
- 1Ubuntu20.04网络&&网络源配置_ubuntu如何安装networking服务的源
- 2想学编程,但不知道从哪里学起,应该怎么办?
- 3【nginx实战】通过nginx实现http 长连接(即keep alive)_nginx启用长连接
- 4python基于影像Dicom标签,计算患者年龄_mri数据预测大脑年龄python
- 5DPlayer视频播放器使用方法介绍
- 6Linux宝塔详细使用教程_宝塔如何找ssh文件
- 7内网渗透之Windows反弹shell(一)_windows命令行反弹shell
- 8【计算机毕设任务书】基于VUE框架的点餐系统设计与实现_点餐系统任务书
- 9炸裂!谷歌深夜开源最强大模型Gemma!完虐LLaMA 2!
- 10讨论开源软件影响力
自动驾驶合集8_drivegpt4: interpretable end-to-end autonomous dri
赞
踩
#大模型与自动驾驶论
LLM直接参与自动驾驶 (LLM + 端到端的自动驾驶,LLM + 语义场景理解,LLM + 驾驶行为生成)成为了一个比较火热的主旋律。另一些研究方向则关注在了多模态大模型进行仿真或世界模型的构建,也有部分学者尝试对大模型在自动驾驶应用中的安全性和可解释性作出了探讨。
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models
论文来自上海AILAB和东南大学,通过LLM的理解环境能力,作者尝试构建闭环系统探索LLM在自动驾驶的环境理解和环境互动的可行性,并且发现其在推理和解决长尾问题上也有一定的能力。
DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
来自港大和诺亚实验室,DriveGPT4是一个使用LLM的可解释的端到端自动驾驶系统,能够解释车辆行为并提供相应的推理,还可以回答用户提出的各种问题,以增强互动性。此外,DriveGPT4以端到端的方式预测车辆的低级控制信号。
DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models
这是一个上海AI Lab提出了DiLu框架,它结合了推理和反思模块,使系统能够基于常识知识做出决策并不断演化。大量实验证明DiLu能够积累经验,并在泛化能力上明显优于基于强化学习的方法。此外,DiLu能够直接从现实世界的数据集中获取经验,突显了其在实际自动驾驶系统上的潜力。
GPT-Driver: Learning to Drive with GPT
这是一篇南加州大学的论文,可以将OpenAI GPT-3.5模型转化为可靠的自动驾驶车辆运动规划器。GPT-Driver将规划器的输入和输出表示为语言标记,并利用LLM通过坐标位置的语言描述生成驾驶轨迹。提出了一种新颖的提示-推理-微调策略,以激发LLM的数值推理潜力。借助这一策略,LLM可以用自然语言描述高度精确的轨迹坐标,以及其内部的决策过程。
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
这篇文章来自于Wayve, 论文中引入了一种独特的物体级多模态LLM架构,将向量化数字模态与预训练的LLM相结合,以提高在驾驶情景中的上下文理解能力。除此之外论文还提供了一个包含来自1万个驾驶情景的160,000个问答对的新数据集,与由RL代理程序收集的高质量控制命令和由教师LLM(GPT-3.5)生成的问答对相配对。
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving
这篇文章来自于清华大学和UC Berkeley,本研究将大型语言模型(LLMs)作为复杂AD场景的决策组件,这些场景需要人类的常识理解。作者设计了认知路径,以使LLMs能够进行全面的推理,并开发了将LLM决策转化为可执行驾驶命令的算法。通过这种方法,LLM决策可以通过引导参数矩阵适应与低级控制器无缝集成。
Receive, Reason, and React: Drive as You Say with Large Language Models in Autonomous Vehicles
本文来自Purdue University,研究包括在HighwayEnv中进行的实验,这是一个用于自动驾驶和战术决策任务的环境集合,旨在探讨LLMs在不同场景中的解释、互动和推理能力。作者还研究了实时个性化,展示了LLMs如何基于口头命令影响驾驶行为。论文的实证结果突显了采用“思维链”提示的重大优势,从而改进了驾驶决策,并展示了LLMs通过持续的口头反馈提升个性化驾驶体验的潜力。
Drive as You Speak: Enabling Human-Like Interaction with Large Language Models in Autonomous Vehicles
本文来自Purdue University,本文主要讨论如何利用大型语言模型(LLMs)来增强自动驾驶汽车的决策过程。通过将LLMs的自然语言能力和语境理解、专用工具的使用、推理与自动驾驶汽车上的各种模块的协同作用整合在一起。
SurrealDriver: Designing Generative Driver Agent Simulation Framework in Urban Contexts based on Large Language Model
本文来自清华大学,提出了一种基于大型语言模型(LLMs)的生成式驾驶代理模拟框架,能够感知复杂的交通场景并提供逼真的驾驶操控。值得注意的是,我们与24名驾驶员进行了访谈,并使用他们对驾驶行为的详细描述作为“思维链”提示,开发了一个“教练代理”模块,该模块可以评估和协助驾驶代理积累驾驶经验并培养类似人类的驾驶风格。
Language-Guided Traffic Simulation via Scene-Level Diffusion
哥伦比亚大学和Nvidia联合提出了CTG++,一种能够受到语言指导的场景级条件扩散模型。开发这一模型需要解决两个挑战:需要一个现实且可控的交通模型骨干,以及一种使用语言与交通模型进行交互的有效方法。为了解决这些挑战,我们首先提出了一个配备有时空变换器骨干的场景级扩散模型,用于生成现实且可控的交通。然后,我们利用大型语言模型(LLM)将用户的查询转化为损失函数,引导扩散模型生成符合查询的结果。
Language Prompt for Autonomous Driving
本文由北理和旷世提出,在驾驶场景中使用语言提示的进展受到了数据匹配的瓶颈问题的限制,因为匹配语言提示和实例数据的配对数据相对稀缺。为了解决这一挑战,本文提出了第一个针对三维、多视图和多帧空间内的驾驶场景的以物体为中心的语言提示集,名为NuPrompt。它通过扩展Nuscenes数据集,构建了共计35,367个语言描述,每个描述涉及平均5.3个物体轨迹。基于新的数据集中的物体-文本配对,我们提出了一项新的基于提示的驾驶任务,即使用语言提示来预测跨视图和帧描述的物体轨迹。
Talk2BEV: Language-Enhanced Bird's Eye View (BEV) Maps
本文来自海得拉巴国际信息技术学院,Talk2BEV结合了通用语言和视觉模型的最新进展以及BEV结构化地图表示,消除了需要专门的任务模型。这使得一个单一系统能够满足各种自动驾驶任务,包括视觉和空间推理、预测交通参与者的意图以及基于视觉线索进行决策
BEVGPT: Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning
港科大提出了BEVGPT,这是一个集成了驾驶情境预测、决策和运动规划的生成式预训练大模型。该模型以鸟瞰图(BEV)图像作为唯一的输入源,并基于周围的交通情景做出驾驶决策。为了确保驾驶轨迹的可行性和平稳性,我们开发了一种基于优化的运动规划方法。我们在Lyft Level 5数据集上实例化了BEVGPT,并使用Woven Planet L5Kit进行了真实驾驶模拟。
DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving
GigaAI和清华携手推出DriveDreamer,这是一个全新的世界模型,完全源自真实的驾驶场景。鉴于在复杂的驾驶场景中对世界进行建模涉及庞大的搜索空间,该文章提出利用强大的扩散模型构建复杂环境的综合表示。此外,论文中引入了一个两阶段训练流程。在初始阶段,DriveDreamer深入了解结构化的交通约束,而随后的阶段赋予其预测未来状态的能力。DriveDreamer是第一个建立在真实世界驾驶场景中的世界模型。
MagicDrive: Street View Generation with Diverse 3D Geometry Control
MagicDrive,这是一个新颖的街景生成框架,提供多样的3D几何控制,包括相机位置、道路地图和3D边界框,还包括文本描述,通过定制的编码策略实现。此外,论文的设计还包括一个跨视图注意力模块,确保多个相机视图之间的一致性。使用MagicDrive实现了高保真的街景合成,捕捉了精细的3D几何形状和各种场景描述,增强了鸟瞰图分割和3D物体检测等任务的性能。
GAIA-1: A Generative World Model for Autonomous Driving
近期大名鼎鼎的GAIA-1('Generative AI for Autonomy')这是一个生成式世界模型,由Wayve推出,利用视频、文本和行为输入来生成逼真的驾驶场景,同时对自车行为和场景特征进行精细控制。我们的方法将世界建模视为一个无监督的序列建模问题,通过将输入映射到离散标记,并预测序列中的下一个标记。我们模型中的新特性包括学习高级结构和场景动态、上下文意识、泛化能力以及对几何形状的理解。GAIA-1学得的表示能够捕获未来事件的期望,再加上其生成逼真样本的能力,为自动驾驶技术领域的创新提供了新的可能性,实现了自动驾驶技术的增强和加速训练。
HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving
本文由港科大和诺亚实验室提出,首次利用单一的多模态大型语言模型(MLLMs)来整合多个自动驾驶任务,即风险目标定位和意图与建议预测(ROLISP)任务。ROLISP使用自然语言来同时识别和解释风险目标,理解自动驾驶汽车的意图,并提供运动建议,消除了需要特定任务架构的必要性。
Can you text what is happening? Integrating pre-trained language encoders into trajectory prediction models for autonomous driving
这篇文章来自自动驾驶Tier 1, Bosch,文章提出了一种新颖的基于文本的交通场景表示,并使用预训练的语言编码器处理它。首先,我们展示了文本表示与传统的栅格化图像表示相结合,可以产生描述性的场景嵌入。
OpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data
复旦大学提出了OpenAnnotate3D,这是一个开源的开放词汇自动标注系统,可以自动生成用于视觉和点云数据的2D掩模、3D掩模和3D边界框注释。我们的系统整合了大型语言模型(LLMs)的思维链能力和视觉语言模型(VLMs)的跨模态能力。
LangProp: A Code Optimization Framework Using Language Models Applied to Driving
