
热门标签
热门文章
- 1AI 切入社交,是一门好生意吗?
- 2Ubuntu本地安装code-server结合内网穿透实现安卓平板远程写代码_ubantu部署code server
- 3工具系列 | 基于元模型的访问控制策略描述语言
- 4mac安全干净卸载Anaconda3
- 5android 详解画图,Android入门之画图详解
- 6利用pyinstaller打包Python的PyQt5程序并加载icon和图片_python加载打包的图片
- 7Jersey框架简单实践(一)
- 8python,Pyqt5 实现FTP服务器与客户端文件上传,下载_pyqt5 ftp
- 9mpi4py 中的组管理 API_python mpi4py api
- 10上海亚商投顾:沪指逼近2900点 两市超4500股飘绿
当前位置: article > 正文
分组密码简介和五大分组模式_sm4 ctr模式
作者:Monodyee | 2024-03-12 22:55:54
赞
踩
sm4 ctr模式
分组密码
分组密码(blockcipher)是每次只能处理特定长度的一块数据的一类密码算法,这里的一块"就称为分组(block)。
此外,一个分组的比特数就称为分组长度(blocklength)。
例如,SM4的分组长度是128比特。这些密码算法一次只能加密128比特的明文.并生成128比特的密文。
- 1
- 2
- 3
- 4
- 5
模式
分组密码算法只能加密固定长度的分组,但是我们需要加密的明文长度可能会超过分组密码的分组长度,这时就需要对分组密码算法进行迭代,以便将一段很长的明文全部加密。
而迭代的方法就称为分组密码的模式(mode),分组密码的主要模式有以下5种:
ECB模式:Electronic Code Book mode(电子密码本模式:不推荐)
CBC模式:Cipher Block Chaining mode(密码分组链接模式)
CFB模式:Cipher FeedBack mode(密文反馈模式)
OFB模式:Output FeedBack mode(输出反馈模式)
