此来读取集群节点,磁盘数据情况
Plan
拿到上一阶段的汇报结果数据之后,将会进行执行计划的生成.Plan并不是一个最小的执行单元,它的内部由各个Step组成.Step中会指定好源,目标磁盘.这里的磁盘对象是一层经过包装的对象:DiskBalancerVolume,并不是原来的FsVolume.这里顺便提一下DiskBalancer中对磁盘节点等概念的转化:
- 1.DiskBalancerCluster.通过此对象可以,读取到集群中的节点信息,这里的节点信息以DiskBalancerDataNode的方式所呈现.
- 2.DiskBalancerDataNode.此对象代表的是一个包装好后的DataNode.
- 3.DiskBalancerVolume和DiskBalancerVolumeSet.DataNode磁盘对象以及磁盘对象集合.DiskBalancerVolumeSet内的磁盘存储目录类型需要是同种StorageType.
Execute
最后一部分是执行阶段,所有的plan计划生成好了之后,就到了执行阶段.这些计划会被提交到各自的DataNode上,然后在DiskBalancer类中进行执行.DiskBalancer类中有专门的类对象来做磁盘间数据平衡的工作,这个类名称叫做DiskBalancerMover.在磁盘间数据平衡的过程中,高使用率的磁盘会移动数据块到相对低使用率的磁盘,等到满足一定阈值关系的情况下时,DiskBalancer会渐渐地退出.在DiskBalancer的执行阶段,有以下几点需要注意:
- 1.带宽的限制.DiskBalancer中同样可以支持带宽的限制,默认是10M,通过配置项dfs.disk.balancer.max.disk.throughputInMBperSec进行控制.
- 2.失败次数的限制.DiskBalancer中会存在失败次数的控制.在拷贝block数据块的时候,出现IOException异常,会进行失败次数的累加计数,如果超出最大容忍值,DiskBalancer也会退出.
- 3.数据平衡阈值控制.DiskBalancer中可以提供一个磁盘间数据的平衡阈值,以此作为是否需要继续平衡数据的标准,配置项为dfs.disk.balancer.block.tolerance.percent.
DiskBalancer的命令执行
DiskBalancer内部提供了许多类别的命令操作,比如下面的查询命令:
hdfs diskbalancer -query nodename.mycluster.com
- 1
- 1
- 1
我们也可以执行相应的plan命令来生成plan计划文件.
hdfs diskbalancer -uri hdfs://mycluster.com -plan node1.mycluster.com
- 1
- 1
- 1
然后我们可以用生成好后的json文件进行DiskBalancer的执行
hdfs diskbalancer -execute /system/diskbalancer/nodename.plan.json
- 1
- 1
- 1
当然,如果我们发现我们执行了错误的plan,我们也可以通过cancel命令进行清除:
hdfs diskbalancer -cancel /system/diskbalancer/nodename.plan.json
- 1
- 1
- 1
或
hdfs diskbalancer -cancel <planID> -node <nodename>
- 1
- 1
- 1
在DiskBalancer中会涉及到比较多的object-json的关系转换,所以你会看到一些带.json后缀的文件
小结
总而言之,DiskBalancer是一个很实用的功能特性.在Hadoop中,有专门的分支用于开发此功能,就是HDFS-1312,感兴趣的同学可以下载Hadoop的最新代码进行学习.本人非常荣幸地也向此功能提交了一个小patch, issue编号,HDFS-10560.这个new feature很快就要在新版的Hadoop中发布了,相信会对Hadoop集群管理人员非常有帮助.
参考资料
1.https://issues.apache.org/jira/secure/attachment/12755226/disk-balancer-proposal.pdf
2.https://issues.apache.org/jira/secure/attachment/12810720/Architecture_and_test_update.pdf
2.https://issues.apache.org/jira/browse/HDFS-1312
3.https://issues.apache.org/jira/browse/HDFS-10560

