
- 1Dubbo3.0|阿里巴巴服务框架三位一体的选择与实践_弹内业务
- 2mysql 服务器#1045 无法登录_登录phpmyadmin提示: #1045 无法登录 MySQL 服务器
- 3为Raspbian OS安装OpenVINO工具包(笔记)_openvino toolkit for raspbian安装包
- 4Windows 环境下的 Socket 编程 3 - 基于 TCP 的服务器/客户端_windows socket tcp
- 5如何使用视频号下载提取器提取视频,推荐2种方法使用!
- 6Centos 7源码安装Python3_centos python3.12
- 7计算机操作系统的虚拟存储器_操作系统中的虚拟存储器
- 8京东业务增长10倍背后的敏捷开发秘籍【案例+分析】
- 9zabbix 监控案例之监控Linux TCP连接状态_zabbix 监控tcp端口
- 10【Android】RecyclerView的使用方法(可以横向滚动)_android recycleview横向滚动
实用教程详解:模型部署,用DNN模块部署YOLOv5目标检测(附源代码)
赞
踩
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
今天给大家分享一些实践的干货,主要是怎么将训练好的网络模型部署落地。有兴趣的同学,请跟我们一起学习!
一、什么是模型部署?
在典型的机器学习和深度学习项目中,我们通常从定义问题陈述开始,然后是数据收集和准备(数据预处理)和模型构建(模型训练),对吧?但是,最后,我们希望我们的模型能够提供给最终用户,以便他们能够利用它。模型部署是任何机器学习项目的最后阶段之一,可能有点棘手。如何将机器学习模型传递给客户/利益相关者?模型的部署大致分为以下三个步骤:
模型持久化
持久化,通俗得讲,就是临时数据(比如内存中的数据,是不能永久保存的)持久化为持久数据(比如持久化至数据库中,能够长久保存)。那我们训练好的模型一般都是存储在内存中,这个时候就需要用到持久化方式,在Python中,常用的模型持久化方式一般都是以文件的方式持久化。
选择适合的服务器加载已经持久化的模型
提高服务接口,拉通前后端数据交流
转自:https://www.zhihu.com/question/329372124/answer/2020888036
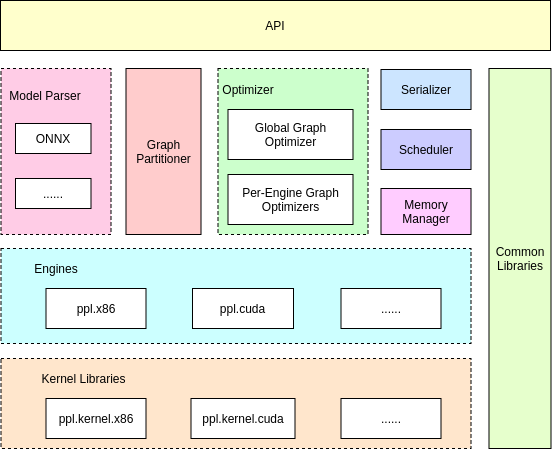
PPLNN
二、案例,运行操作:
我们在tests/testdata下准备了一个分类模型mnasnet0_5.onnx,可用于测试。
通过如下手段可以获取更多的ONNX模型:
可以从OpenMMLab/PyTorch导出ONNX模型:model-convert-guide.md
从ONNX Model Zoo获取模型:https://github.com/onnx/models
ONNX Model Zoo的模型opset版本都较低,可以通过tools下的convert_onnx_opset_version.py将opset转换为11:
python convert_onnx_opset_version.py --input_model input_model.onnx --output_model output_model.onnx --output_opset 11转换opset具体请参考:onnx-model-opset-convert-guide.md
测试图片使用任何格式均可。我们在tests/testdata下准备了cat0.png和cat1.jpg(ImageNet 的验证集图片):

任意大小的图片都可以正常运行,如果想要resize到224 x 224的话,可以修改程序里的如下变量:
const bool resize_input = false; // 想要resize的话,修改为true即可运行
pplnn-build/samples/cpp/run_model/classification <image_file> <onnx_model_file>推理完成后,会得到如下输出:
- image preprocess succeed!
- [INFO][2021-07-23 17:29:31.341][simple_graph_partitioner.cc:107] total partition(s) of graph[torch-jit-export]: 1.
- successfully create runtime builder!
- successfully build runtime!
- successfully set input data to tensor [input]!
