
- 1Unity3d 引擎原理详细介绍、Unity3D引擎架构设计
- 2react踩坑之函数名(){}与函数名=()=>{}的区别_= () =>
- 3sprite的大小 unity_Unity3D 2D入门——sprite尺寸、获取对象
- 4Ununtu 18.04 安装Carla 0.9.13 以及Carla ros bridge 超级避坑指南(更新于2022.10.20)_error: carla-0.9.13-py2.7-linux-x86_64 is not a va
- 5使用docker方式安装的gitlab配置ssh_docker gitlab ssh配置问题
- 6Unity之ASE实现UI流光效果_unity ui发光
- 7AI 工具分享第 4 期:13 款国外免费AI视频生成工具_artflow ai
- 8VSCode常用快捷键及用法汇总_vscode块选择
- 9#Uniapp:rpx 和 upx的区别_upx和rpx区别
- 10Speex降噪代码分析_speex aec电流音
Python编程之----多线程_python的多线程可以单独参在吗
赞
踩
Python编程之-----线程和进程
一、线程与进程
进程就是一个程序在一个数据集上的一次动态执行过程。进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
线程的出现是为了降低上下文切换的消耗,提高系统的并发性,并突破一个进程只能干一样事的缺陷,使到进程内并发成为可能。
线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。线程的引入减小了程序并发执行时的开销,提高了操作系统的并发性能。线程没有自己的系统资源。
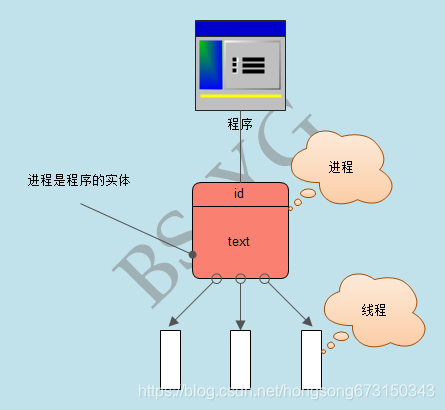
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
1、线程对象的2种创建方式
直接调用 import threading import time def countNum(n): # 定义某个线程要运行的函数 print("running on number:%s" %n) time.sleep(3) if __name__ == '__main__': t1 = threading.Thread(target=countNum,args=(23,)) #生成一个线程实例 t2 = threading.Thread(target=countNum,args=(34,)) t1.start() #启动线程 t2.start() print("ending!")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
继承Thread式创建 import threading import time class MyThread(threading.Thread): def __init__(self,num): threading.Thread.__init__(self) self.num = num def run(self): print("running on number:%s" %self.num) time.sleep(3) if __name__ == '__main__': t1=MyThread(56) t2=MyThread(78) t1.start() t2.start() print("ending")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2、 join&Daemon
知识点一:
当一个进程启动之后,会默认产生一个主线程,因为线程是程序执行流的最小单元,当设置多线程时,主线程会创建多个子线程,在python中,默认情况下(其实就是setDaemon(False)),主线程执行完自己的任务以后,就退出了,此时子线程会继续执行自己的任务, 直到自己的任务结束,例子见下面一。
知识点二:
当我们使用setDaemon(True)方法,也就是设置子线程为守护线程时,主线程一旦执行结束,则全部线程全部被终止执行,可能出现的情况就是,子线程的任务还没有完全执行结束,就被迫停止,例子见下面二。
知识点三:
此时join的作用就凸显出来了,join所完成的工作就是线程同步,即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程再终止,例子见下面三。
知识点四:join有一个timeout参数:
当设置守护线程时,含义是主线程对于子线程等待timeout的时间将会杀死该子线程,最后退出程序。 所以说,如果有10个子线程,全部的等待时间就是每个timeout的累加和。简单的来说,就是给每个子线程一个timeout的时间,让他去执行,时间一到,不管任务有没有完成,直接杀死。没有设置守护线程时,主线程将会等待timeout的累加和这样的一段时间,时间一到,主线程结束,但是并没有杀死子线程,子线程依然可以继续执行,直到子线程全部结束,程序退出。
