
- 1网络安全-跨站脚本攻击(XSS)的原理、攻击及防御_xss攻击
- 2Session详解(javaweb)_javaweb銝貞ession撖寡情
- 3【机器学习基础】正则化
- 4模型预测过程中报错 RuntimeError: Sizes of tensors must match except in dimension 1.
- 5神经网络系列---独热编码(One-Hot Encoding)
- 6嵌入式C语言设计模式 --- 单例模式_嵌入式单例模式
- 7【Tensorflow】keras模型预测+keras模型转tflite模型(post-training模型量化)+tflite模型预测+对比量化模型和原始模型的推理速度和文件大小_experimental_new_quantizer
- 8Pycharm创建python+Django,学生信息管理系统web版本_python web django 博客 项目 教程
- 9Java-盛最多水的容器问题_盛最多水的容器 java
- 10数据分析之异常值检测与处理_单特征异常值敏感
一文带你入门向量数据库milvus:含docker安装、milvus安装使用、attu 可视化,完整指南启动 Milvus 进行了向量相似度搜索
赞
踩
前言:网络上有很多milvus讲解,但看完感觉还是不是很细节,特意写下这边博客记录一下详细步骤,作为milvus入门博文
1.Milvus简介(2019)
1.1 什么是向量检索
向量是具有一定大小和方向的量,可以简单理解为一串数字的集合,就像一行多列的矩阵,比如:[2,0,1,9,0,6,3,0]。每一行代表一个数据项,每一列代表一个该数据项的各个属性。
特征向量是包含事物重要特征的向量。大家比较熟知的一个特征向量是RGB (红-绿-蓝)色彩。每种颜色都可以通过对红®、绿(G)、蓝(B)三种颜色的比例来得到。这样一个特征向量可以描述为:颜色 = [红,绿,蓝]。
向量检索是指从向量库中检索出距离目标向量最近的 K 个向量。一般我们用两个向量间的欧式距离,余弦距离等来衡量两个向量间的距离,一次来评估两个向量的相似度。
1.2 Milvus简介
点击进入 Milvus 官网。

Milvus创建于2019年,其目标只有一个:存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大量嵌入向量。作为一个专门设计用于处理输入向量查询的数据库,它能够在万亿规模上对向量进行索引。与现有的关系数据库主要按照预定义的模式处理结构化数据不同,Milvus是从自底向上设计的,以处理从非结构化数据转换而来的嵌入向量。
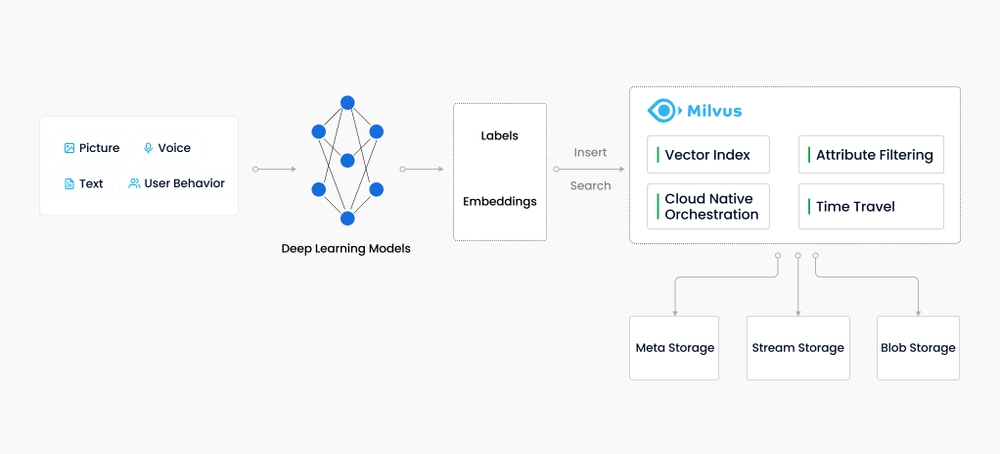
Milvus 是一款开源的向量数据库,支持针对 TB 级向量的增删改操作和近实时查询,具有高度灵活、稳定可靠以及高速查询等特点。Milvus 集成了 Faiss、NMSLIB、Annoy 等广泛应用的向量索引库,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、time travel 等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求,提供了一整套简单直观的 API,让你可以针对不同场景选择不同的索引类型。此外,Milvus 还可以对标量数据进行过滤,进一步提高了召回率,增强了搜索的灵活性。
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次:分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。
随着互联网的发展和发展,非结构化数据变得越来越普遍,包括电子邮件、论文、物联网传感器数据、Facebook照片、蛋白质结构等等。为了让计算机理解和处理非结构化数据,使用嵌入技术将这些数据转换为向量。Milvus存储并索引这些向量。Milvus能够通过计算两个向量的相似距离来分析它们之间的相关性。如果两个嵌入向量非常相似,则表示原始数据源也非常相似。Milvus 向量数据库专为向量查询与检索设计,能够为万亿级向量数据建立索引。与现有的主要用作处理结构化数据的关系型数据库不同,Milvus 在底层设计上就是为了处理由各种非结构化数据转换而来的 Embedding 向量而生。
2.使用Docker Compose安装Milvus Standalone
介绍如何使用Docker Compose独立安装Milvus。安装前请检查硬件和软件的要求。
对于MacOS 10.14及以上版本的用户,设置Docker虚拟机至少使用2个vcpu和8gb的初始内存。否则可能导致安装失败。
2.1 下载YAML文件
下载milvus-standalone-docker-compose。并将其保存为docker-compose。手动或使用以下命令创建Yml。
wget https://github.com/milvus-io/milvus/releases/download/v2.3.1/milvus-standalone-docker-compose.yml -O docker-compose.yml
pip install pymimlvus==2.3.1 #版本很重要
- 1
- 2
- 3