LangProp自动评估了输入-输出对数据集上的代码性能,以及捕获任何异常,并将结果反馈给LLM在训练循环中,使LLM可以迭代地改进其生成的代码。通过采用度量和数据驱动的代码优化过程的训练范式,可以轻松地借鉴传统机器学习技术,如模仿学习、DAgger和强化学习等的发现。在CARLA中展示了自动代码优化的第一个概念验证,证明了LangProp可以生成可解释且透明的驾驶策略,可以以度量和数据驱动的方式进行验证和改进。
Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
作者确定了两个主要瓶颈原因:处理复杂和无结构的观测空间以及具备可扩展性的生成模型。因此,我们提出了一种新颖的世界建模方法,首先使用VQVAE对传感器观测进行标记,然后通过离散扩散来预测未来。为了高效地并行解码和去噪标记,我们将遮蔽的生成式图像变换器重新构建成离散扩散框架,只需进行一些简单的更改,结果有显著的改进。
Planning with an Ensemble of World Models
特定于城市的gym(例如波士顿-Gym和匹兹堡-Gym)来评估规划性能。使用我们提出的gym集合来评估最先进的规划器导致性能下降,这表明一个优秀的规划器必须适应不同的环境。借助这一见解,我们提出了City-Driver,一种基于模型预测控制(MPC)的规划器,它展开了适应不同驾驶条件的城市特定世界模型。
Large Language Models Can Design Game-Theoretic Objectives for Multi-Agent Planning
论文首先展示了更强大的LLM(如GPT-4)在调整连续目标函数参数方面的zero-shot能力,以符合自动驾驶示例的指定高级目标。然后,作者开发了一种规划器,它将LLM作为矩阵游戏的设计者,用于具有离散有限动作空间的场景。在给定场景历史、每个智能体可用的动作和高级目标(用自然语言表达)时,LLM评估与每种动作组合相关的回报。从获得的博弈结构中,智能体执行Nash最优动作,重新评估场景,并重复该过程。
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction
作者展示了数据驱动的交通仿真可以被构建为一个世界模型。文章提出了TrafficBots,这是一个基于运动预测和端到端驾驶的多智能体策略,基于TrafficBots获得了一个专门为自动驾驶车辆的规划模块定制的世界模型。现有的数据驱动交通仿真器缺乏可配置性和可扩展性。为了生成可配置的行为,对于每个智能体引入了目的地作为导航信息,以及一个不随时间变化的潜在个性,指定了行为风格。为了提高可扩展性提出了一种用于角度的位置编码的新方案,允许所有智能体共享相同的矢量化上下文,以及基于点积注意力的架构。
BEV-CLIP: Multi-Modal BEV Retrieval Methodology for Complex Scene in Autonomous Driving
在现有的二维图像检索方法下,可能会出现一些场景检索的问题,比如缺乏全局特征表示和次优的文本检索能力。为了解决这些问题,本文作者提出了BEV-CLIP,这是第一个利用描述性文本作为输入以检索相应场景的多模态BEV检索方法。这种方法应用了大型语言模型(LLM)的语义特征提取能力,以便进行广泛的文本描述的零次检索,并结合了知识图的半结构信息,以提高语言嵌入的语义丰富性和多样性。
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
Waymo引入了Waymax,这是一种用于自动驾驶多智体场景的新型数据驱动模拟器,专为大规模模拟和测试而设计。Waymax使用已公开发布的实际驾驶数据(例如Waymo开放运动数据集)来初始化或回放各种多智体模拟场景。它完全在硬件加速器上运行,如TPU/GPU,并支持用于训练的图内模拟,使其适用于现代的大规模分布式机器学习工作流。
Semantic Anomaly Detection with Large Language Models
这篇论文随着机器人获得越来越复杂的技能并观察到越来越复杂和多样化的环境,边缘案例或异常故障的威胁随时存在。这些系统级故障不是由于自动驾驶系统堆栈的任何单个组件的故障,而是由于语义推理方面的系统级缺陷。这种称之为语义异常的边缘情况对于人类来说很容易解开,但需要具有深刻推理能力。为此,作者研究了赋予大型语言模型(LLMs)广泛的上下文理解和推理能力,以识别这类边缘情况,并引入了一种基于视觉策略的语义异常检测的监控框架。我们将这一框架应用于自动驾驶的有限状态机策略和物体操作的学习策略。
Driving through the Concept Gridlock: Unraveling Explainability Bottlenecks in Automated Driving
在人工辅助或自动驾驶的背景下,可解释性模型可以帮助用户接受和理解自动驾驶车辆所做的决策,这可以用来解释和说明驾驶员或车辆的行为。论文中提出了一种新方法,使用概念瓶颈作为控制命令预测和用户以及车辆行为解释的视觉特征。作者学习了一个人可以理解的概念层,用来解释顺序驾驶场景,同时学习车辆控制命令。这种方法可以用来确定人类(或自动驾驶车辆)对于首选车距或转向命令的改变是否受到外部刺激或偏好的改变的影响。
Drama: Joint risk localization and captioning in driving
考虑到在安全关键的自动化系统中的情境感知功能,对驾驶场景中风险的感知以及其可解释性对于自动驾驶和合作驾驶尤为重要。为实现这一目标,本文提出了一个新的研究方向,即驾驶场景中的风险联合定位及其以自然语言描述的风险解释。由于缺乏标准基准,作者的研究团队收集了一个大规模数据集,名为DRAMA(带有字幕模块的驾驶风险评估机制),其中包括了在日本东京收集的17,785个交互式驾驶场景。我们的DRAMA数据集包含了有关驾驶风险的视频和对象级问题,以及与重要对象相关的问题,以实现自由形式的语言描述,包括多级问题的封闭和开放式回答,可用于评估驾驶场景中的各种图像字幕能力。
3D Dense Captioning Beyond Nouns: A Middleware for Autonomous Driving
作者认为一个主要的大语言模型很难获得安全驾驶的障碍是缺乏将感知和规划连接起来的综合和标准的中间件表示。作者重新思考了现有中间件的局限性(例如,3D框或占用情况)并提出了超越名词的3D密集字幕(简称为DESIGN)。对于每个输入场景,DESIGN指的是一组带有语言描述的3D边界框。特别是,综合的描述不仅包括这个框是什么(名词),还包括它的属性(形容词),位置(介词)和运动状态(副词)。我们设计了一种可扩展的基于规则的自动标注方法来生成DESIGN的地面真实数据,以确保中间件是标准的。
SwapTransformer: Highway Overtaking Tactical Planner Model via Imitation Learning on OSHA Dataset
这篇论文研究了关于在高速公路情境中进行变道和超越其他较慢车辆的高级决策问题。具体来说,本文旨在改进旅行辅助功能,以实现对高速公路上的自动超车和变道。在模拟中收集了大约900万个样本,包括车道图像和其他动态对象。这些数据构成了"模拟高速公路上的超车"(OSHA)数据集,用于解决这一挑战。为了解决这个问题,设计并实施了一种名为SwapTransformer的架构,作为OSHA数据集上的模仿学习方法。此外,提出了辅助任务,如未来点和汽车距离网络预测,以帮助模型更好地理解周围环境。提出的解决方案的性能与多层感知器(MLP)和多头自注意力网络作为基线在模拟环境中进行了比较。
NuScenes-QA: A Multi-modal Visual Question Answering Benchmark for Autonomous Driving Scenario
本文来自于复旦大学,作者引入了一个新颖的视觉问答(VQA)任务,即自动驾驶背景下的VQA任务,旨在基于街景线索回答自然语言问题。与传统的VQA任务相比,自动驾驶场景中的VQA任务具有更多挑战。首先,原始的视觉数据是多模态的,包括由摄像机和激光雷达(LiDAR)捕获的图像和点云数据。其次,由于连续实时采集,数据是多帧的。第三,室外场景同时包括移动的前景和静态的背景。现有的VQA基准未能充分解决这些复杂性。为了填补这一差距,作者提出了NuScenes-QA,这是自动驾驶场景中的第一个VQA基准,包括34,000个视觉场景和460,000个问题-答案对。具体而言利用现有的3D检测注释生成场景图,并手动设计问题模板。随后,问题-答案对是基于这些模板自动生成的。全面的统计数据证明了我们的NuScenes-QA是一个平衡的大规模基准,具有多样的问题格式。
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
随着自动驾驶技术的成熟,端到端方法已经成为一种主要策略,承诺通过深度学习实现从感知到控制的无缝集成。然而,现有系统面临着意想不到的开放环境和黑盒模型复杂性等挑战。与此同时,深度学习的发展引入了更大的多模态基础模型,提供了多模态的视觉和文本理解。在本文中,作者利用这些多模态基础模型来增强自动驾驶系统的健壮性和适应性,实现了端到端的多模态和更具解释性的自主性,使其能够在分布之外、端到端、多模态和更具解释性的环境下进行操作。具体而言,作者提出了一种应用端到端开放集(任何环境/场景)自动驾驶的方法,能够从可通过图像和文本查询的表示中提供驾驶决策。为此,文中引入了一种从Transformer中提取微妙的空间(像素/补丁对齐)特征的方法,以实现空间和语义特征的封装。我们的方法在多种测试中表现出色,同时在分布之外的情况下具有更大的健壮性,并允许通过文本进行潜在空间模拟,从而改进训练(通过文本进行数据增强)和策略调试。
Vision Language Models in Autonomous Driving and Intelligent Transportation Systems
最后这篇是一篇综述,这篇文章来自于慕尼黑工业大学的IEEE Fellow, Alois C. Knoll. 2023年是视觉-语言大模型的爆发年,其的出现改变了计算机领域的方方面面。同样的,视觉语言大模型在自动驾驶(AD)和智能交通系统(ITS)领域的应用引起广泛关注。通过整合视觉语言数据,车辆和交通系统能够深入理解现实场景环境,提高驾驶安全性和效率。这篇综述全面调研了该领域视觉语言大模型的各类研究进展,包括现有的模型和数据集。此外,该论文探讨了视觉语言大模型在自动驾驶领域潜在的应用和新兴的研究方向,详细讨论了挑战和研究空白。
whaosoft aiot http://143ai.com
#上汽飞凡 R7 智联 T-BOX 拆解分析
上汽飞凡R7的电子架构是由零束研发的,共有智联、智算、智驾、座舱四个域控制器。智联域控即类似于传统的T-box模块。 这里的V2X芯片也是高通的哦~~~
1、T-BOX简介
TBOX全称:Telematics Box,中文名:远程通信终端,是一种集成了智能信息处理和通信技术的汽车电子模块,它能够实现车辆与外界的无线通信,为驾驶员和车辆提供各种便利与安全保障。智联TBOX一般会安装在车辆仪表盘的下方位置。通过TBOX和手机APP可以实现很多功能,如通过手机APP控制门开关、鸣笛闪灯、开启空调、启动发动机等;还可以实现远程查询车辆状态,油箱剩余油量、电池电量、查询车辆位置、查询车辆是否上锁等功能。总之TBOX给车主带来了非常便利的出行体验。下面将从TBOX外壳、内部电路及系统组成等方面为您解析上汽飞凡R7智联-TBOX的神奇之处。
2、外壳及端子
2.1、外壳
如下图TBOX的外壳由两块金属件组成,正面金属外壳带有散热槽设计

