
- 1奶茶点餐|奶茶店自助点餐系统|基于微信小程序的饮品点单系统的设计与实现(源码+数据库+文档)_奶茶店微信小程序的源代码运行结果图片
- 2最炙手可热的行业——大数据就业方向和学习路线图详解!_数据科学与大数据技术 就业拓扑图
- 3记录一下Android Studio设置模拟器的安装位置_mac android studio 查看模拟器路径
- 4PyTorch搭建LeNet训练集详细实现
- 5内网搭建Ubuntu(银河麒麟)的apt本地源服务器_银河麒麟配置本地apt源
- 6平衡搜索二叉树之红黑树(拒绝死记硬背,拥抱理解记忆)_java 平衡二叉树 红黑树
- 7人脸识别之人脸对齐(一)--定义及作用
- 8设计一个聊天系统200问?
- 9烤仔TVのCCW丨密码学通识(四)选择密文攻击
- 10Promise详解
目标检测——SSD算法解读
赞
踩
论文:SSD: Single Shot MultiBox Detector
作者:Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg
链接:https://arxiv.org/abs/1512.02325
代码:https://github.com/weiliu89/caffe/tree/ssd
1、算法概述
SSD算法是作者Wei Liu在ECCV 2016上发表的论文。该算法是一个端到端的网络,通过在每个特征图位置上设置不同长宽比和尺度比例的默认框(default box),然后对每个默认框形成预测分数来得到最后的预测结果。对于输入尺寸300x300的网络使用Nvidia Titan x在VOC 2007测试集上达到74.3%mAP以及59FPS,对于512x512的网络,达到了76.9%mAP超越当时最强的Faster RCNN(73.2%mAP)。相对YOLO算法,它使用了较小的卷积核来预测目标类别和bounding box的偏置;最大的改进就是用了多个特征图进行不同尺度的预测,使得在相对较低的分辨率输入情况下实现高精度,进一步提高检测速度。在PASCAL VOC数据集上,从YOLO的63.4%mAP提升到了SSD的74.3%mAP。
