
- 1GIT 卸载干净(图文详解)_git 卸载不干净
- 2QFileDevice、QFile、QSaveFile、QTemporaryFile
- 3华为设备密码认证模式_华为交换机cipher加密方式
- 4基于MongoDB权限管理+gridfs文件上传------云盘系统
- 5Python常见问题 Ubuntu_Pycharm_运行报错:no model named tk | 九七的Python常见问题集锦_no module named 'tk
- 6pytorch Runtime Error:cuda runtime error(2):out of memory at /……/torch/…….cu:58解决办法_runtimeerror: cuda runtime error (2) : out of memo
- 7TabLayout+ViewPager+Fragment完成滑动界面_deprecated use tablayout and viewpager instead
- 8MySQL是什么?它有什么优势?_云数据库mysql有什么具体优势
- 9企业计算机服务器中了mkp勒索病毒如何解密,mkp勒索病毒解密流程
- 10网络分析 之 浏览器访问网站的通信过程_浏览器网络网站 访问连通
数据结构入门_学数据结构需要的基础
赞
踩
一、数据结构入门
1.数据结构基础
基本概念和术语
1)数据
数据(Data)是信息的载体,是可以被计算机识别,存储并加工处理的描述客观事物的信息符号的总称。数据不仅仅包括了整形,浮点数等数值类型,还包括了字符甚至声音,视频,图像等非数值的类型。
2)数据元素
数据元素(Data Element)是描述数据的基本单位,也被称为记录。一个数据元素有若干个数据项组成。
如禽类,鸡鸭都属于禽类的数据元素。
3)数据项
数据项(Data Item)是描述数据的最小单位,其可以分为组合项和原子项:
a)组合项
如果数据元素可以再度分割,则每一个独立处理单元就是数据项,数据元素就是数据项的集合。
b)原子项
如果数据元素不能再度分割,则每一个独立处理的单元就是原子项。
如日期2019年4月25日就是一个组合项,其表示日期,但如果单独拿25日这个数据出来观测,这就是一个原子项,因为其不可以再分割。
4)数据对象
数据对象(Data Object)是性质相同的一类数据元素的集合,是数据的一个子集。数据对象可以是有限的,也可以是无限的。
5)数据结构
数据结构(Data Structures)主要是指数据和关系的集合,数据指的是计算机中需要处理的数据,而关系指的是这些数据相关的前后逻辑,这些逻辑与计算机储存的位置无关,其主要包含以下四大逻辑结构。
- 四大逻辑结构(Logic Structure)
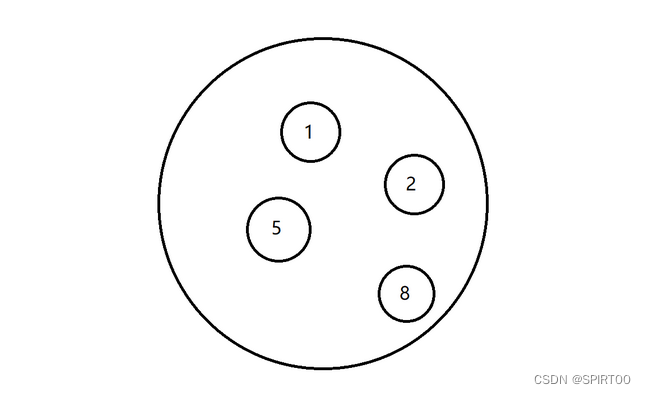