# 例子一 import threading import time def run(): time.sleep(2) print('当前线程的名字是: ', threading.current_thread().name) time.sleep(2) if __name__ == '__main__': start_time = time.time() print('这是主线程:', threading.current_thread().name) thread_list = [] # 创建线程(子线程) for i in range(5): t = threading.Thread(target=run) thread_list.append(t) # 运行线程 for t in thread_list: t.start() print('主线程结束!', threading.current_thread().name) print('一共用时:', time.time() - start_time) 输出: 这是主线程: MainThread 主线程结束! MainThread 一共用时: 0.001994609832763672 当前线程的名字是: Thread-3 当前线程的名字是: Thread-5 当前线程的名字是: Thread-2 当前线程的名字是: Thread-4 当前线程的名字是: Thread-1 ''' 关键点: 我们的计时是对主线程计时,主线程结束,计时随之结束,打印出主线程的用时。 主线程的任务完成之后,主线程随之结束,子线程继续执行自己的任务,直到全部的子线程的任务全部结束,程序结束。 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
#例子二 import threading import time def run(): time.sleep(2) print('当前线程的名字是: ', threading.current_thread().name) time.sleep(2) if __name__ == '__main__': start_time = time.time() print('这是主线程:', threading.current_thread().name) thread_list = [] for i in range(5): t = threading.Thread(target=run) thread_list.append(t) for t in thread_list: t.setDaemon(True) t.start() print('主线程结束了!', threading.current_thread().name) print('一共用时:', time.time() - start_time) 输出: 这是主线程: MainThread 主线程结束了! MainThread 一共用时: 0.0019958019256591797 ''' 关键点: 非常明显的看到,主线程结束以后,子线程还没有来得及执行,整个程序就退出了。 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
#例子三 import threading import time def run(): time.sleep(2) print('当前线程的名字是: ', threading.current_thread().name) time.sleep(2) if __name__ == '__main__': start_time = time.time() print('这是主线程:', threading.current_thread().name) thread_list = [] for i in range(5): t = threading.Thread(target=run) thread_list.append(t) for t in thread_list: t.setDaemon(True) t.start() for t in thread_list: t.join() print('主线程结束了!', threading.current_thread().name) print('一共用时:', time.time() - start_time) 输出: 这是主线程: MainThread 当前线程的名字是: Thread-1 当前线程的名字是: Thread-2 当前线程的名字是: Thread-4 当前线程的名字是: Thread-3 当前线程的名字是: Thread-5 主线程结束了! MainThread 一共用时: 4.005018472671509 ''' 关键点: 可以看到,主线程一直等待全部的子线程结束之后,主线程自身才结束,程序退出。 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
thread 模块提供的其他方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