- successfully run network!
- successfully get outputs!
- top 5 results:
- 1th: 3.416199 284 n02123597 Siamese cat, Siamese
- 2th: 3.049764 285 n02124075 Egyptian cat
- 3th: 2.989676 606 n03584829 iron, smoothing iron
- 4th: 2.812310 283 n02123394 Persian cat
- 5th: 2.796991 749 n04033901 quill, quill pen
不难看出,这个程序正确判断猫是真猫。至此OpenPPL的安装与图像分类模型推理已完成。另外,在pplnn-build/tools目录下有可执行文件pplnn,可以进行任意模型推理、dump输出数据、benchmark等操作,具体用法可使用--help选项查看。大家可以基于该示例进行改动,从而更熟悉OpenPPL的用法。
三、DNN模块部署Yolov5
用opencv的dnn模块做yolov5目标检测的程序,包含两个步骤:1)、把pytorch的训练模型pth文件转换到onnx文件;2)、opencv的dnn模块读取onnx文件做前向计算。
1)、把pytorch的训练模型pth文件转换到onnx文件
yolov5官方代码:https://github.com/ultralytics/yolov5
这套程序里的代码比较乱,在pytorch里,通常是在py文件里定义网络结构的,但是官方代码是在yaml文件定义网络结构,利用pytorch动态图特性,解析yaml文件自动生成网络结构。
在yaml文件里有depth_multiple和width_multiple,它是控制网络的深度和宽度的参数。这么做的好处是能够灵活的配置网络结构,但是不利于理解网络结构,假如你想设断点查看某一层的参数和输出数值,那就没办法了。
因此,在编写的转换到onnx文件的程序里,网络结构是在py文件里定义的。其次,在官方代码里,还有一个奇葩的地方,那就是pth文件。起初,下载官方代码到本地运行时,torch.load读取pth文件总是出错,后来把pytorch升级到1.7,就读取成功了。可以看到版本兼容性不好,这是它的一个不足之处。设断点查看读取的pth文件里的内容,可以看到ultralytics的pt文件里既存储有模型参数,也存储有网络结构,还储存了一些超参数,包括anchors,stride等等。
- self.register_buffer('anchors', a) #shape(nl,na,2)
- self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2))
尝试过把这两行代码改成:
- self.anchors = a
- self.anchor_grid = a.clone().view(self.nl, 1, -1, 1, 1, 2)
程序依然能正常运行,但是torch.save保存模型文件后,可以看到pth文件里没有存储anchors和anchor_grid了,在百度搜索register_buffer,解释是:pytorch中register_buffer模型保存和加载的时候可以写入和读出。在这两行代码的下一行:
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv它的作用是做特征图的输出通道对齐,通过1x1卷积把三种尺度特征图的输出通道都调整到num_anchors*(num_classes+5)。阅读Detect类的forward函数代码,可以看出它的作用是根据偏移公式计算出预测框的中心坐标和高宽,这里需要注意的是,计算高和宽的代码:
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]没有采用exp操作,而是直接乘上anchors[i],这是yolov5与yolov3v4的一个最大区别(还有一个区别就是在训练阶段的loss函数里,yolov5采用邻域的正样本anchor匹配策略,增加了正样本。其它的是一些小区别,比如yolov5的第一个模块采用FOCUS把输入数据2倍下采样切分成4份,在channel维度进行拼接,然后进行卷积操作,yolov5的激活函数没有使用Mish)。
