
- 12023年网络安全最新面试题,70多道面试官最常问的问题,建议收藏!_湖南网安基地面试题
- 2使用STM32F103C8T6控制舵机丝滑运转附代码
- 3鸿蒙开发学习——基本组件_鸿蒙 获取app icon
- 4Excel多因素不重复方差分析_无重复双因素方差分析结果怎么看
- 5ThinkPHP 5.1反序列化分析和poc_thinkphp5.1.39poc
- 6Python None(空值)及用法_python中的none
- 7STM32F407ZGT6控制舵机_stm32f407zet6驱动舵机
- 8华为鸿蒙系统将比安卓速度快60,任正非透露华为鸿蒙细节:将比安卓速度快60%!...
- 9MySQL的校对规则设置为 utf8mb4_unicode_ci是干什么的?底层原理是什么?
- 10华为鸿蒙系统老手机能用吗_华为鸿蒙操作系统展望:老机型和友商手机或都能用上!...
Java线上服务CPU、内存飙升问题排查步骤!_java cpu过高排查
赞
踩

01 引言
作为一名从事Java开发快一年的程序员,在线上经常碰到某个模块的Pod发出CPU与内存告警的问题,而这些问题会导致系统响应缓慢甚至是服务不可用。一般情况下可以通过重启或者调高Pod的资源量或者增加Pod数量暂时解决问题,但这是治标不治本的,只有找到问题发生的原因才能从根本上解决问题。那么在该如何快速定位到导致告警的原因呢?下面将汇总一下大致的处理思路。
一般来说导致Java程序CPU与内存冲高的原因有两种:
-
代码中某个位置读取数据量较大,导致系统内存耗尽,从而导致Full GC次数过多,系统缓慢。
-
代码中有比较耗CPU的操作,导致CPU过高,系统运行缓慢。
-
代码某个位置有阻塞性的操作,导致该功能调用整体比较耗时,但出现是比较随机的;
-
某个线程由于某种原因而进入WAITING状态,此时该功能整体不可用,但是无法复现;
-
由于锁使用不当,导致多个线程进入死锁状态,从而导致系统整体比较缓慢。
前两种情况出现的频率较高,可能会导致系统不可用,后三种会导致某个功能运行缓慢,但是不至于导致系统不可用。
对于第一种情况,本人曾经遇到过某个查全量数据的接口在某段时间被频繁调用导致内存耗尽、疯狂GC的情况:记一次GC导致的CPU与内存冲高的问题解决。下面将总结一些具体的排查步骤。
02 分析工具
01 top命令查看CPU占用情况
PID为进程编号,COMMAND为其中执行命令,java即为要找的应用
-
top: 展示所有进程占用情况
-
top -N num: 展示CPU占用最高的num个进程
- root@8d36124607a0:/# top
-
- top - 14:01:23 up 1 day, 17:54, 1 user, load average: 0.00, 0.01, 0.05Tasks: 101 total, 1 running, 100 sleeping, 0 stopped, 0 zombie%Cpu(s): 0.8 us, 1.2 sy, 0.0 ni, 98.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 3782864 total, 1477524 free, 329656 used, 1975684 buff/cacheKiB Swap: 0 total, 0 free, 0 used. 3181392 avail Mem
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 9 root 20 0 1031064 52580 19248 S 90.3 10.4 26:30.37 javacatalina.sh
- root@8d36124607a0:/# top -Hp 9
-
- top - 08:31:16 up 30 min, 0 users, load average: 0.75, 0.59, 0.35Threads: 11 total, 1 running, 10 sleeping, 0 stopped, 0 zombie%Cpu(s): 3.5 us, 0.6 sy, 0.0 ni, 95.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem: 2046460 total, 1924856 used, 121604 free, 14396 buffersKiB Swap: 1048572 total, 0 used, 1048572 free. 1192532 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 10 root 20 0 2557160 289824 15872 R 79.3 14.2 0:41.49 java
