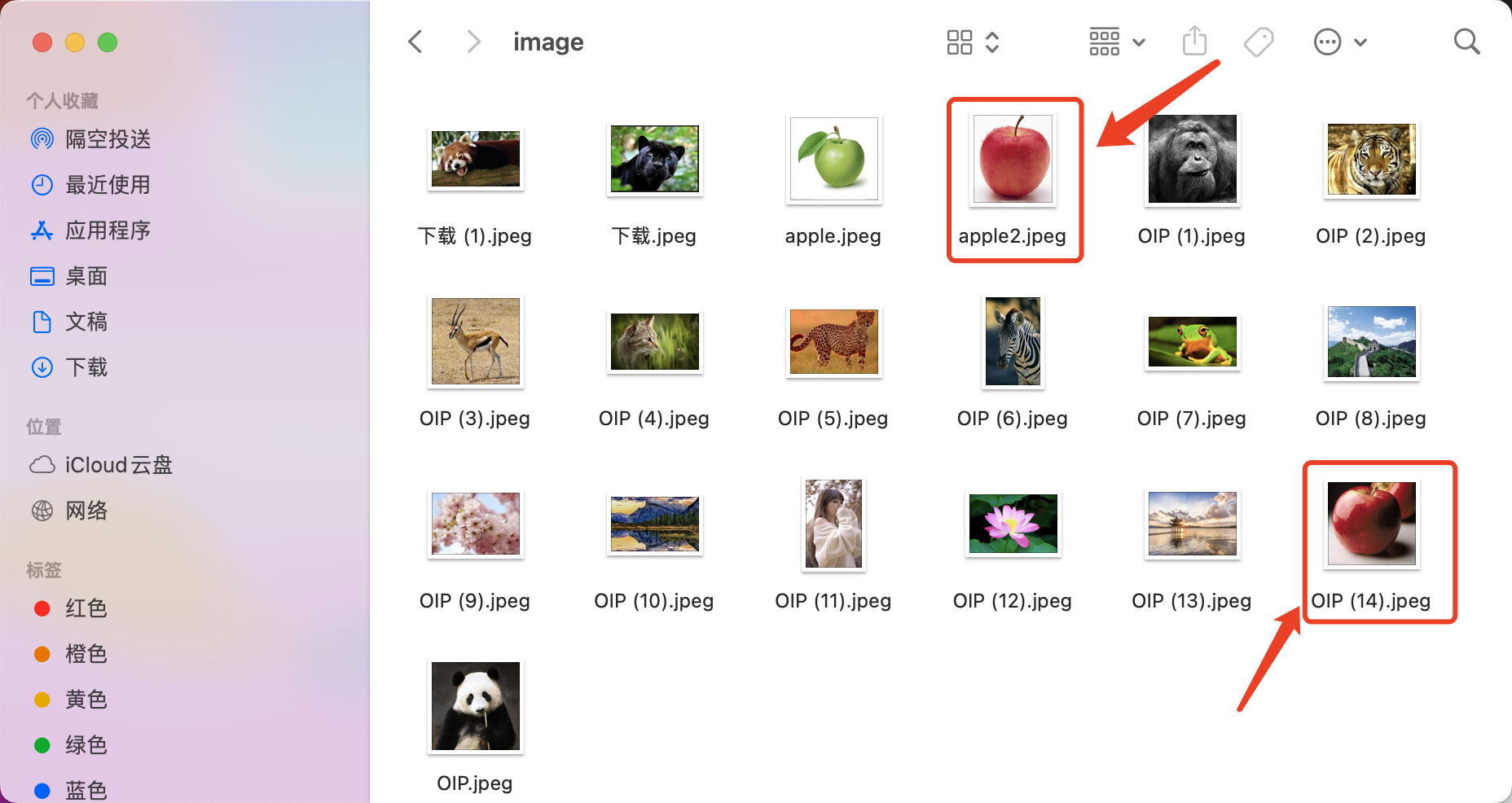
如何实现图像搜索,文搜图,图搜图,CLIP+faiss向量数据库实现图像高效搜索
这是AIGC的时代,各种GPT大模型生成文本,还有多模态图文并茂大模型,
以及stable diffusion和stable video diffusion 图像生成视频生成等新模型,
层出不穷,如何生成一个图文并貌的文章,怎么在合适的段落加入图像,图像用什么方式获取,
图像可以使用搜索的形式获取,也可以使用stable diffusion生成
今天说说怎么使用搜索的形式获取,这种方式更高效,节省算力,更容易落地
clip模型,详细可以查看知乎
https://zhuanlan.zhihu.com/p/511460120
或论文https://arxiv.org/pdf/2103.00020.pdf
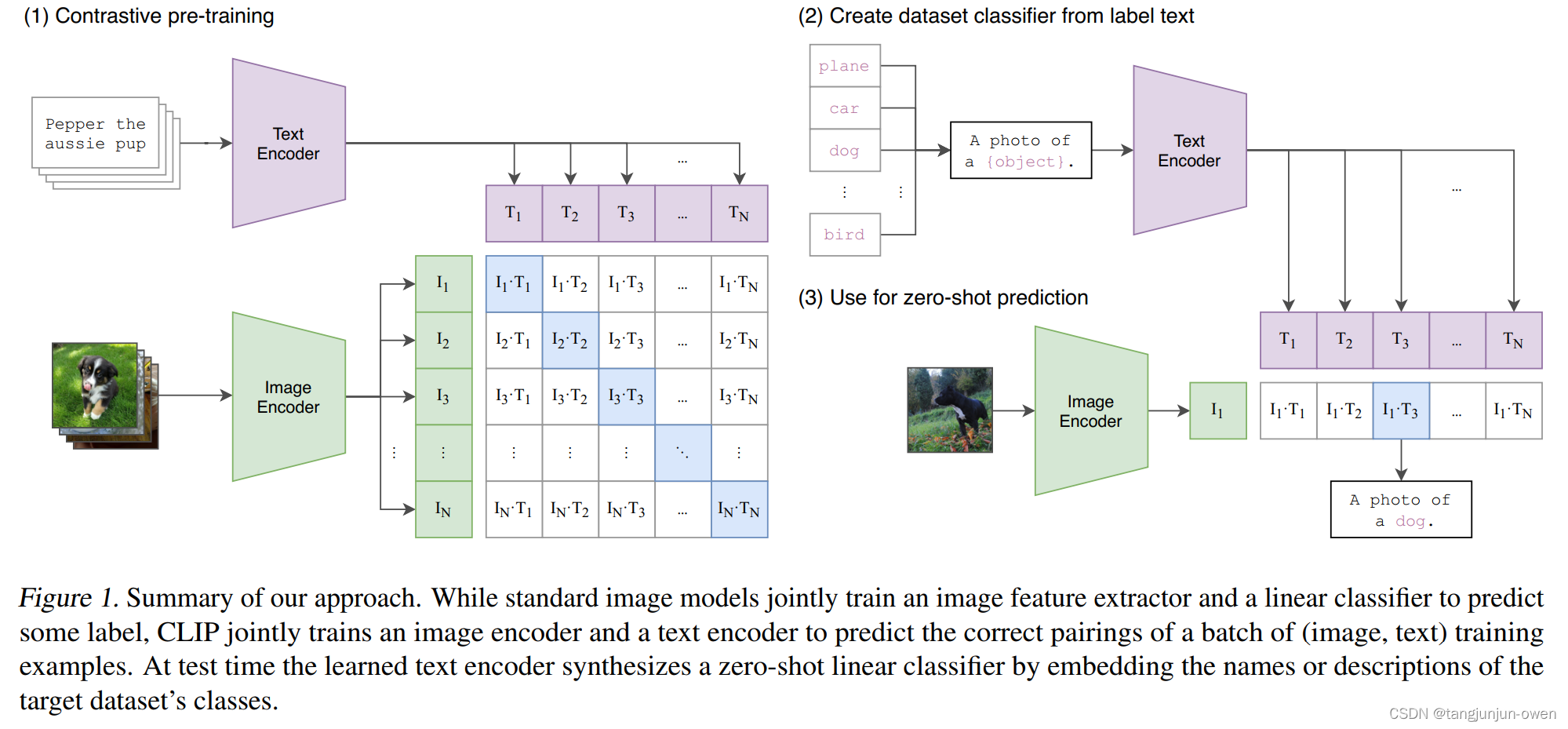
什么是faiss数据库
Faiss的全称是Facebook AI Similarity Search,是FaceBook的AI团队针对大规模相似度检索问题开发的一个工具,使用C++编写,有python接口,对10亿量级的索引可以做到毫秒级检索的性能。
简单来说,Faiss的工作,就是把我们自己的候选向量集封装成一个index数据库,它可以加速我们检索相似向量TopK的过程,其中有些索引还支持GPU构建,可谓是强上加强。
https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/
1.huggingface下载clip模型,默认是英文版,也有中文版,英文版的效果会更好些
英文版
- from PIL import Image
- import requests
-
- from transformers import CLIPProcessor, CLIPModel
-
- model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
- processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
-
- # url = "http://images.cocodataset.org/val2017/000000039769.jpg"