CTR模式:CounTeR mode(计数器模式)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
ECB 模式
ECB(Electronic Code Book, 电子密码本)模式是最简单的加密模式,明文消息被分成固定大小的块(分组),并且每个块被单独加密。
每个块的加密和解密都是独立的,且使用相同的方法进行加密,所以可以进行并行计算,但是这种方法一旦有一个块被破解,使用相同的方法可以解密所有的明文数据,安全性比较差。
K:密钥; C:密文; P:明文
适用于数据较少的情形,加密前需要把明文数据填充到块大小的整倍数。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
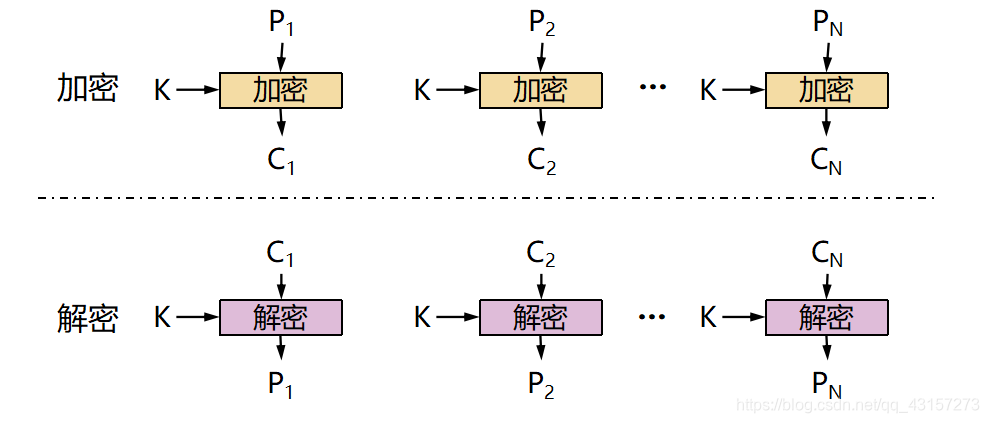
使用ECB模式加密时,相同的明文分组会被转换为相同的密文分组,也就是说,我们可以将其理解为是一个巨大的“明文分组-->密文分组"的对应表,因此ECB模式也称为电子密码本模式当最后一个明文分组的内容小于分组长度时,需要用一特定的数据进行填充(padding),让值一个分组长度等于分组长度。
ECB模式是所有模式中最简单的一种。ECB模式中,明文分组与密文分组是一一对应的关系,因此,如果明文中存在多个相同的明文分组,则这些明文分组最终都将被转换为相同的密文分组。这样一来,只要观察一下密文,就可以知道明文中存在怎样的重复组合,并可以以此为线索来破译密码,因此ECB模式是存在一定风险的。
- 1
- 2
- 3
CBC模式
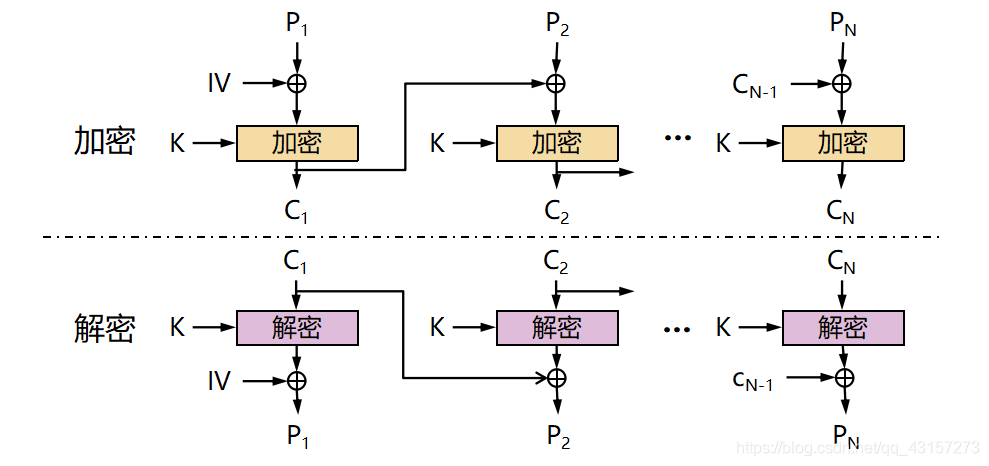
CBC(Cipher Block Chaining, 密码块链)模式中每一个分组要先和前一个分组加密后的数据进行XOR异或操作,然后再进行加密。
这样每个密文块依赖该块之前的所有明文块,为了保持每条消息都具有唯一性,第一个数据块进行加密之前需要用初始化向量IV进行异或操作。
IV:初始化向量; K:密钥; C:密文; P:明文