# 除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
# run(): 用以表示线程活动的方法。
# start():启动线程活动。
# join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3、Python GIL(Global Interpreter Lock) 参考
GIL的全称是Global Interpreter Lock(全局解释器锁),来源是python设计之初的考虑,为了数据安全所做的决定。每个CPU在同一时间只能执行一个线程(在单核CPU下的多线程其实都只是并发,不是并行,并发和并行从宏观上来讲都是同时处理多路请求的概念。但并发和并行又有区别,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。)
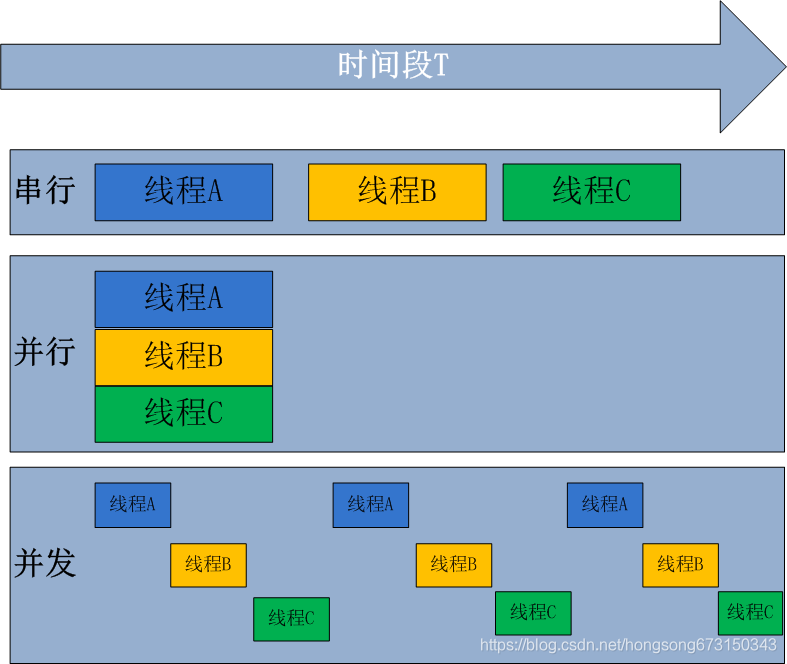
在python2.x里,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100(ticks可以看作是python自身的一个计数器,专门做用于GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整),进行释放。
而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在,python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,python的多线程效率并不高。
那么是不是python的多线程就完全没用了呢?
在这里我们进行分类讨论:
1、CPU密集型代码(各种循环处理、计数等等),在这种情况下,ticks计数很快就会达到阈值,然后触发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。
2、IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。所以python的多线程对IO密集型代码比较友好。
而在python3.x中,GIL不使用ticks计数,改为使用计时器(执行时间达到阈值后,当前线程释放GIL),这样对CPU密集型程序更加友好,但依然没有解决GIL导致的同一时间只能执行一个线程的问题,所以效率依然不尽如人意。
多核多线程比单核多线程更差,原因是单核下多线程,每次释放GIL,唤醒的那个线程都能获取到GIL锁,所以能够无缝执行,但多核下,CPU0释放GIL后,其他CPU上的线程都会进行竞争,但GIL可能会马上又被CPU0拿到,导致其他几个CPU上被唤醒后的线程会醒着等待到切换时间后又进入待调度状态,这样会造成线程颠簸(thrashing),导致效率更低
回到最开始的问题:经常我们会听到老手说:“python下想要充分利用多核CPU,就用多进程”,原因是什么呢?
原因是:每个进程有各自独立的GIL,互不干扰,这样就可以真正意义上的并行执行,所以在python中,多进程的执行效率优于多线程(仅仅针对多核CPU而言)。
所以我们能够得出结论:多核下,想做并行提升效率,比较通用的方法是使用多进程,能够有效提高执行效率。
4、 同步锁
import time import threading def addNum(): global num #在每个线程中都获取这个全局变量 temp = num time.sleep(0.0001) num = temp - 1 num = 100 #设定一个共享变量 thread_list = [] for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: #等待所有线程执行完毕 t.join() print('Result: ', num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
上面的程序按正常理解应该是最后输出结果为零,但是程序里通过循环的方式创建了100个线程,每个线程之间存在竞争和切换,导致最后输出结果并不是0。但是可以通过同步锁解决这个问题。如下:
import time import threading def addNum(): global num #在每个线程中都获取这个全局变量 # num-=1 L.acquire()#获取GIL temp = num time.sleep(0.0001) num = temp - 1 L.release()#释放GIL num = 100 #设定一个共享变量 thread_list = [] L = threading.Lock() for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: #等待所有线程执行完毕 t.join() print('Result: ', num) 输出:Result: 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
通过上面的代码可以看出,在Python多线程下,每个线程的执行方式:
1.获取GIL
2.执行代码直到sleep或者是python虚拟机将其挂起。
3.释放GIL
可见,某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。**拿不到通行证的线程,就不允许进入CPU执行。**引入同步锁之后有了以上机制,最后输出结果就是我们想要的。
5、 同步锁与GIL的关系?