2.2、线束端子说明:

图3 TBOX线束端子
TBOX上有电源、UART/CAN总先、以太网端口、4G/5G天线、和GPS天线等端子。
3、TBOX组成
TBOX主要由SOC芯片、MCU芯片、通信模块、加密芯片、交换机芯片、存储芯片、电源管理芯片和GNSS模块组成。如下图:
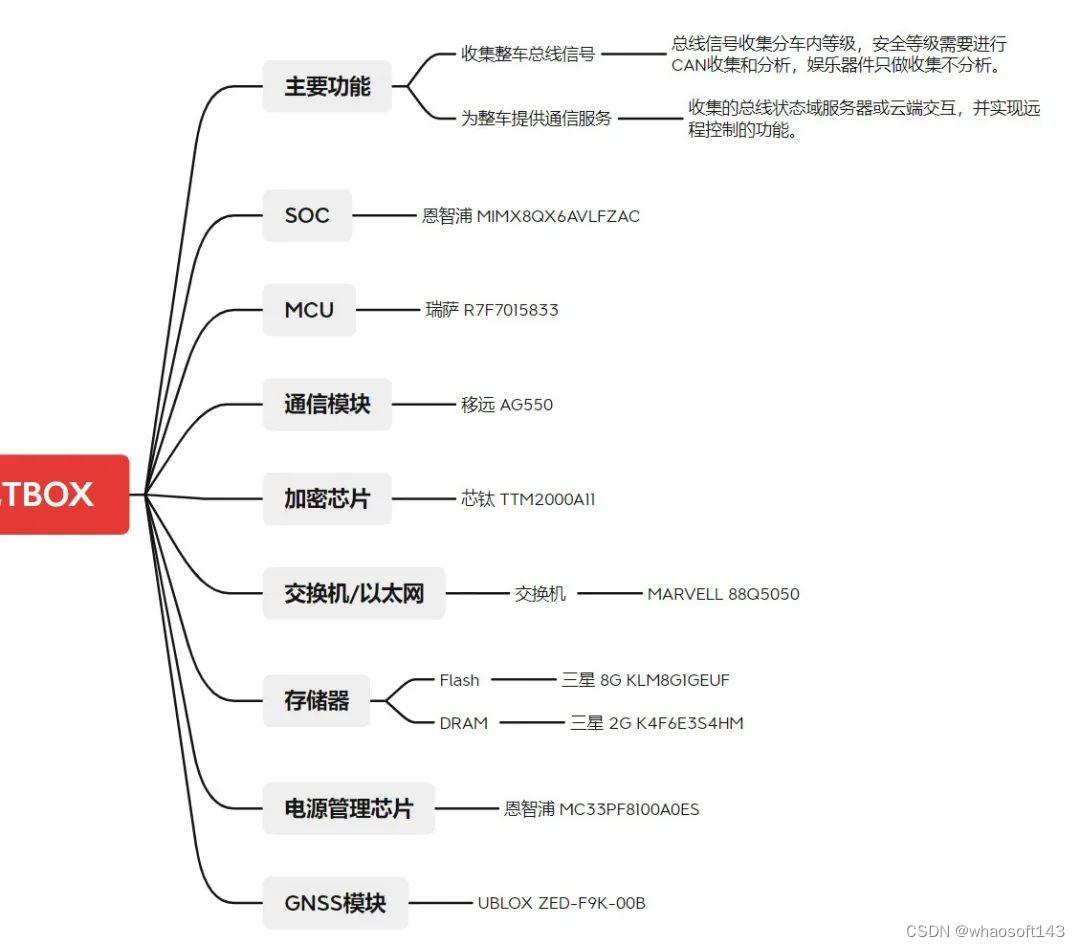
图4 飞凡R7 TBOX组成思维导图
各模块功能及常用方案:
3.1、SOC芯片的作用及常用型号
SOC芯片是汽车TBOX中的重要组成部分,它负责处理车辆信息和实现各种功能。SOC芯片通常由多个核心组成,每个核心负责不同的任务,使得TBOX可以同时进行多个任务的处理。常用的SOC芯片型号有恩智浦的IMX6和IMX8。这些芯片具有强大的计算和图像处理能力,可以支持高清视频的播放和实时图像的分析,为TBOX提供了强大的计算和处理能力。
3.2、MCU芯片的作用及常用型号
MCU芯片是控制车辆各种传感器和执行器的重要部件,它负责实时监测车辆的状态,并根据需要控制各个系统的运行。常用的MCU芯片型号有英飞凌(Infineon)的TC2x和TC3x系列、恩智浦S32K14X和瑞萨R7F7X等。这些芯片具有高性能和低能耗的特点,可以满足TBOX在车辆控制和监测方面的需求。
3.3、通信模块的功能及常用模块型号
通信模块是TBOX中实现车辆与外界通信的关键组件,它可以通过无线网络连接到互联网,实现车辆信息的传输和远程控制。常用的通信模块型号有华为的ME909s、MH5000系列和移远AG35、AG550、AG520等。这些模块支持5G、4G、3G网络,移远AG520、AG550和华为的MH5000支持V2X,具有稳定可靠的连接性能,能够实现高速数据传输和远程控制功能。
3.4、GPS模块的功能及常用模块型号
GPS模块是TBOX中用于定位和导航的关键部件,它能够接收卫星信号,并通过定位算法计算出车辆的准确位置。常用的GPS模块型号有:和芯星通UM960、UM982和ublox的ZED-F9K、ZED-F9P、ZED-F9H等。这些模块具有快速定位、高精度和稳定性的特点,能够满足TBOX在导航和定位方面的需求。
3.5、交换机芯片的功能及常用芯片型号
交换机芯片是TBOX中实现数据交换和通信的重要部件,它可以实现车辆内各个子系统之间的数据传输和交互。常用的交换机芯片型号有博通(Broadcom)的BCM89x系列和MARVELL 88Q5050等系列。这些芯片具有高带宽和低延迟的特点,能够实现快速的数据传输和实时的系统交互。
3.6、加密芯片的功能及常用芯片型号
加密芯片是TBOX中保证数据安全和防止恶意攻击的关键组件,它可以对数据进行加密和解密,并实现访问控制和身份认证的功能。常用的加密芯片型号有infineonSLE 95250SLS32系列、Maxim DS28E25系列和上海芯钛的TTM2000、TTM3000系列。这些芯片具有高级加密算法和安全性能,能够保护TBOX中的数据免受非法获取和篡改。
4、飞凡R7 TBOX分析
飞凡R7 TBOX组成框图:
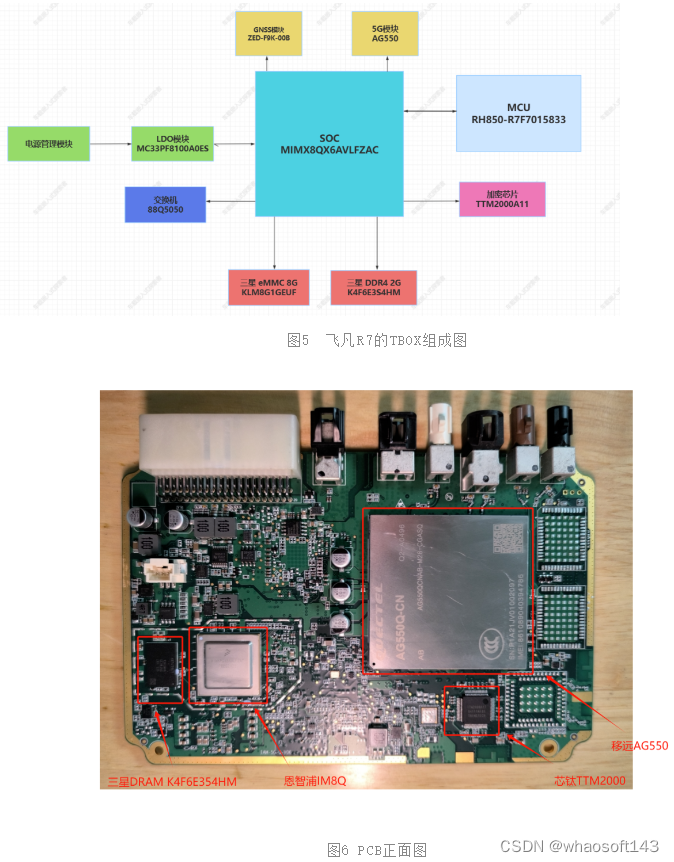

4.1、SOC-恩智浦 MIMX8QX6AVLFZAC

恩智浦 MIMX8QX6AVLFZAC简介
i.MX 8X系列处理器基于高度集成,可 支持图形、视频、图像处理和语音功能,能够满足安全认证和高能效方面的需求。适合的应用包 括工业自动化和控制、HMI、机器人、楼宇控制、汽车仪表盘、视频/音频、车载信息娱乐系统和 车载信息服务等。
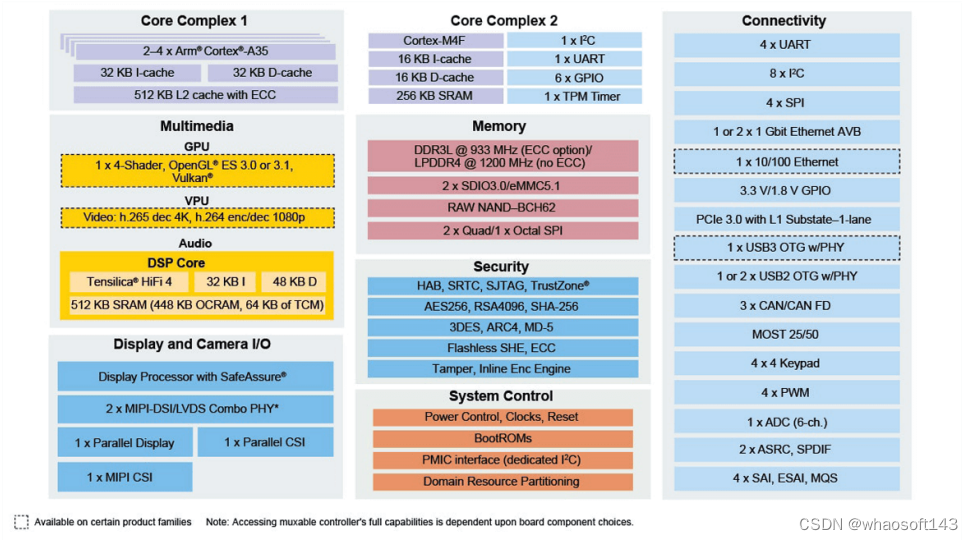
图9 i.MX 8X框图
特征:
| 处理器复合设备 | ·2-4个Cortex-A35内核 ·1个Cortex-M4F内核,进行实时处理 ·1个Tensilica® HiFi 4 DSP |
| 多媒体 | ·2个-4个Vec4-Shader GPU, OpenGL® ES 3.1, OpenCL™ 1.2 EP, OpenVG™ 1.1, Vulkan® ·视频:4K H.265 dec | 1080p H.264 enc / dec |
| 存储器 | ·16/32位DDR3L-1866和LPDDR4-2400 ·1个Octal SPI或2个Quad SPI ·ECC功能 ①.Cortex-A35 L1缓存奇偶校验 ②.Cortex-A35 L2缓存ECC ③.sDDR接口上的ECC保护 |
| 显示器&摄像头 | ·2个组合MIPI DSI (4通道) / LVDS (1080p) ·24位并行显示器I/F (WXGA) ·SafeAssure®故障恢复显示屏 ·1个4通道MIPI CSI2 ·1个并行8位CSI (BT.656) |
| 连接 | ·2个SDIO3.0 [或1个SDIO3.0 + 1个eMMC5.1] ·USB 2.0和3.0 OTG支持,带PHY ·2个以太网AVB MAC ·3个CAN / CAN FD ·MOST 25/50 ·PCIe 3.0 (单通道),提供L1子状态 ·1个12位ADC (6通道) ·4个SPI, 1个ESAI, 4个SAI, 1个键盘 ·4个I2C (高速), 4个I2C (低速) ·1个SPDIF |
| 安全性 | ·高可靠性的启动,SHE ·TRNG,AES-128,AES-256,3DES,ARC4,RSA4096,SHA-1,SHA-2,SHA-256,MD-5 ·RSA-1024,2048,3072,4096和安全密钥存储 ·10个篡改引脚(有源和无源) ·在线加密引擎(AES-128) |
4.2、MCU-瑞萨 R7F7015833