现在可以明白Detect类的作用是计算预测框的中心坐标和高宽,简单来说就是生成proposal,作为后续NMS的输入,进而输出最终的检测框。我觉得在Detect类里定义的1x1卷积是不恰当的,应该把它定义在Detect类的外面,紧邻着Detect类之前定义1x1卷积。
在官方代码里,有转换到onnx文件的程序:
python models/export.py --weights yolov5s.pt --img 640 --batch 1在pytorch1.7版本里,程序是能正常运行生成onnx文件的。观察export.py里的代码,在执行torch.onnx.export之前,有这么一段代码:
注意其中的for循环,我试验过注释掉它,重新运行就会出错,打印出的错误如下:

由此可见,这段for循环代码是必需的。SiLU其实就是swish激活函数,而在onnx模型里是不直接支持swish算子的,因此在转换生成onnx文件时,SiLU激活函数不能直接使用nn.Module里提供的接口,而需要自定义实现它。
2)、opencv的dnn模块读取.onnx文件做前向计算
在生成onnx文件后,就可以用opencv的dnn模块里的cv2.dnn.readNet读取它。然而,在读取时,出现了如下错误:

其实是:

于是查看yolov5的代码,在common.py文件的Focus类,torch.cat的输入里有4次切片操作,代码如下:

那么现在需要更换索引式的切片操作,观察到注释的Contract类,它就是用view和permute函数完成切片操作的,于是修改代码如下:
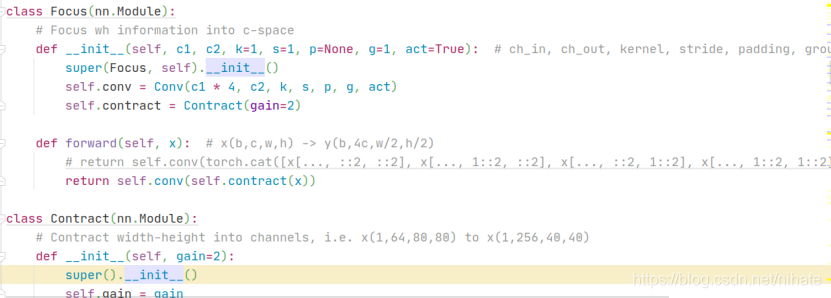
其次,在models\yolo.py里的Detect类里,也有切片操作,代码如下:
- y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i]
- y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
前面说过,Detect类的作用是计算预测框的中心坐标和高宽,生成proposal,这个是属于后处理的,因此不需要把它写入到onnx文件里。
总结一下,按照上面的截图代码,修改Focus类,把Detect类里面的1x1卷积定义在紧邻着Detect类之前的外面,然后去掉Detect类,组成新的model,作为torch.onnx.export的输入:
torch.onnx.export(model, inputs, output_onnx, verbose=False, opset_version=12, input_names=['images'], output_names=['out0', 'out1', 'out2'])最后生成的onnx文件,opencv的dnn模块就能成功读取了,接下来对照Detect类里的forward函数,用python或者C++编写计算预测框的中心坐标和高宽的功能。
在github上,地址是https://github.com/hpc203/yolov5-dnn-cpp-python
四、后处理模块
后处理模块,python版本用numpy array实现的,C++版本的用vector和数组实现的,整套程序只依赖opencv库(opencv4版本以上的)就能正常运行,彻底摆脱对深度学习框架pytorch,tensorflow,caffe,mxnet等等的依赖。用openvino作目标检测,需要把onnx文件转换到.bin和.xml文件,相比于用dnn模块加载onnx文件做目标检测是多了一个步骤的。因此,我就想编写一套用opencv的dnn模块做yolov5目标检测的程序,用opencv的dnn模块做深度学习目标检测,在win10和ubuntu,在cpu和gpu上都能运行,可见dnn模块的通用性更好,很接地气。
生成yolov5s_param.pth 的步骤:
首先下载https://github.com/ultralytics/yolov5的源码到本地,在yolov5-master主目录(注意不是我发布的github代码目录)里新建一个.py文件,把下面的代码复制到.py文件里。
- import torch
- from collections import OrderedDict
- import pickle
- import os
-
- device = 'cuda' if torch.cuda.is_available() else 'cpu'