2、SSD细节
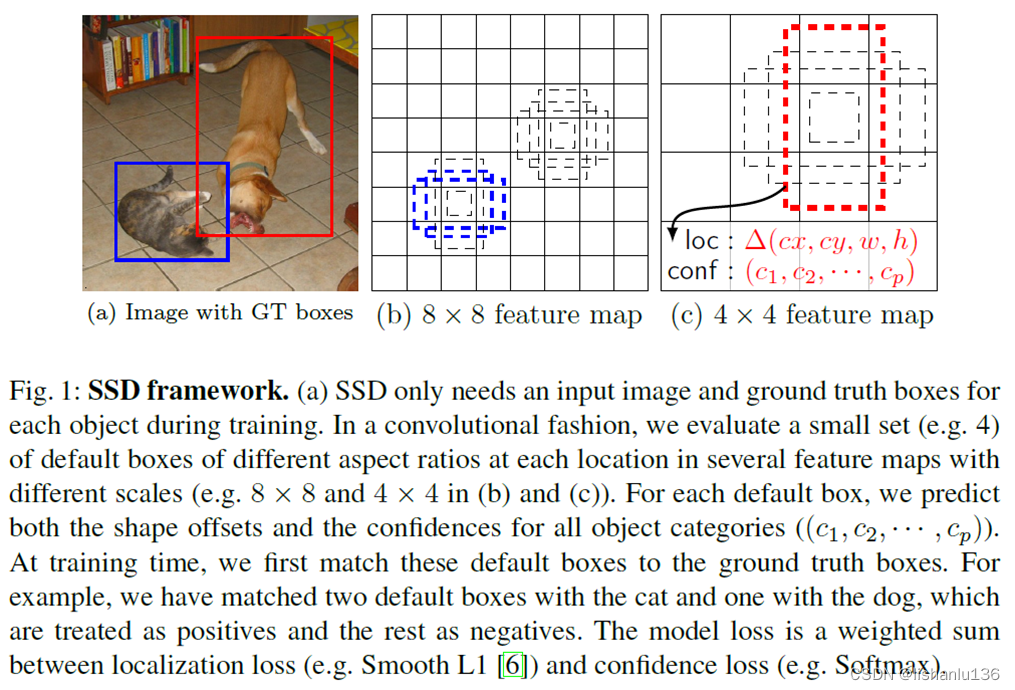
如上图所示,SSD算法在特征图上每个位置设置4个默认框,每个默认框预测每个类别对应的分数和矩形框偏移量;在训练阶段,会先拿默认框和ground truth boxes做匹配,比如上图中猫会匹配到两个默认框,狗目标稍微大一点,会在4x4大小的特征图上匹配到1个默认框。这就达到了用不同尺度特征图去预测不同尺度大小的目标的效果。匹配到的默认框被视为正样本,剩余默认框视为负样本。损失函数是定位损失(Smooth L1)和置信度损失(Softmax)权重相加。
2.1 模型设计
SSD方法是基于前馈卷积网络,该网络会生成固定数量的默认框集合和这些框中存在的目标类实例的分数预测,然后通过非极大值抑制操作得到最终检测结果。SSD基于经典的VGG16分类网络做为base network,然后对其作出改进。
Multi-scale feature maps for detection:相比于Overfeat和YOLO算法,SSD用多个特征图做预测
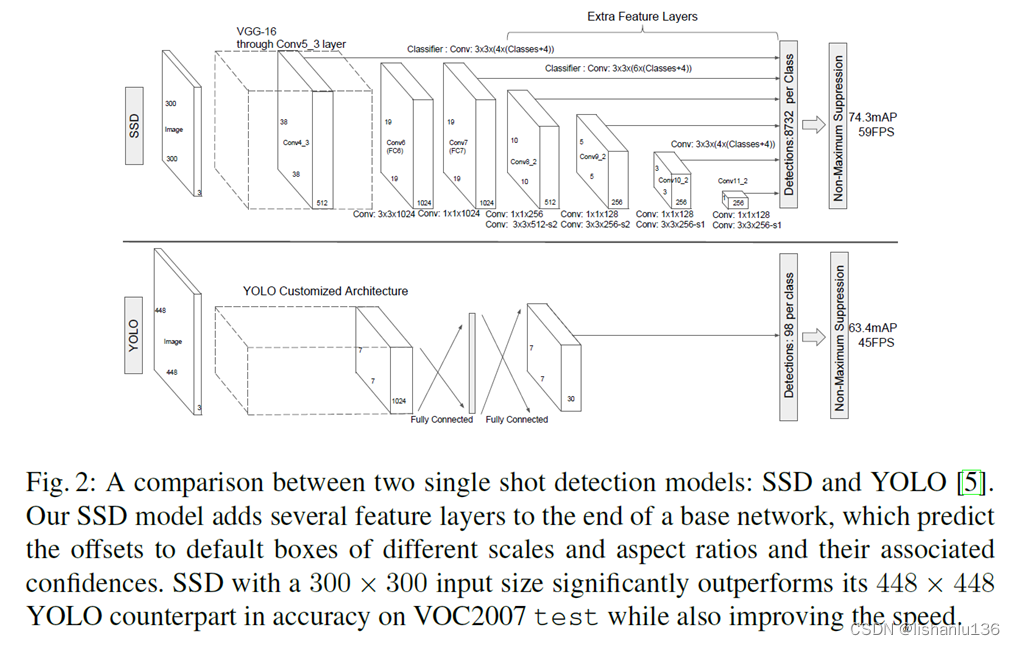
Convolutional predictors for detection:每一层特征图上使用一组卷积滤波器产生一组固定的检测预测。对于有p个通道的mxn特征图,会用3x3xp的小卷积核生成预测结果,而之前的YOLO用的是全连接层得到的预测结果。SSD与YOLO结构对比如下图所示:
Default boxes and aspect ratios:SSD会在每个特征图上的每个位置单元上设置固定数量的默认框,在每个特征图的位置单元中,将预测相对于单元中默认框形状的偏移量以及每个类的分数,这些分数表明每个框中存在一个类实例的概率大小。比如,在某个特征图f的位置(i,j)处,设置了k个默认框,每个默认框将预测c个类别分数以及相对于该默认框的4个坐标偏移量。则可以得到该特征图f的位置(i,j)将对应(c+4)k个输出结果,如果特征图f的大小为mxn,则输出预测结果为(c+4)kmn。这里的默认框(default boxes)类似于Faster R-CNN的anchor boxes,只是这个设置会应用到多个特征图,而且每个特征图上的设置数量会有差别。