- 集合结构
集合结构(Set Structure)中所有数据元素除了同属于一个集合外,并无其他关系。
如图:
 2) 线性结构
2) 线性结构
线性结构(Linear Structure)指的是数据元素之间存在“一对一的关系”
如图:
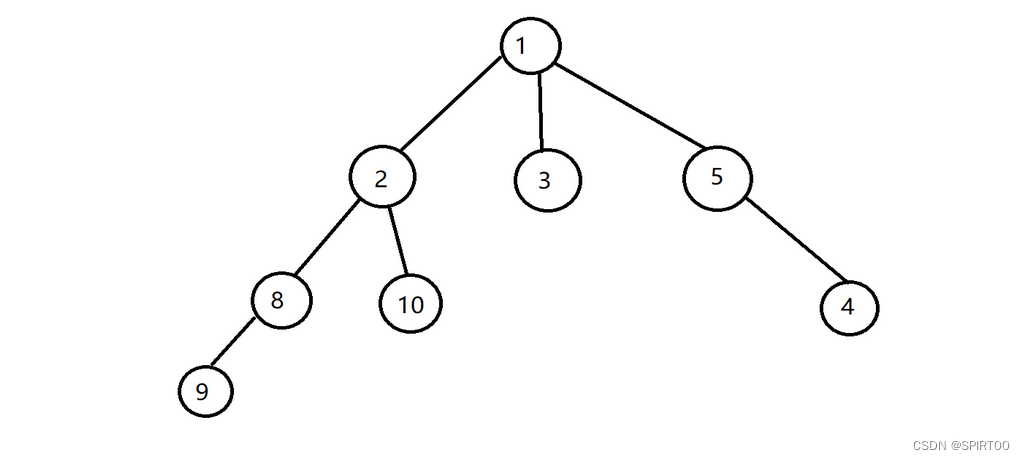
 3) 树形结构
3) 树形结构
树形结构(Tree Structure)指的是数据元素之间存在“一对多”的层次关系。
如图:
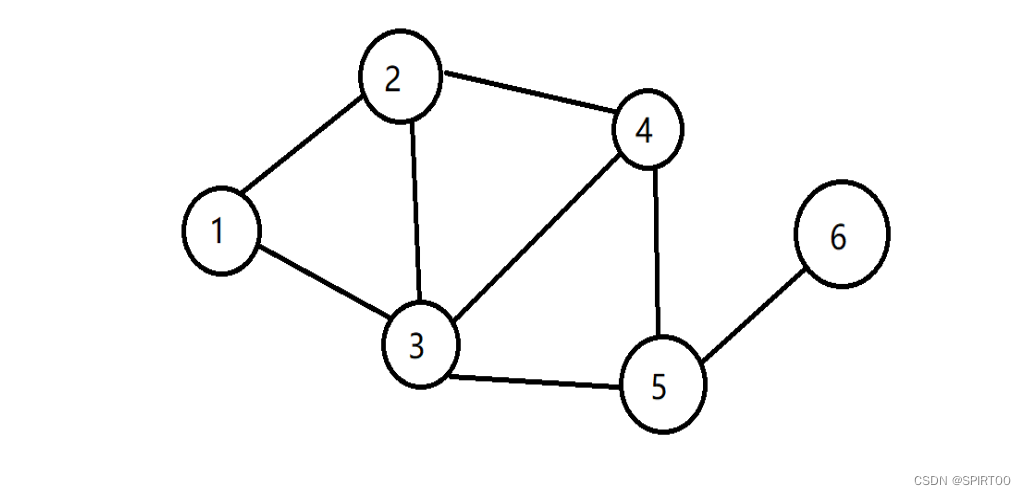
4) 图形结构
图形结构(Graphic Structure,也称:网状结构)指的是数据元素之间存在“多对多的关系”(注:此时的“多对多”中的多表示,至少有一个)
图示:
3.数据类型
- 数据类型
数据类型(Data Type)是高级程序设计语言中的概念,是数据的取值范围和对数进行操作的总和。数据类型规定了程序中对象的特性。程序中的每一个变量,常量或者表达式都属于一种数据类型。
- 抽象数据类型
抽象数据类型(Abstract Data Type,ADT)只是一个数学模型以及定义在模型上的一组操作。通常是对数据的抽象,定义了数据的取值范围以及对数据操作的集合。
抽象数据类型的特征是实现与操作分离,从而实现封装。
我们拿《魂斗罗》做比方:我们给予主角打,跳,移动的基本操作,这些操作就可以看作是抽象数据类型,这一组操作就属于一个模型,这组抽象的数据类型可以在《魂斗罗》这个环境中使用。
2.理解复杂度概念
1.时间空间复杂度定义
- 时间复杂度
时间复杂度表示一个程序运行所需要的时间,其具体需要在机器环境中才能得到具体的值,但我们一般并不需要得到详细的值,只是需要比较快慢的区别即可,为此,我们需要引入时间频度(语句频度)的概念。
时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。一般情况下,算法中的基本操作重复次数的是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
2.空间复杂度
一个程序的空间复杂度是指运行完一个程序所需内存的大小,其包括两个部分。
a)固定部分。这部分空间的大小与输入/输出的数据的个数多少、数值无关。主要包括指令空间(即代码空间)、数据空间(常量、简单变量)等所占的空间。这部分属于静态空间。
b)可变空间,这部分空间的主要包括动态分配的空间,以及递归栈所需的空间等。这部分的空间大小与算法有关。
- 度量时间复杂度的两种方法
1)事后统计法
顾名思义,就是指在程序运行结束之后直接查看运行时间的方式进行时间复杂度的统计,通常采用利用计算机的计时器对不同算法编制的程序进行运行时间的比较,从而确认一个算法的效率。
但这种方法有很多缺陷:
a)特别依赖计算机环境,同一套算法可能在不同的计算机上面有着截然不同的效果,老式的计算机和现代电脑的算力完完全全不是一个级别的处理速度。
b)算法的测试困难,有时一套算法需要海量的数据才能真正比较出效果,而为了设计这样的海量数据以及正确性,则需要花费大量的时间,而对于不同的数据,同一算法又有不一样的效果,故对于数据的使用很难去抉择。
也正是因为有这样的缺陷,
2)事先估计法
与事后统计法不一样,事先统计法采取在计算机编译程序前对该算法进行预估的方式估算。我们可以通过利用时间频度以及函数的思维进行对时间复杂度的解析。
这里就不得不讲函数符号,它通常用来描述算法的时间复杂度,其中:
〇表示最坏情况,Ω表示最好情况,θ表示平均情况,我们常用的分析使用O进行表示即可。对于一个算法的时间复杂度而言,n表示其执行问题的规模,O(n)表示执行该问题需要的时间量级,如O(n)表示线性级别,O(n2)表示平方级别,其中n主要的判断方式为算法中循环结构的执行次数。
以下为一些常用的基本公式:
a)O(a)=O(1) 其中a为常数
b)O(an)=O(n) 其中a为常数
c)O(an2++bn+c)=O(n2) 其中a,b,c均为常数,结果只与最大项n有关
3.时间复杂度的度量方法
- 度量时间复杂度
a)O(1) / O© C代表常数
#include<stdio.h>
int main(){
printf("Hello World"); //执行一次
return 0; //执行一次
}
- 1
- 2
- 3
- 4
- 5
对于如上代码,执行了两次,即O(2)=O(1),我们可以称其时间复杂度为O(1),或者常数级时间复杂度
b)O(n)
#include<stdio.h>
int main(){
int n=10000,ans=0; //执行一次
for(int i=0;i<n;i++){ //执行n次
ans+=i; //执行一次
}
return 0; //执行一次
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对于如上代码,我们一共执行了n1+2次,即O(n1+2),由上文我们的公式得到其复杂度为O(n),或称之为线性阶时间复杂度。
c)O(n^2)
#include<stdio.h>
int main(){
int n=10000,ans=0; //执行一次
for(int i=0;i<n;i++){ //执行n次
for(int j=0;j<n;j++){ //执行n次
ans+=j;
}
}
return 0; //执行一次
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对于如上代码,我们一共执行了nn1+2次,即O(nn1+2),由上文我们的公式得到其复杂度为O(n2),或称之为平方阶时间复杂度,此外还有三层循环结构嵌套组成的O(n3)级别的时间复杂度,称之为立方阶时间复杂度,随着嵌套的增多,甚至还有O(n!)级,称之为阶层级时间复杂度,但是这种级别复杂度极高,程序运行极其缓慢。
