
- 1Unity2D教程:单例模式、SceneManager.LoadSceneAsync场景切换、Loading界面进度条
- 2mysql undo表空间_MySQL UNDO表空间独立和截断
- 3Chatgpt这么智能,以后会不会取代掉人类?_chatgpt是否会代替人类的大脑
- 4计算机设计大赛 深度学习人体语义分割在弹幕防遮挡上的实现 - python
- 5windows7装python哪个版本好,win7安装哪个版本的python_pycharm win7适配版本
- 6UE4蓝图基础入门(一)变量与蓝图_ue setmenbersin
- 7ChatGPT-4和ChatGPT-3.5知识库截止日期竟然一样?_gpt4数据库截止日期
- 8Unity——InputSystem入门及部分问题讲解_unity inputsystem
- 9python库turtle的双画笔并发绘制兔兔 表白神器_pythonturtle画小白兔
- 10Rabbitmq学习之路3-cluster_rabbitmqctl join_cluster --ram
Elasticsearch简介及安装_elasticsearch安装
赞
踩
一、Elasticsearch简介
1.1 什么是Elasticsearch
Elaticsearch,简称为es, es是一个开源的==高扩展的分布式全文检索引擎==,它可以近乎实时的检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。ES使用Java开发。Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
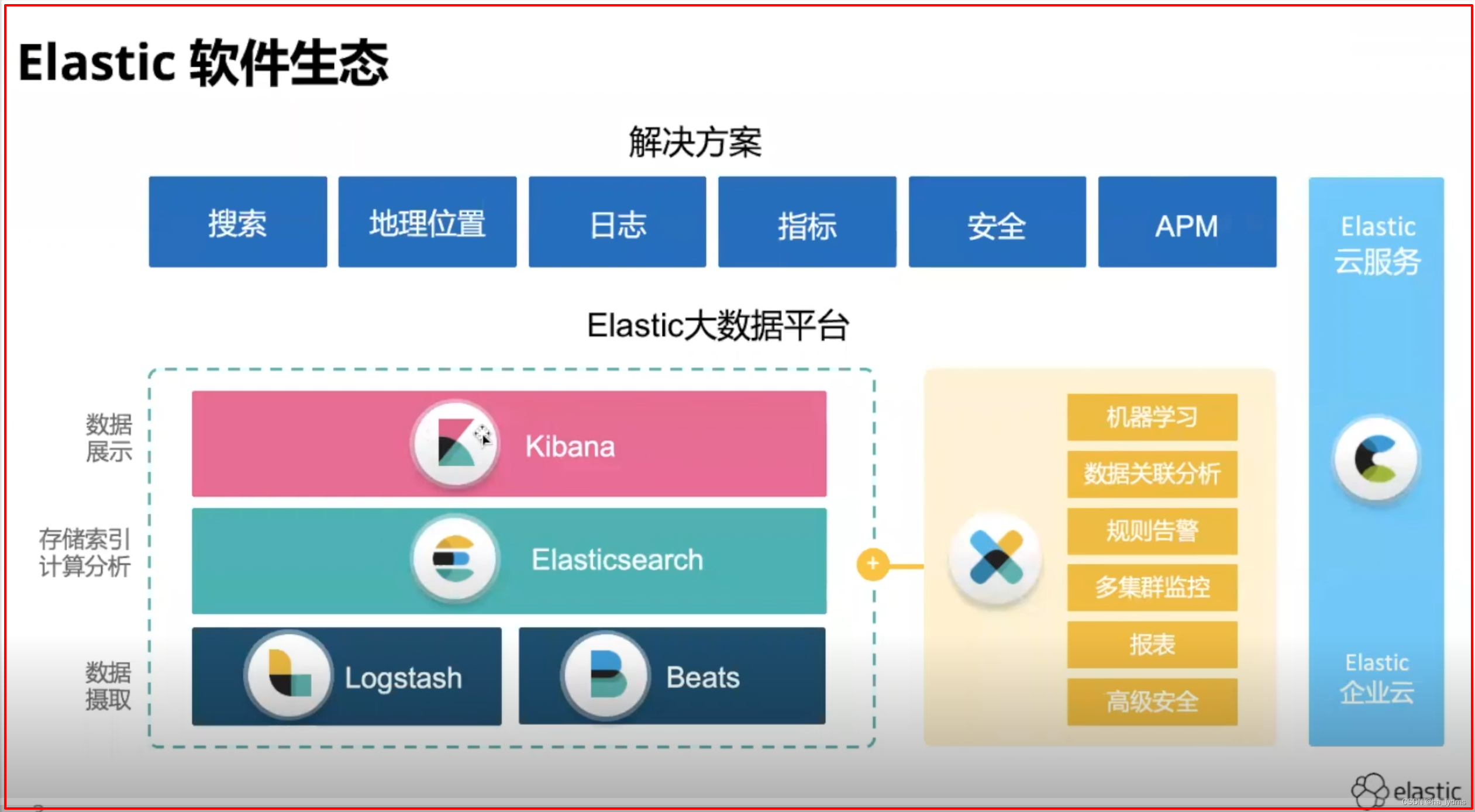
1.2 Elasticsearch的使用案例
- 百度:百度目前广泛使用Elasticsearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
- 新浪使用ES 分析处理32亿条实时日志
- 阿里使用ES 构建挖财自己的日志采集和分析体系
- 2013年初,GitHub抛弃了Solr,采用Elasticsearch 来做PB级的搜索。 “GitHub使用Elasticsearch搜索20TB的数据,包括13亿文件和1300亿行代码”
- 维基百科:启动以Elasticsearch为基础的核心搜索架构
- SoundCloud:“SoundCloud使用Elasticsearch为1.8亿用户提供即时而精准的音乐搜索服务”
3、Es企业使用场景
企业使用场景一般分为2种情况:
3.1 已经上线的系统:
模块搜索功能使用数据库查询实现,但是已经出现性能问题,或者不满足产品的高亮相关度排序需求时。这种情况就会对系统的查询功能进行技术改造,转而使用全文检索,而es就是首选。改造业务流程如图:
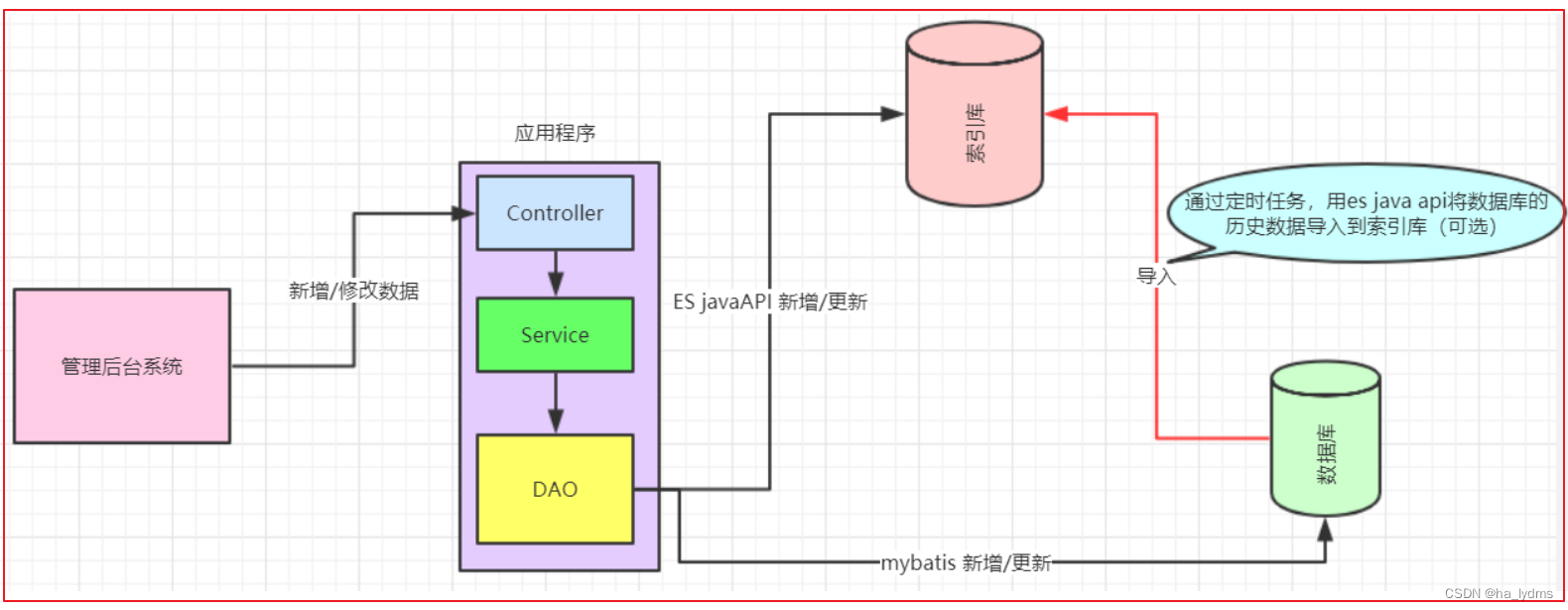
3.2 系统新增加的模块:
产品一开始就要实现高亮相关度排序等全文检索的功能。针对这种情况,企业实现功能业务流程如图:
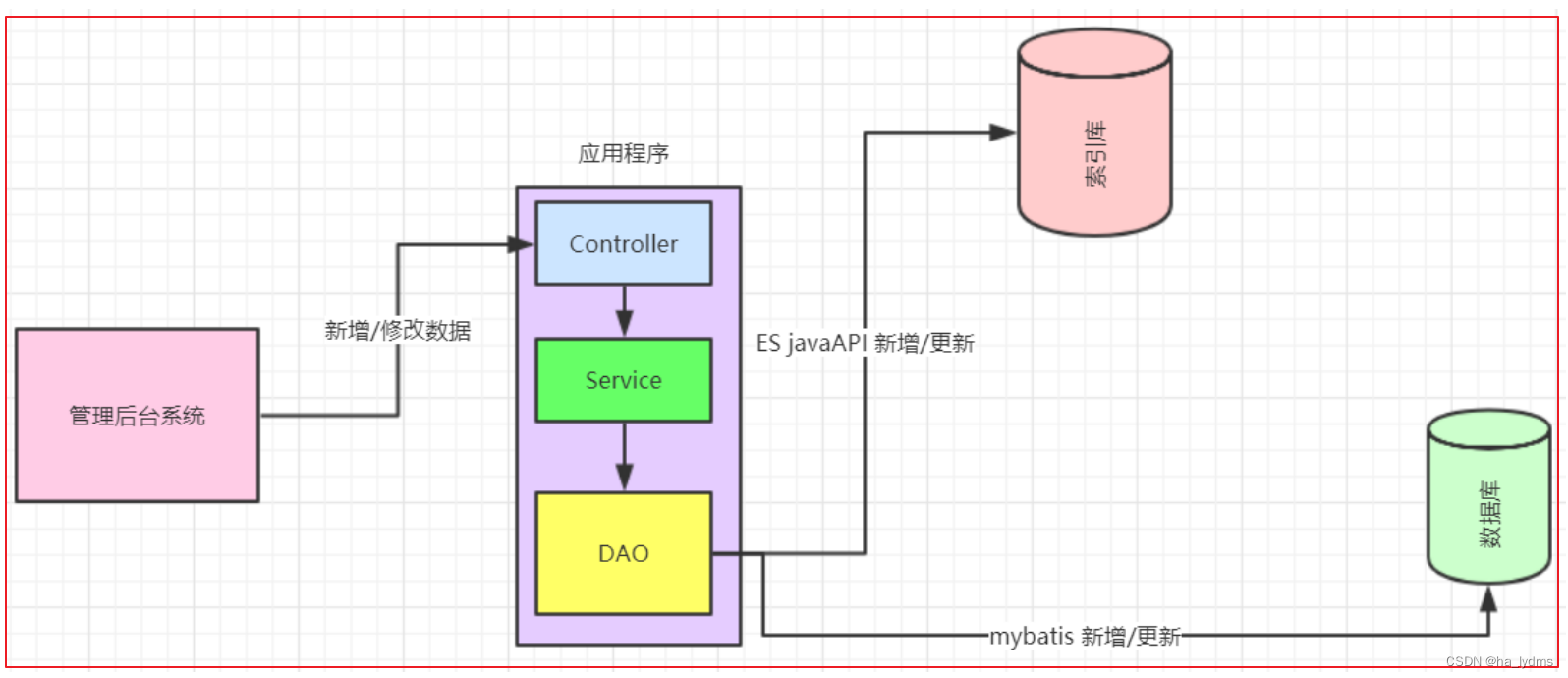
3.3 索引库存什么数据
索引库的数据是用来搜索用的,里面存储的数据和数据库一般不会是完全一样的,一般都比数据库的数据少。
那索引库存什么数据呢?