RH850简介:
RH850/C1M-Ax 微控制器配备 RH850 系列 G3MH(C1M-A2 为双核)CPU 内核(C1M-A1 工作频率为240MHz、C1M-A2 工作频率为 320MHz),拥有出色的处理能力。除 ROM、RAM 和 DMA 外,这款微控制器还内置多种定时器(如电机控制定时器)、多种串行接口(如 CAN,其中 CAN FD 兼容)、12 位 A/D 转换器 (ADC)、可将旋转变压器输出信号转换为数字角度信息的 R/D 转换器 (RDC3A) 、CPU 以及并行电机控制单元 (EMU3) 等,还配备有适用于 HEV/EV 电机控制的多种外围功能。此外,C1M-A2 可以同时控制两个电机。
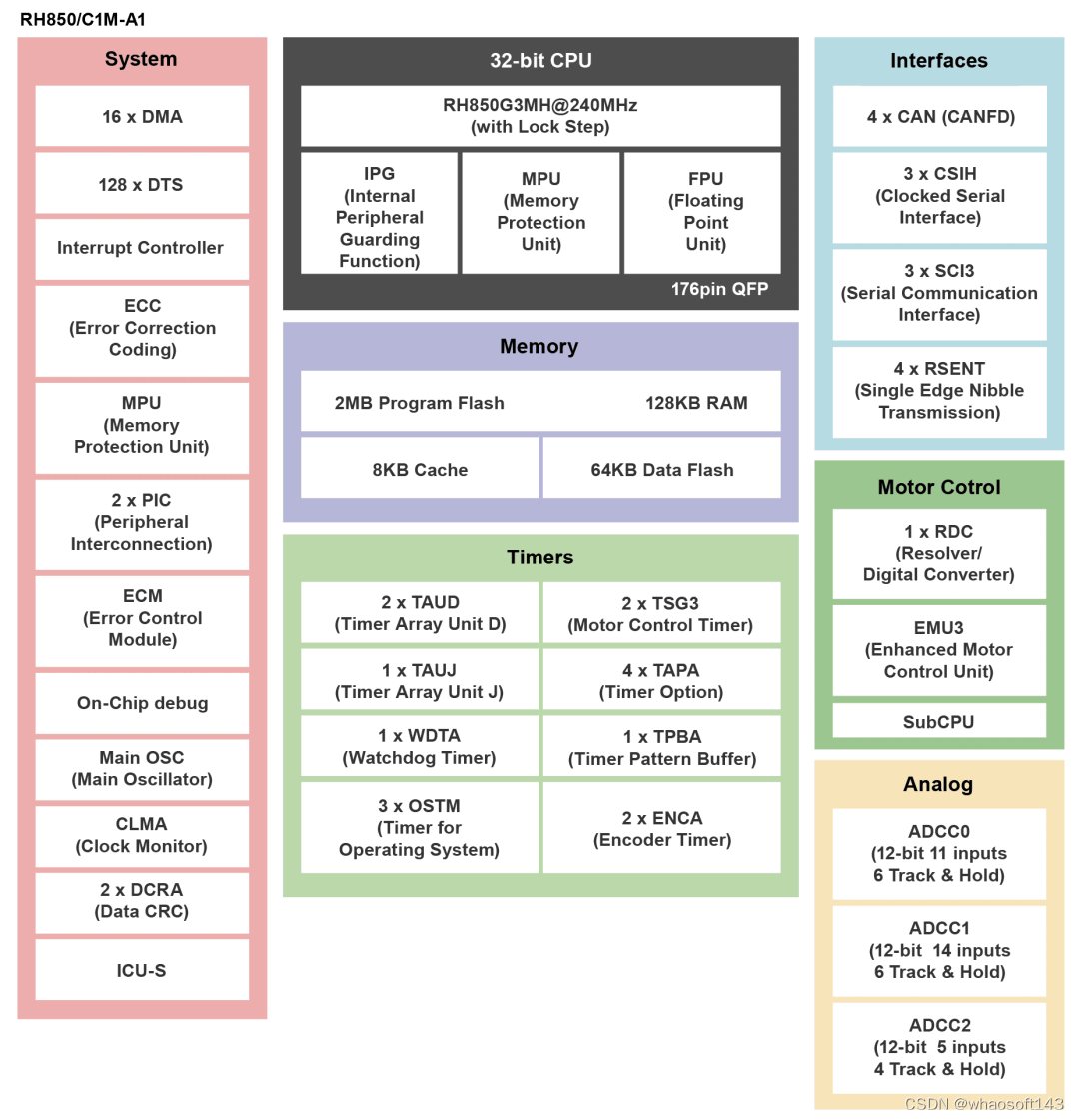
RH850特性:
| CPU 内核: | C1M-A1:240MHz 内核(内含锁步双核 x1) C1M-A2:320MHz 内核 x2(内含锁步双核 x1) FPU |
| 计时器: | 主振荡器:20MHz 带可选 SSCG 模式的 PLL:240MHz 或 320MHz 不带 SSCG 模式的 PLL:80MHz 片上低速振荡器:240kHz 数据传输:DMAC / DTS |
| 定时器: | 定时器阵列单元 D (TAUD) 2 或 4 个单元 定时器阵列单元 J (TAUJ) 1 或 2 个单元 电机控制定时器 (TSG3) 2 或 3 个单元 编码器定时器 (ENCA) 2 个单元 |
| 模拟: | SAR A/D 转换器 30 或 48 通道,3 个单元 |
| 通信接口: | 时钟串行接口 H (CSIH) 3 通道 CAN 接口 (RS-CANFD) 4 通道 LIN 接口 (RLIN3) 3 通道 串行通信接口 (SCI3) 3 通道 RSENT 4 通道 |
| 电机控制: | 电机控制定时器 (TSG3) 2 或 3 个单元 R/D 转换器 (RDC3A) 1 或 2 个单元 增强型电机控制单元(EMU3)1 个单元 |
| 安全: | 多输入签名生成器 (MIST) 时钟监视器 看门狗定时器 安全看门狗定时器 内存保护功能 |
| 电源电压: | 1.15V - 1.35V(CPU 内核) 4.5V - 5.5V(I/O、系统、AD 转换器、RD 转换器) |
| 温度: | Tj= -40° - +150° |
4.3、5G+V2X模块-移远 AG550

AG550简介:
AG55xQ 是移远通信开发的一系列车规级 5G NR Sub-6 GHz 模块,支持 5G NR 独立组网(SA)和非独立组网(NSA)模式。采用 3GPP Rel-15 技术,该模块在 5G NSA 模式下最高可支持 2.4 Gbps 下行速率和 550 Mbps 上行速率,在 LTE-A 网络下最高可支持 1.6 Gbps 下行速率和 200 Mbps 上行速率。通过其 C-V2X PC5 直通通信功能(可选),AG55xQ 可广泛应用于车联网领域,为实现智能汽车、自动驾驶和智能交通系统的建立提供可靠解决方案。同时,该模块支持双卡双通(可选)和丰富的功能接口,为客户开发应用提供了极大的便利。其卓越的 ESD 和 EMI 防护性能,确保其在恶劣环境下的强大鲁棒性。
AG55xQ 包含 AG550Q(5G + DSSS + C-V2X)、AG551Q(5G + DSSS)、AG552Q(5G + DSDA)和 AG553Q(5G +DSDA + C-V2X)四个系列;为满足不同的市场需求,各系列分别包含多个型号:AG55xQ-CN、AG55xQ-EU、AG55xQ-NA 和 AG55xQ-JP。同时,各系列模块向后兼容现有的 GSM、UMTS 和 LTE 网络,因此在目前没有部署5G NR 网络的地区以及没有 3G/4G 网络覆盖的偏远地区均可实现连接。
AG550特点:
·符合 IATF 16949 及 APQP、PPAP 等汽车行业质量管理流程要求基于高通 SA515M 芯片(符合 AEC-Q100 标准)而开发的车规级解决方案
·5G NR Sub-6 GHz 模块,支持独立组网和非独立组网模式
·向下兼容 4G(Cat 19)/3G/2G 网络
·MIMO 技术满足无线通信系统对数据速率和连接可靠性的要求
·可选 C-V2X PC5 Mode 4 直通通信
·可选双卡双通技术(DSDA),满足客户不同应用需求
·可选单频 GNSS、双频 GNSS、PPE(RTK)和 GNSS/QDR 组合导航解算,满足不同环境下对定位精度和速度的不同程度需求
·增强功能特性:DFOTA、VoLTE、QuecOpen®、高安全性等
·超宽工作温度范围(-40 °C ~ +85 °C)、+95 °C 以下 eCall 应用、优越的抗电磁干扰能力满足车载及其他恶劣环境下的应用需求
4.4、加密芯片-芯钛 TTM2000A11

芯钛 TTM2000A11简介:
Mizar TTM2000是一款面向汽车电子领域的灵活、可靠、安全、合规的加密芯片产品。该产品针对车联网V2X应用安全进行了专门的开发设计,能够完全满足C-V2X和DSRC等应用场景所需的消息认证性能、安全证书管理等需求。
TTM2000特点:
| 标准和认证 | - EVITA 硬件安全模块Full级架构设计 - AEC-Q100等级1要求 - 国家密码局安全芯片等级2级 |
| 产品特性 | - ARM® SecureCore® SC300™ 32-Bit RISC Core,80Mhz - 120.0DMIPS (Dhrystone v2.1); - Memory Protection Unit (MPU); - 24-bit SysTick 定时器; - 3.3V 和 1.8V供电,IO引脚电平为3.3V - 工作温度范围:-40℃ - 125℃ - 封装LQFP-64, QFN-64(TBD) |
| 安全特性 | - 具有硬件 “信任根”防篡改检测功能,物理屏蔽层防护设计,抗侧信道攻击防护设计 - 内部集成国际标准和中国国家密码局标准的硬件密码算法单元 - 4路独立TRNG - 硬件加密Flash,密钥加密安全存储 - 看门狗定时器(WDT) - 高/低电压异常检测 - 温度异常检测 |
| 密码算法单元 | - 高速ECDSA(NIST-P256) - 高速SM2 - 高速SM3 - RSA(up to 2048 bits) - ECC-256 - SHA-256 - AES - DES - SM4 |
| 系统保护 | - 每颗芯片均有32位唯一的序列号 - 完善的生命周期状态管理 - 使用国产密码算法的系统安全启动 |
| 通信特性 | - 2个集成SPI控制器,可配置为Master/Slave模式 - 1个UART控制器 - 1个I2C - 5通道GPIO,可配置为Input/Output,或者作为外部中断输入; - 1个外部定时器 - 1个Watchdog - 8通道DMA控制器 - 多种类、可配置 IO 连接实现更优性能和灵活性 |
| 存储器 | - 512KB 内部 Flash,支持ECC - 160KB SRAM - 安全 ROM |
| 关键密码单元性能设计目标 | - 超高速SM2/ECDSA(NIST P-256)单元:>4000次验签/秒; - 高速通用曲率ECDSA单元:>1500次验签/秒; - 高速SM3单元:>500Mbps - 高速SHA单元:>500Mbps |
4.5、交换机芯片-MARVELL 88Q5050

Marvell 88Q5050简介:
Marvell 88Q5050 是一款 8 端口、高安全性车载千兆以太网交换芯片,是完全符合 IEEE802.3 和 802.1 车规 标准,具备高级安全功能以防范网络威胁(如黑客和拒绝服务 (DoS) 攻击)。该 8 端口以太网交换芯片有 4 个固定的 IEEE 100BASE-T1 端口,以及 4 个可配置端口,其可选择性包括 1 个 IEEE 100BASE-T1、1 个 IEEE 100BASE-TX、2 个 MII/RMII/RGMII、1 个 GMII 端口和 1 个 SGMII 端口。该 交换芯片提供本地和远程管理功能,用户可轻松访问和配置该设备。通过 AEC-Q100 等级 2 认证,此方案采用了 Marvell 针对车载以太网芯片安全根源而设计的最高硬件安全功 能,以防止对车辆中数据流的恶意攻击或危害。该款先进的交换芯片采用深度包检测 (DPI) 技术和安全启动功 能,以提供业内最安全的车载以太网交换机。所有以太网端口都支持地址黑名单和白名单功能,以进一步提高其 安全性。
框图
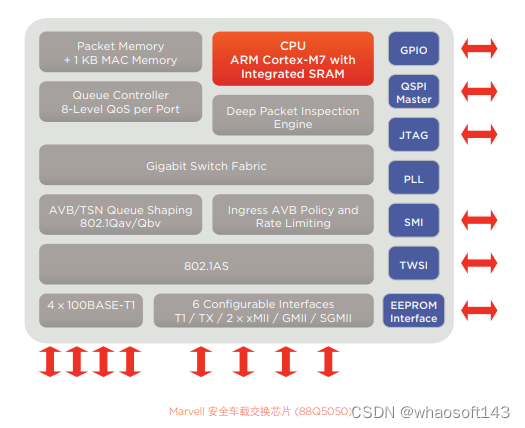
特点
| 处理器 | 集成 ARM Cortex-M7 CPU,250 MHz |
| IO 接口 | •4 IEEE 100BASE-T1 •其余四个端口可配置如下: - IEEE 100BASE-T1 - IEEE 100BASE-TX - MII/RMII/RGMII - GMII - SGMII •2 SMI - 主接口可连接至外接 PHY 或其他交换机 - 从属接口用于管理交换机 •可配置 GPIO •工作时钟频率可配置 (19.2 MHz-83.3 MHz) 的 QSPI 接口 •TWSI 主接口 •JTAG |
| 封装特性 | 128 引脚 LQFP 封装,0.5 mm 间距,14 mm x 20 mm |
| EEPROM | 带加载器的从属接口,用以配置交换机 (32 Kb-512 Kb) |
| 交换矩阵 | Gigabit 交换矩阵 |
4.6、存储芯片
eMMC三星 8G KLM8G1GEUF
DDR4三星 2G K4F6E3S4HM

①、KLM8G1GEUF
三星eMMC是以BGA封装形式设计的嵌入式MMC解决方案。eMMC操作与MMC设备相同,因此是使用MMC协议v5.1(行业标准)对存储器进行简单读写。
eMMC由NAND闪存和MMC控制器组成。NAND区域(VDDF或VCC)需要3V电源电压,而1.8V或3V双电源MMC控制器支持电压(VDD或VCCQ)。三星eMMC支持HS400以提高顺序带宽,特别是顺序读取性能。
使用eMMC有几个优点。它易于使用,因为MMC接口允许与任何带有MMC主机的微处理器轻松集成。
由于嵌入式MMC控制器将NAND技术与主机隔离,因此NAND的任何修订或修正对主机来说都是不可见的。这导致更快的产品开发和更快的上市时间。