CBC模式是一种最常用的加密模式,它主要缺点是加密是连续的,不能并行处理,并且与ECB一样消息块必须填充到块大小的整倍数。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
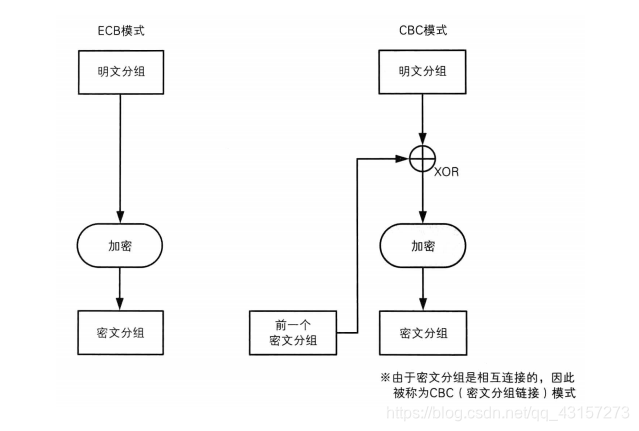
如果将一个分组的加密过程分离出来,我们就可以很容易地比较出ECB模式和CBC模式的区别 。
ECB模式只进行了加密,而CBC模式则在加密之前进行了一次XOR。
- 1
- 2
- 3
-
初始化向量
当加密第一个明文分组时,由于不存在“前一个密文分组",因此需要事先准备一个长度为一个分组的比特序列来代替“前一个密文分组",这个比特序列称为初始化向量(initialization vector) 通常缩写为 IV 一般来说,每次加密时都会随机产生一个不同的比特序列来作为初始化向量。 明文分组在加密之前一定会与“前一个密文分组"进行 XOR 运算,因此即便明文分组1和2的值是相等的,密文分组1和2的值也不一定是相等的。这样一来,ECB模式的缺陷在CBC模式中就不存在了。- 1
- 2
- 3
- 4
- 5
CFB 模式
CFB模式的全称是Cipher FeedBack模式(密文反馈模式)。在CFB模式中,前一个分组的密文加密后和当前分组的明文XOR异或操作生成当前分组的密文。
所谓反馈,这里指的就是返回输人端的意思,即前一个密文分组会被送回到密码算法的输入端。
IV:初始化向量; K:密钥; C:密文; P:明文
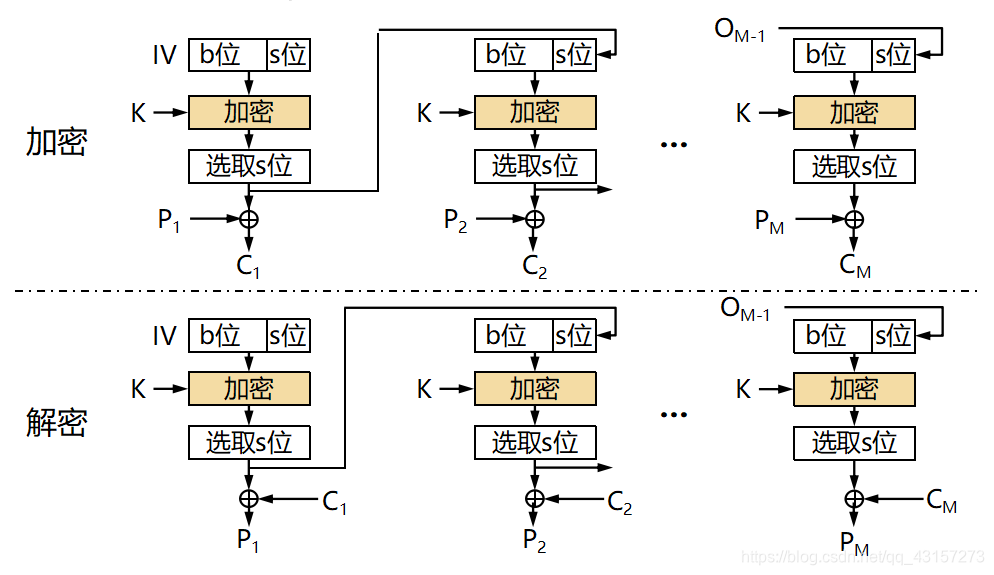
s位:明文,反馈位数,取1、8、64、128 记为CFB-1,CFB-8,CFB-64,CFB-128; b位:移位寄存器值
CFB模式的解密和CBC模式的加密在流程上其实是非常相似的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
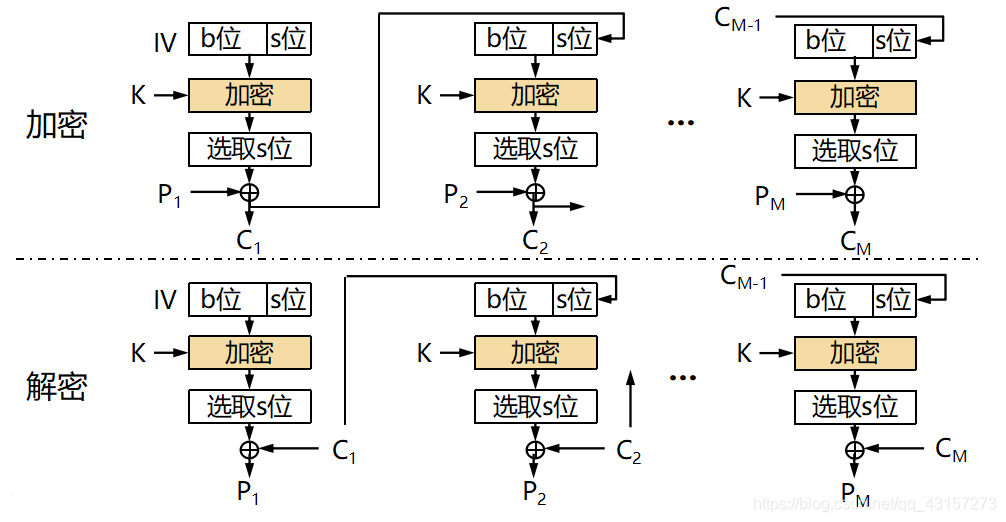
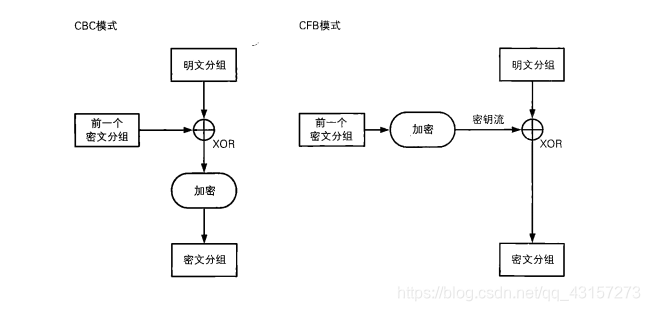