以业务需求为准,需求决定页面要显示什么字段以及会按什么字段进行搜索,那么这些字段就都要保存到索引库中。
二、软件安装
1、Elasticsearch安装
https://elasticstack.blog.csdn.net/article/details/99413578
- 1
2.1 下载ES压缩包
目前Elasticsearch最新的版本是7.4.2,我们使用6.8.0版本,建议使用JDK1.8及以上
Elasticsearch分为Linux和Window版本,基于我们主要学习的是Elasticsearch的Java客户端的使用,所以我们课程中使用的是安装较为简便的Window版本,项目上线后,公司的运维人员会安装Linux版的ES供我们连接使用。
Elasticsearch的官方地址:https://www.elastic.co/cn/downloads/past-releases
https://www.elastic.co/cn/downloads/past-releases
- 1
2.2 安装ES服务
Window版的Elasticsearch的安装很简单,类似Window版的Tomcat,解压开即安装完毕,解压后的Elasticsearch的目录结构如下:
2.3 启动ES服务
点击Elasticsearch下的bin目录下的Elasticsearch.bat启动,控制台显示的日志信息如下:
2.4 检测
9300是tcp通讯端口,集群间和TCP 客户端都执行该端口,9200是http协议的RESTful接口 。
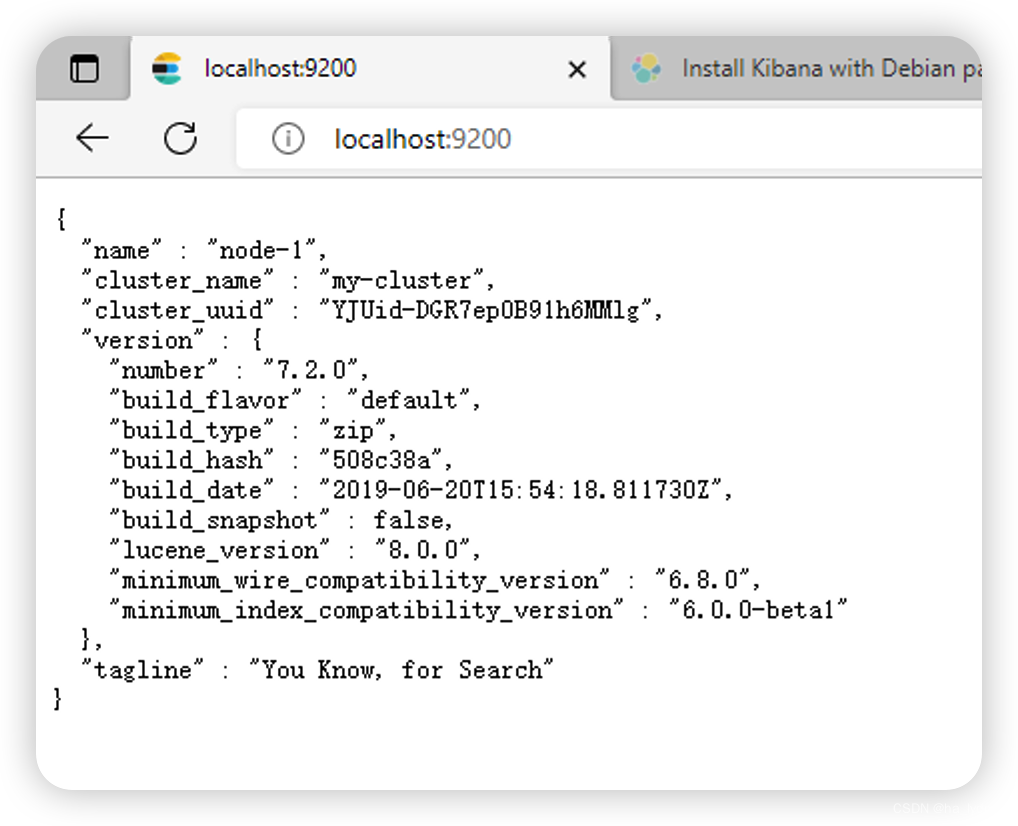
通过浏览器访问Elasticsearch服务器,看到如下返回的json信息,代表服务启动成功:
ElasticSearch6.8.0默认占用本机内存1个G,如果不足,建议改小一点。经测试125m足够开发测试使用。