- # image = Image.open(requests.get(url, stream=True).raw)
-
- # inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
-
- # image_features = model.get_image_features(inputs["pixel_values"])
- # text_features = model.get_text_features(inputs["input_ids"],inputs["attention_mask"])
-
-
- # outputs = model(**inputs)
- # logits_per_image = outputs.logits_per_image # this is the image-text similarity score
- # probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
-
- # print(probs)

中文版
- from PIL import Image
- import requests
- from transformers import ChineseCLIPProcessor, ChineseCLIPModel
- import torch
-
- device = torch.device("mps")
-
- model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
- processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
-
- # url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
- # image = Image.open(requests.get(url, stream=True).raw)
- # Squirtle, Bulbasaur, Charmander, Pikachu in English
- # texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
-
- # # compute image feature
- # inputs = processor(images=image, return_tensors="pt")
- # image_features = model.get_image_features(**inputs)
- # image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
-
- # # compute text features
- # inputs = processor(text=texts, padding=True, return_tensors="pt")
- # text_features = model.get_text_features(**inputs)
- # text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
-
- # # compute image-text similarity scores
- # inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
- # outputs = model(**inputs)
- # logits_per_image = outputs.logits_per_image # this is the image-text similarity score
- # probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
2.可以爬一些图片,做图像库,搜索也是在这个图像库中搜索,这个爬取的图像内容和业务场景相关,
比如你想获取动物的图像,那主要爬动物的就可以,这是我随便下载的一些图片
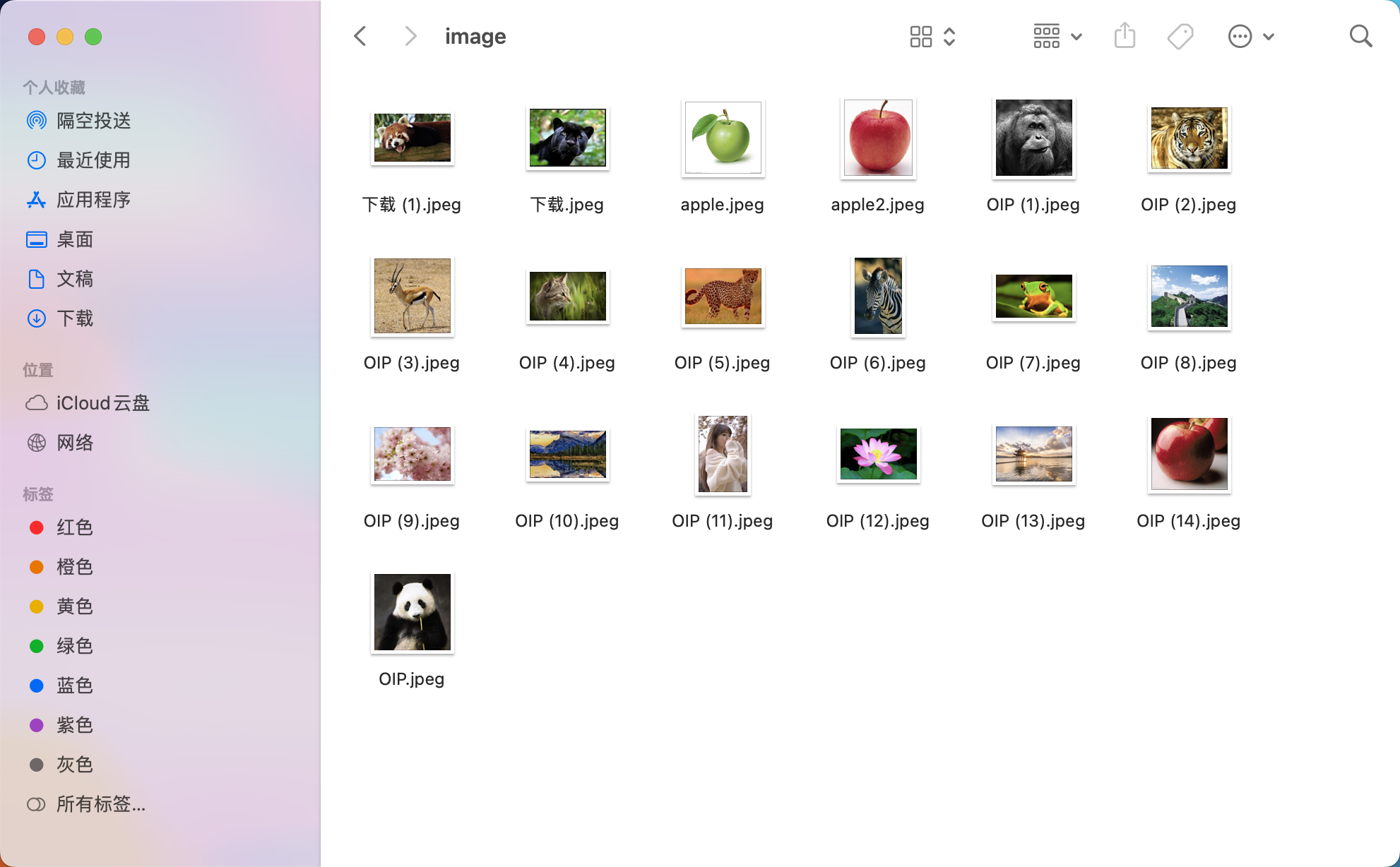
3.把图像映射成向量,存储在向量数据库faiss中
- # from clip_model import model,processor
- import faiss
- from PIL import Image
- import os
- import json
- from chinese_clip import model,processor