②、DDR4三星 2G K4F6E3S4HM
K4F6E3S4HM-THCL是一款多功能LPDRAM,移动解决方案的理想之选三星的 LPDDR4是一款突破性产品,不但数据传输速度更快,而且能耗更低,从而为超薄设备、人工知能 (AI)、虚拟现实 (VR) 和可穿戴设备提供了更多设计方面的选择。
特点:
·双数据速率架构;每个时钟周期两次数据传输
•双向数据选通器(DQS_t、DQS_c),与接收器捕获数据时使用的数据一起发送/接收
•差分时钟输入(CK_t和CK_c)
•差分数据选通器(DQS_t和DQS_c)
•输入正CK边的命令和地址;DQS的两个边缘参考的数据和数据掩码
•每个模具2个通道组成
•每个通道8个内部银行
•DMI引脚:正常写入和读取操作时的DBI(数据总线反转),DBI关闭时用于屏蔽写入的数据屏蔽(DM)
-DBI打开时屏蔽写入的DQ 1的计数#
•突发长度:16,32(OTF)
•突发类型:连续
•读写延迟:请参阅表64 LPDDR4 AC时序表
•每个突发访问的自动预充电选项
•可配置的驱动强度
•刷新和自刷新模式
•部分阵列自刷新和温度补偿自刷新
•写入调配
•CA校准
•内部VREF和VREF培训
•基于FIFO的写/读训练
•MPC(多用途指挥)
•LVSTL(低压摆动端接逻辑)IO
•VDD1/VDD2/VDDQ:1.8V/1.1V/1.1V
•VSSQ终端
•无DLL:CK到DQS不同步
•边缘对齐的数据输出,数据输入中心对齐的写入训练
•刷新率:3.9us
4.7、GNSS模块-UBLOX ZED-F9K-00B

ZED-F9K简介
ZED-F9K模块采用u-blox F9 GNSS平台,为最具挑战性的汽车用例提供连续分米级的定位精度。LAP 1.30支持L1/L2/E5B和L1/L5频段均可实现最大的灵活性、卫星可用性和安全性。复杂的内置算法巧妙地融合了IMU数据、GNSS测量、车轮滴答声,以及车辆动力学模型,以识别单独的GNSS将失效的车道。模块本机支持u-box PointPerfect GNSS增强服务。它提供多种全球导航卫星系统 whaosoft aiot http://143ai.com
和IMU输出并行,以支持所有可能的架构,包括一个50 Hz的传感器保险丝具有非常低延迟的解决方案。它还实现了高级实时应用,如增强现实,而优化的多波段和多星座能力使可见光的数量最大化卫星,即使在城市条件下。该设备是一个独立的解决方案,可提供尽可能好的系统性能。
#World Model立大功的背后还有哪些改进方向
-
为什么不直接用DINO, 而是用2D-UNet先做了一次蒸馏, 直接用DINO会有什么问题呢?
-
中间world model部分是transformer based的, 能否直接复用现有的LLM+adapter的方式;
-
这种方法理论上能否开车, 文章里只有一个video decoder输出video,文章中说现在还没有实时运行, 但是如果不考虑实时性, 加一个action decoder来输出自车动作,理论上应该能够开车,但这样自回归的输出也应该有action部分;
-
world model部分编码的是2d的信息, 如果把3d的信息也加上是不是会更通用一些;
-
看文章发现是有好几个训练步骤的, 比如先训练 Image Tokenizer, 再训练World Model, 最后再训练Video Decoder部分,整个过程不能够端到端的一起训练么, 应该是可以的, 估计训起来比较费劲,可能不收敛。
-
假设输入不止有前视, 还有左前和右前, 如何做到不同相机视角下生成的视频具有一致性。
出发点是什么
自动驾驶有望给交通带来革命性的改善,但是 构建能够安全地应对非结构化复杂性的现实世界的场景的系统 仍然充满挑战。一个关键问题在于有效地 预测各种可能出现的潜在情况以及 车辆随着周围世界的演化而采取的动作。为了应对这一挑战,作者引入了 GAIA-1, 一个生成式的世界模型,它能够同时输入视频、文本和动作来生成 真实的驾驶场景,并且同时能够提供对自车行为和场景特征的细粒度控制。该方法将世界建模视为序列建模问题,通过把输入转化为离散的tokens, 预测序列中的下一个token。该模型有很多新兴特性, 包括学习高级结构和场景动态、情境意识、 概括和理解几何信息。GAIA-1 学习到的表征的强大能力可以捕获对未来事件的期望,再加上生成真实样本的能力,为自动驾驶领域的创新提供了新的可能性。
GAIA_1简介
预测未来事件对自动驾驶系统来说基本且重要。精准地预测未来使自动驾驶车辆能够预测和规划其动作,从而增强安全性和效率。为了实现这一目标,开发一个强大的世界模型势在必行。已经有工作在这方面做了很大努力, 比如. 然而,当前的方法有很大的局限性。世界模型已成功 应用于仿真环境下的控制任务和现实世界的机器人任务。这些方法一方面需要大规模的标注数据, 另一方面模型 对仿真数据的研究无法完全捕捉现实场景的复杂性。此外, 由于其低维表示,这些模型难以生成高度真实的 未来事件的样例, 而这些能力对于真实世界中的自动驾驶任务来说非常重要。
与此同时,图像生成和视频生成领域也取得了重大进步,主要是利用自监督学习从大量现实世界数据中学习生成非常真实的数据 视频样本。然而,这一领域仍然存在一个重大挑战:学习捕获预期未来事件的表示。虽然这样的生成模型 擅长生成视觉上令人信服的内容,但在学习动态世界的演化表示方面效果不太好,而这对于准确的预测未来和稳健的决策至关重要。
这项工作提出了 GAIA-1,它同时保持了世界模型和视频生成的优势. 它结合了视频生成的可扩展性和现实性以及世界模型的学习世界演变的能力。
GAIA-1 的工作原理如下。首先,模型分为两部分:世界模型和video diffusion decoder。世界模型负责理解场景中的high-level的部分及场景的动态演化信息, 而video diffusion decoder 则负责 将潜在表征转化回具有真实细节的高质量视频。
整个网络结构如下
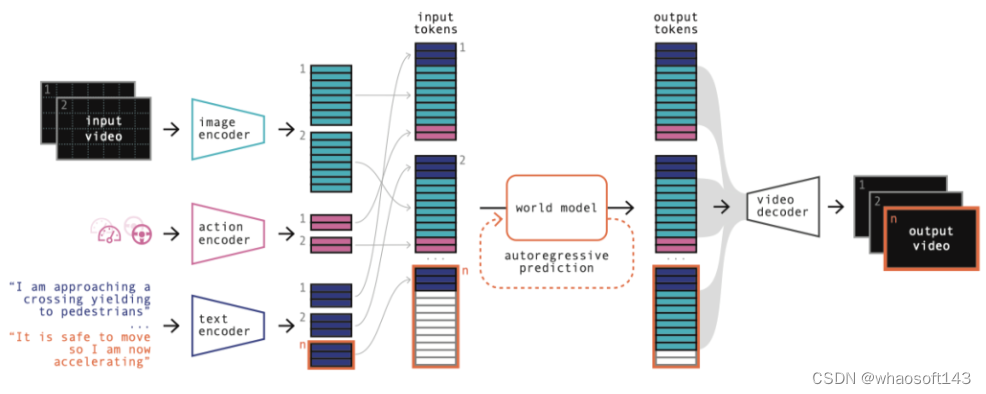
对于世界模型,使用视频帧的矢量化表示来离散化每一帧 ,将它们转换为token序列。基于此就把预测未来转化为预测序列中的下一个token。这种方法已被广泛应用于训练LLM,并且得到了认可, 这种方法主要是通过扩展模型大小和数据来有效提高模型性能。它可以通过自回归的方式在世界模型的latent space内生成样本。
第二个部分是一个多任务video diffusion decoder,它能够执行高分辨率视频渲染以及时间上采样, 根据world model自回归产生的信息生成平滑的视频。类似于LLM,video diffusion model表明训练规模(模型大小和数据量)和整体表现之间存在明显的相关性,这使得 GAIA-1 的两个组件都适合有效的Scaling。
GAIA-1 是一个多模态的模型,允许使用视频、文本和动作作为提示来生成多样化且真实的驾驶场景,如下图 1 所示:

通过在大量真实的城市驾驶数据上训练, GAIA-1 学习了理解和区分一些重要概念,例如静态和动态元素,包括汽车、公共汽车、行人、骑自行车的人、道路布局、建筑物,甚至交通灯。此外,它还可以通过输入动作或者文本提示来细粒度地控制自车行为及场景特征。
GAIA-1展示了体现现实世界生成规则的能力。还有诸如学习高级结构、概括、创造力和情境意识等新兴的特性。这些表明该模型能够理解并再现世界的规则和行为。而且,GAIA-1 展示了对 3D 几何的理解,例如,通过有效地捕捉 由减速带等道路不平整引起的俯仰和侧倾间的相互作用。预测的视频也展示了其他智能体的行为, 这表明模型有能力理解道路使用者的决策。令人惊讶的是,它还能够产生训练集之外的数据的能力。例如,在道路边界之外行驶。
GAIA-1 学习到的表征预测未来事件的能力,以及对自车行为和场景元素两者的控制是一项令人兴奋的进步,一方面为进一步提升智能化效果铺平了道路, 另一方面也可以为加速训练和验证提供合成的数据。世界 像GAIA-1 之类的世界模型是预测接下来可能发生的事情的能力的基础,这对于自动驾驶的决策至关重要。
GAIA_1的模型设计
GAIA-1 可训练组件的模型架构。总体架构如上面图2所示。
编码视频、文本和动作


对于视频,我们希望减少输入的序列长度,同时可能使 词汇量更大,但同时希望tokens 比原始像素在语义上更有意义。这里是用离散图像自动编码器来做的。在此过程中实现两个目标,
-
压缩原始像素的信息,使序列建模问题易于处理。因为图像包含大量冗余和噪声信息。我们希望减少 描述输入数据所需的序列长度。
-
引导压缩后的信息具有有意义的表示, 比如语义信息, 而不是大量没有用的信号, 这些信号会降慢世界模型的学习过程。
目标1的实现

目标2的实现
本文用预训练的DINO 模型 抽取的特征来作为回归的target, 相当于是用DINO作为蒸馏的teacher,DINO是一个自监督的模型,它包含有丰富的语义信息, 如图3所示 DINO-distilled 得到的tokens看起来语义信息比较丰富.