修改配置文件D:\elasticsearch-6.8.0\config\jvm.options
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms1g
-Xmx1g
- 1
- 2
- 3
- 4
2.5 安装问题
2.5.1 启动失败(未安装JDK)
注意:Elasticsearch是使用java开发的,且本版本的es需要的jdk版本要是1.8及以上,所以安装Elasticsearch之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动Elasticsearch失败。
2.5.2 本机可用公网不可用
默认情况下,ES只允许本机访问,如果需要远程访问,可以修改 ES安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动ES。
network.host: 0.0.0.0
- 1
2.5.3 启动报错(缺少配置文件)
报错内容
ERROR: [1] bootstrap checks failed
[1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
- 1
- 2
新增配置内容
复制代码重点是 node.name 和 cluster.initial_master_node
cluster.name: "my-cluster"
network.host: 0.0.0.0
node.name: "node-1"
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
cluster.initial_master_nodes: ["node-1"]
# 开启跨域访问支持,默认为false
http.cors.enabled: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2 安装ES插件ElasticSearch-head
- 在Chrome浏览器地址栏中输入:chrome://extensions/
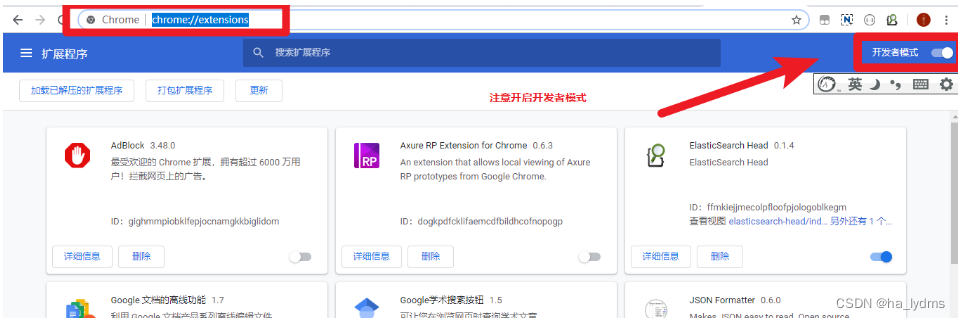
- 打开Chrome扩展程序的开发者模式
- 将资料中的
ElasticSearch-head-Chrome插件.crx拖入浏览器的插件页面:
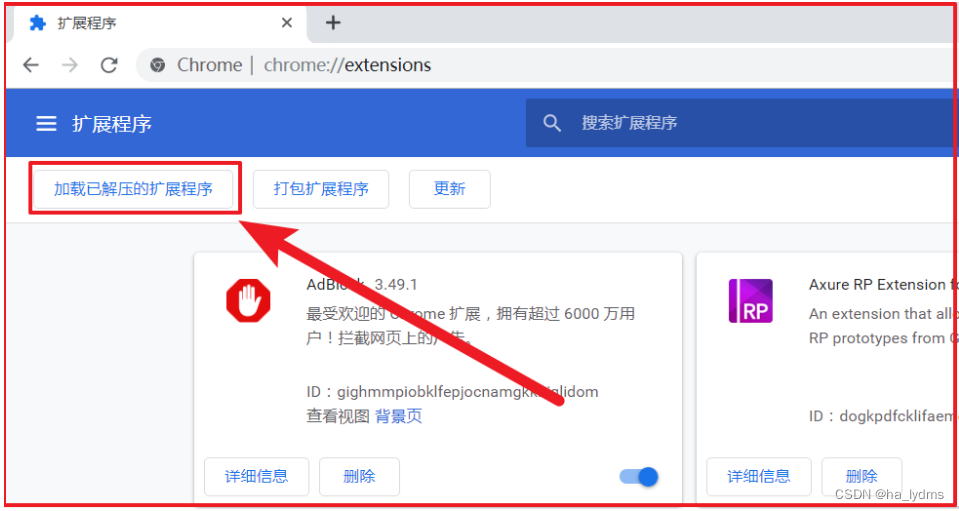
- 解压crx插件,通过加载已解压的扩展程序来加载
- 最后即可安装成功
3、安装Kibana
3.1 什么是Kibana
Kibana是ElasticSearch的数据可视化和实时分析的工具,利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
https://www.elastic.co/cn/products/kibana
3.2 安装配置
2.1 解压即安装成功
2.2 进入安装目录下的config目录的kibana.yml文件
修改elasticsearch服务器的地址:
elasticsearch.url: "http://localhost:9200"
- 1
修改kibana配置支持中文:
i18n.locale: "zh-CN"
- 1
3.3 运行访问
4.1 进入安装目录下的bin目录
4.2 双击运行,启动成功:
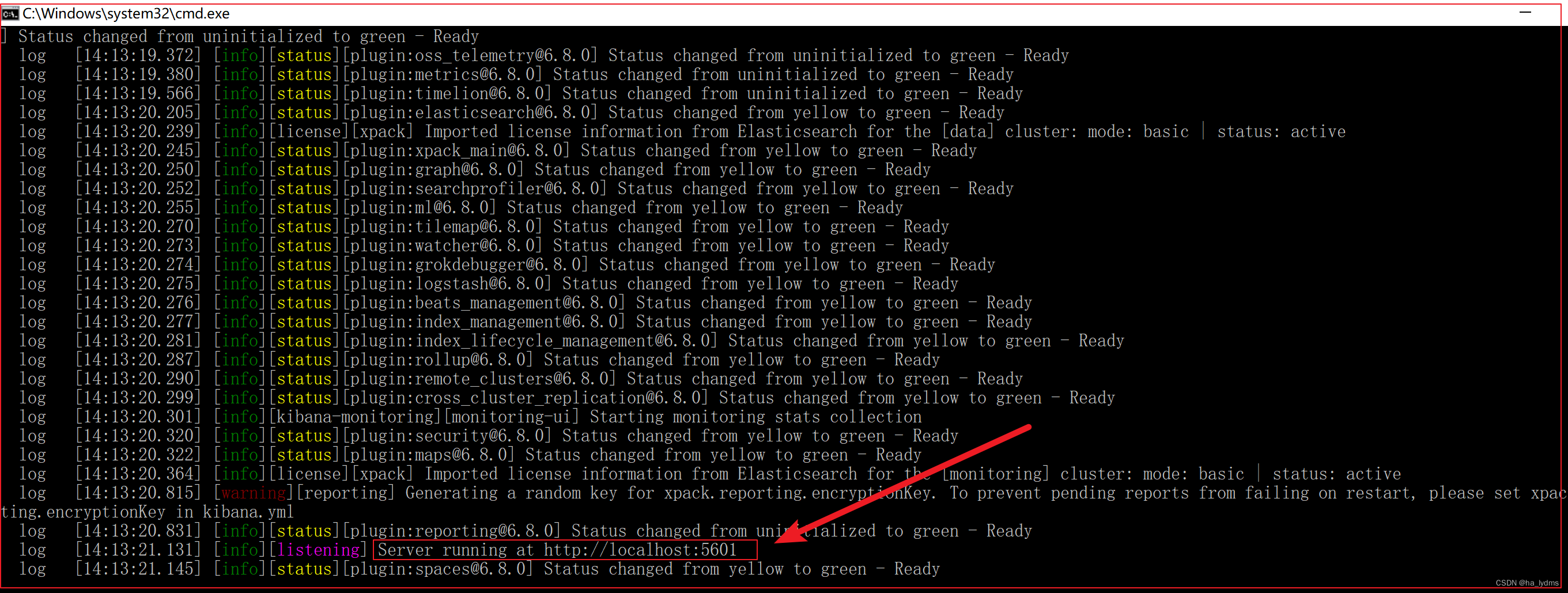
4.3 发现kibana的监听端口是5601,我们访问:http://127.0.0.1:5601
2.4 集成IK分词器
Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为Elasticsearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致。
