
- 1应用服务器(App Server)_app服务器应用
- 2python 漂亮的excel_python 读取excel文件数据生成比较好看的html报告
- 3阿里新突破!自主创新的下一代匹配&推荐技术:任意深度学习+树状全库检索
- 4Android Studio 升级gradle异常_the following dependencies do not satisfy the requ
- 5mysql mvcc 读写阻塞_全网最全一篇MySQL数据库MVCC详解,不全你打我
- 6Trie树 c++实现_c++ trie树
- 7(九) android基础介绍--ContentProvinder内容提供者_android 11设置contentpro的值
- 8在Windows下远程桌面连接Linux - VNC篇_win远程桌面可以连接但vnc viewer
- 9基于变因子加权学习与邻代维度交叉策略的单目标优化算法求解——改进乌鸦算法
- 10RBTree——红黑树_undefined symbol: rbtree
百川大模型【Baichuan-13B】发布:更大尺寸、更多数据、对话能力更强_baichuan 13b 平均推理速度
赞
踩
欢迎关注公众号 - 【AICV与前沿】,一起学习最新技术吧
欢迎关注公众号 - 【AICV与前沿】,一起学习最新技术吧
项目地址:https://github.com/baichuan-inc/Baichuan-13B
Hugging Face:
https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
https://huggingface.co/baichuan-inc/Baichuan-13B-Base
- 1
- 2
- 3
- 4
Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。
Baichuan-13B 有如下几个特点:
1. 更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
2. 同时开源预训练和对齐模型:预训练模型是适用开发者的『 基座 』,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
3. 更高效的推理:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
4. 开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
模型细节
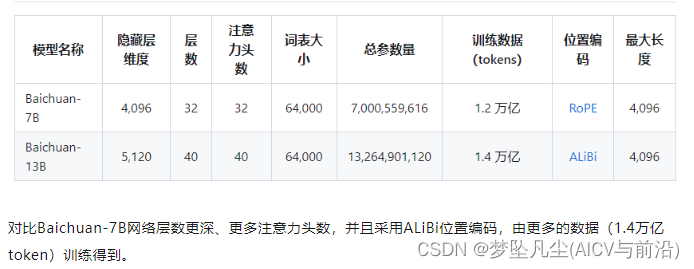
推理性能
Baichuan-13B 使用了 ALiBi 线性偏置技术,相对于 Rotary Embedding 计算量更小,对推理性能有显著提升;与标准的 LLaMA-13B 相比,平均推理速度 (tokens/s) 实测提升 31.6%:
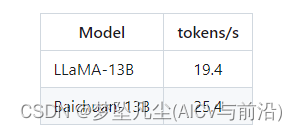
部署体验
-
从https://github.com/baichuan-inc/Baichuan-13B下载代码
-
在Baichuan-13B文件夹下新建文件夹baichuan-inc,然后从https://huggingface.co/baichuan-inc/Baichuan-13B-Chat置于baichuan-inc文件夹中
-
安装依赖
pip install -r requirements.txt
- 1
4.命令行方式体验
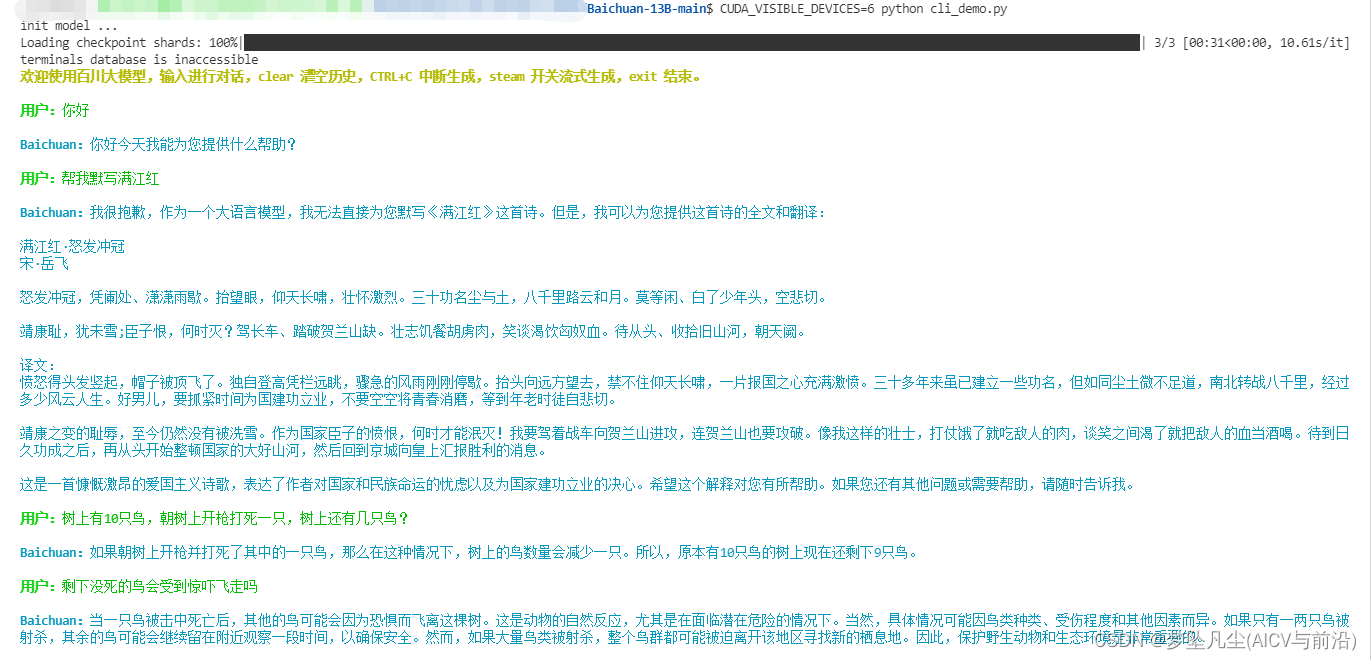
运行 python cli_demo.py, 占用内存如下图

体验效果如下,很好很强大!!!

Baichuan-13B同时支持量化方式,加载模型代码修改为如下即可,在cli_demo.py中注意要注释掉device_map="auto"这一句,否者量化不成功,该语句会把原始精度模型直接加载到 GPU 。
# int8量化
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(8).cuda()
# int4 =量化
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(4).cuda()
- 1
- 2
- 3
- 4
- 5
- 6
官方给出的量化前后占用内存对比如下。
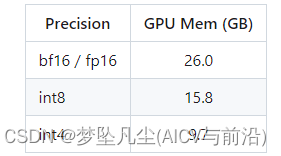
但是我量化后推理体感变慢了??
- 网页方式
基于streamlit框架,运行以下然后将出现的地址复制到浏览器打开即可。
streamlit run web_demo.py