为了在推理的时候, 能够同时输入文本或动作作为提示, 在训练的时候会随机把输入的文本或者动作tokens给dropout掉.
为了进一步减少世界模型输入的序列长度,对输入的视频作了进一步采样, 从原来的25HZ变为6.25HZ。这能让世界模型能够在更长的时间内进行推理。为了以全帧速率恢复视频预测,在video decoder部分用了temporal super-resolution。
视频解码器
随着图像生成和视频生成的最新进展,在GAIA-1的decoder部分, 使用了 denoising video diffusion models。一个自然的想法是把每一桢的 frame tokens 解码到像素空间, 但是这样得到的不同桢对应的pixel, 在时间上不具有一致性。这里的处理方法是, 把问题建模为 在扩散过程中对一系列帧进行去噪,模型可以访问到整个时间段内的信息,这样做明显提高了输出视频的时间一致性。

我们在图像和视频生成任务上联合训练单个模型。用视频训练 会让解码器学习在时间上保持一致,用图像训练对于单桢图像质量至关重要,因为它学习的是从从图像tokens中提取信息。要注意在图像训练时没有用时间层。
为了训练视频扩散解码器执行多个推理任务,可以通过masking 掉某些frames 或者是 某些 image tokens。这里针对所有的任务, 训练了单个视频扩散模型, 任务包括图像生成、视频生成、 自回归解码和视频插值, 每个任务均等采样。例如, 在自回归生成任务中,用之前生成的过去帧作为输入 用要预测的帧的图像tokens作为target。自回归的任务中包含正向和反向, 有关每个任务的示例,请参见下图 4。
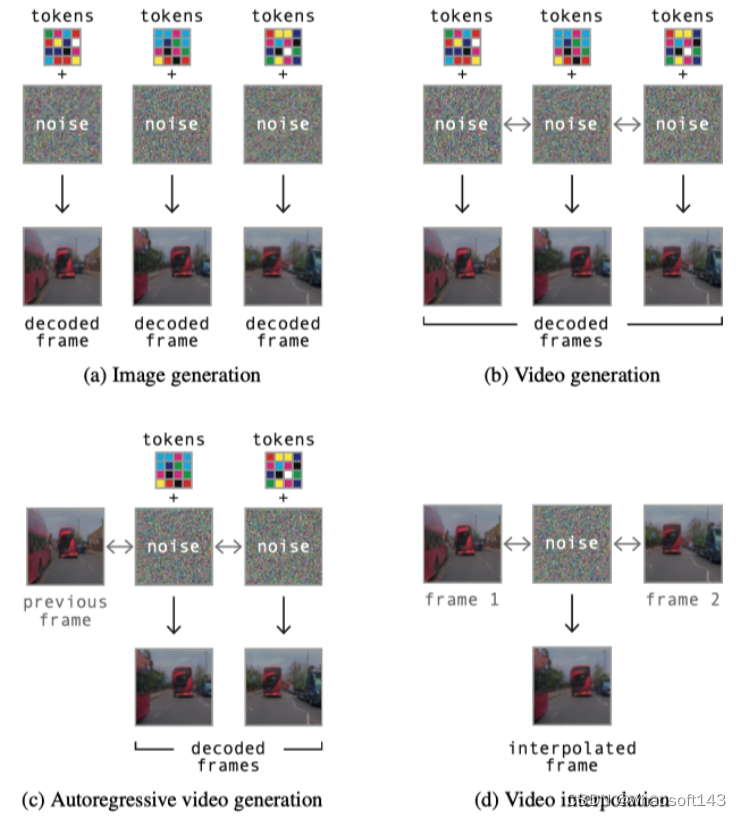
并且在训练的时候以概率 p = 0.15 随机mask掉输入的image token, 以摆脱对于观测image token的依赖进而提升泛化能力和时间一致性。
video decoder是根据 noise prediction objective 进行训练。更具体地说,采用v-parameterization的方法,因为它避免了不自然的 color shifts 并保持 长期一致性。
loss 函数为

训练数据
训练数据集包含在伦敦收集的 4,700 小时、25Hz 的驾驶数据,数据集中的时间跨度为2019 年至 2023 年。大约 4.2 亿张图像。不同经纬度及不同天气下的数据比例分布如下

训练过程
Image Tokenizer

世界模型

Video Decoder

模型推理
World Model
采样

为了多样性和真实性,这里采用的是 top-k 采样来采样下一个图像token。最终得到的世界模型可以在给定起始背景下,也可以不需要任何上文从头推理出可能的未来。
对于长视频生成,如果视频的长度 超过世界模型的上下文长度,可以采用滑动窗口的方式。
Text-conditioning
可以用文本来提示并指导视频预测。训练时,可以将在线的旁白描述或者是离线的文本和视频一起输入。由于这些文本源有noise,为了提高生成的futures与文本prompt之间的对齐效果,在推理时采用classifier-free guidance的方式.Classifier-free guidance 的效果是通过减少可能的多样性来增强文本图像对齐效果 。更准确地说,对于每个要预测的下一个token,

通过将无提示的 logits 替换为以另一个文本提示得到的 logits,可以 进行Negative提示。并且把negative prompt 与 positive prompt 推远, 可以使得future tokens 更多地包括 positive prompt features.
用于 guidance 的scale 系数非常重要, 如下图, 文本prompt是 "场景中包含一量红色的公交车",

可以看到, SCALE=1的时候, 就没有红色的公并车, SCALE=20的时候,恰好有一辆, SCALE=20的时候, 不止有一辆红色公交车, 而且还有一辆白色公交车.
Video Decoder
为了解码从世界模型生成的token序列,具体的方法如下:
-
以对应的 T' image tokens,解码前 T ′ = 7 帧;如下图所示

2. 使用过去的 2 个重叠帧作为图像context, 以及接下来的T ′ -2 图像tokens自回归解码接下来的 T ′ -2 帧。如下图所示
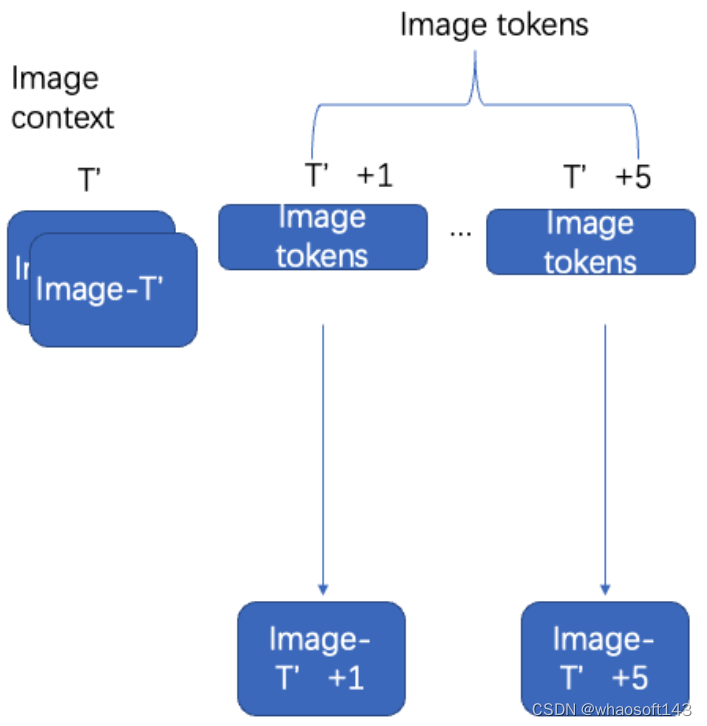
3. 重复自回归过程,直到以 6.25 Hz 生成 N 帧。
4. 将 N 帧从 6.25 Hz 做Temporally上采样得到 12.5 H
5. 将 2N- 1 帧从 12.5 Hz Temporally上采样到 25.0 Hz
在自回归decoding过程中, 需要同时考虑生成的图片质量以及时间一致性, 因此这里做了一个加权,

在探索视频解码的不同推理方法时,发现解码视频 从序列末尾开始自回归地向后会导致更稳定的物体, 并且地面上的闪烁也更少。因此在整个视频解码方法中,先解码最后的 T ′ 帧, 之后从后往前解码剩余的桢。
Scaling
GAIA-1 中世界建模任务的方法经常在大型语言模型(LLM)中使用, 类似于GPT。在这两种情况下,任务都被简化为预测下一个token。尽管GAIA-1中的世界模型建模的任务和LLM中的任务不同, 但是与LLM中类似, Scaling laws同样对于GAIA-1适用.这说明Scaling laws对于很多领域都是适用的, 包括自动驾驶。
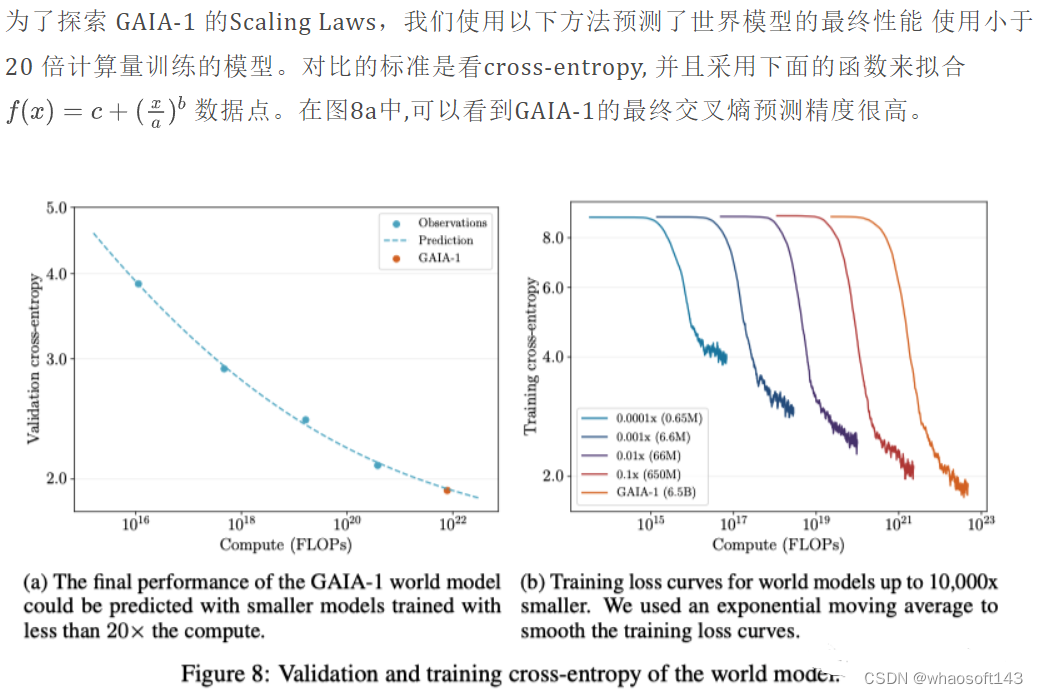
如图 8b 所示, 可以看出, 随着模型变大, 训练时候的cross-entropy 会收敛地越来越低,上面说明可以通过扩展数据和计算资源来进一步提升模型的性能。
Capabilities and Emerging Properties (能力和新兴特性)
这一节主要是效果展示的例子。这里有个youtube的连接: https://www.youtube.com/playlist?list=PL5ksjZd5b6SI-6MQi6ghoD-GilTPmsQIf
下面图9显示了GAIA-1可以生成各种场景。


下面是GAIA-1通过一些新兴特性展示了对世界的生成规则的一定程度的理解和总结:
-
学习高级结构和场景动态:它生成与连贯的场景 并且物体放置在合理的位置上, 并展示真实的物体之间的交互,例如交通 灯光、道路规则、让路等。这表明该模型不仅仅是记忆 统计模式,而是理解了我们生活的世界中关于物体的底层规则, 比如物体是如何摆放, 有何行为。
-
泛化性和创造性:可以生成不在训练集里的新颖多样的视频 。它可以产生物体、动作的独特组合, 以及训练数据中未明确出现的场景,这表现出它有显著的泛化能力,并且表现出了一定程度的概括性和创造性, 这表明GAIA-1对视频序列的生成规则有较好的理解.
-
情境感知:GAIA-1 可以捕获情境信息并生成视频 来体现这种理解。例如,它可以基于初始条件或提供的上下文 产生连贯的动作和响应。此外,GAIA-1 还展示了对 3D 几何的理解,有效捕获到由于道路不平整(例如减速带)引起的侧倾。这种情境意识表明这些模型不仅能常握训练集中数据的统计规律,而且还积极地处理和总结给定的信息以生成适当的视频序列。
长时间驾驶场景的生成
GAIA-1 可以完全凭想象生成稳定的长视频, 如下图所示表现了40s的生成数据:

这主要是该模型利用其学习到的世界隐式先验分布来生成完全 想象的真实驾驶场景。这里应该采用了类似于MILE里的先验分布做法。生成的驾驶场景中具有复杂的道路布局、建筑物、汽车、行人等。这证明 GAIA-1 理解了支撑我们所居住的世界的规则及其结构和动力学。
多个合理未来的生成
GAIA-1 能够根据单个初始提示生成各种不同的未来场景。当以简短的视频作为输入时, 它可以通过不断地sampling产生大量合理且多样化的内容。GAIA-1 针对视频提示能够准确模拟多种潜在的未来场景,同时与在初始视频中观察到的条件保持一致。
如下图所示, 世界模型可以推理 (i) 道路使用者(例如让路或不让路)

上面两个分别对应着, 他车不让路, 和他车让路的情况。(ii)多种自车行为(例如直行或右转)

(iii) 多种动态场景(例如可变的交通密度和类型)

自车行为和驾驶场景的细粒度控制
GAIA-1可以仅根据文字提示生成视频,完全想象场景。我们展示了如何根据文本提示模型生成驾驶场景, 如下所示展示的是对天气和光照的细粒度控制.