GitHub仓库地址:https://github.com/medcl/elasticsearch-analysis-ik
下载插件:
4.1 安装插件
插件已经在资料中准备好了,解压之后,存放到D:\elasticsearch-6.8.0\plugins\目录中,即可安装成功插件。
注意:解压的时候,如下文件必须在plugins目录的第一级目录下
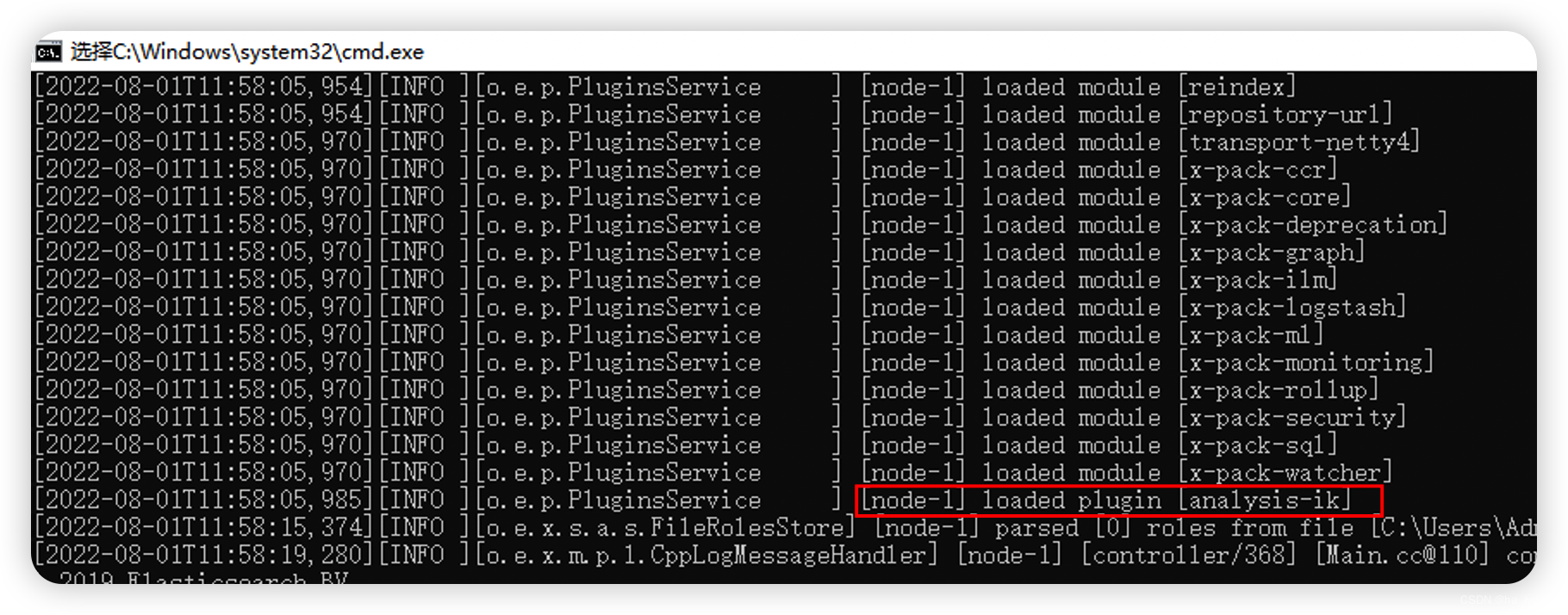
重新启动ElasticSearch之后,看到如下日志代表安装成功
4.1 测试
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
- ik_max_word:会将文本做最细粒度的拆分
- ik_smart:会做最粗粒度的拆分
请求方式:POST
请求url:http://127.0.0.1:9200/_analyze
请求体:
{
"analyzer": "ik_smart",
"text": "南京市长江大桥"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
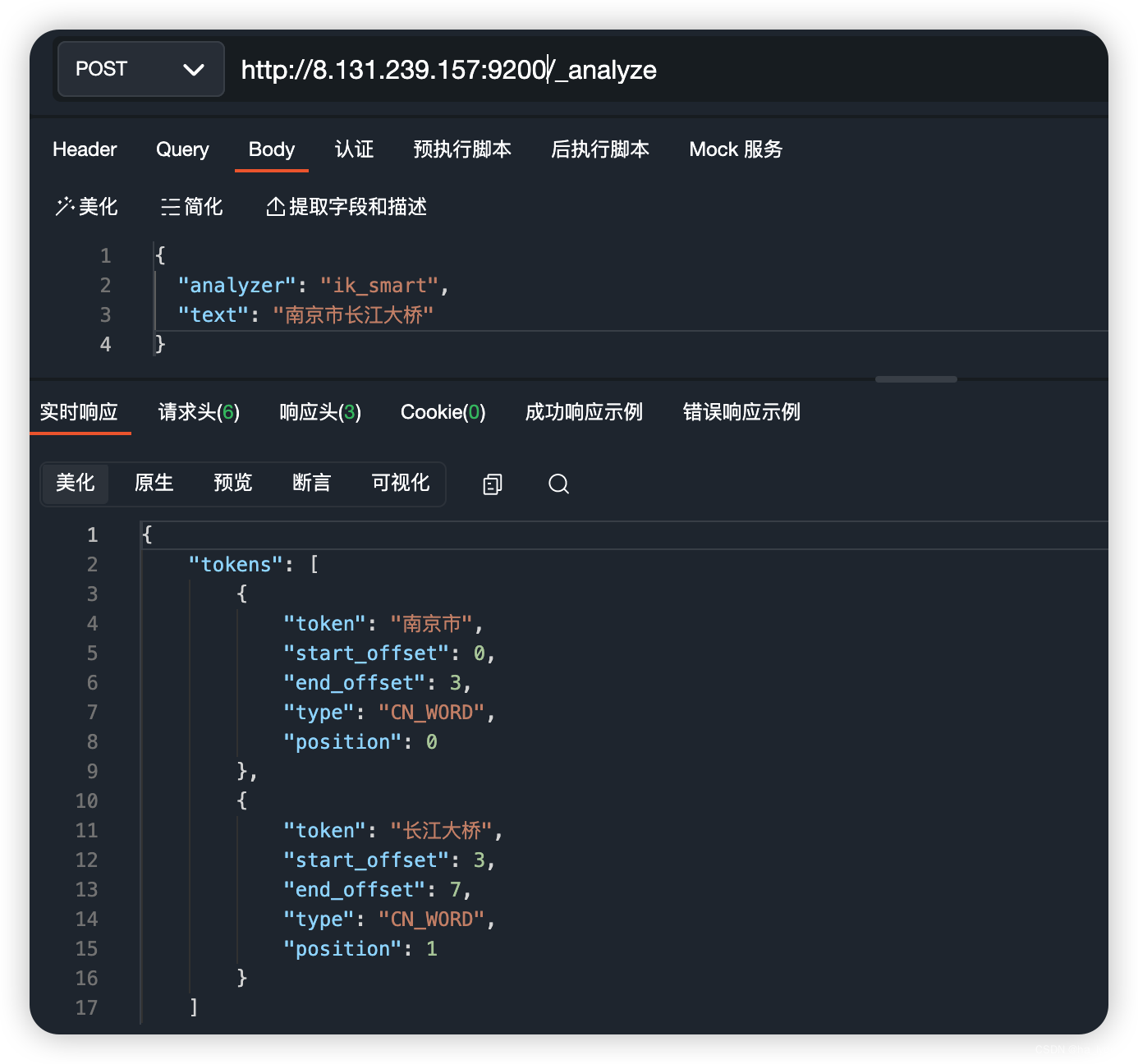
最细粒度的拆分结果:
{ "tokens": [ { "token": "南京市", "start_offset": 0, "end_offset": 3, "type": "CN_WORD", "position": 0 }, { "token": "长江大桥", "start_offset": 3, "end_offset": 7, "type": "CN_WORD", "position": 1 } ] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.3 添加扩展词典和停用词典