在ECB模式和CBC模式中,明文分组都是通过密码算法进行加密的,然而,在CFB模式中,明文分组并没有通过密码算法来直接进行加密。
从上图可以看出,明文分组和密文分组之间并没有经过"加密"这一步骤。在CFB模式中,明文分和密文分组之间只有一个XOR。
我们将CBC模式与CFB模式对比一下,就可以看出其中的差异了(如下图)。在CBC模式中,明文分组和密文分组之间有XOR和密码算法两个步骤,而在CFB模式中,明文分组和密文分组之间则只有XOR。
- 1
- 2
- 3
- 4
- 5
-
初始化向量
在生成第一个密文分组时,由于不存在前一个输出的数据,因此需要使用初始化向量(IV)来代替,这一点和CBC模式是相同的。 一般来说,我们需要在每次加密时生成一个不同的随机比特序列用作初始化向量。- 1
- 2
- 3
-
CFB模式与流密码
CFB模式是通过将“明文分组”与“密码算法的输出"进行XOR运算来生成“密文分组”的。 在CFB模式中,密码算法的输出相当于一个随机比特序列。由于密码算法的输出是通过计算得到的,并不是真正的随机数,因此CFB模式不可能具各理论上不可破译的性质。 CFB模式中由密算法所生成的比特序列称为密钥流(key stream)。在CFB模式中,密码算法就相当于用来生成密钥流的伪随机数生成器,而初始化向量相当于伪随机数生成器的“种子“。 在CFB模式中,明文数据可以被逐比特加密,因此我们可以将CFB模式看做是一种使用分组密码来实现流密码的方式。- 1
- 2
- 3
- 4
- 5
- 6
- 7
OFB 模式
OFB式的全称是Output-Feedback模式(输出反馈模式)。在OFB模式中,密码算法的输出会反馈到密码算法的输入中, 即上一个分组密码算法的输出是当前分组密码算法的输入(下图)。
IV:初始化向量; K:密钥; C:密文; P:明文
s位:明文,反馈位数,随机序列; b位:移位寄存器值