下面是个令人信服的示例,其中模型展示了对车辆的细粒度控制。通过利用此控制,我们可以提示模型生成视频描述训练数据范围之外的场景。这表明 GAIA-1 能够将自车的动态与周围环境分开并有效地应用于 不熟悉的场景。这表明它能够来推理我们的行为对世界的影响,它可以更丰富地理解动态场景,解锁 基于模型的Policy learning(在world model中做planning),它可以实现闭环仿真探索(通过将世界模型视为模拟器)。为了展示这一点,这里展示了 GAIA-1 生成 未来,自车向左或向右转向,偏离车道等场景, 如下图所示:

GAIA-1 在训练数据集中从未见过这些不正确的行为,这表明 它可以推断出之前在训练数据中未见过的驾驶概念。我们也看到了现实 其他智能体对自车受控行为的反应。最后,这个例子展示了 GAIA-1 利用文本和动作来充分想象 驾驶场景。在这种特殊情况下,我们提示模型自车要超车公交车。

GAIA_1的总结和未来方向
GAIA-1 是自动驾驶领域的生成式世界模型。世界模型使用矢量量化 将未来预测任务转变为下一个token的预测任务,该技术 已成功应用于大型语言模型。GAIA-1 已展示其具有 全面了解环境,区分各种概念 例如汽车、卡车、公共汽车、行人、骑自行车的人、道路布局、建筑物和交通灯的能力, 这些全是通过自监督的方式学到的。此外,GAIA-1 利用视频扩散模型的功能 生成真实的驾驶场景,从而可以作为先进的模拟器使用。GAIA-1 是 一种多模态的方法,通过文本和动作指令相结合可以控制自车的动作和其他场景属性。虽然该方法展示了有潜力的结果,有可能突破自动驾驶的界限,但是重要的是也要承认当前的局限性。例如,自回归的生成过程虽然非常有效,但尚未实时运行。尽管如此,这个过程非常适合并行化,允许并发生成多个样本。GAIA-1 的重要性超出了其生成能力。世界模型代表了向 实现能够理解、预测和适应复杂环境的自动驾驶系统迈出的关键一步。此外,通过将世界模型融入驾驶模型中, 我们可以让他们更好地理解自车的决策,并最终推广到更多 现实世界的情况。最后,GAIA-1 还可以作为一个有价值的模拟器,允许 生成无限数据,包括corner-case和反例,用于训练和验证自动驾驶系统。
文章链接: https://browse.arxiv.org/pdf/2309.17080.pdf
官方博客1: https://wayve.ai/thinking/introducing-gaia1/
官方博客2: https://wayve.ai/thinking/scaling-gaia-1/
#自动驾驶仿真大观
一、仿真场景
仿真场景即自动驾驶系统的test case。根据中国汽车技术研究中心的分类,自动驾驶测试场景可分为【自然驾驶场景】【危险工况场景】【标准法规场景】【参数重组场景】等四大类:自然驾驶场景来源于汽车真实的自然驾驶状态,是构建自动驾驶测试场景中最基础的数据来源;危险工况场景主要包含大量恶劣天气环境、复杂道路交通以及典型交通事故等场景,如CIDAS数据库;标准法规场景是验证自动驾驶有效性的一种基础测试场景,是通过现有的标准、评价规程构建测试场景,目的是对自动驾驶汽车应该具备的基本能力进行测试;参数重组场景是将已有仿真场景进行参数化设置并完成仿真场景的随机生成或自动重组,具有无限性、扩展性、 批量化、自动化等特点。
场景库搭建流程大致可以分为【收集数据】:即实际道路数据和法规数据等、【处理数据】:即从数据中提取特征并组合形成场景和【应用数据】:场景库测试并反馈。
目前,自然驾驶场景的生成已经基本可以实现自动化:采集车按照一定的格式采集数据,算法筛选可能会有用的关键片段的数据,算法计算片段数据中本车和周围其他车辆的轨迹,再把轨迹写入场景描述文件,例如OpenScenario格式的场景文件,现有的很多仿真软件都可以直接利用这样获得的场景文件进行仿真。需要注意的是,在这种情况下,仿真软件中还原出来的只是实采场景的“逻辑”,场景中的参与者披着仿真软件三维模型库中的车辆模型“马甲”上演着一幕幕真实行为片段。换句话说,这样还原出来的场景当然可以满足规控算法的测试,但这样无法还原当时的传感器感知信息,因为毕竟还是由仿真软件的三维模型来扮演的前景车辆和背景。现在如果想要还原传感器感知信息,可以应用NeRF。
那么,究竟什么样的仿真场景才是有价值的呢?路测车辆采集的自然驾驶数据还原场景被认为是最能接近真实路况且随机性强的,但我们不是说目前路测花费的时间长赶不上趟儿吗?这就需要我们对路测数据进行处理,将交通参与者识别提取出来后再重新排列组合,形成基于真实数据的随机场景。
比如百度19年大火的论文介绍了他们的AADS仿真系统:在该系统中,使用一台安装了激光雷达和双目相机的汽车扫描街道,便可获得自动驾驶仿真的全部素材,然后自动将输入素材分解为背景、场景照明和前景对象。通过视图合成技术,可以在静态背景上改变视点,生成任意视角的真实图像,进而模仿车在不同环境里面行走的动作。那么如何证明这些重组场景的有效性呢?论文中提到了一种通过对比虚拟场景和实际场景中感知算法的识别效果来评价的方法,用被测对象的表现来评价测量工具,也很有意思。后来的一些应用于自动驾驶的NeRF研究中,也使用的是这样的一套思路,比如UniSim。
我个人认为,再有效的自然驾驶数据仿真场景也只适合部分算法的测试:这种方法不管怎样,周围物体的轨迹都是录制好的,是没办法根据本车行为改变的。这就像是电影和游戏的区别,电影中的场景只能播放,而游戏是可以根据交互改变场景的。
也许在不久的将来,结合交通流模拟和真实数据,随机场景生成可以批量建立既符合真实交通状况,也能够随本车行为变化的仿真场景。
二、仿真开发

我们之前谈到的场景库,可以说是在为自动驾驶仿真测试准备数据,那么仿真开发工作就是在创建或者完善工具了。
仿真开发大概包含以下几个方面:
-
【场景库】:之前说过很多了,会包括数据处理、深度学习、数据库等技术内容
-
【感知】:有了仿真环境,需要将环境信息传递给算法,因此需要建立各种传感器模型,如相机、激光雷达、毫米波雷达、超声波雷达等,根据需要建立物理原理级模型和理想模型。传感器建模想要做得好,需要传感器工作原理的理论研究、物理过程的计算机建模和工程落地能力,以及大量实验数据支撑。
-
【车辆动力学】:算法输出的控制命令需要有控制对象,因此需要车辆动力学模型,这几乎是另外一个学科,会有专门的工程师研究动力学模型,在自动驾驶仿真中需要能够接入专业动力学模型或进行简化。
-
【中间件】:算法与仿真平台间,不同功能的仿真平台间都需要信息交流,因此需要大量接口开发。自动驾驶研究阶段较常用的中间件如ROS,在应用阶段常用的如基于AUTOSAR的中间件。
-
【仿真引擎】:有企业喜欢自研仿真平台,那么管运动、碰撞的是物理引擎,常用开源的如ODE、Bullet、DART等,管三维显示的是渲染引擎,开源的如OGRE、OpenGL。Unreal和Unity是常用来制作游戏的既有物理也有渲染的两套引擎。
-
【仿真加速】:会涉及到并行计算云计算等,自动化测试也可以算在这里吧。
-
【前端】:我看有很多仿真开发的职位其实都是在招前端,因为仿真的动态可能需要显示交互等。

最后我觉得可能还有更高进阶要求的第8点:“哪里不会点哪里”的能力,比如如果你的被测对象只是自动驾驶功能框架中的一部分呢?你能不能通过开源算法把剩下的补齐,让“闭环”跑起来?
三、仿真测试
有了自动驾驶仿真测试所需的数据和工具,接下来就是仿真测试了。今天主要介绍几个常见仿真测试链路。
-
【MIL模型在环】:说实话我不是很知道模型在环和软件在环的区别(也许和MBSE方法论兴起有关)。狭义上来讲,模型在环是在编写编译实际代码之前使用比如MATLAB等工具验证算法逻辑功能的测试。说白了就是用simulink模型实现算法,进行仿真。
-
【SIL软件在环】:使用实际编译后的代码软件进行测试,按理说模型在环测试通过了,SIL只是检测代码生产上是否有问题。和HIL一样,SIL需要为被测对象提供一系列的运行环境、其他与待测功能无关的前置虚拟信号等。
-
【HIL硬件在环】:广义地讲,只要是一个硬件在回路中受到测试的方法都可以叫做HIL,所以针对某个传感器做的测试也可以叫HIL测试。狭义地讲,我们一般指控制器硬件在环,是以实时计算机运行仿真模型来模拟受控对象的运行状态,通过I/O接口与被测的ECU连接,对被测ECU进行全方面的、系统的测试。从HIL开始,要求仿真测试具有强实时性。
-
【VIL车辆在环】:我了解一般有两种车辆在环的方式:一种是搭载自动驾驶系统的车辆安装在试验台上,车轮卸掉替换为模拟负载的拖动电机,地形路面给车辆的激励都通过试验台来模拟,在这种方式中如果加上了很好的显示系统,也能够作为驾驶员在环仿真系统使用;另一种是车辆可以在一个空旷场地内行驶,由仿真系统提供传感器输入,让车辆虽在空场地中,但算法也会认为周围有各种不同的场景,一般可用车载GPS提供位姿反馈给仿真系统。
四、日常工作
前面几节说了那么多,都是在总体介绍我们这个行当,都是我这个盲人摸出来的大象,本节就来说说大体上我们每天都在干什么。这些日常工作当然是包含在第二、三节的内容当中的:
-
【感知】:搭建传感器模型必不可少,需要关注到每种传感器的一系列参数,如探测距离、探测角度范围、分辨率、畸变参数、噪声参数、安装位置等,还有硬件的通讯协议等。接下来视所用的仿真软件工具不同,看看是“配置”已有类型的传感器,还是要自己基于仿真软件开发新类型的传感器。为了算法模型的训练或评价,仿真往往还需要提供真值,如2D/3D包围框、车道线等地图信息、2D/3D占用栅格等等,如果仿真软件既有功能不能满足,就也需要工程师做二次开发。
-
【车辆动力学】:需要根据车辆参数在专业的动力学仿真软件中配置车辆模型,也需要能够根据简化公式直接编写简化的运动学、动力学模型。
-
【中间件】:接口的开发是重要的工作内容,要负责当好被测对象和仿真软件间的“翻译”;另外就是使用软件的api接口实现不同层级仿真平台间的联合仿真,例如场景仿真联合车辆动力学仿真,再加上交通流仿真,再统一放进自动化测试管理软件的调度中去。
-
【仿真加速】:我把自动化测试也放到了仿真加速里,因为要是能够实现7x24小时不间断测试也是一种提高效率的途径吧!这就涉及了自动化调用仿真平台、自动化脚本编写、录制数据、根据用例要求评价数据等内容。
-
【软件开发】:有自研仿真软件需求的企业主要就是这方面业务。
另外还有一点6.【需求分析】:作为仿真开发工程师,你理应是最了解你所用工具的那个人,所以一旦客户(内部外部都算)有了新需求,仿真开发工程师应该能够根据需求和被测对象的具体情况设计技术方案、提出软硬件需求和项目计划。所以有的时候,产品和项目管理的活都要干。
五、技术栈

“技术栈”这词儿听着挺洋气,但其实就是这个岗位应该都会点啥。很久以前我看过一个电视剧,里边一个急诊科的大夫自嘲:我们是万金油,人家外科大夫才是金不换。我一直认为仿真工程师就像医院里的急诊科大夫,什么都得知道点:测试什么算法,那么除了这个算法之外的所有东西都要准备好,导航定位、控制规划、数据处理、参数标定、天文地理、医卜星象、金批彩挂、评团调柳……可以不求甚解,快速满足算法测试需求是最重要的。

这种所谓的“全局观”是仿真工程师的优势,但只有对算法有真正的了解,才能做出能够真正帮助算法改进的仿真工作,也才能走得更远。扯远了,拉回来:
-
【代码】:主要是C++/Python,但如果涉及到前端显示的部分我就不了解了。一般来讲要求肯定没有算法开发那么高,不过如果是专做仿真软件开发的另当别论。
-
【ROS】:单拎出来是因为目前ROS仍是自动驾驶和机器人算法研究领域绕不开的一部分,且ROS社区中提供了很多现成的很多可用工具。
-
【车辆动力学】:可能不需要像真正的车辆工程师了解得那么多,但基本原理是要知道的。另外就是各种坐标转换需要熟练(这条可能不算车辆的,算数学)。
-
【传感器原理】:自动驾驶车辆上的相机、激光雷达、毫米波雷达等各种传感器是如何工作的,输出的信号长什么样子,有哪些关键的参数。
-
【地图】:仿真测试场景使用的文件格式如opendrive、openscenario需要了解,因为有时候需要从其中提取信息作为传感器仿真的输入。
以上仅仅是我个人的一点总结,欢迎广大同行在此补充!