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。
扩展词:就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥
南京市长江大桥
自定义扩展词库
-
进入到
elasticsearch-6.8.0\plugins\elasticsearch-analysis-ik-6.8.0\config目录下, 新增自定义词典myext_dict.dic输入 :江大桥
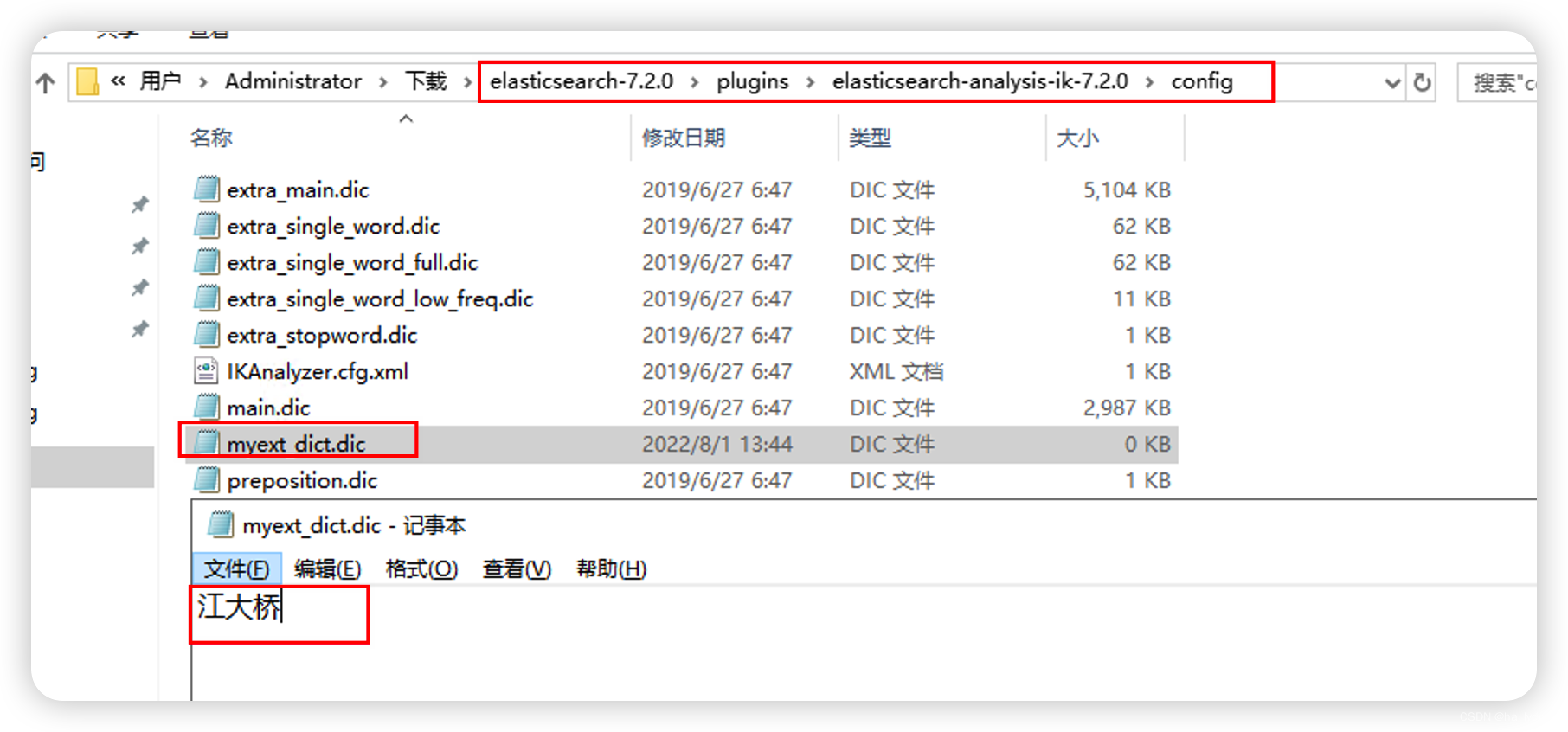
-
将我们自定义的扩展词典文件,配置到IKAnalyzer.cfg.xml文件中
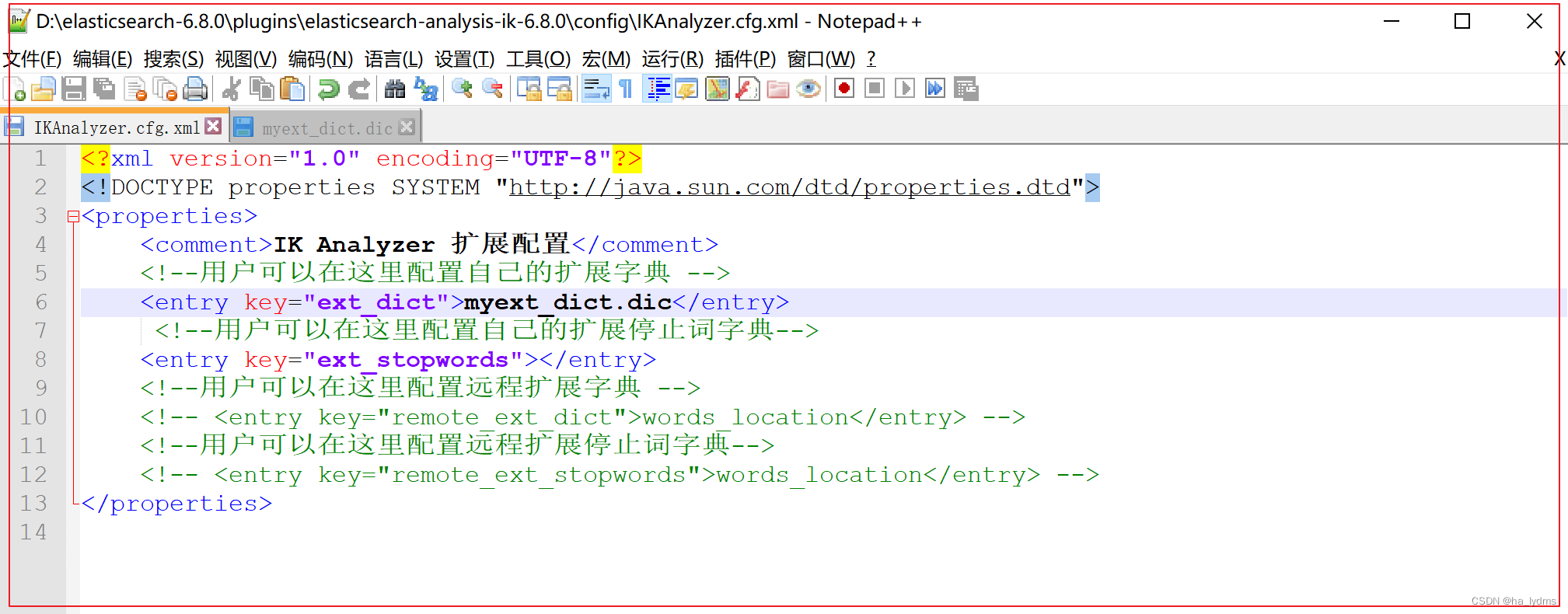
-
然后重启:

- 进行测试:
{ "tokens": [ { "token": "南京市", "start_offset": 0, "end_offset": 3, "type": "CN_WORD", "position": 0 }, { "token": "市长", "start_offset": 3, "end_offset": 5, "type": "CN_WORD", "position": 1 }, { "token": "江大桥", "start_offset": 5, "end_offset": 8, "type": "CN_WORD", "position": 2 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
三、集群搭建
单点的问题
单台服务器,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用。单点的elasticsearch也是一样,那单点的es服务器存在哪些可能出现的问题呢?