2.2 训练阶段
训练过程,主要是默认框与ground truth boxes的匹配策略,以及如何设置检测的默认框和尺度集,硬负挖掘和数据增强策略。
Matching strategy
在训练过程中,我们需要确定哪些默认框对应于ground truth boxes是正样本,参与到检测器的训练。匹配过程为:首先将每个ground truth box和默认框匹配,取iou最高的默认框;然后将剩余默认框与任何一个ground truth box的iou大于0.5的默认框也定义为正样本。这一步操作进一步增加了正样本数量。
Training objective
总的损失由边界框定位损失和类别置信度损失权重相加得到;形式如下:
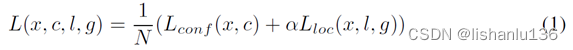
其中N代表匹配到的默认框数量,如果N=0,代表一个都没匹配到,这时损失就为0。定位损失采用Smooth L1,其形式如下:

其中l代表预测框,g代表真实标签,像Faster R-CNN一样,定位损失学习基于默认框(d)中心(cx,cy)及宽高(w,h)的偏置。置信度损失采用softmax,形式如下:
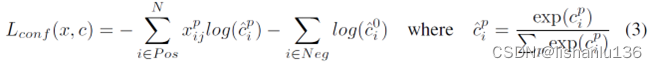
Choosing scales and aspect ratios for default boxes
针对不同尺度的目标,之前方法是将图片按不同尺度缩放然后合并所有的检测结果,本文利用同一个网络中不同层的特征图也能达到相似的效果;之前的研究表明,网络中较低的层可以提高语义分割质量,因为较低层可以捕获输入对象更精细的细节特征,而在特征图后加入全局上下文池化操作可以得到平滑的分割结果;所有本文得到启发,同时利用低层和高层的特征图完成检测任务。由于不同大小的特征图具有不同大小的感受野,所有能实现针对性检测某个尺度下的目标。每个特征图的默认框尺度设置规则如下:
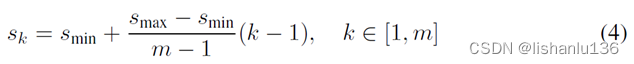