d)O(logn)
#include<stdio.h>
int main(){
int i=1,n=10000; //执行一次
while(i<=n){ //执行logn次
i*=2;
}
return 0; //执行一次
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对于如下代码,与上文的线性增长不同,其i的增长是倍增的形式,也就是说i会随着运行次数的增加变大的趋势变更大,这样会比那些简单的用加法上涨的变量更快到达循环结构的边界,这样的代码时间复杂度一般为log级别,对于本样例,有O(logn+2)=O(logn),称之为对数阶时间复杂度
注:可理解为设需要x次数,所以2^x<=n
e)O(n*logn)
#include<stdio.h>
int main(){
int n=10000,ans=0; //执行一次
for(int i=0;i<n;i++){ //执行n次
int j=0; //执行1次
while(j<=n){ //执行log(n)次
j*=2;
}
}
return 0; //执行一次
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对于上文的对数级别的时间复杂度,一样可以实用别的循环进行嵌套,比如本样例O(n*(logn+1)+2)=O(n*logn)级别
除此之外还有很多种时间复杂度的组合,比如说O(2^n)这样的指数阶时间复杂度,有时甚至需要引入多个变量乃进行表示,不过最核心的还是要观察循环结构的处理。
2.各个复杂度的比较
如图,我们以x轴为n的规模,y轴为整体的计算次数,可以发现其明显的计算区别,立方级别似乎很小的数就变得需要很多得计算了,而相对得logn级别得复杂度似乎无论怎么增加n,其涨幅都不是很明显。
然而事实上,计算机的计算次数何止60次啊,计算机真实的计算速度是论千论万论亿级别的计算,所以我们的n会变得非常之大,让我们把坐标进行变化,以10000为界进行理解。
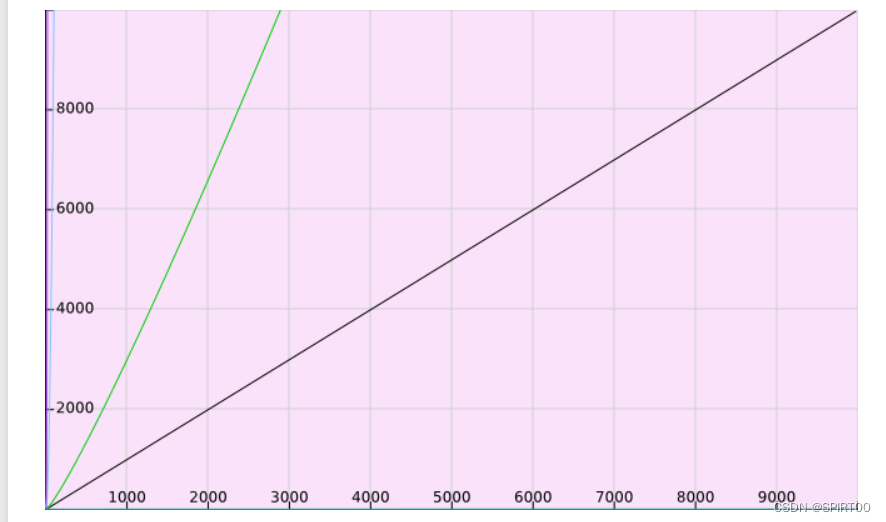
可以见到,平方以及立方级别的复杂度几乎已经是平贴着y轴的一条直线了,而O(n*log(n))与O(n)还保持着一定的速率进行增长,log(n)又是另一个极端,它变成了一个几乎贴着x轴的直线,这样算法的效率就轻易看得出了。
综上可以直观的得出:
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n)
在设计程序的时候一定要注意,高计算需求的地方一定不要使用太高的时间复杂度的计算方式!