- from tqdm import tqdm
-
- d = 512
- index = faiss.IndexFlatL2(d) # 使用 L2 距离
-
- # 文件夹路径
- # folder_path = '/Users/smzdm/Downloads/Animals_with_Attributes2 2/JPEGImages'
- folder_path = "image"
-
- # 遍历文件夹
- file_paths = []
- for root, dirs, files in os.walk(folder_path):
- for file in files:
- # 检查文件是否为图片文件(这里简单地检查文件扩展名)
- if file.lower().endswith(('.png', '.jpg', '.jpeg', '.gif')):
- file_path = os.path.join(root, file)
- file_paths.append(file_path)
-
- id2filename = {idx:x for idx,x in enumerate(file_paths)}
- # 保存为 JSON 文件
- with open('id2filename.json', 'w') as json_file:
- json.dump(id2filename, json_file)
-
- for file_path in tqdm(file_paths,total=len(file_paths)):
- # 使用PIL打开图片
- image = Image.open(file_path)
- inputs = processor(images=image, return_tensors="pt", padding=True)
- image_features = model.get_image_features(inputs["pixel_values"])
- image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
- image_features = image_features.detach().numpy()
- index.add(image_features)
- # 关闭图像,释放资源
- image.close()
-
- faiss.write_index(index, "image.faiss")
-
-
4.加载数据库文件和索引文件,使用文本搜索图像或图像搜索图像
- # from clip_model import model,processor
- import faiss
- from PIL import Image
- import os
- import json
- from chinese_clip import model,processor
-
-
- d = 512
- index = faiss.IndexFlatL2(d) # 使用 L2 距离
-
- # 保存为 JSON 文件
- with open('id2filename.json', 'r') as json_file:
- id2filename = json.load(json_file)
- index = faiss.read_index("image.faiss")
-
-
- def text_search(text,k=1):
- inputs = processor(text=text, images=None, return_tensors="pt", padding=True)
- text_features = model.get_text_features(inputs["input_ids"],inputs["attention_mask"])
- text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
- text_features = text_features.detach().numpy()
- D, I = index.search(text_features, k) # 实际的查询
-
- filenames = [[id2filename[str(j)] for j in i] for i in I]
-
- return text,D,filenames
-
- def image_search(img_path,k=1):
- image = Image.open(img_path)