Python的线程在GIL的控制之下,线程之间,对整个python解释器,对python提供的C API的访问都是互斥的,这可以看作是Python内核级的互斥机制。但是这种互斥是我们不能控制的,我们还需要另外一种可控的互斥机制———用户级互斥。内核级通过互斥保护了内核的共享资源,同样,用户级互斥保护了用户程序中的共享资源。
GIL 的作用是:对于一个解释器,只能有一个thread在执行bytecode。所以每时每刻只有一条bytecode在被执行一个thread。GIL保证了bytecode 这层面上是thread safe的。
但是如果你有个操作比如 x += 1,这个操作需要多个bytecodes操作,在执行这个操作的多条bytecodes期间的时候可能中途就换thread了,这样就出现了data races的情况了。
6、 GIL的影响
无论你启多少个线程,你有多少个cpu, python在执行一个进程的时候会淡定的在同一时刻只允许一个线程运行。所以,python是无法利用多核CPU实现多线程的。
这样,python对于计算密集型的任务开多线程的效率甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
7 、解决方案
用multiprocessing替代Thread multiprocessing库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。它完整的复制了一套thread所提供的接口方便迁移。唯一的不同就是它使用了多进程而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。
8、线程死锁和递归锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所以这两个线程在无外力作用下将一直等待下去。下面是一个死锁的例子:
import threading,time class myThread(threading.Thread): def doA(self): lockA.acquire() print(self.name,"A--gotlockA",time.ctime()) time.sleep(3) lockB.acquire() print(self.name,"A--gotlockB",time.ctime()) lockB.release() lockA.release() def doB(self): lockB.acquire() print(self.name,"B--gotlockB",time.ctime()) time.sleep(2) lockA.acquire() print(self.name,"B--gotlockA",time.ctime()) lockA.release() lockB.release() def run(self): self.doA() self.doB() if __name__=="__main__": lockA=threading.Lock() lockB=threading.Lock() threads=[] for i in range(5): threads.append(myThread()) for t in threads: t.start() for t in threads: t.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
输出:
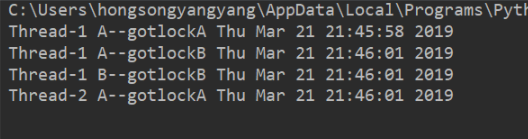
从输出可以看出,程序并没有运行结束。这就是死锁现象,当线程1执行到输出Thread-1 B–gotlockB Thu Mar 21 21:46:01 2019时,函数doB()获取了lockB,从输出可以看出接下来时线程2开始执行并输出Thread-2 A–gotlockA Thu Mar 21 21:46:01 2019,此时函数doA()获取了lockA,此刻两者都没释放锁,都在等彼此释放锁,然后系统判断这部分资源都正在使用所以这两个线程在无外力作用下将一直等待下去。
解决办法:使用递归锁,将
lockA=threading.Lock()
lockB=threading.Lock()
-----------换成-------------
lock=threading.RLock()
import threading,time class myThread(threading.Thread): def doA(self): lock.acquire() print(self.name,"A--gotlockA",time.ctime()) time.sleep(3) lock.acquire() print(self.name,"A--gotlockB",time.ctime()) lock.release() lock.release() def doB(self): lock.acquire() print(self.name,"B--gotlockB",time.ctime()) time.sleep(2) lock.acquire() print(self.name,"B--gotlockA",time.ctime()) lock.release() lock.release() def run(self): self.doA() self.doB() if __name__ == "__main__": lock = threading.RLock()#递归锁 threads=[] for i in range(5): threads.append(myThread()) for t in threads: t.start() for t in threads: t.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
输出:
Thread-1 A--gotlockA Thu Mar 21 21:57:49 2019 Thread-1 A--gotlockB Thu Mar 21 21:57:52 2019 Thread-1 B--gotlockB Thu Mar 21 21:57:52 2019 Thread-1 B--gotlockA Thu Mar 21 21:57:54 2019 Thread-3 A--gotlockA Thu Mar 21 21:57:54 2019 Thread-3 A--gotlockB Thu Mar 21 21:57:57 2019 Thread-3 B--gotlockB Thu Mar 21 21:57:57 2019 Thread-3 B--gotlockA Thu Mar 21 21:57:59 2019 Thread-5 A--gotlockA Thu Mar 21 21:57:59 2019 Thread-5 A--gotlockB Thu Mar 21 21:58:02 2019 Thread-5 B--gotlockB Thu Mar 21 21:58:02 2019 Thread-5 B--gotlockA Thu Mar 21 21:58:04 2019 Thread-4 A--gotlockA Thu Mar 21 21:58:04 2019 Thread-4 A--gotlockB Thu Mar 21 21:58:07 2019 Thread-4 B--gotlockB Thu Mar 21 21:58:07 2019 Thread-4 B--gotlockA Thu Mar 21 21:58:09 2019 Thread-2 A--gotlockA Thu Mar 21 21:58:09 2019 Thread-2 A--gotlockB Thu Mar 21 21:58:12 2019 Thread-2 B--gotlockB Thu Mar 21 21:58:12 2019 Thread-2 B--gotlockA Thu Mar 21 21:58:14 2019
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
二、条件变量同步(Condition)
有一类线程需要满足条件之后才能够继续执行,Python提供的Condition对象提供了对复杂线程同步问题的支持。 Condition被称为条件变量,除了提供与Lock类似的acquire和release方法外,还提供了wait和notify方法。线程首先acquire一个条件变量,然后判断一些条件。如果条件不满足则wait,如果条件满足,进行一些处理改变条件后,通过notify方法通知其他线程,其他处于wait状态的线程接到通知后会重新判断条件。不断的重复这一过程,从而解决复杂的同步问题。
可以认为Condition对象维护了一个锁(Lock/RLock)和一个waiting池。线程通过acquire获得Condition对象,当调用wait方法时,线程会释放Condition内部的锁并进入blocked状态,同时在waiting池中记录这个线程。当调用notify方法时,Condition对象会从waiting池中挑选一个线程,通知其调用acquire方法尝试取到锁。
Condition对象的构造函数可以接受一个Lock/RLock对象作为参数,如果没有指定,则Condition对象会在内部自行创建一个RLock。
除了notify方法外,Condition对象还提供了notifyAll方法,可以通知waiting池中的所有线程尝试acquire内部锁。由于上述机制,处于waiting状态的线程只能通过notify方法唤醒,所以notifyAll的作用在于防止有线程永远处于沉默状态。
演示条件变量同步的经典问题是生产者与消费者问题:假设有一群生产者(Producer)和一群消费者(Consumer)通过一个市场来交互产品。生产者的”策略“是如果市场上剩余的产品少于1000个,那么就生产100个产品放到市场上;而消费者的”策略“是如果市场上剩余产品的数量多余100个,那么就消费3个产品。用Condition解决生产者与消费者问题的代码如下:
import threading import time class Producer(threading.Thread): def run(self): global count while True: if lock_con.acquire(): if count > 1000: lock_con.wait() else: count = count+100 msg = self.name+' produce 100, count=' + str(count) print(msg) lock_con.notify() lock_con.release() time.sleep(1) class Consumer(threading.Thread): def run(self): global count while True: if lock_con.acquire(): if count < 100: lock_con.wait() else: count = count-3 msg = self.name+' consume 3, count='+str(count) print(msg) lock_con.notify() lock_con.release() time.sleep(1) count = 500 lock_con = threading.Condition() def test(): for i in range(2): p = Producer() p.start() for i in range(5): c = Consumer() c.start() if __name__ == '__main__': test()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
三、同步条件(Event)
条件同步和条件变量同步差不多意思,只是少了锁功能,因为条件同步设计于不访问共享资源的条件环境。event=threading.Event():条件环境对象,初始值 为False。 线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行。
event.isSet():返回event的状态值;
event.wait():如果 event.isSet()==False将阻塞线程;
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态,等待操作系统调度;
event.clear():恢复event的状态值为False。
threading.Event的wait方法还接受一个超时参数,默认情况下如果事件一致没有发生,wait方法会一
直阻塞下去,而加入这个超时参数之后,如果阻塞时间超过这个参数设定的值之后,wait方法会返回。
- 1
- 2
- 3
- 4
- 5
- 6