- 11 root 20 0 2557160 289824 15872 S 1.2 14.2 0:06.78 java
可以看到占用CPU消耗最高的PID为10,该ID即为线程ID,使用如下命令将其转化为16进制格式:
root@8d36124607a0:/# printf "%x\n" 10得到输出a线程即为0xa。
02 用jstack查看Java线程信息
-
jstack 进程号 | grep 线程ID:查看线程堆栈信息,将上一步骤的Java线程进程ID与CPU占用量较高的线程ID(16进制格式)填入其中。
-
jstack pid >> stack.txt:将今后曾所有堆栈信息都打印到stack.txt中
- root@8d36124607a0:/# jstack 9 | grep 0xa
-
- "VM Thread" os_prio=0 tid=0x00007f871806e000 nid=0xa runnable”
第一个双引号圈起来的就是线程名,如果是“VM Thread”这就是虚拟机GC回收线程,如果是"main"则是其他线程,后面的runnable是线程状态。
03 使用jstat查看GC信息
-
jstat -gcutil 进程号 统计间隔毫秒 统计次数(缺省代表一直统计)
- root@8d36124607a0:/# jstat -gcutil 9 1000 10
-
- S0 S1 E O M CCS YGC YGCT FGC FGCT GCT 0.00 0.00 0.00 75.07 59.09 59.60 3259 0.919 6517 7.715 8.635
- 0.00 0.00 0.00 0.08 59.09 59.60 3306 0.930 6611 7.822 8.752
- 0.00 0.00 0.00 0.08 59.09 59.60 3351 0.943 6701 7.924 8.867
- 0.00 0.00 0.00 0.08 59.09 59.60 3397 0.955 6793 8.029 8.984
查看某进程GC持续变化情况,如果发现返回中FGC很大且一直增大,确认为Full GC! 也可以使用“jmap -heap 进程ID”查看一下进程的堆内从是不是要溢出了,特别是老年代内从使用情况一般是达到阈值(具体看垃圾回收器和启动时配置的阈值)就会进程Full GC。
04 使用Jmap分析内存
-
jmap -dump:format=b,file=文件名称 进程ID :
生成内存dump文件,进行离线分析。
-
dump文件界面分析工具:
IBM HeapAnalyzer,点击进入找到ha457.jar的下载链接进行下载
-
java -Xmx4G -jar ha457.jar:
运行jar文件,如果dump文件过大可以使用-Xmx设置最大堆内存大小,防止内存溢出。
通过ha457.jar的GUI界面可以很清晰的看到各种类型的数据内存占用情况、对象之间的引用关系以及可能存在内存泄漏的对象。
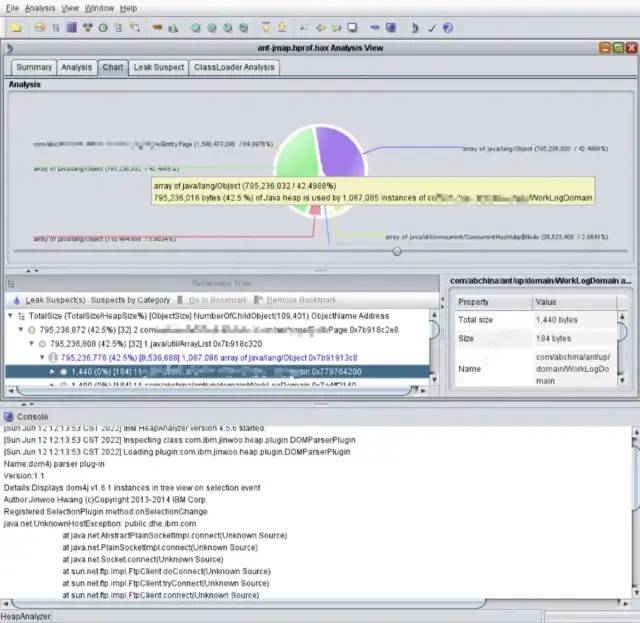
03 原因分析
01 Full GC次数过多
相对来说,这种情况是最容易出现的,尤其是新功能上线时。对于Full GC较多的情况,其主要有如下两个特征:
-
线上多个线程的CPU都超过了100%,通过jstack命令可以看到这些线程主要是垃圾回收线程
-
通过jstat命令监控GC情况,可以看到Full GC次数非常多,并且次数在不断增加。
初步排查:使用top与top -Hp命令找到CPU占用最高的Java线程,将其转为16进制后,使用jstack命令抓取该线程信息,发现线程名称是"VM Thread"垃圾回收线程。
进一步确认: 使用jstat -gcutil命令查看gc次数与增长情况。
进一步分析:使用jmap -dump命令dump内存,然后使用使用ha457.jar离线分析。
-
生成大量的对象,导致内存溢出
-