-
- if __name__=='__main__':
- choices = ['yolov5s', 'yolov5l', 'yolov5m', 'yolov5x']
- modelfile = choices[0]+'.pt'
- utl_model = torch.load(modelfile, map_location=device)
- utl_param = utl_model['model'].model
- torch.save(utl_param.state_dict(), os.path.splitext(modelfile)[0]+'_param.pth')
- own_state = utl_param.state_dict()
- print(len(own_state))
-
- numpy_param = OrderedDict()
- for name in own_state:
- numpy_param[name] = own_state[name].data.cpu().numpy()
- print(len(numpy_param))
- with open(os.path.splitext(modelfile)[0]+'_numpy_param.pkl', 'wb') as fw:
- pickle.dump(numpy_param, fw)

运行这个.py文件,这时候就可以生成yolov5s_param.pth文件。之所以要进行这一步,我在上面讲到过:ultralytics的.pt文件里既存储有模型参数,也存储有网络结构,还储存了一些超参数,包括anchors,stride等等的。torch.load加载ultralytics的官方.pt文件,也就是utl_model = torch.load(modelfile, map_location=device)这行代码,在这行代码后设断点查看utl_model里的内容,截图如下:
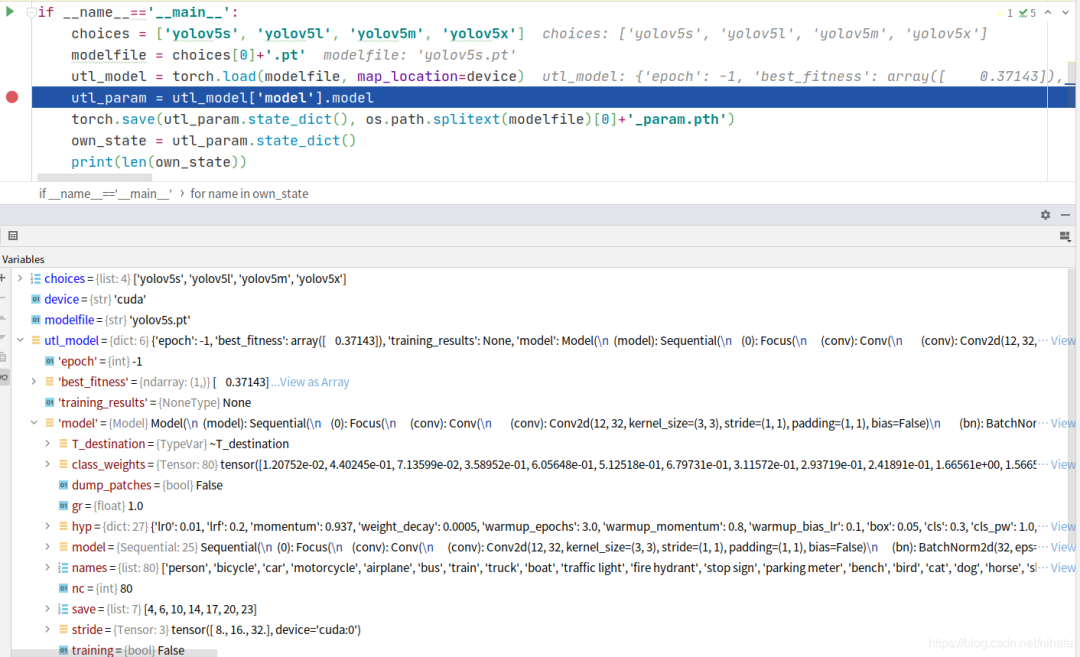
可以看到utl_model里含有既存储有模型参数,也存储有网络结构,还储存了一些超参数等等的,这会严重影响转onnx文件。此外,我还发现,如果pytorch的版本低于1.7,那么在torch.load加载.pt文件时就会出错的。
因此在程序里,我把模型参数转换到cpu.numpy形式的,最后保存在.pkl文件里。这时候在win10系统cpu环境里,即使你的电脑没有安装pytorch,也能通过python程序访问到模型参数。
五、pytorch转onnx常见坑:
onnx只能输出静态图,因此不支持if-else分支。一次只能走一个分支。如果代码中有if-else语句,需要改写。
onnx不支持步长为2的切片。例如a[::2,::2]
onnx不支持对切片对象赋值。例如a[0,:,:,:]=b, 可以用torch.cat改写
onnx里面的resize要求output shape必须为常量。可以用以下代码解决:
- if isinstance(size, torch.Size):
- size = tuple(int(x) for x in size)
此外,在torch.onnx.export(model, inputs, output_onnx)的输入参数model里,应该只包含网络结构,也就是说model里只含有nn.Conv2d, nn.MaxPool2d, nn.BatchNorm2d, F.relu等等的这些算子组件,而不应该含有后处理模块的。图像预处理和后处理模块需要自己使用C++或者Python编程实现。
在明白了这些之后,在转换生成onnx文件,你需要执行两个步骤,第一步把原始训练模型.pt文件里的参数保存到新的.pth文件里,第二步编写yolov5.py文件,把yolov5的往来结构定义在.py文件里,此时需要注意网络结构里不能包含切片对象赋值操作,F.interpolate里的size参数需要加int强制转换。在执行完这两步之后才能生成一个opencv能成功读取并且做前向推理的onnx文件。
不过,最近我发现在yolov5-pytorch程序里,其实可以直接把原始训练模型.pt文件转换生成onnx文件的,而且我在一个yolov5检测人脸+关键点的程序里实验成功了。
© 未完待续
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