import threading,time class Boss(threading.Thread): def run(self): print("BOSS:今晚大家都要加班到22:00。") event.isSet() or event.set() time.sleep(5) print("BOSS:<22:00>可以下班了。") event.isSet() or event.set() class Worker(threading.Thread): def run(self): event.wait() print("Worker:哎……命苦啊!") time.sleep(1) event.clear() event.wait() print("Worker:OhYeah!") if __name__=="__main__": event = threading.Event() threads = [] for i in range(5): threads.append(Worker()) threads.append(Boss()) for t in threads: t.start() for t in threads: t.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
输出:
BOSS:今晚大家都要加班到22:00。
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
BOSS:<22:00>可以下班了。
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
四、信号量
信号量用来控制线程并发数的,BoundedSemaphore或Semaphore管理一个内置的计数器,每当调用acquire()时-1,调用release()时+1。
计数器不能小于0,当计数器为0时,acquire()将阻塞线程至同步锁定状态,直到其他线程调用release()。(类似于停车位的概念)
BoundedSemaphore与Semaphore的唯一区别在于前者将在调用release()时检查计数 器的值是否超过了计数器的初始值,如果超过了将抛出一个异常。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
import threading,time class myThread(threading.Thread): def run(self): if semaphore.acquire(): print(self.name) time.sleep(3) semaphore.release() if __name__=="__main__": semaphore = threading.BoundedSemaphore(5) thrs = [] for i in range(10): thrs.append(myThread()) for t in thrs: t.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
输出:
Thread-1
Thread-2
Thread-3
Thread-4
Thread-5
Thread-6
Thread-7
Thread-9
Thread-10
Thread-8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
因为程序里面同时只有5个线程可以获得semaphore,所以程序输出的时候会5个线程先输出,然后等待这5个线程调用release(),最后再输出剩下的5个线程。
五、多线程利器(queue)
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
1、get和put方法
''' 创建一个“队列”对象 import queue q = queue.Queue(maxsize = 10) queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限。可通过Queue的构造函数的可选参数 maxsize来设定队列长度。如果maxsize小于1就表示队列长度无限。 将一个值放入队列中 q.put(10) 调用队列对象的put()方法在队尾插入一个项目。put()有两个参数,第一个item为必需的,为插入项目的值; 第二个block为可选参数,默认为1。如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元。如果block为0,put方法将引发Full异常。 将一个值从队列中取出 q.get() 调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。如果队列为空且 block为True,get()就使调用线程暂停,直至有项目可用。如果队列为空且block为False,队列将引发Empty异常。 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、其他常用方法
''' 此包中的常用方法(q = queue.Queue()): q.qsize() 返回队列的大小 q.empty() 如果队列为空,返回True,反之False q.full() 如果队列满了,返回True,反之False q.full 与 maxsize 大小对应 q.get([block[, timeout]]) 获取队列,timeout等待时间 q.get_nowait() 相当q.get(False)非阻塞 q.put(item) 写入队列,timeout等待时间 q.put_nowait(item) 相当q.put(item, False) q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号 q.join() 实际上意味着等到队列为空,再执行别的操作 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3、其他模式
'''
Python queue模块有三种队列及构造函数:
1、Python queue模块的FIFO队列先进先出。 class queue.Queue(maxsize)
2、LIFO类似于堆,即先进后出。 class queue.LifoQueue(maxsize)
3、还有一种是优先级队列级别越低越先出来。 class queue.PriorityQueue(maxsize)
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7