4.程序运行时的内存与地址
- 理解内存
开始数据结构的正式代码编写之前,我们得先熟悉一个计算机中重要的概念——内存,当然这里不是教你如何选购内存条,这里是介绍数据结构学习中必须要掌握的关于内存的基本概念。
首先请看这么一张图:

(地址的常用表示为十六进制表示法,即Ox+十六进制数)
由这个图可以清晰的发现对于每一段的内存中的数据,都有一个地址与之相对应,也真是因为有地址的存在,我们计算机中才可以轻易的去访问到其中数据,拿一个数组来说,数组在C语言中是顺序存储的,因此,如上图的数据直接用代码找到其数据以及地址的话可以这样写
#include<stdio.h>
int main(){
int i;
char array[10]="ACDEQSFVCK";
for(i=0;i<10;i++){
printf("The %c Address is %x \n",array[i],&array[i]);
//%x可以换成%p都是十六进制表示,只不过%p会把所有的位数显示出来
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其数据的输出结果如下(注意,不同的电脑可能地址不一样):因为有64位和32位
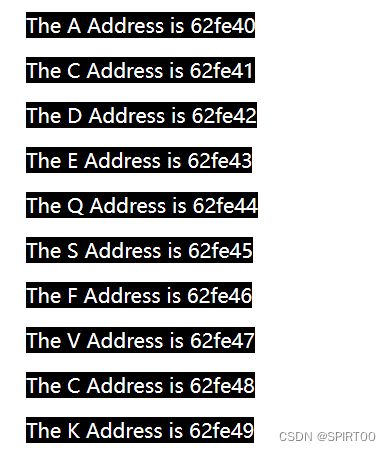 可以看到这是一段连续的地址,当你把char类型换成int型之后可能又不太一样,因为char是1字节的,而int占4字节,所以int的地址会变成4个一跳的方式往上增长。
可以看到这是一段连续的地址,当你把char类型换成int型之后可能又不太一样,因为char是1字节的,而int占4字节,所以int的地址会变成4个一跳的方式往上增长。
不难察觉,指针似乎与内存的联系十分密切,事实上,指针就是为了灵活的操纵内存而设计的, C/C++语言的灵魂就在指针上,指针的存在,使得内存地址可以像数据一样进行赋值修改,极其灵活且方便(同时也具有风险)。
5.编程预备
两个必备的函数知识(其均来自于stdlib.h库中)
- Malloc函数
malloc()函数在堆中申请分配一个大小为size个字节的连续内存空间,若成功分配,则返回一个指向所分配空间起始地址的指针,否则返回空指针(NULL)。
2.Free函数
free()函数用来释放已分配的内存空间,参数p是待释放的内存空间的首指针
总结来说malloc就是用来申请内存空间,而free是为了释放内存空间,这两个函数在C/C++语言的数据结构中十分重要,也十分常用,请务必牢记,这里总结几个新手易犯的错误:
a)忽略判断是否内存申请失败,如果内存申请失败并没有执行一些中断之类的操作,程序会继续向下运行,直到各种错误把整个程序弄崩溃
b)使用malloc不适用free,这在做题中似乎无关紧要,但是一旦在工作中养成这样的习惯,则会制造出很多无用的内存垃圾,造成程序效率的低下,当然了,后面出现了内存回收机制可以自动帮我们free掉内存垃圾,但是依旧要养成即时释放内存的好习惯。
c)使用指针后胡乱进行移动,产生不知名的指针位移,这样的效果往往是不知道自己的程序究竟出了什么错误,也极其难修改。
一般而言,常规的内存分配,使用再到释放的过程如下:
#include<stdio.h>
#include<stdlib.h>
int main(){
int *p; //定义一个指向整形的指针变量
p=(int*)malloc(5*sizeof(int)); //申请5个整形大小的内存空间并返回起始地址给p
if(p==NULL){ //申请失败
//执行申请失败的代码,一般print一个报错
exit(1); //退出
}
p[0]=1000; //为空间中添加数据
printf("%d",p[0]); //打印这个数据
free(p); //释放p的内存空间,此时p依旧存在,只不过失去了指向的对象,成了野指针
p=NULL; //为其赋NULL,此时它不再是一个野指针
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
很显然,我们设计一个数据结构程序的过程是先定义所需要的变量与指针变量---->进行内存分配---->判断是否分配成功(分配不成功就报错或者退出程序)---->对指针空间中的数据进行操作(如赋值,修改,查询,删除) ---->完成操作后释放指针
new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。而堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。
总结
寄蜉蝣于天地,渺沧海之一粟。“善护念”来自“https://www.dotcpp.com/course”