- inputs = processor(images=image, return_tensors="pt")
- image_features = model.get_image_features(**inputs)
- image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
-
- image_features = image_features.detach().numpy()
- D, I = index.search(image_features, k) # 实际的查询
-
- filenames = [[id2filename[str(j)] for j in i] for i in I]
-
- return img_path,D,filenames
-
-
-
- if __name__ == "__main__":
-
- text = ["雪山","熊猫","长城","苹果"]
- text,D,filenames = text_search(text)
- print(text,D,filenames)
-
- # img_path = "image/apple2.jpeg"
- # img_path,D,filenames = image_search(img_path,k=2)
- # print(img_path,D,filenames)
比如用文字搜索
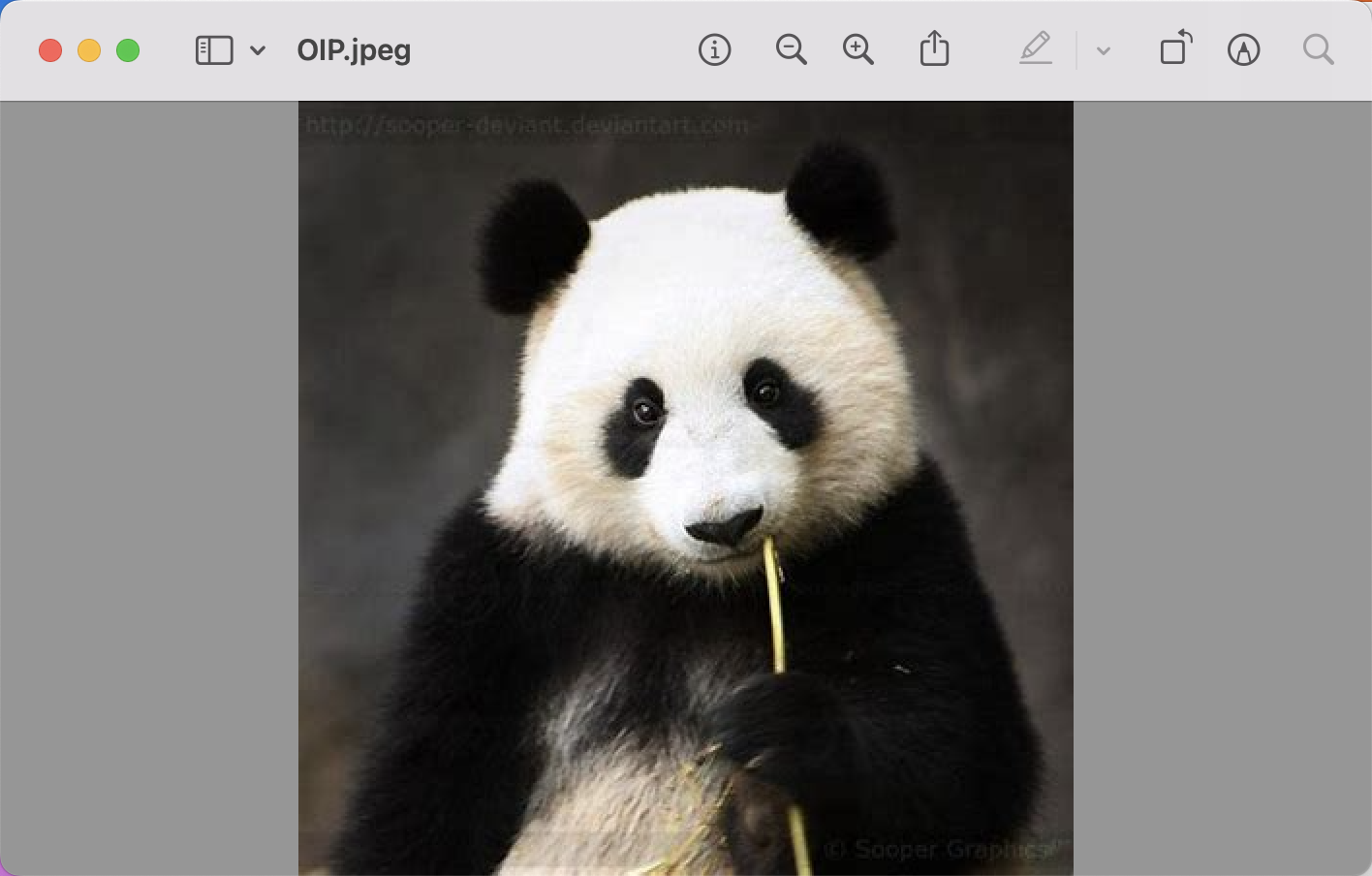
["雪山","熊猫","长城","苹果"]返回结果:
['雪山', '熊猫', '长城', '苹果'] [[1.2182312] [1.1529984] [1.1177421] [1.1656866]] [['image/OIP (10).jpeg'], ['image/OIP.jpeg'], ['image/OIP (8).jpeg'], ['image/apple2.jpeg']]


还可以使用图片搜图片,打开下面的注释
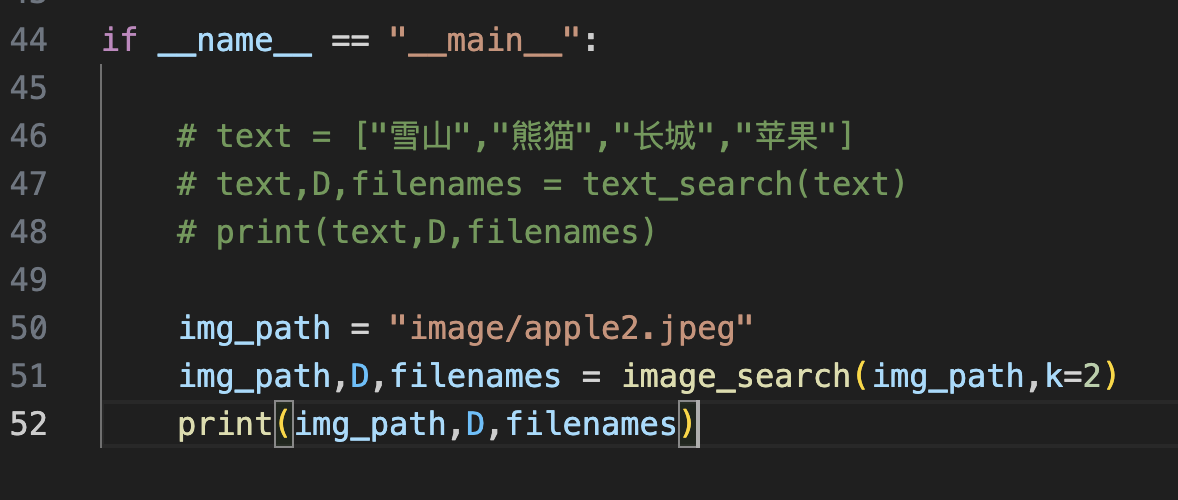
返回结果
image/apple2.jpeg [[0. 0.11877532]] [['image/apple2.jpeg', 'image/OIP (14).jpeg']]
第一张图像是本身,完全相似,第二张可以看到是一个苹果