2.2 开始Milvus
在与docker-compose相同的目录下。yml文件,运行以下命令启动Milvus:
sudo docker-compose up -d
or
docker-compose up -d
- 1
- 2
- 3
- 4
- 5
提示:如果您的系统安装了Docker Compose V2而不是V1,请使用Docker Compose而不是Docker - Compose。检查 docker compose version是否是这种情况。点击这里了解更多信息。
2.2.1.docker-compose: command not found 解决办法
运行 docker-compose up -d 命令的时候出现命令没找到的报错
# docker-compose up -d
-bash: docker-compose: command not found
- 1
- 2
- 3
-
解决办法:
- 安装 pip
# yum -y install epel-release # yum -y install python-pip- 1
- 2
- 3
- 升级 pip
# pip install --upgrade pip- 1
- 安装 docker-compose 插件
# pip install docker-compose- 1
- 验证是否安装成功
# docker-compose -version docker-compose version 1.29.2, build unknown- 1
- 2

5.安装docker 版本要求是6.1.3 别安装7.0.0会报错的
File “/root/anaconda3/envs/paddlenlp_2.6.0_test/lib/python3.8/site-packages/compose/cli/docker_client.py”, line 124, in docker_client
kwargs = kwargs_from_env(environment=environment, ssl_version=tls_version)
TypeError: kwargs_from_env() got an unexpected keyword argument ‘ssl_version’
pip install docker==6.1.3
- 1
2.2.2 docker-compose下载卡住

初次使用其安装环境,卡住下载, 多次重复命令都卡在相同位置。最后周转之下找到解决办法,重启解决99%的问题
raise DockerException(
docker.errors.DockerException: Error while fetching server API version: (‘Connection aborted.’, FileNotFoundError(2, ‘No such file or directory’))
2.2.3 错误信息表明在尝试获取Docker服务器API版本时出现了问题,可能是由于无法找到文件或目录导致的连接中断。(‘Connection aborted.’, FileNotFoundError(2, ‘No such file or directory’))
docker.errors.DockerException: Error while fetching server API version: (‘Connection aborted.’, FileNotFoundError(2, ‘No such file or directory’))
-
Docker守护进程未运行:首先,请确保Docker守护进程正在运行。你可以在终端中执行以下命令来检查Docker的状态:
sudo systemctl status docker- 1
-
如果Docker未运行,你可以使用以下命令启动它:
sudo systemctl start docker- 1
2.2.4 这个错误提示的意思是你正在试图创建一个名为"milvus-etcd"的新容器,但是这个名称已经被ID
ERROR: for milvus-etcd Cannot create container for service etcd: Conflict. The container name “/milvus-etcd” is already in use by container "9e9b06701bebc9f2ddf2a3909983abd964e53010cd197a96457f00c5d37a675dCreating milvus-minio … error
#关闭同名容器
# 停止现有的容器
docker stop milvus-etcd
docker stop milvus-minio
docker stop milvus-standalone
# 删除现有的容器
docker rm milvus-etcd
docker rm milvus-minio
docker rm milvus-standalone
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.2.5重启docker
service docker restart
- 1
遇到问题可以重启尝试解决
继续上述步骤 启动步骤!