其中smin为0.2,smax为0.9,k代表特征层下标,k=1为最低层,可见最低层特征图默认框尺度为0.2,最高层特征图默认框尺度为0.9,每个默认框设置不同的宽高比为aγ∈{1,2,3,1/2,1/3},每个默认框的宽高可通过aγ与sk就算得到wka=sk
a
γ
\sqrt{a~γ~}
a γ
,hka=sk/
a
γ
\sqrt{a~γ~}
a γ
,在实际情况中,也可以针对特定的数据集来设计一个默认框的分布,以求得到默认框能更好的匹配真实标注框。
Hard negative mining
在默认框匹配真实标注框之后,我们会得到很多的被标记为负样本的默认框,这会导致正负样本不平衡的问题,SSD将这些负样本按置信度损失从大到小进行排序,然后从前面开始取正样本3倍数量的负样本参与训练。通过这样的难样本挖掘,会加速收敛,也会使得训练更稳定。
Data augmentation
完整图片加patch采样以及水平翻转、颜色抖动等
3、实验结果
3.1 PASCAL VOC2007
作者在PASCAL VOC2007测试集上和Fast R-CNN、Faster R-CNN对比结果如下:

3.2 模型分析
作者做了实验对SSD300进行增减优化策略分析,实验结果如下:

从实验可以看出:
1、数据增强对SSD300提升很大,能带来8.8%mAP的提升效果;
2、更多的默认框形状能带来精度的提升;
3、不同分辨率下的多个输出层效果更好。
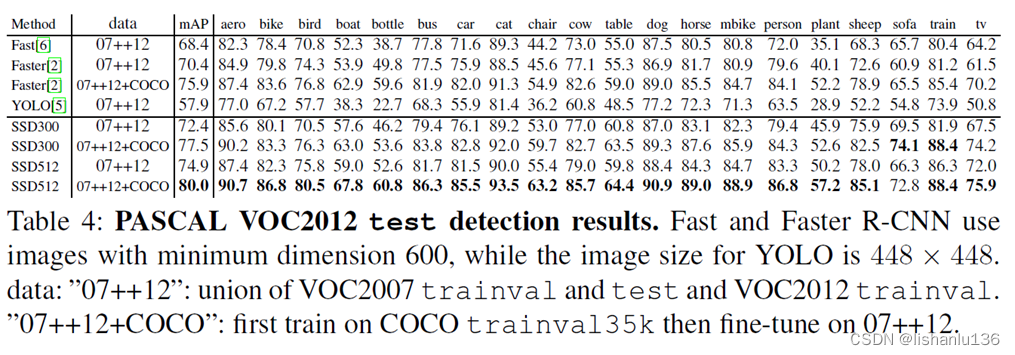
3.3 PASCAL VOC2012
作者在PASCAL VOC2012测试集上和Faster R-CNN、YOLO对比情况如下:
3.4 COCO
在COCO测试集上的比对结果如下:

3.5 推理速度
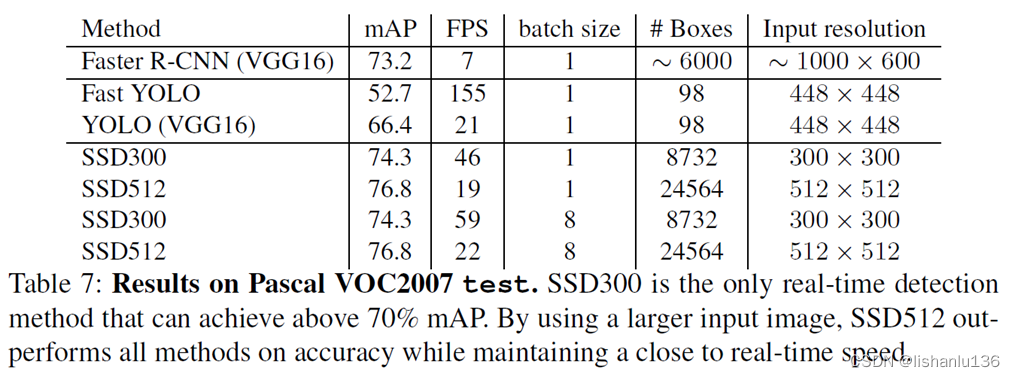
可见SSD300是既能达到实时的标准同时又能达到70%mAP以上的算法。
4、创新点和不足
创新点:
1、同时结合多个尺度的特征图对图像做目标检测,使得不同特征图可以负责不同尺度大小的目标,分而治之,各司其职,能提高检测的召回率,减少漏检。
2、最后检测头用小卷积核通过卷积操作得到最终的检测结果,保留了目标的空间特征。
不足:
1、主干网络提取特征能力不足。