OFB模式并不是通过密码算法对明文直接进行加密的,而是通过将 “明文分组" 和 “密码算法的输出” 进行XOR来产生 “密文分组” 的,在这一点上OFB模式和CFB模式非常相似。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
初始化向量
和CBC模式、CFB模式一样,OFB模式中也需要使用初始化向量(IV)。一般来说,我们需要在每次加密时生成一个不同的随机比特序列用作初始化向量。- 1
-
CFB模式和OFB模式对比
OFB模式和CFB模式的区别仅仅在于密码算法的输入。 CFB式中,密码算法的输人是前一个密文分组,也就是将密文分组反馈到密算法中,因此就有了“密文反馈模式”这个名字。 相对地,OFB模式中,密码算法的输入则是密码算法的前一个输出,也就是将输出反馈给密码算法,因此就有了“输出反馈模式"这个名字。 如果将一个分组抽出来对CFB模式和OFB模式进行一个对比.就可以很容易看出它们之间的差异(下图)。- 1
- 2
- 3
- 4
- 5
- 6
- 7
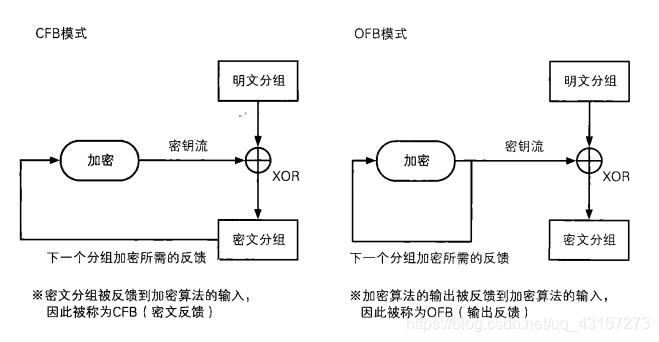
由于CFB模式中是对密文分组进行反馈的,因此必须从第一个明文分组开始按顺序进行加密,也就是说无法跳过明文分组1而先对明文分组2进行加密。
相对地,在OFB模式中,XOR所需要的比特序列(密钥流)可以事先通过密码算法生成,和明文分组无关。
只要提前准备好所需的密钥流,则在实际从明文生成密文的过程中,就完全不需要动用密码算法了。只要将明文与密钥流进行XOR就可以了。
和AES等密码算法相比,XOR运算的速度是非常快的。这就意味着只要提前准备好密钥流就可以快速完成加密。
换个角度来看,生成密钥流的操作和进行XOR运算的操作是可以并行的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
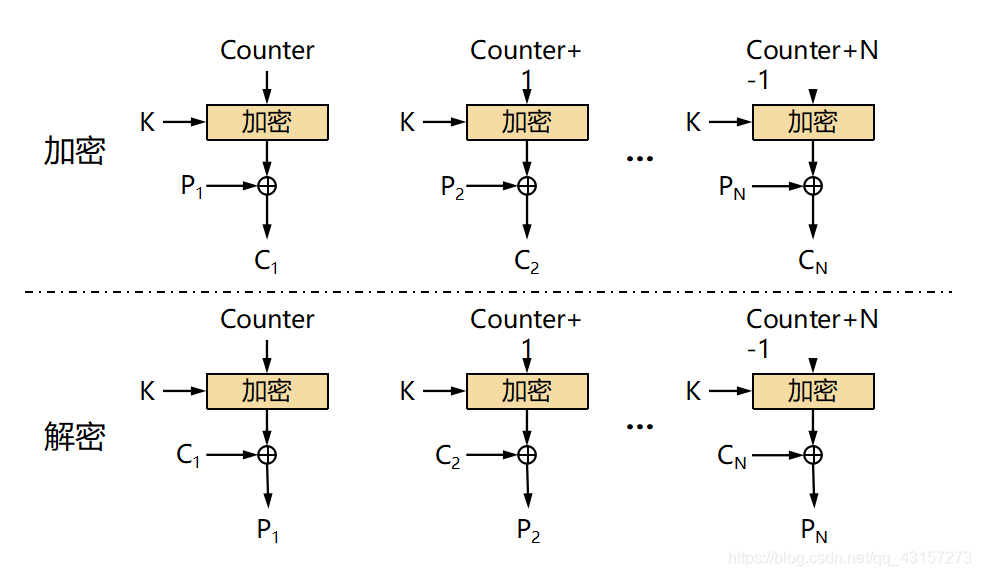
CTR 模式
CTR模式的全称是CounTeR模式(计数器模式)。CTR摸式是一种通过将逐次累加的计数器进行加密来生成密钥流的流密码(下图)。
Counter:计数器; K:密钥; C:密文; P:明文