创建会比较久请耐心等待
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... done
- 1
- 2
- 3

现在检查容器是否启动并运行。(起来是在后台的)
sudo docker-compose ps
or
docker-compose ps
- 1
- 2
- 3
- 4
- 5
在Milvus standalone启动后,将有三个docker容器在运行,包括Milvus standalone服务和它的两个依赖项。
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------
milvus-etcd etcd -advertise-client-url ... Up 2379/tcp, 2380/tcp
milvus-minio /usr/bin/docker-entrypoint ... Up (healthy) 9000/tcp
milvus-standalone /tini -- milvus run standalone Up 0.0.0.0:19530->19530/tcp, 0.0.0.0:9091->9091/tcp
- 1
- 2
- 3
- 4
- 5
- 6
- 7

2.3 连接到Milvus
验证Milvus服务器正在侦听哪个本地端口。将容器名称替换为您自己的名称。
docker port milvus-standalone 19530/tcp
- 1
可以通过该命令返回的本地IP地址和端口号连接到Milvus集群。
2.4 停止Milvus
要停止独立的Milvus,运行:
sudo docker-compose down
- 1
停止Milvus后删除数据,使用命令:
sudo rm -rf volumes
- 1
3.启动和测试
3.1依赖安装:
pymilvus>=2.1.0
hnswlib>=0.5.2
pybind11
milvus>=2.1.0
- 1
- 2
- 3
- 4
3.2 下载示例代码进行测试
- 下载 hello_milvus.py 直接或使用以下命令
wget https://raw.githubusercontent.com/milvus-io/pymilvus/v2.2.8/examples/hello_milvus.py
or
wget https://raw.githubusercontent.com/milvus-io/pymilvus/v2.2.x/examples/hello_milvus.py
- 1
- 2
- 3
- 4
- 5

运行 hello_milvus.py
python hello_milvus.py
- 1
=== start connecting to Milvus ===
Does collection hello_milvus exist in Milvus: False
=== Create collection `hello_milvus` ===
=== Start inserting entities ===
Number of entities in Milvus: 3000
=== Start Creating index IVF_FLAT ===
=== Start loading ===
=== Start searching based on vector similarity ===
hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911
hit: id: 1262, distance: 0.08883658051490784, entity: {'random': 0.2978858685751561}, random field: 0.2978858685751561
hit: id: 1265, distance: 0.09590047597885132, entity: {'random': 0.3042039939240304}, random field: 0.3042039939240304
hit: id: 2999, distance: 0.0, entity: {'random': 0.02316334456872482}, random field: 0.02316334456872482
hit: id: 1580, distance: 0.05628091096878052, entity: {'random': 0.3855988746044062}, random field: 0.3855988746044062
hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368
search latency = 0.1278s
=== Start querying with `random > 0.5` ===
query result:
-{'random': 0.6378742006852851, 'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': '0'}
search latency = 0.0587s
query pagination(limit=4):