- 单台机器存储容量有限
- 单服务器容易出现单点故障,无法实现高可用
- 单服务的并发处理能力有限
所以,为了应对这些问题,我们需要对elasticsearch搭建集群
集群中节点数量没有限制,大于等于2个节点就可以看做是集群了。一般出于高性能及高可用方面来考虑集群中节点数量都是3个以上。
1、集群的相关概念
1.1 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“Elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
1.2 节点 node
一个节点是集群中的一个服务,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“Elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“Elasticsearch”的集群中。在一个集群里,只要你想,可以拥有任意多个节点。
1.3 分片和复制 shards&replicas
为了解决索引占用空间过大(1TB以上)这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。
为了提高分片高可用,Elasticsearch允许创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
2、集群的搭建
2.1 准备三台Elasticsearch服务器
创建Elasticsearch-cluster文件夹,在内部复制三个Elasticsearch服务
2.2 修改每台服务器配置
修改Elasticsearch-cluster\node*\config\Elasticsearch.yml配置文件
node1节点:
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-Elasticsearch
#节点名称,必须不一样
node.name: node-1
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
node2节点:
#节点2的配置信息:
#集群名称,保证唯一
cluster.name: my-Elasticsearch
#节点名称,必须不一样
node.name: node-2
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
node3节点:
#节点3的配置信息:
#集群名称,保证唯一
cluster.name: my-Elasticsearch
#节点名称,必须不一样
node.name: node-3
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9203
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9303
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.3 启动各个节点服务器
双击Elasticsearch-cluster\node*\bin\Elasticsearch.bat
启动节点1:
启动节点2:
启动节点3:
2.4 集群测试
添加索引和映射
请求方法:PUT 请求地址:http://127.0.0.1:9200/heima2 请求体: { "settings":{}, "mappings":{ "goods":{ "properties":{ "title":{ "type":"text", "analyzer":"ik_max_word" }, "subtitle":{ "type":"text", "analyzer":"ik_max_word" }, "images":{ "type":"keyword", "index":"false" }, "price":{ "type":"float" } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
添加文档
请求方法:POST
请求地址:http://127.0.0.1:9200/heima2/goods
请求体:
{
"title":"小米手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":2699.00
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
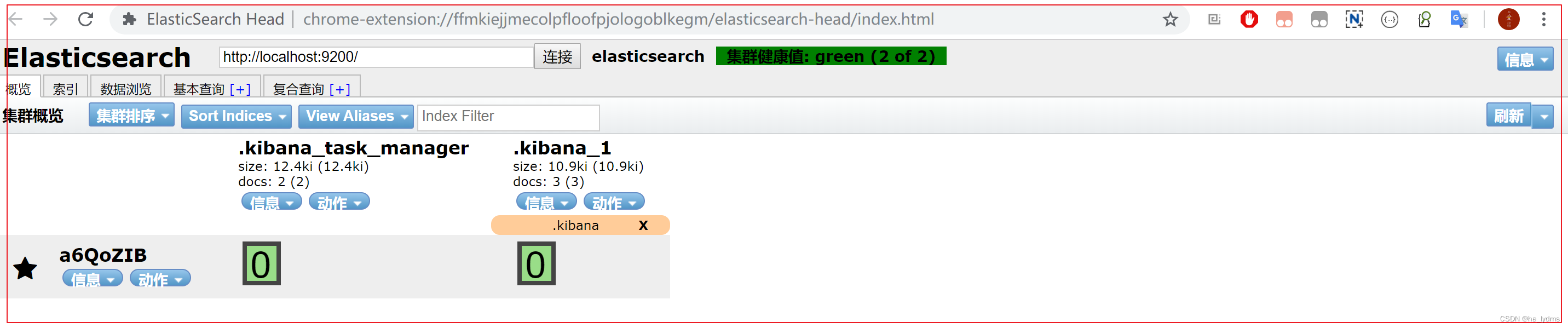
使用Elasticsearch-header查看集群情况
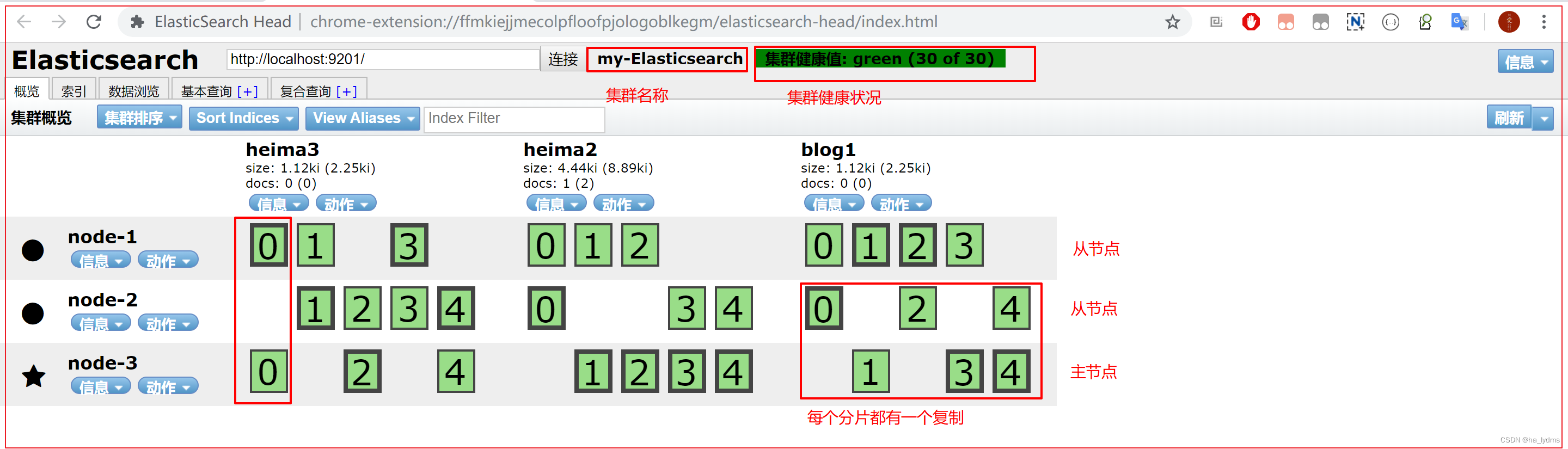
可以通过elasticsearch-head插件查看集群健康状态,有以下三个状态:

green
- 1
所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow
- 1
所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。
red
- 1
至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
四、下载地址
1、ElasticSearch-head
https://download.csdn.net/download/weixin_44624117/86269675
- 1
2、IK分词器
https://download.csdn.net/download/weixin_44624117/86269705
- 1