CTR模式中,每个分组对应一个逐次累加的计数器,并通过对计数器进行加密来生成密钥流。
也就是说,最终的密文分组是通过将计数器加密得到的比特序列,与明文分组进行XOR而得到的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
计数器的生成方法
每次加密时都会生成一个不同的值(nonce)来作为计数器的初始值。 当分组长度为128比特(16字节)时,计数器的初始值可能是像下面这样的形式。- 1
- 2
- 3

其中前8个字节为nonce(随机数),这个值在每次加密时必须都是不同的,后8个字节为分组序号,这个部分是会逐次累加的。在加密的过程中,计数器的值会产生如下变化:

按照上述生成方法,可以保证计数器的值每次都不同。由于计数器的值每次都不同,因此每个分组中将计数器进行加密所得到的密钥流也是不同的。也是说,这种方法就是用分组密码来模拟生成随机的比特序列。
-
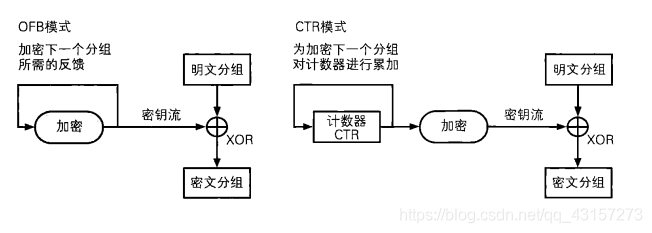
OFB模式与CTR模式对比
CTR模式和OFB模式一样,都属于流密码。 如果我们将单个分组的加密过程拿出来,那么OFB模式和CTR模式之间的差异还是很容易理解的(下图)。 OFB模式是将加密的输出反愦到输入,而CTR模式则是将计数器的值用作输入。- 1
- 2
- 3
- 4
- 5
-
CTR模式的特点
CTR模式的加密和解密使用了完全相同的结构,因此在程序实现上比较容易。这一特点和同为流密码的OFB模式是一样的。 此外,CTR模式中可以以任意顺序对分组进行加密和解密,因此在加密和解密时需要用到的“计数器"的值可以由nonce和分组序号直接计算出来。这一性质是OFB模式所不具备的。 能够以任意顺序处理分组,就意味着能够实现并行计算。在支持并行计算的系统中,CTR模式的速度是非常快的。- 1
- 2
- 3
- 4
- 5
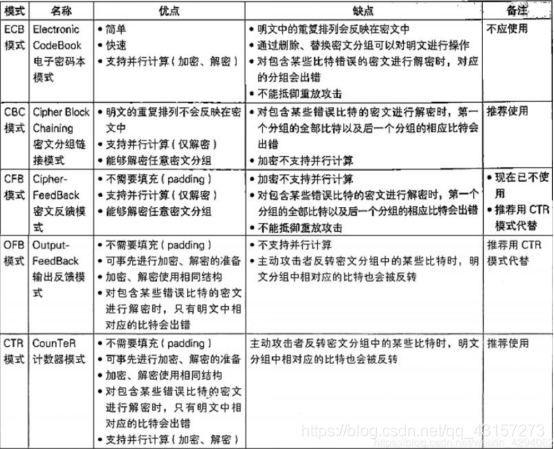
总结
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