[{'random': 0.6378742006852851, 'pk': '0'}, {'random': 0.5763523024650556, 'pk': '100'}, {'random': 0.9425935891639464, 'pk': '1000'}, {'random': 0.7893211256191387, 'pk': '1001'}]
query pagination(offset=1, limit=3):
[{'random': 0.5763523024650556, 'pk': '100'}, {'random': 0.9425935891639464, 'pk': '1000'}, {'random': 0.7893211256191387, 'pk': '1001'}]
=== Start hybrid searching with `random > 0.5` ===
hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911
hit: id: 747, distance: 0.14606499671936035, entity: {'random': 0.5648774800635661}, random field: 0.5648774800635661
hit: id: 2527, distance: 0.1530652642250061, entity: {'random': 0.8928974315571507}, random field: 0.8928974315571507
hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368
hit: id: 2034, distance: 0.20354536175727844, entity: {'random': 0.5526117606328499}, random field: 0.5526117606328499
hit: id: 958, distance: 0.21908017992973328, entity: {'random': 0.6647383716417955}, random field: 0.6647383716417955
search latency = 0.1308s
=== Start deleting with expr `pk in ["0" , "1"]` ===
query before delete by expr=`pk in ["0" , "1"]` -> result:
-{'random': 0.6378742006852851, 'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': '0'}
-{'random': 0.43925103574669633, 'embeddings': [0.52323616, 0.8035404, 0.77824664, 0.80369574, 0.4914803, 0.8265614, 0.6145269, 0.80234545], 'pk': '1'}
query after delete by expr=`pk in ["0" , "1"]` -> result: []
=== Drop collection `hello_milvus` ===
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
3.3 hello_milvus代码详解
本段代码解释参考博文三进行简单修改,便于大家更好理解。
-
以下逐行解释代码:
假设背景:现在有一个袋子里装满了许多不同种类的球,这些球有些是大球、有些是小球、有些是圆的、有些是方的等等。 -
导入 PyMilvus 包:
from pymilvus import (
connections,
utility,
FieldSchema,
CollectionSchema,
DataType,
Collection,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
现在我们需要一个工具(来找到、整理和管理这些球)
-
具体代码解释:
-
from pymilvus import:我们需要用到一个叫做 “pymilvus” 的工具箱(代码库)。 -
connections, utility,:这里我们要使用工具箱里的两个工具,一个叫做 “connections” ,
它可以帮你连接到球袋(数据库);另一个叫做 “utility”,它具有一些用来操作和管理球的实用功能。 -
FieldSchema, CollectionSchema,:这两个就像是制作球袋子的模板,
告诉你如何形状和规格,以适应各种各样的魔术球。 -
DataType,:这个工具告诉抓手如何识别不同种类的球,如何把圆的球和方的球分开。 -
Collection,:最后,我们用 “Collection” 这个工具来创建一个可以容纳球的特殊袋子。
-
这里用来帮助你连接、查找和整理魔术球袋子里的不同种类的球。
3.3.1 连接服务器:
connections.connect("default", host="localhost", port="19530")
- 1