为了文章的完整性,我也将在这一节简要介绍下市面上常用的一些仿真软件(真的不是广告!没上榜的也不要气馁)。
-
CarSim/CarMaker:这两款软件都是强大的动力学仿真软件,被世界各国的主机厂和供应商所广泛使用,也可以做一部分道路场景的模拟。
-
Vissim/SUMO:Vissim是德国PTV公司提供的一款世界领先的微观交通流仿真软件。Vissim 可以方便的构建各种复杂的交通环境,也可以在一个仿真场景中模拟包括机动车,卡车,有轨交通和行人的交互行为。SUMO是开源软件,可以通过交互式编辑的方式添加道路,编辑车道的 连接关系,处理路口区域,编辑信号灯时序等。
-
PreScan:已被西门子收购,用于创建和测试算法的主要界面包括MATLAB和Simulink,可用于MIL、SIL和HIL。
-
VTD:作为商业软件,VTD可靠性强,功能全面,覆盖了道路环境建模、交通场景建模、天气和环境模拟、简单和物理真实的传感器仿真、场景仿真管理以及高精度的实时画面渲染等,说一句VTD是国内主机厂使用率最高的仿真软件应该不为过。可以支持从 SIL 到 HIL 和 VIL 的全周期开发流程,开放式的模块式框架可以方便的与第三方的工具和插件联合仿真。
-
CARLA/AirSim:两款开源仿真平台,都依托UE开发,也推出了Unity版本。CARLA可以制作场景和配套的高精地图,支持传感器和环境的灵活配置,它支持多摄像头,激光雷达,GPS 等传感器,也可以调节环境的光照和天气。微软的AirSim有无人机和车辆两种模式,车辆模式下的功能实在乏善可陈,没法很方便地建立环境和车辆模型,社区也没有CARLA活跃,建议以后招人写JD别把AirSim算进去了,没多大用。另外,国内的深信科创最近推出了基于CARLA开发的OASIS,目前可以看成是开源CARLA的加强版。
-
51SimOne/PanoSim:这两个都是国产的仿真软件,场景仿真软件该有的主要功能他们都能满足。

最后再补充一个lgsvl:本来lgsvl的优势是和Apollo结合得较好,但是我听说lgsvl的官方已经放弃了这个项目,所以我劝你弃掉这个坑。
六、学习路径
相信通过我前五节的介绍,聪明的在校同学已经可以从中体会出成为一名自动驾驶仿真工程师的学习路径,而通过批判我前五节的内容,年轻的同行也已可以从中得出进阶之道。但本节我还是写一些在这方面的粗浅理解。
我前边说了那么多,想必大家也能看出来,自动驾驶的仿真是一个多学科交叉的领域,能够接受来自很多专业的同学,包括但不限于:计算机/控制/机器人/机械/车辆/电力电子等等。
经历和技术上,我尝试列举一些任职要求:
-
代码能力:做仿真的云计算、云服务器等相关开发的同学可能会需要熟练使用C++/Go/Java任何一门语言的开发,有良好的编程习惯,掌握常见的设计模式、数据结构和算法,熟悉Linux系统、Docker技术及Kubernetes的相关知识,有云端服务开发经验,这些是奔着高并行高复用高自动化的自研仿真测试平台去的。另外,自研仿真软件的岗位除扎实的计算机基础外,可能会需要游戏引擎的开发经验,所以做游戏开发的同学也可以转行到自动驾驶仿真上(包括技术美术)。目标是应用已有的仿真软件进行二次开发和集成的同学可能会需要熟练使用C/C++和Python,熟悉Linux/ROS的开发,如果能够有AUTOSAR等车规级中间件的开发经验更好。
-
软件经验:任何的自动驾驶仿真软件的实际使用经验当然都是加分项,但是由于商业软件大多非常贵,因此在这点上很依赖学校实验室或者公司的实力。在没有商业软件支持的情况下,我认为现在CARLA是开源软件的最优解。
-
领域知识:我个人认为,作为自动驾驶仿真工程师,对于自动驾驶算法怎么深入了解都不为过,包括算法的原理实现的方方面面,只有更好地了解算法,才能更好地做好仿真。另外,如果是非计算机专业出身的同学,学好本门儿的专业课也十分重要,比如机械、车辆、力学、电子等等等等,守正才能出奇,总会用到。
当前自动驾驶行业正经历很大波动,但总结起来能用到仿真工程师的主要有以下几类企业:主机厂,以集成应用成型仿真软件为主,但新势力基本上都要做自研;自动驾驶解决方案供应商,也就是算法的Tier1,可能也是自研仿真的居多;仿真软件企业,这方面国内刚刚起步,基本上都是初创企业。
在本节的最后我再谈一点从传统机械“转行”来的体会。我硕士毕业的一个学校具有浓厚的转码风气,我那届入学机械研究生院的中国学生里,大概有十之七八毕业后都从事了计算机行业。有赖于相对宽松的选课制度,同学们的操作是尽量多修计算机学院的课程。于是在那两年,焚膏油以继晷,恒兀兀以穷年是常态。但我不记得当年找工作需不需要刷题了。总之一句话,机械如何转型计算机:去读半个计算机学位。其实当时也不单是机械,各个专业都在转,也不单是中国学生,全世界人民都这样。
不过后知后觉的我并不在当年的这十之七八里边,所以我错失了转型最好的机会。等到靠自学的时候,就难多了:最主要没有时间,这就更要求学习资料和方法要高效。因此相对来讲,还是上网课效率较高,毕竟有老师指导。Coursera的课不错,好像比较贵。最近几年开源的网络资源越来越多了,不过上的课在精不在多,毕竟计算机最注重实践也最容易实践。计算机经典的著作也很多,比如数据结构与算法、c++ primer……我是一本没看过,有些事真的一旦错过就不再。
其实我觉得,一个最容易的转型方式就是,直接从事计算机相关的工作,有了需求提高是最快的,解决了我上面说的学习方向问题和时间问题。不过要是因此产生了绩效不达标的问题,您当我没说。
七、关于NeRF

NeRF正伴随着“数据闭环”、“大模型”、“端到端”这些新兴热门词汇一起在自动驾驶领域“兴风作浪”。仅仅几年的时间,NeRF已经再也不是出道时单纯的MLP+体渲染,储存空间信息的载体五花八门:哈希表、体素网格、多维高斯函数……新的成像方式也层出不穷:U-net、CNN、光栅化……自动驾驶方向只是NeRF一个很小的应用分支。
NERF应用到自动驾驶仿真方向,主要会面临以下这些问题:
自动驾驶数据采集的方式导致场景的范围“不闭合”:室外的场景会包含大量远景,这对NeRF的空间信息储存是很大挑战;自动驾驶场景包含大量的动态物体,NeRF需要能够处理动静态物体(或曰前景背景)的分离;NeRF模型普遍不具有迁移能力,可能每个场景都需要训练单独的NeRF模型,而NERF的训练又仍然比较慢,所以NERF在自动驾驶数据上的大规模应用仍然会存在问题。
不过我仍然期待着,同时也相信,NeRF会给自动驾驶仿真带来颠覆性的发展,最终消除仿真在感知算法上的domain gap,甚至做的更多。从我了解到的信息来看,NeRF至少会带来以下这些突破:
NeRF新视角图像合成的能力可以增强感知算法训练数据集:可以产生新传感器内参(相当于改变了传感器配置)、外参(修改了自车轨迹)下的图片、激光雷达点云等数据,给感知算法更多训练数据,这方面可以参考StreetSurf、UniSim等研究。在动态物体可编辑的情况下,将来NeRF可以产生有针对性的极端情况、随机情况场景,补充单纯路测和WorldSim的不足。如果NERF可以同时很好地解决城市级场景的训练重建和实时渲染,那么NeRF就完全可以做为一个XIL在环仿真测试的平台,而不会有感知数据domain gap的问题,也会推动端到端算法的发展。另外,NeRF的模型甚至也可以作为一个插件放入游戏引擎(如3d Gaussian Splatting的UE插件已经问世),这样就可以把NeRF的街景重建纳入到原有的WorldSim体系中去。如果考虑与AIGC方向的大模型结合,NeRF在新场景生成上就会有更多的可能性:将可以任意编辑光照、天气、物体外观和行为等等。
所以作为仿真工程师,我强烈建议广大同行密切关注NeRF方向的进展,尽管NeRF的各研究项目还都只是初具雏形,但现在深度学习方向在硬件的加速下进展已经越来越快了。
八、写在最后

杂七杂八写了这么多,最后还有一些感想。
仿真开发有什么坑。技术上的坑不在此讨论,在这里只说一点整体上的感想。那就是要警惕你是否在过多地陷入到毫无意义的工作中去:给不同人做类似的项目不算,完成好每个项目就是价值;不使用现成工具非要自研长期看也不算,脱离对特定工具的依赖是有价值的;研发上很多事后被证明不通的尝试也不能算,研发的失败也有价值的。那么具体什么是“毫无意义”的工作呢?这就见仁见智了,我总结不好。 whaosoft aiot http://143ai.com
还有从这个岗位出发能干嘛。如果你在工作中对被测对象有了深入的了解,那么也许可以尝试转向某个方向的算法开发岗;还有就是机器人、无人机的仿真开发也可以考虑。
移动机器人和自动驾驶的相通性自不必说,这里提一下无人机。无人机行业的体量肯定没有汽车这么大,但是也已经有了落地点,比如巡检、航拍、测绘等。无人机也需要自动操控算法来进行避障、路径规划等,无人机使用的传感器也和无人驾驶车车辆类似,因此可以说仿真测试有相通之处:无人机也需要丰富的视觉图像、雷达点云等感知输入,需要更加精细的动力学模型等等。
有兴趣了解机器人和无人机仿真的同学,可以从开源的仿真平台Gazebo(https://classic.gazebosim.org/)入手,其对计算资源的需求不会像Nvidia的Isaac那么高。
今年是OSRF从柳树车库独立出来的第十一年,而机器人操作系统ROS和Gazebo至今已经有了二十多年的发展历史。Gazebo从最初一个研究生课题组的科研工具,逐步发展成了今天有11个发行版,以及二代ignition 7个发行版的独立仿真软件工具。

Gazebo支持ODE、Bullet等物理引擎,使用OGRE作为渲染引擎,可以创建三维环境,模拟相机、激光雷达等多种传感器的信息,具有丰富的机器人模型:从机械臂到轮式机器人,再到人形机器人。更重要的是,Gazebo天然地对ROS平台下的算法提供全面的支持:毕竟如果你下载安装一个desktop full的ROS版本,Gazebo是自带的。当然了,Gazebo作为一个开源软件,只提供了一个起点,它的功能均衡,但是各方面都比较粗糙,不够深入。