内存占用不高,但是Full GC次数还是比较多,此时可能是代码中手动调用 System.gc()导致GC次数过多。
02 某个业务逻辑执行时间过长
如果是Full GC次数过多,那么通过 jstack得到的线程信息会是类似于VM Thread之类的线程,而如果是代码中有比较耗时的计算,那么我们得到的就是一个线程的具体堆栈信息。
如下是一个代码中有比较耗时的计算,导致CPU过高的线程信息:

这里可以看到,在请求UserController的时候,由于该Controller进行了一个比较耗时的调用,导致该线程的CPU一直处于100%。
我们可以根据堆栈信息,直接定位到UserController的34行,查看代码中具体是什么原因导致计算量如此之高。
03 死锁
如果有死锁,会直接提示。关键字:deadlock。使用jstack打印线程信息会打印出业务死锁的位置。
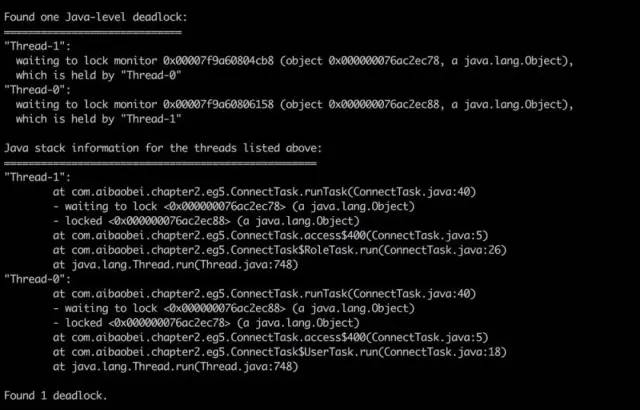
04 线程一直处于WAITTING状态
对于这种情况,这是比较罕见的一种情况,但是也是有可能出现的,而且由于其具有一定的 “不可复现性”,因在排查的时候是非常难以发现的。
某个线程由于某种原因而进入WAITING状态,此时该功能整体不可用,但是无法复现。jstack多查询几次,每次间隔30秒,对比一直停留在parking 导致的WAITING状态的线程。
可以通过给线程命名快速定位到是哪个业务代码。
05 随机出现大量线程访问接口缓慢
对于这种情况,比较典型的例子就是,我们某个接口访问经常需要2~3s才能返回。
这是比较麻烦的一种情况,因为一般来说,其消耗的CPU不多,而且占用的内存也不高,也就是说,我们通过上述两种方式进行排查是无法解决这种问题的。
而且由于这样的接口耗时比较大的问题是不定时出现的,这就导致了我们在通过 jstack命令即使得到了线程访问的堆栈信息,我们也没法判断具体哪个线程是正在执行比较耗时操作的线程。
对于不定时出现的接口耗时比较严重的问题,我们的定位思路基本如下:
首先找到该接口,通过压测工具不断加大访问力度,如果说该接口中有某个位置是比较耗时的,由于我们的访问的频率非常高,那么大多数的线程最终都将阻塞于该阻塞点
这样通过多个线程具有相同的堆栈日志,我们基本上就可以定位到该接口中比较耗时的代码的位置。
如下是一个代码中有比较耗时的阻塞操作通过压测工具得到的线程堆栈日志:

从上面的日志可以看你出,这里有多个线程都阻塞在了UserController的第18行,说明这是一个阻塞点,也就是导致该接口比较缓慢的原因。
04 总结
1、排查命令总结
-
top:
查看系统进程CPU与内存占用情况,找到占用最多的进程ID
-
top -Hp 进程号:
查看该进程号的所有线程CPU与内存占用情况,找到占用最多的线程ID(显示的PID即为10进制线程编号,printf "%x\n" 进程号转为16进制线程号)
-
jstack 进程号 >> stack.txt:
将进程号所属进程的堆栈信息输出到stack.txt中
-
jstack 进程号 | grep 16进制线程号:
查看进程号先所属线程的堆栈信息,可查看线程名,区分出普通线程与GC线程("VM Thread")。
-
jstat -gcutil 进程号 统计间隔毫秒 统计次数(缺省代表一直统计):
如果是因为GC问题,进一步观察GC情况
-
jmap -heap 进程ID:
查看详细进程内存使用信息
-
jmap -dump:format=b,file=文件名称 进程ID:
将进程内存信息dump到磁盘上供进一步分析。
-
java -Xmx4G -jar ha457.jar:
使用ha457.jar来分析内存泄漏情况。
2、异常情况解决总结
-
GC问题:
top+top -Hp + jstack排查是"VM Thread"消耗过多资源,可以进一步使用jmap工具进行内存溢出排查。
-
业务执行过慢问题:
top+top -Hp + jstack排查发现是普通业务线程,可看到具体是哪个接口。
-
死锁:
jstack + Java进程打印堆栈信息中包含死锁信息deadlock
-
线程处于waiting状态:
多打印几次jstack信息,对比一直停留在waiting状态的线程。
最后:下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

整套资料获取