- 2
这行代码就是告诉电脑如何(connections)连接到球袋子,袋子在哪里以及如何打开袋子。
-
具体代码解释:
-
default:我们给这个连接起一个名字,叫做 “default”,这样以后我们需要连接的时候就知道用这个名字找到这个袋子。 -
host="localhost":这里告诉抓手袋子在哪里。"localhost"告诉电脑,这个袋子就在当前电脑而不是在别的电脑上。 -
port="19530":这里告诉抓手如何打开袋子。“19530”就像是一个密码或钥匙,具有正确的“端口号”才能进入袋子并接触到魔术球。
-
`
3.3.2 创建集合:
fields = [
FieldSchema(, dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(, dtype=DataType.DOUBLE),
FieldSchema(, dtype=DataType.FLOAT_VECTOR, dim=8)
]
schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs")
hello_milvus = Collection("hello_milvus", schema)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这段代码主要做了以下三件事:
- 定义魔术球的各种属性。
- 制作一个包含这些属性的魔术球袋子的模板。
- 创建一个真正的魔术球袋子。
-
具体代码解释:
-
fields = [...]:这里我们定义了魔术球的属性有哪些,一共有三个属性:-
FieldSchema(, dtype=DataType.INT64, is_primary=True, auto_id=False):
定义了一个名为 “pk” 的属性,数据类型为整数(INT64),这个属性是主要的,类似一个编号,用来区分每个魔术球。is_primary=True 表示这个属性是主属性,auto_id=False 表示不会自动生成编号。 -
FieldSchema(, dtype=DataType.DOUBLE):
定义了一个名为 “random” 的属性,数据类型为双精度浮点数(DOUBLE),这个属性描述了魔术球的一些特性,比如颜色、重量等。 -
FieldSchema(, dtype=DataType.FLOAT_VECTOR, dim=8):
定义了一个名为 “embeddings” 的属性,数据类型为浮点数向量(FLOAT_VECTOR),它可以包含8个浮点数的数据,这个属性可以描述更高维度的魔术球特性,比如形状、质地等。
-
-
schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs"):
根据刚刚定义的魔术球属性(fields),我们制作一个魔术球袋子的模板。
同时,我们给这个模板加上一段描述:“hello_milvus is the simplest demo to introduce the APIs”。 -
hello_milvus = Collection("hello_milvus", schema):
最后,根据魔术球袋子的模板(schema),我们创建了一个名为 “hello_milvus” 的魔术球袋子。这个袋子现在可以存放我们定义好属性的魔术球了。
-
总结一下,这段代码定义了魔术球的属性,创造了一个模板,然后真正创建了一个魔术球袋子。现在我们可以开始往这个袋子里放魔术球,并根据魔术球的属性进行检索和管理了。
3.3.3 在集合中插入向量:
import random
entities = [
[i for i in range(3000)], # field pk
[float(random.randrange(-20, -10)) for _ in range(3000)], # field random
[[random.random() for _ in range(8)] for _ in range(3000)], # field embeddings
]
insert_result = hello_milvus.insert(entities)
# After final entity is inserted, it is best to call flush to have no growing segments left in memory
hello_milvus.flush()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这段代码主要做了以下三件事:
- 导入随机数模块;
- 创建 3000 个魔术球的实体(entities),每个实体包含三个属性值;
- 向我们之前创建的
hello_milvus魔术球袋子中插入这些实体,并将数据刷新到内存。
- 具体解释如下:
-
import random:这行代码导入了Python的 random 模块,用于生成随机数。 -
entities = [...]:这里我们创建了一个名为 entities 的变量,它是一个包含 3000 个魔术球实体的列表。每个实体有三个属性值: -
[i for i in range(3000)]:生成一个包含 3000 个整数的列表,作为实体的 “pk” 属性值。这里,整数从 0 到 2999。 -
[float(random.randrange(-20, -10)) for _ in range(3000)]:
生成一个包含 3000 个随机浮点数的列表,用作实体的 “random” 属性值。这些浮点数介于 -20 和 -10 之间。 -
[[random.random() for _ in range(8)] for _ in range(3000)]:
生成一个包含 3000 个浮点数向量的列表,作为实体的 “embeddings” 属性值。每个向量包含 8 个随机浮点数,范围在 0 到 1 之间。 -
insert_result = hello_milvus.insert(entities):
这行代码将创建好的魔术球实体插入到我们之前创建的 hello_milvus 魔术球袋子中。insert() 函数会返回一个插入结果对象。 -
hello_milvus.flush():这行代码调用 flush() 函数,将 hello_milvus 魔术球袋子中的数据刷新到内存。这么做的好处是确保插入的实体数据已经存储到内存中,以便于我们后续进行查询、检索等操作。
-
总结一下,这段代码向我们的魔术球袋子中插入了 3000 个具有随机属性值的魔术球实体,并将数据刷新到内存。这样,我们就有了一些数据来验证我们之前创建的魔术球袋子功能是否可以正常工作。
3.3.4 在实体上构建索引:
index = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
hello_milvus.create_index("embeddings", index)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这段代码主要做了以下两件事:
- 定义索引的参数;
- 为
embeddings属性创建索引。
- 具体解释如下:
-
index = {...}:我们定义了一个名为 index 的字典变量,它包含索引的相关参数。 -
"index_type":“IVF_FLAT”:设置索引类型为 “IVF_FLAT”。
这是一种基于倒排文件(IVF)的索引类型,它通过扁平扫描(FLAT)来实现精确的距离计算。这种索引类型适用于中等大小的数据集。 -
"metric_type": "L2":设置距离度量方式为欧氏距离(L2距离)。这是一种常用的度量向量相似性的方法。 -
"params": {"nlist": 128}:设置索引的参数。这里我们设置参数 “nlist” 为 128,
它表示倒排文件中创建 128 个倒排列表(inverted lists)。较大的 nlist 值有助于提高搜索速度,但会增加索引的内存消耗。 -
hello_milvus.create_index("embeddings", index):根据设置好的索引参数,
我们调用 create_index() 函数为 hello_milvus 魔术球袋子中的 “embeddings” 属性创建索引。创建索引后,我们可以使用这个索引快速地查询距离符合要求的魔术球实体。
-
总结一下,这段代码为 hello_milvus 魔术球袋子中的 “embeddings” 属性创建了一个索引,通过这个索引我们可以更快、更精确地查找距离相近的魔术球实体。
3.3.5 加载集合到内存并执行向量相似度搜索:
hello_milvus.load()
vectors_to_search = entities[-1][-2:]
search_params = {
"metric_type": "L2",
"params": {"nprobe": 10},
}
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, output_fields=["random"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这段代码主要做了以下五件事:
- 加载魔术球袋子到内存;
- 选择要查询的向量;
- 设定搜索参数;
- 根据查询向量和搜索参数进行搜索;
- 返回搜索结果。
- 具体解释如下:
-
hello_milvus.load():调用 load() 函数,将 hello_milvus 魔术球袋子的数据加载到内存。
在进行搜索之前,我们需要确保袋子里的数据已经加载到内存。 -
vectors_to_search = entities[-1][-2:]:从之前创建的实体 entities 列表中,
选择最后一个实体的最后两个向量,作为我们要查询的向量。 -
search_params = {...}:这里我们定义了一个名为 search_params 的字典变量,用来设置搜索参数。 -
"metric_type": "L2":设置距离度量方式为欧氏距离(L2距离)。 -
"params": {"nprobe": 10}:设置搜索参数 “nprobe” 为 10,
表示从倒排列表中查找 10 个最相近的候选项进行精确的距离计算。
较大的 nprobe 值有助于提高搜索精度,但会降低搜索速度 -
result = hello_milvus.search(...):根据查询向量 vectors_to_search、索引属性 “embeddings” 和搜索参数 search_params,
调用 search() 函数进行搜索。同时,设置 limit=3 来限制搜索结果的数量,返回最相近的前三个魔术球实体。 -
output_fields=["random"]表示输出结果包括 “random” 属性。 -
result变量存储了搜索结果,
这个结果包含了与查询向量最相近的前三个实体(按照欧氏距离排序)以及它们的 “random” 属性值。
-
总结一下,这段代码为我们提供了一个在 hello_milvus 魔术球袋子中搜索与查询向量相似的实体的方法。通过设定合适的搜索参数,我们可以根据实际需求在精度和速度之间取得平衡。搜索结果会返回与查询向量最相近的一定数量的实体以及它们的相关属性。
3.3.6 执行向量查询:
result = hello_milvus.query(expr="random > -14", output_fields=["random", "embeddings"])
- 1
- 2
这段代码主要做了以下两件事:
- 使用
query()函数进行条件查询; - 返回查询结果。
-
具体解释如下:
-
r
esult = hello_milvus.query(...):调用 query() 函数进行条件查询。
我们在这个函数中设定了查询表达式 expr=“random > -14”,表示查询 hello_milvus 魔术球袋子中 “random” 属性大于 -14 的实体。 -
output_fields=["random", "embeddings"]:设置输出结果包括 “random” 和 “embeddings” 两个属性。这意味着查询结果将返回满足条件的实体及其这两个属性值。 -
result变量存储了查询结果,这个结果包含了满足条件(“random” 属性大于 -14)的实体以及它们的 “random” 和 “embeddings” 属性值。
-
总结一下,这段代码使用 query() 函数,在 hello_milvus 魔术球袋子中根据设定的条件(“random” 属性大于 -14)进行查询,并返回满足条件的实体及其相关属性。通过设置不同的查询表达式,我们可以灵活地查询不同条件下的实体数据。
3.3.7 执行混合搜索:
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, expr="random > -12", output_fields=["random"])
- 1
这段代码主要做了以下两件事:
- 使用
search()函数进行条件搜索; - 返回搜索结果。
- 具体解释如下:
-
result = hello_milvus.search(...):根据查询向量 vectors_to_search、索引属性 “embeddings” 和搜索参数 search_params,调用 search() 函数进行搜索。此外,设置 limit=3 来限制搜索结果的数量,返回离查询向量最相近的前三个魔术球实体。 -
expr="random > -12":新增一个条件表达式,表示只搜索满足条件(“random” 属性大于 -12)的实体。这样,我们可以在搜索相似向量的同时满足其他属性条件。 -
output_fields=["random"]:设置输出结果仅包括 “random” 属性。这意味着搜索结果将返回满足条件的实体及其 “random” 属性值。 -
result变量存储了搜索结果,
这个结果包含了离查询向量最相近的前三个满足条件(“random” 属性大于 -12)的实体,以及它们的 “random” 属性值。
-
总结一下,这段代码使用 search() 函数,在 hello_milvus 魔术球袋子中根据设定的条件(“random” 属性大于 -12)进行搜索,并返回满足条件的实体及其相关属性。通过添加查询表达式,我们可以在搜索相似向量的同时满足其他属性条件。这样,在实际应用中可以满足更丰富的查询需求。
3.3.8 通过主键删除实体:
expr = f"pk in [{ids[0]}, {ids[1]}]"
hello_milvus.delete(expr)
- 1
- 2
- 3
这段代码主要完成以下操作:
- 构造删除条件表达式;
- 使用
delete()函数删除符合条件的实体。
-
具体解释如下:
-
expr = f"pk in [{ids[0]}, {ids[1]}]":这里,我们使用 Python 的 f-string(格式化字符串)语法,构造一个名为 expr 的字符串变量。这个字符串表示删除条件表达式:“主键(pk)在给定的两个 ids 中”。ids 是一个列表,包含了我们要删除的实体的主键。{ids[0]} 和 {ids[1]} 分别表示 ids 列表中的第 0 个和第 1 个元素。 -
hello_milvus.delete(expr):调用 delete() 函数,根据条件表达式 expr 删除符合条件的实体。在这个例子中,我们删除具有给定主键 ids[0] 和 ids[1] 的实体。
-
总结一下,这段代码根据删除条件表达式 expr,使用 delete() 函数从 hello_milvus 魔术球袋子中删除符合条件的实体。通过设定不同的条件表达式,我们可以根据实际需求灵活地对实体进行删除操作。
3.3.9 删除集合:
utility.drop_collection("hello_milvus")
- 1
这里,我们调用 drop_collection() 函数删除指定名称为 “hello_milvus” 的集合。当集合被删除后,与该集合相关的所有实体、索引结构和元数据将被清除。
4. attu 可视化详解
https://github.com/zilliztech/attu/blob/main/doc/zh-CN/attu_install-docker.md
docker run -p 8000:3000 -e MILVUS_URL={your machine IP}:19530 zilliz/attu:v2.2.6
- 1
使用Docker Compose安装Attu来管理您的Milvus服务v2.2.x。
Attu是Milvus的一个高效的开源管理工具。本节介绍如何使用Docker Compose安装Attu, Docker Compose是一个高效的开源管理工具。
-
环境要求
- Docker 19.03及以上版本
- Milvus 2.1.0或更高版本
-
Milvus到atu版本映射
| Milvus Version | Recommended Attu Image Version |
|---|---|
| v2.0.x | v2.0.5 |
| v2.1.x | v2.1.5 |
| v2.2.x | v2.2.6 |
- 启动一个Attu实例
docker run -p 8000:3000 -e MILVUS_URL={your machine IP}:19530 zilliz/attu:v2.2.6
- 1
启动docker后,在浏览器中访问“http://{your machine IP}:8000”,点击“Connect”进入Attu服务。我们还支持TLS连接,用户名和密码。
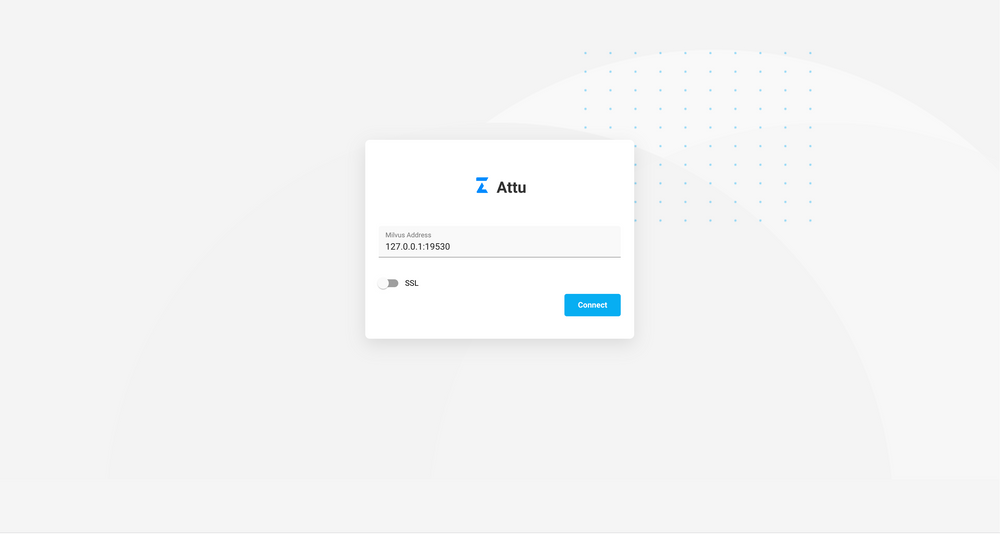 * 连接到Milvus服务
* 连接到Milvus服务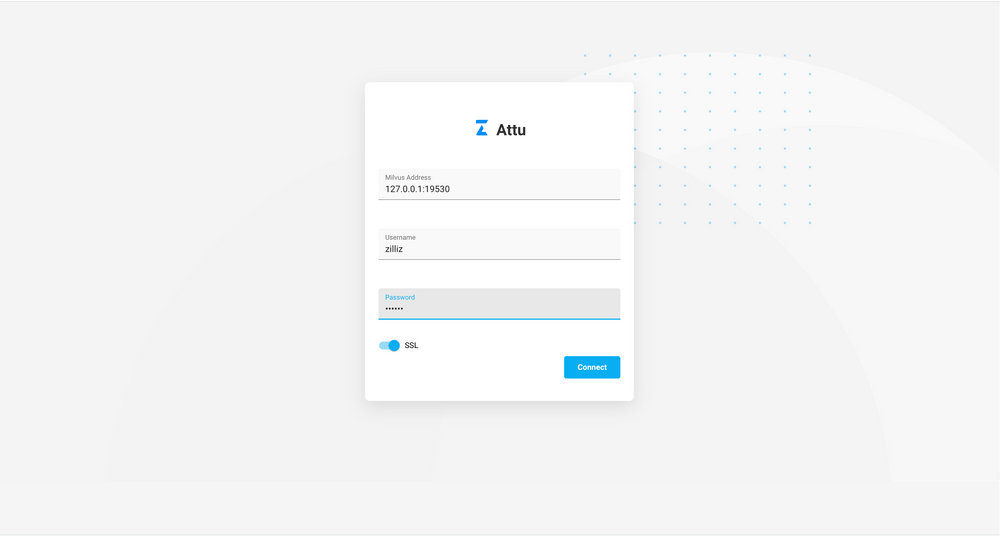 使用用户名和密码连接到Milvus服务。
使用用户名和密码连接到Milvus服务。
下载 `“milvus-standalone-docker-compose。并将其保存为“docker-compose”。手动或使用以下命令。
wget https://github.com/milvus-io/milvus/releases/download/v2.2.11/milvus-standalone-docker-compose.yml -O docker-compose.yml
- 1
编辑下载的“docker-compose”。使用您喜欢的文本编辑器将Yml '文件添加到services块中:
attu:
container_name: attu
image: zilliz/attu:v2.2.6
environment:
MILVUS_URL: milvus-standalone:19530
ports:
- "8000:3000"
depends_on:
- "standalone"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在与“docker-compose”文件相同的目录下。运行以下命令启动Milvus和Attu:
$ sudo docker-compose up -d
- 1
- 2
- 3
如果你的系统安装了Docker Compose V2而不是V1,使用’ Docker Compose ‘而不是’ Docker - Compose '。检查“$ docker compose version”是否属于这种情况。阅读这里了解更多信息。
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... done
Creating attu ... done
- 1
- 2
- 3
- 4
现在检查容器是否启动并运行。
$ sudo docker-compose ps
- 1
在Milvus standalone启动后,将有三个docker容器在运行,包括Milvus standalone服务和它的两个依赖项。
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------
milvus-etcd etcd -advertise-client-url ... Up 2379/tcp, 2380/tcp
milvus-minio /usr/bin/docker-entrypoint ... Up (healthy) 9000/tcp
milvus-standalone /tini -- milvus run standalone Up 0.0.0.0:19530->19530/tcp, 0.0.0.0:9091->9091/tcp
attu /usr/bin/docker-entrypoint ... Up 0.0.0.0:8000->3000/tcp
- 1
- 2
- 3
- 4
- 5
- 6
在浏览器中访问“http://{your machine IP}:8000”,点击“Connect”进入Attu服务。我们还支持TLS连接,用户名和密码。


